300分钟搞定数据结构与算法课程学习5 ——DFS和BFS
DFS 和 BFS 经常在算法面试题当中出现,在整个算法面试知识点中所占的比重非常大。应用最多的地方就是对图进行遍历,树也是图的一种。
深度优先搜索(Depth-First Search / DFS)
深度优先搜索,从起点出发,从规定的方向中选择其中一个不断地向前走,直到无法继续为止,然后尝试另外一种方向,直到最后走到终点。就像走迷宫一样,尽量往深处走。
DFS 解决的是连通性的问题,即,给定两个点,一个是起始点,一个是终点,判断是不是有一条路径能从起点连接到终点。起点和终点,也可以指的是某种起始状态和最终的状态。问题的要求并不在乎路径是长还是短,只在乎有还是没有。有时候题目也会要求把找到的路径完整的打印出来。
DFS 遍历
例题:假设我们有这么一个图,里面有A、B、C、D、E、F、G、H 8 个顶点,点和点之间的联系如下图所示,对这个图进行深度优先的遍历。
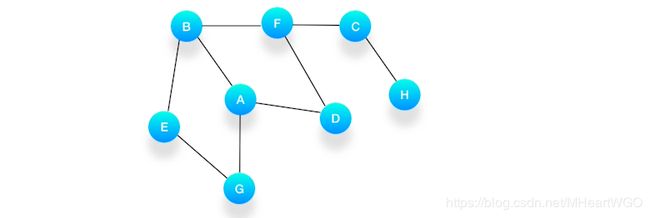
解题思路
必须依赖栈(Stack),特点是后进先出(LIFO)。
第一步,选择一个起始顶点,例如从顶点 A 开始。把 A 压入栈,标记它为访问过(用红色标记),并输出到结果中。
第二步,寻找与 A 相连并且还没有被访问过的顶点,顶点 A 与 B、D、G 相连,而且它们都还没有被访问过,我们按照字母顺序处理,所以将 B 压入栈,标记它为访问过,并输出到结果中。
第三步,现在我们在顶点 B 上,重复上面的操作,由于 B 与 A、E、F 相连,如果按照字母顺序处理的话,A 应该是要被访问的,但是 A 已经被访问了,所以我们访问顶点 E,将 E 压入栈,标记它为访问过,并输出到结果中。
第四步,从 E 开始,E 与 B、G 相连,但是B刚刚被访问过了,所以下一个被访问的将是G,把G压入栈,标记它为访问过,并输出到结果中。
第五步,现在我们在顶点 G 的位置,由于与 G 相连的顶点都被访问过了,类似于我们走到了一个死胡同,必须尝试其他的路口了。所以我们这里要做的就是简单地将 G 从栈里弹出,表示我们从 G 这里已经无法继续走下去了,看看能不能从前一个路口找到出路。
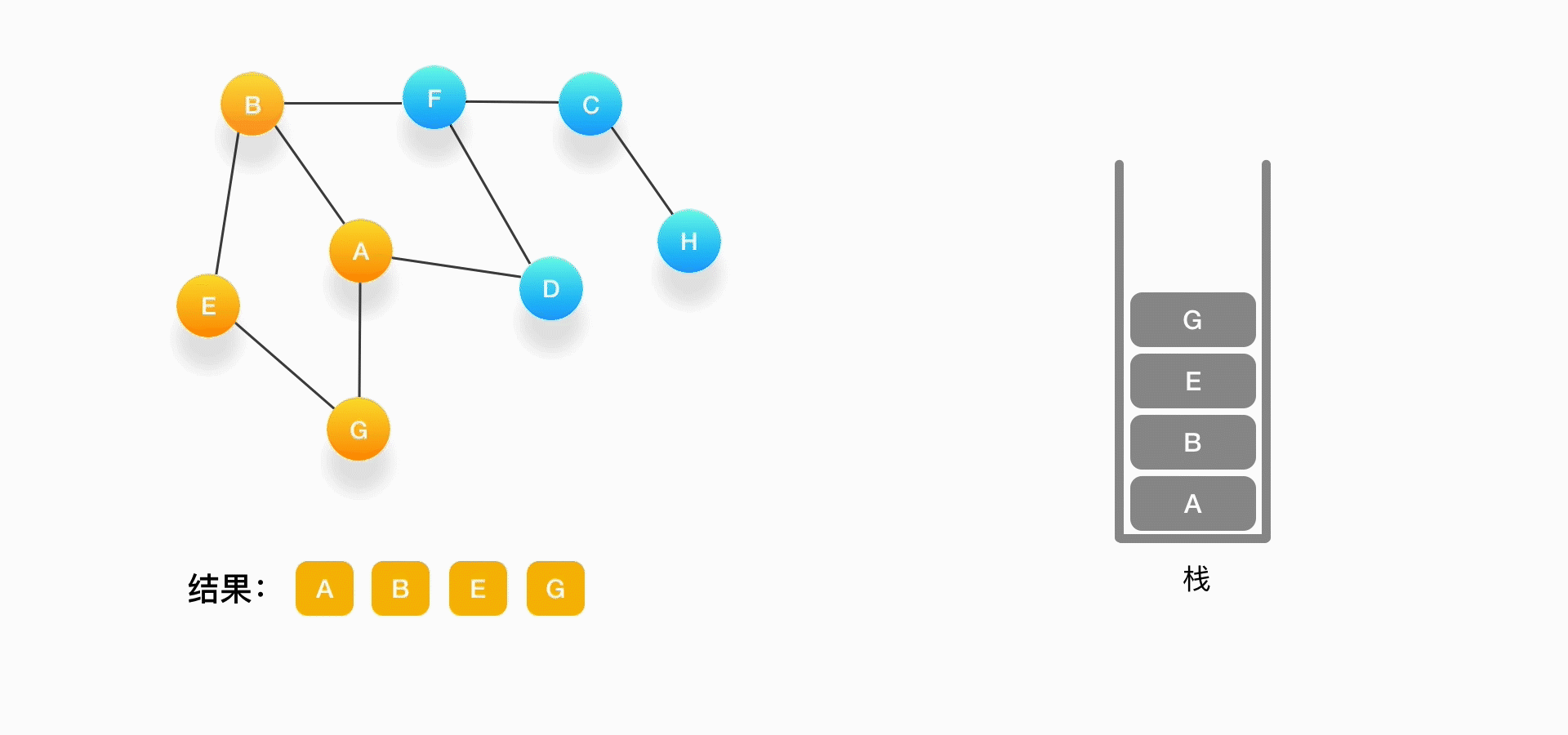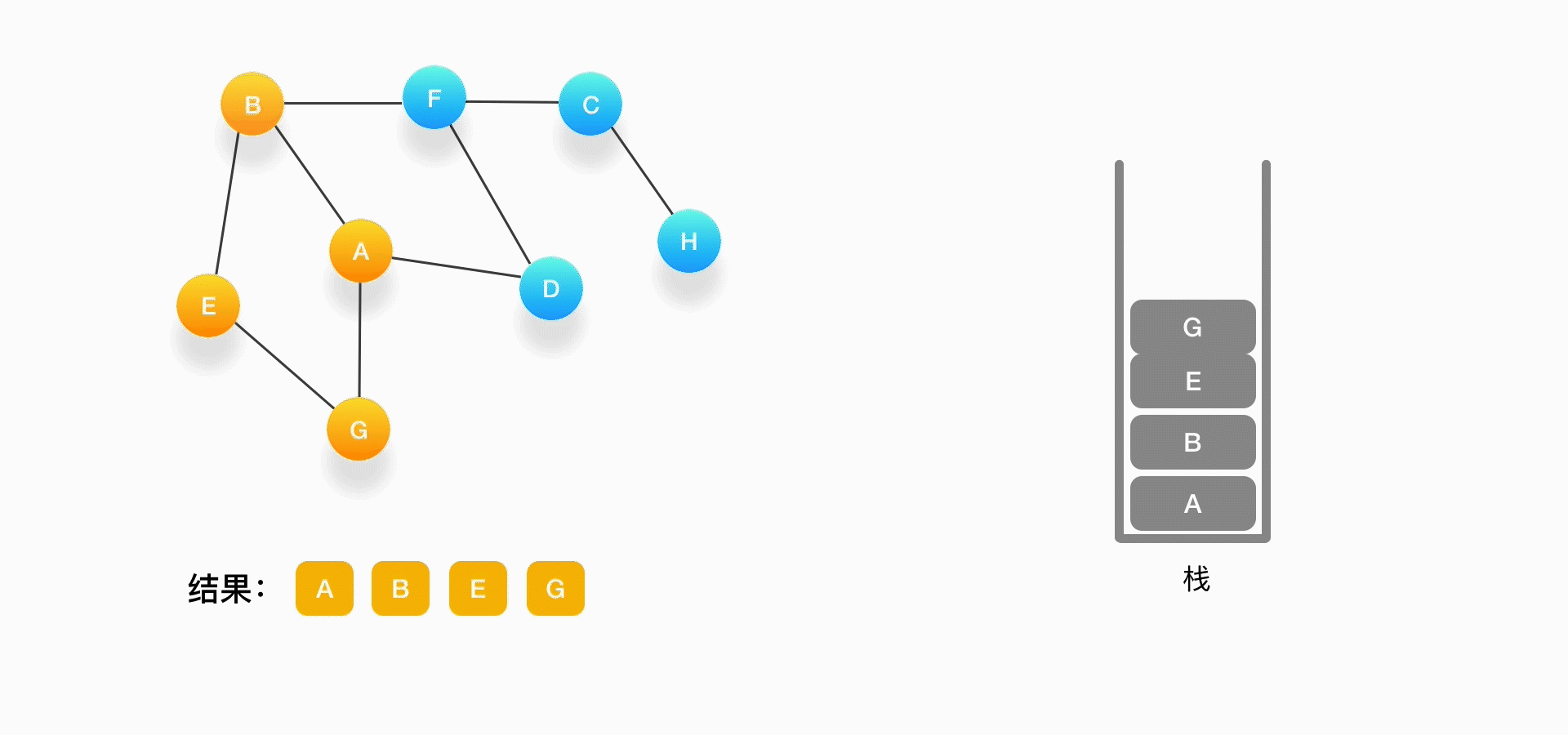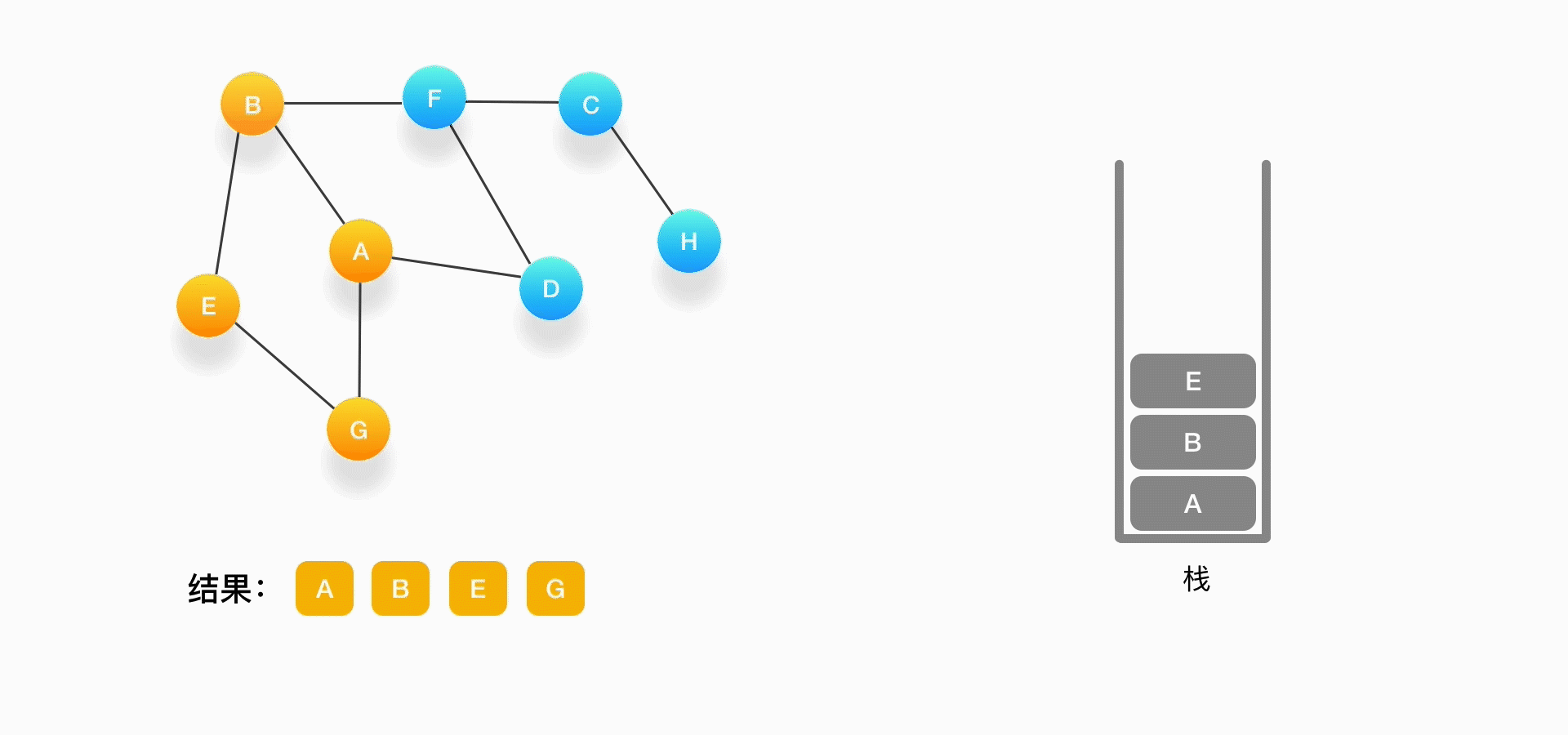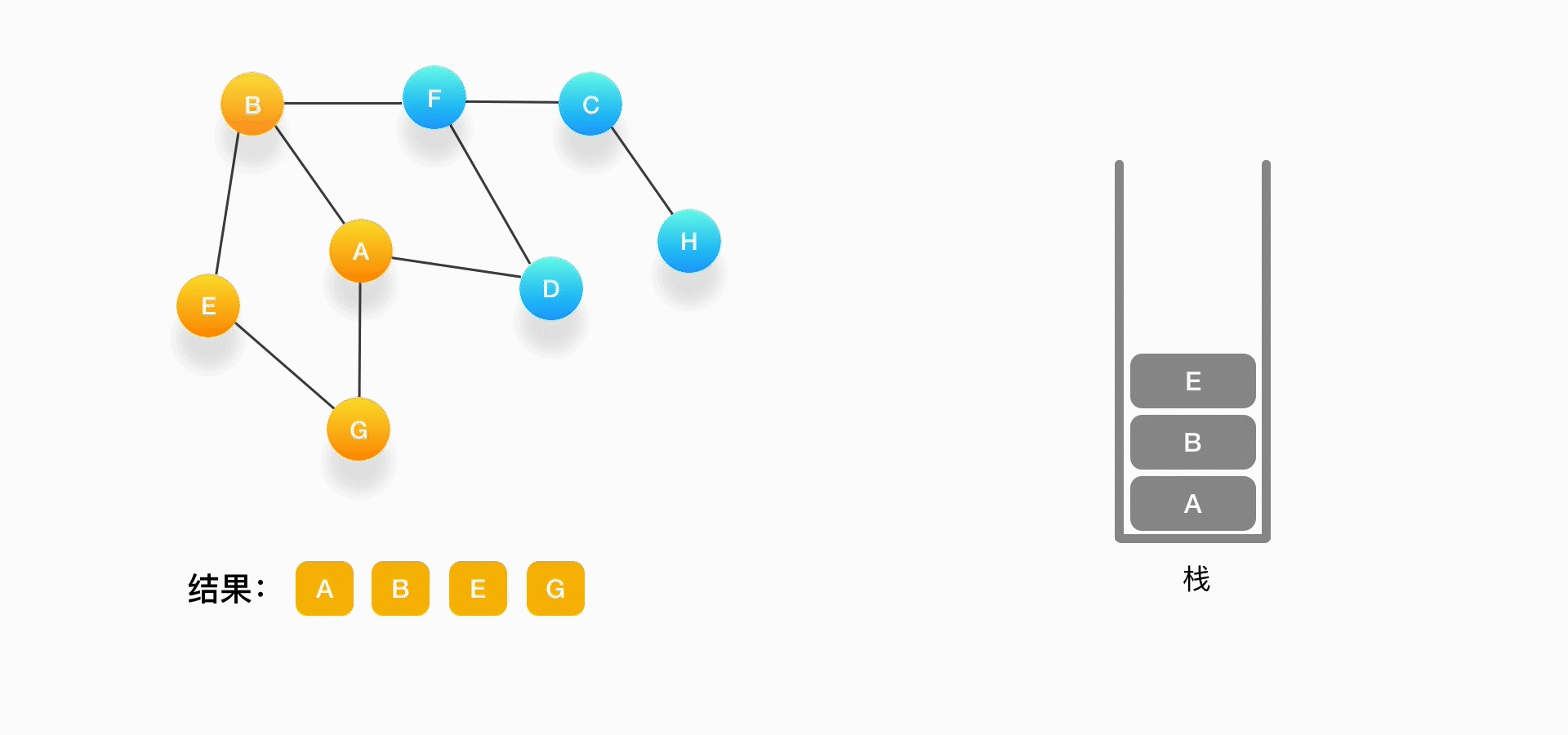
可以看到,每次我们在考虑下一个要被访问的点是什么的时候,如果发现周围的顶点都被访问了,就把当前的顶点弹出。
第六步,现在栈的顶部记录的是顶点 E,我们来看看与 E 相连的顶点中有没有还没被访问到的,发现它们都被访问了,所以把 E 也弹出去。
