监督学习——综述
目录
生成模型
判别模型
常见的损失函数
0-1损失
绝对值损失
log对数损失
平均绝对误差
平方损失
均方根误差
指数损失
Hinge损失
Huber损失
softmax损失
参考博客
大致写完了数据处理相关的部分,接下来就要手撕各种算法了。
先从有监督学习算法开始,大致包括以下算法:
感知机
线性回归+Ridge+Lasso+ElasticNet+正则化
逻辑回归+多分类问题
决策树
最近邻
朴素贝叶斯
SVM
Adaboost
随机森林
GBDT、GBRT、Xgboost
Bagging、Boost等综述
因为博主最近要准备面试..所以自然是先从自己用过的算法中进行描述,所以感知机、朴素贝叶斯往后放放~
这里还会先写写LSTM、GD、牛顿法等
这将不是一个入门博客,这是个人总结博客!
这将不是一个入门博客,这是个人总结博客!
这将不是一个入门博客,这是个人总结博客!
重点:算法核心原理(几句话描述)、推导过程、伪代码、算法对比
监督学习方法又可以分为生成方法(generative approach)和判别方法(discriminative approach),所学到的模型分别称为生成模型和判别模型。
生成模型
生成模型由数据学习联合概率分布P(X, Y),然后求出条件概率分布P(Y|X)作为预测。常见的生成方法有LDA主题模型、朴素贝叶斯算法和隐式马尔科夫模型等。
生成模型的求解思路 :联合分布--->计算类别先验概率P(Y)和类别条件概率P(X|Y)--->P(Y|X)。
优点 :
- 收敛速度比较快,即当样本数量较多时,生成模型能更快地收敛于真实模型;
- 能够应付存在隐变量的情况,比如混合高斯模型就是含有隐变量的生成方法;
缺点 :
- 联合分布是能提供更多的信息,但也需要更多的样本和更多计算,尤其是为了更准确估计类别条件分布,需要增加样本的数目,而且类别条件概率的许多信息是我们做分类用不到的,因而如果我们只需要做分类任务,就浪费了计算资源;
- 实践中多数情况下判别模型效果更好;
判别模型
判别模型是由数据直接学习决策函数F(X)或者条件概率分布P(Y|X)作为预测的模型。常见的判别方法有SVM、LR等。
判别模型求解思路 :条件分布--->模型参数后验概率最大--->(似然函数* 参数先验)最大--->最大似然。
优点 :
- 与生成模型缺点对应,首先是节省计算资源,另外,需要的样本数量也少于生成模型;
- 准确率往往较生成模型高;
- 由于直接学习P(Y|X),而不需要求解类别条件概率,所以允许我们对输入进行抽象(比如降维、构造等),从而能够简化学习问题;
缺点 :
没有生成模型的上述优点;
常见的损失函数
损失函数(Loss Function)是用来估量模型的预测值 f(x) 与真实值 y 的不一致程度。
对于这么多的损失函数,光看下面的内容是看不懂的,毕竟下面的内容是一个总结。等学到了相关的算法,再回过头来看看,就会发现这些东西都是特别容易的。

下面依次来说说损失函数的问题,算是一个总结。
0-1损失
用于分类问题,这个最简单,真实值与预测值不同,记为1,相同则为0。

当然,如果要用于回归,我们可以对“相同”这个条件适当的放宽:
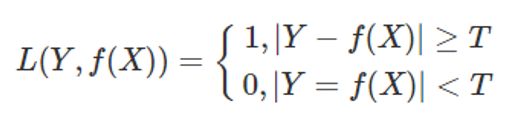
绝对值损失
用于回归问题,真实值与预测值之差的绝对值。

log对数损失
用于分类问题,常用于逻辑回归之中,

由此可以引出交叉熵的公式,也就是逻辑回归的损失函数:
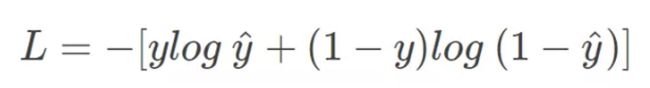
平均绝对误差
MAE,用于回归问题,在绝对值损失的基础上除一个样本数量。
有一个改进的指标,来个加权,叫加权平均绝对误差:

平方损失
用于回归问题,常用于线性回归之中,这是一个典型的凸函数。
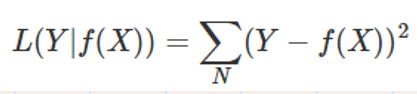
应该注意到,MSE的平方特性,对于大于1的误差会将其放大,对于小于1的误差会放小;可以理解为其偏向于惩罚误差较大的点,赋予它们更大的权重。所以,MSE放大了异常点的误差贡献,以牺牲其他正常数据点的预测效果为代价,这最终会降低模型的整体性能。比如下面的图,能明显感觉到,拟合曲线偏向于离群点。
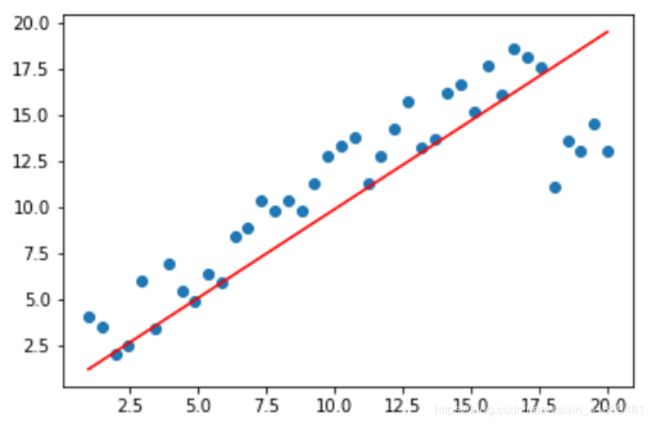
当然是有办法可以让这条拟合的线“忽略”那些可恶的离群点的,比如说ElasticNet算法、鲁棒线性回归等。
均方根误差
RMSE,公式为

