JAVA中的ArrayList(原理篇+使用篇)
这一篇呢,介绍了ArrayList的一些底层原理和用法。
本来想把原理和使用分开来写,但似乎内容不是那么多,就放在一起写了吧;
关于ArrayList的特点,他的底层实现是基于动态数组的数据结构,完全就可以当做一个可以进行增删改查的数组;
最开始呢,就说一下ArrayList实现的接口,ArrayList实现了三个标记性接口:
1、Serializable:序列化接口
Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程。
举个例子,如果我们有一个学生类;
public class Student implements Serializable{
private String name;
private int age;
private Skill skill;
public Student() {
}
public Student(String name,int age){
this.name=name;
this.age=age;
}
public Skill getSkill() {
return skill;
}
public void setSkill(Skill skill) {
this.skill = skill;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + ", skill=" + skill + "]";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
你看学生类的后面,我加上了Serializable接口,是为了干什么呢?目的就是为了能让这个学生类的对象能够序列化,现在我们就可以这样做;
public class Test {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Student stu1=new Student("张三",12);
ObjectOutputStream out=new ObjectOutputStream(new FileOutputStream("C:\\Users\\xuhexin\\Workspaces\\MyEclipse CI\\List\\111.text"));
out.writeObject(stu1);
out.close();
ObjectInputStream ins=new ObjectInputStream(new FileInputStream("C:\\Users\\xuhexin\\Workspaces\\MyEclipse CI\\List\\111.text"));
Student stu=(Student) ins.readObject();
System.out.println(stu);
}
}
主函数是把学生类的对象写进文件中,然后在读取,这就是序列化和反序列化的过程,如果不加上接口的话,java就会给你报一个无法序列化的异常,那通过这个例子,我们应该知道,只有实现了Serializable这个接口,数据才能够序列化和反序列化;
那既然ArrayList已经实现了Serializable这个接口,如果我不给学生类实现Serializable这个接口,这么写的话:
public static void main(String[] args) throws IOException, ClassNotFoundException{
Student stu1=new Student("张三",12);
Student stu2=new Student("李四",13);
Student stu3=new Student("王二麻子",14);
Student stu4=new Student("小淘气",15);
ArrayList<Student> list=new ArrayList<Student>();
list.add(stu1);
list.add(stu2);
list.add(stu3);
list.add(stu4);
//序列化
ObjectOutputStream out=new ObjectOutputStream(new FileOutputStream("C:\\Users\\xuhexin\\Workspaces\\MyEclipse CI\\List\\111.txt"));
out.writeObject(list);
//反序列化
ObjectInputStream ins=new ObjectInputStream(new FileInputStream("C:\\Users\\xuhexin\\Workspaces\\MyEclipse CI\\List\\111.txt"));
ArrayList<Student> list2=new ArrayList<Student>();
list2=(ArrayList<Student>) ins.readObject();
for(Student stu:list2) {
System.out.println(stu);
}
}
那也是完全没有问题的啊,因为ArrayList本身就实现了这个接口;
2、Cloneable:克隆接口
ArrayList所实现的第二个接口就是克隆接口,那用起来也是很简单;
还是以学生类举例子:
ArrayList<Student> listclone=(ArrayList<Student>) list2.clone();
for(Student stu:listclone) {
System.out.println(stu);
}
我们的listclone就是list2调用的克隆方法来实现的一个list拷贝,然后再用for…each循环输出,也是没有问题的,两个list是一样的数据;
然后值得注意的是,这个接口也是和上一个一样,是因为ArrayList本身实现了这个接口所以可以直接用,如果你想实现学生类对象的克隆,那就一定要在学生类后面添加这个接口;
3.RandAccess接口
这个接口的实现,用来表明其支持快速(通常是固定时间)随机访问。
我门这样来解释:
List<String> list=new ArrayList<String>();
for(int i=0;i<10000;i++) {
list.add(i+"a");
}
我门先创建一个list然后添加1万条数据;
然后我们来看一下随机访问的用时:
long start=System.currentTimeMillis();
for(int index=0;index<list.size();index++) {
list.get(index);
}
long end=System.currentTimeMillis();
System.out.println(end-start);
然后再来看一下顺序访问的用时:
long start1=System.currentTimeMillis();
Iterator<String> it=list.iterator();
while(it.hasNext()) {
it.next();
}
long end1=System.currentTimeMillis();
System.out.println(end1-start1);
然后对两个用时记性比较,然后会发现,随机访问要比顺序访问快;
所以结论是:如果实现了RandAccess接口,理论上随机访问要比顺序访问快!
接口说完就要说构造方法了:
4、无参数构造方法
无参构造方法也是最常用的,我们来看一下无参构造的源码是什么样的:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
能看到后面有个一大串英文,我们就在点开它看一下:
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
能看到,这就是一个空数组,对吧,所以结论是什么?
无参构造,构造的是一个初始容量为0的数组!
5.带初始容量的构造方法
依旧是看一下源码:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
我们倒过来看,先判断给的初始容量的值,如果小于0,就会报异常!