第七步,当前栈的顶点是 B,看看它周围有没有还没被访问的顶点,有,是顶点 F,于是把 F 压入栈,标记它为访问过,并输出到结果中。
第八步,当前顶点是 F,与 F 相连并且还未被访问到的点是 C 和 D,按照字母顺序来,下一个被访问的点是 C,将 C 压入栈,标记为访问过,输出到结果中。
第九步,当前顶点为 C,与 C 相连并尚未被访问到的顶点是 H,将 H 压入栈,标记为访问过,输出到结果中。
第十步,当前顶点是 H,由于和它相连的点都被访问过了,将它弹出栈。
第十一步,当前顶点是 C,与 C 相连的点都被访问过了,将 C 弹出栈。
第十二步,当前顶点是 F,与 F 相连的并且尚未访问的点是 D,将 D 压入栈,输出到结果中,并标记为访问过。
第十三步,当前顶点是 D,与它相连的点都被访问过了,将它弹出栈。以此类推,顶点 F,B,A 的邻居都被访问过了,将它们依次弹出栈就好了。最后,当栈里已经没有顶点需要处理了,我们的整个遍历结束。
例题分析一
给定一个二维矩阵代表一个迷宫,迷宫里面有通道,也有墙壁,通道由数字 0 表示,而墙壁由 -1 表示,有墙壁的地方不能通过,那么,能不能从 A 点走到 B 点。
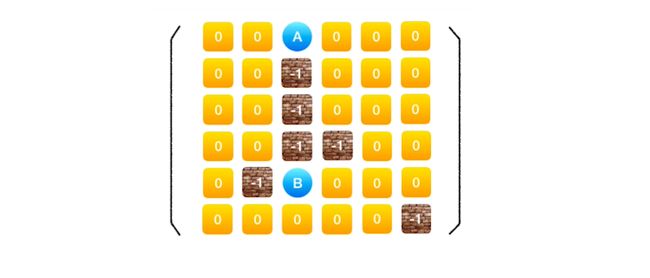
从 A 开始走的话,有很多条路径通往 B,例如下面两种。
代码实现
根据例题,来看实现代码,如下。
boolean dfs(int maze[][], int x, int y) {
// 第一步:判断是否找到了B
if (x == B[0] && y == B[1]) {
return true;
}
// 第二步:标记当前的点已经被访问过
maze[x][y] = -1;
// 第三步:在四个方向上尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
// 第四步:如果有一条路径被找到了,返回true
if (isSafe(maze, i, j) && dfs(maze, i, j)) {
return true;
}
}
// 付出了所有的努力还是没能找到B,返回false
return false;
}
非递归实现
递归实现:
代码看上去很简洁;
实际应用中,递归需要压入和弹出栈,栈深的时候会造成运行效率低下。
非递归实现:
栈支持压入和弹出;
栈能提高效率。
代码实现
boolean dfs(int maze[][], int x, int y) {
// 创建一个Stack
Stack
// 将起始点压入栈,标记它访问过
stack.push(new Integer[] {x, y});
maze[x][y] = -1;
while (!stack.isEmpty()) {