均方根误差也对离群点敏感,并且健壮性不如平均绝对误差,所以有一个改进指标叫均方根对数误差。
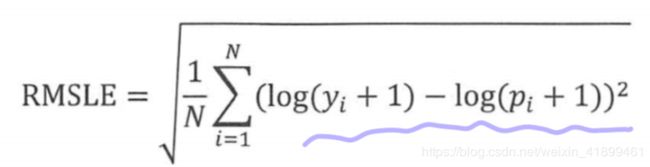
指数损失
用于Adaboost算法之中。
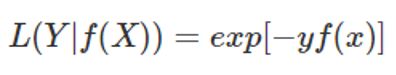
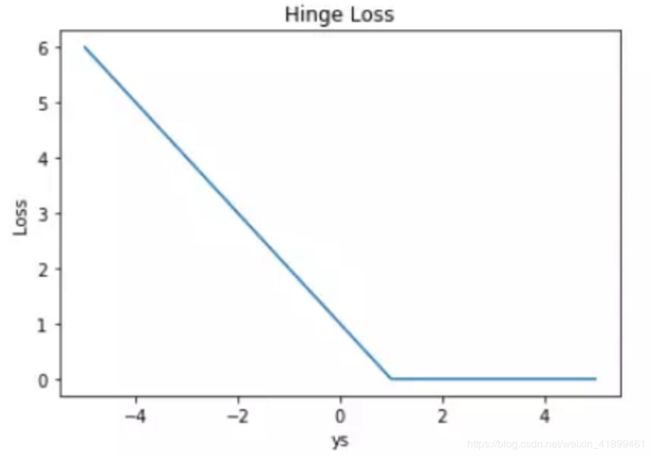
Hinge损失
用于分类问题,hinge loss又称为合页损失,因为它的图像看起来就像一本即将合上的书~

Huber损失
用于回归问题,一眼看过去以为很复杂的公式,其实很简单,它只是综合了平方损失和绝对值损失而已。
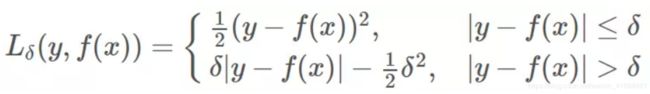
当误差较小时,我们使用平方损失;当误差较大时,我们使用绝对值损失。这么做有一个明显的好处,平方损失在误差较大的时候,因为平方了一下,所以误差会更加大的离谱,尤其是有一些离群点存在时,这种“放大”的误差往往掩盖了模型真实的能力。所以我们要对其优化,用的就是绝对值损失函数。
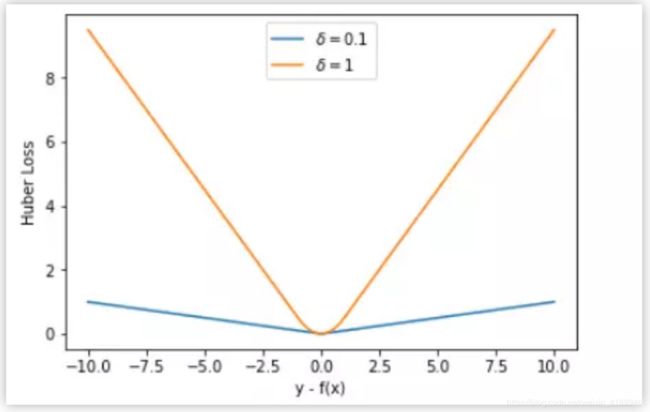
当然,huber损失也可以用于分类问题,
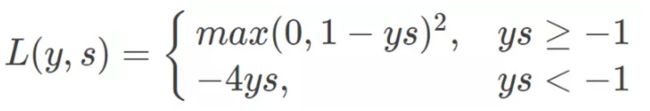
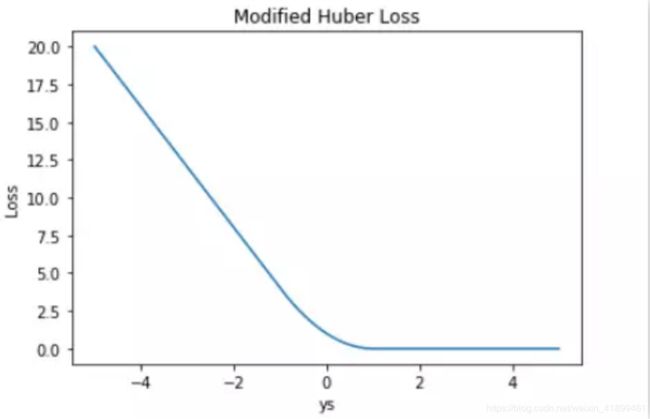
softmax损失
(待补充)
参考博客
https://www.zhihu.com/question/20446337