如果等于0:那就和无参构造一样的吧;
如果大于0,那么就创建一个大小为initialCapacity的数组!
6、以单列表为参数的构造方法
还是来看一下源码:
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// defend against c.toArray (incorrectly) not returning Object[]
// (see e.g. https://bugs.openjdk.java.net/browse/JDK-6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
可以看得出,先把c这个单列表调用了toArray方法,转换成了数组,然后把这个数组给了这个elementData ,然后在进行后面的判断elementData 的大小;
构造方法说完了,那就说add添加方法,刚才的例子中也有很多:
关于add方法,总各有四个,我就两个两个放一起说:
7、add(E e) 和 addAll(Collection c) 方法
前一个是:将指定的元素添加到此列表的尾部。
后一个是:按照指定 collection 的迭代器所返回的元素顺序,将该 collection 中的所有元素添加到此列表的尾部。
刚才我们说过在无参构造方法中初始容量为0,那,在第一次调用添加方法的时候,初始容量就会变成10,然后每次容量不够用了,就会进行扩容,扩容后得容量是原容量的1.5倍!
然后我们看这个例子:
public static void main() {
List<String> list=new ArrayList<String>();
list.add("123");
List<String> list2=new ArrayList<String>();
list2.addAll(list);
}
这就用到了上面的两个add方法;
那为什么要把这两个放在一起呢,因为他们都属于直接放在数组的末位置上就行,不管是一个还是一条,直接放在原数组的后面就行,如果容量不够,那我就进行扩容!
8、add(int index, E element)和addAll(int index, Collection c)方法
前一个:将指定的元素插入此列表中的指定位置。
后一个:从指定的位置开始,将指定 collection 中的所有元素插入到此列表中。
那这两个方法是怎么实现的呢?
先举个例子:
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<String>();
list.add("123");
list.add("456");
list.add("789");
list.add(1, "000");
System.out.println(list);
}
我们来看一下输出结果:
[123, 000, 456, 789]
没错,000把456和789挤后面去了;
我们来看一下图:
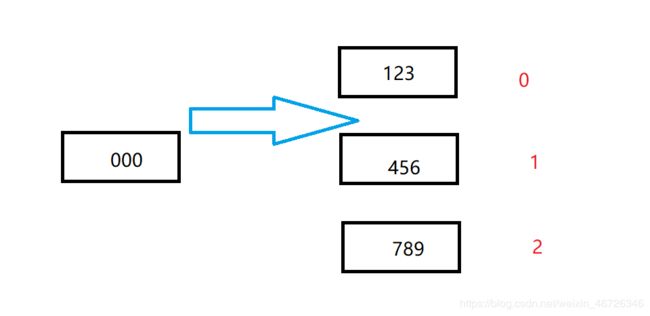
实现过程就是这样的,如果看源码的话,会知道其实是调用了arraycopy这个方法来实现出这个过程的!
然后我们如果再加点东西:
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<String>();
list.add("123");
list.add("456");
list.add("789");
list.add(1, "000");
System.out.println(list);
ArrayList<String> list2=new ArrayList<String>();
list2.add("abc");
list2.add("cde");
list2.addAll(0, list);
System.out.println(list2);
}
这样的list2话输出就是:[123, 000, 456, 789, abc, cde]
看一下图:

就是这个样子!把整个list插进去!
9、set和get方法
ArrayList本身就是一个数组,那他的set方法和get方法就简单多了;
set(int index, E element)
用指定的元素替代此列表中指定位置上的元素
get(int index)
返回此列表中指定位置上的元素。
来看一下例子:
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<String>();
list.add("123");
list.add("456");
list.add("789");
list.add(1, "000");
list.set(1, "abc");
System.out.println(list);
System.out.println(list.get(3));
}
输出结果就是
[123, abc, 456, 789]
789
底层的源码也就是对数组的简单操作:
public E set(int index, E element) {
Objects.checkIndex(index, size);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
public E get(int index) {
Objects.checkIndex(index, size);
return elementData(index);
}
10、删除元素remove和clear()清空元素
我们直接来看例子:
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<String>();
list.add("123");
list.add("456");
list.add("789");
list.remove(1);
System.out.println(list);
list.clear();
System.out.println(list);
}
输出结果是:
[123, 789]
[]
这里也就说一下怎么用就好了;
11、toString()方法
最后的话想说一下toString方法;
我们每次用System.out.println(list)这行代码就是调用了list的toString函数;
那我们来看一下底层是怎么实现这个toString方法的:
public String toString() {
Iterator<E> it = iterator();
if (! it.hasNext())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())
return sb.append(']').toString();
sb.append(',').append(' ');
}
}
我们能看出来,在这个方法体中,是用了Iterator对list进行遍历,然后用StringBuilder 这个可添加的字符串类型把所有的元素进行一个汇总,最后返回一个字符串;
所以结论就是,ArrayList的toString方法是用迭代器进行遍历,返回字符串的!
到此,关于ArrayList的一些底层原理和大部分方法的用法,就都说完了!
OK,end结束;