// 取出当前点
Integer[] pos = stack.pop();
x = pos[0]; y = pos[1];
// 判断是否找到了目的地
if (x == B[0] && y == B[1]) {
return true;
}
// 在四个方向上尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
if (isSafe(maze, i, j)) {
stack.push(new Integer[] {i, j});
maze[i][j] = -1;
}
}
}
return false;
}
//DFS与BFS 打通墙的问题
#include
#include
#include
using namespace std;
int a[6][6] =
{{0,0,1,0,0,0},
{0,0,-1,0,0,0},
{0,0,-1,0,0,0},
{0,0,-1,-1,0,0},
{-1,-1,1,0,0,0},
{0,0,0,0,0,-1}};
int A = a[0][2];
int B = a[4][2];
//int s = A[0];
int dx[4] = {0,0,-1,1}; //我在这里设置的顺序是,左右上下
int dy[4] = {-1,1,0,0};
bool isSafe(int maze[6][6], int x, int y) {
if(maze[x][y] !=-1&&x>=0&&y>=0&&y<6&&x<6)
return true;
return false;
}
int num = 0;
bool dfs(int maze[6][6], int x, int y) {
//第一步 判断是否找到目的节点
num++;
if(x == 4 && y == 2) {
return true;
}
//第二步 标记当前节点已经被访问过
//cout< s;
stack m;
stack n;
s.push(maze[x][y]);
m.push(x);
n.push(y);
maze[x][y] = -1;
while(!s.empty()) {
int pop1 = s.top();
x = m.top();
y = n.top();
cout<
算法分析
DFS 是图论里的算法,分析利用 DFS 解题的复杂度时,应当借用图论的思想。图有两种表示方式:邻接表、邻接矩阵。假设图里有 V 个顶点,E 条边。
时间复杂度:
邻接表
访问所有顶点的时间为 O(V),而查找所有顶点的邻居一共需要 O(E) 的时间,所以总的时间复杂度是 O(V + E)。
邻接矩阵
查找每个顶点的邻居需要 O(V) 的时间,所以查找整个矩阵的时候需要 O(V2) 的时间。
举例:利用 DFS 在迷宫里找一条路径的复杂度。迷宫是用矩阵表示。
解法:把迷宫看成是邻接矩阵。假设矩阵有 M 行 N 列,那么一共有 M × N 个顶点,因此时间复杂度就是 O(M × N)。
空间复杂度:
DFS 需要堆栈来辅助,在最坏情况下,得把所有顶点都压入堆栈里,所以它的空间复杂度是 O(V),即 O(M × N)。
例题分析二
例题:利用 DFS 去寻找最短的路径。
解题思路
思路 1:暴力法。
寻找出所有的路径,然后比较它们的长短,找出最短的那个。此时必须尝试所有的可能。因为 DFS 解决的只是连通性问题,不是用来求解最短路径问题的。
思路 2:优化法。
一边寻找目的地,一边记录它和起始点的距离(也就是步数)。
从某方向到达该点所需要的步数更少,则更新。
从各方向到达该点所需要的步数都更多,则不再尝试。
代码实现
void solve(int maze[][]) {
// 第一步. 除了A之外,将其他等于0的地方用MAX_VALUE替换
for (int i = 0; i < maze.length; i++) {
for (int j = 0; j < maze[0].length; j++) {
if (maze[i][j] == 0 && !(i == A[0] && j == A[1])) {
maze[i][j] = Integer.MAX_VALUE;
}
}
}
// 第二步. 进行优化的DFS操作
dfs(maze, A[0], A[1]);
// 第三步. 看看是否找到了目的地
if (maze[B[0]][B[1]] < Integer.MAX_VALUE) {
print("Shortest path count is: " + maze[B[0]][B[1]]);
} else {
print("Cannot find B!");
}
}
void dfs(int maze[][], int x, int y) {
// 第一步. 判断是否找到了B
if (x == B[0] && y == B[1]) return;
// 第二步. 在四个方向上尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
// 判断下一个点的步数是否比目前的步数+1还要大
if (isSafe(maze, i, j) && maze[i][j] > maze[x][y] + 1) {
// 如果是,就更新下一个点的步数,并继续DFS下去
maze[i][j] = maze[x][y] + 1;
dfs(maze, i, j);
}
}
}
void dfs2(int maze[6][6], int x, int y) {
// 第一步. 判断是否找到了B
if(x == 4 && y == 2) return;
// 第二步. 在四个方向上尝试
for(int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
// 判断下一个点的步数是否比目前的步数+1还要大
if (isSafe(maze, i, j) && maze[i][j] > maze[x][y] + 1) {
// 如果是,就更新下一个点的步数,并继续DFS下去
maze[i][j] = maze[x][y] + 1;
dfs2(maze, i, j);
}
}
}
void solve(int maze[6][6]) {
for(int i = 0; i < 6; i++) {
for(int j = 0; j < 6; j++) {
if(maze[i][j] == 0 &&!(i == 0&&j==2)) {
maze[i][j] = 10000;
}
}
}
dfs2(a,0,2);
// 第三步. 看看是否找到了目的地
if (maze[4][2] <10000 ){
cout<<"Shortest path count is: " << maze[4][2]<
注意:之前的题目只要找到了一个路径就返回,这里我们必须尽可能多的去尝试,直到找到最短路径。
运行结果
当程序运行完毕之后,矩阵的最终结果如下。
2 1 0 1 2 3
3 2 -1 2 3 4
4 3 -1 3 4 5
5 4 -1 -1 5 6
-1 -1 8 7 6 7
11 10 9 8 7 -1
可以看到,矩阵中每个点的数值代表着它离 A 点最近的步数。
广度优先搜索(Breadth-First Search / BFS)
广度优先搜索,一般用来解决最短路径的问题。和深度优先搜索不同,广度优先的搜索是从起始点出发,一层一层地进行,每层当中的点距离起始点的步数都是相同的,当找到了目的地之后就可以立即结束。
广度优先的搜索可以同时从起始点和终点开始进行,称之为双端 BFS。这种算法往往可以大大地提高搜索的效率。
举例:在社交应用程序中,两个人之间需要经过多少个朋友的介绍才能互相认识对方。
解法:
只从一个方向进行 BFS,有时候这个人认识的朋友特别多,那么会导致搜索起来非常慢;
如果另外一方认识的人比较少,从这一方进行搜索,就能极大地减少搜索的次数;
每次在决定从哪一边进行搜索的时候,要判断一下哪边认识的人比较少,然后从那边进行搜索。
BFS 遍历
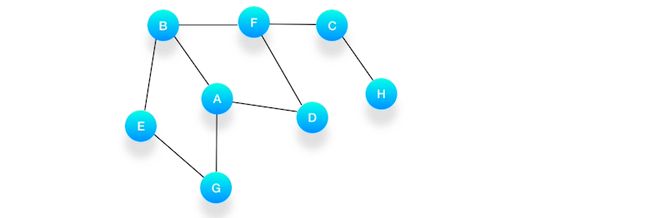
例题:假设我们有这么一个图,里面有A、B、C、D、E、F、G、H 8 个顶点,点和点之间的联系如下图所示,对这个图进行深度优先的遍历。
解题思路
依赖队列(Queue),先进先出(FIFO)。
一层一层地把与某个点相连的点放入队列中,处理节点的时候正好按照它们进入队列的顺序进行。
第一步,选择一个起始顶点,让我们从顶点 A 开始。把 A 压入队列,标记它为访问过(用红色标记)。
第二步,从队列的头取出顶点 A,打印输出到结果中,同时将与它相连的尚未被访问过的点按照字母大小顺序压入队列,同时把它们都标记为访问过,防止它们被重复地添加到队列中。
第三步,从队列的头取出顶点 B,打印输出它,同时将与它相连的尚未被访问过的点(也就是 E 和 F)压入队列,同时把它们都标记为访问过。
第四步,继续从队列的头取出顶点 D,打印输出它,此时我们发现,与 D 相连的顶点 A 和 F 都被标记访问过了,所以就不要把它们压入队列里。
第五步,接下来,队列的头是顶点 G,打印输出它,同样的,G 周围的点都被标记访问过了。我们不做任何处理。
第六步,队列的头是 E,打印输出它,它周围的点也都被标记为访问过了,我们不做任何处理。
第七步,接下来轮到顶点 F,打印输出它,将 C 压入队列,并标记 C 为访问过。
第八步,将 C 从队列中移出,打印输出它,与它相连的 H 还没被访问到,将 H 压入队列,将它标记为访问过。
第九步,队列里只剩下 H 了,将它移出,打印输出它,发现它的邻居都被访问过了,不做任何事情。
第十步,队列为空,表示所有的点都被处理完毕了,程序结束。
例题分析一
运用广度优先搜索的算法在迷宫中寻找最短的路径。
解题思路
搜索的过程如下。
从起始点 A 出发,类似于涟漪,一层一层地扫描,避开墙壁,同时把每个点与 A 的距离或者步数标记上。当找到目的地的时候返回步数,这个步数保证是最短的。
代码实现
void bfs(int[][] maze, int x, int y) {
// 创建一个队列queue,将起始点A加入队列中
Queue
queue.add(new Integer[] {x, y});
// 只要队列不为空就一直循环下去
while (!queue.isEmpty()) {
// 从队列的头取出当前点
Integer[] pos = queue.poll();
x = pos[0]; y = pos[1];
// 从四个方向进行BFS
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
if (isSafe(maze, i, j)) {
// 记录步数(标记访问过)
maze[i][j] = maze[x][y] + 1;
// 然后添加到队列中
queue.add(new Integer[] {i, j});
// 如果发现了目的地就返回
if (i == B[0] && j == B[1]) return;
}
}
}
}
算法分析
同样借助图论的分析方法,假设有 V 个顶点,E 条边。
时间复杂度:
邻接表
每个顶点都需要被访问一次,时间复杂度是 O(V);相连的顶点(也就是每条边)也都要被访问一次,加起来就是 O(E)。因此整体时间复杂度就是 O(V+E)。
邻接矩阵
V 个顶点,每次都要检查每个顶点与其他顶点是否有联系,因此时间复杂度是 O(V2)。
举例:在迷宫里进行 BFS 搜索。
解法:用邻接矩阵。假设矩阵有 M 行 N 列,那么一共有 M×N 个顶点,时间复杂度就是 O(M×N)。
空间复杂度:
需要借助一个队列,所有顶点都要进入队列一次,从队列弹出一次。在最坏的情况下,空间复杂度是 O(V),即 O(M×N)。
//DFS与BFS 打通墙的问题
#include
#include
#include
#include
using namespace std;
int a[6][6] =
{{0,0,0,0,0,0},
{0,0,-1,0,0,0},
{0,0,-1,0,0,0},
{0,0,-1,-1,0,0},
{0,-1,0,0,0,0},
{0,0,0,0,0,-1}};
int A = a[0][2];
int B = a[4][2];
int b[6][6] = {0};
//int s = A[0];
int dx[4] = {0,0,-1,1}; //我在这里设置的顺序是,左右上下
int dy[4] = {-1,1,0,0};
bool isSafe(int maze[6][6], int x, int y) {
if(maze[x][y] !=-1&&x>=0&&y>=0&&y<6&&x<6)
return true;
return false;
}
int num = 0;
bool dfs(int maze[6][6], int x, int y) {
//第一步 判断是否找到目的节点
num++;
if(x == 4 && y == 2) {
return true;
}
//第二步 标记当前节点已经被访问过
//cout< s;
stack m;
stack n;
s.push(maze[x][y]);
m.push(x);
n.push(y);
maze[x][y] = -1;
while(!s.empty()) {
int pop1 = s.top();
x = m.top();
y = n.top();
cout< maze[x][y] + 1) {
// 如果是,就更新下一个点的步数,并继续DFS下去
maze[i][j] = maze[x][y] + 1;
dfs2(maze, i, j);
}
}
}
void solve(int maze[6][6]) {
for(int i = 0; i < 6; i++) {
for(int j = 0; j < 6; j++) {
if(maze[i][j] == 0 &&!(i == 0&&j==2)) {
maze[i][j] = 10000;
}
}
}
dfs2(a,0,2);
// 第三步. 看看是否找到了目的地
if (maze[4][2] < 10000) {
cout<<"Shortest path count is: " << maze[4][2]< q;
queue m;
queue n;
q.push(maze[x][y]);
m.push(x);
n.push(y);
while(!q.empty()) {
//cout<
//下面的内容暂没有研究
例题分析二
例题:假设从起始点 A 走到目的地 B 的过程中,最多允许打通 3 堵墙,求最短的路径的步数。(这个题目可以扩展到允许打通任意数目的墙。)
解题思路
思路 1:暴力法。
1. 首先枚举出所有拆墙的方法.
假设一共有 K 堵墙在当前的迷宫里,最多允许拆 3 堵墙,有四种情况:不拆,只拆一堵墙、两堵墙、三堵墙。组合方式如下。
C(K, 0) + C(K, 1) + C(K, 2) + C(K, 3) = 1 + K + K ×(K - 1) / 2 + K× (K - 1) ×(K - 2) / 6
上式复杂度为 K 的 3 次方,如果允许打通墙的数量是 w,那么就是 K 的 w 次方。
2. 分别进行 BFS,整体的时间复杂度就是 O(n2×Kw),从中找到最短的那条路径。
很显然,该方法非常没有效率。
思路 2:
1. 将 BFS 的数量减少。
在不允许打通墙的情况下,只有一个人进行 BFS 搜索,时间复杂度是 n2;
允许打通一堵墙的情况下,分身为两个人进行 BFS 搜索,时间复杂度是 2×n2;
允许打通两堵墙的情况下,分身为三个人进行 BFS 搜索,时间复杂度是 3×n2;
允许打通三堵墙的情况下,分身为四个人进行 BFS 搜索,时间复杂度是 4×n2。
2. 解决关键问题。
如果第一个人又遇到了一堵墙,那么他是否需要再次分身呢?不能。
第一个人怎么告诉第二个人可以去访问这个点?把这个点放入到队列中。
如何让 4 个人在独立的平面里搜索?利用一个三维矩阵记录每个层面里的点。
只需要 4 个人去做 BFS,整体的时间复杂度就是 4 倍的 BFS。
代码实现
int bfs(int[][] maze, int x, int y, int w) {
// 初始化
int steps = 0, z = 0;
// 利用队列来辅助BFS
Queue
queue.add(new Integer[] {x, y, z});
queue.add(null);
// 三维的visited记录各层平面中每个点是否被访问过
boolean[][][] visited = new boolean[N][N][w + 1];
visited[x][y][z] = true;
// 只要队列不为空就一直循环
while (!queue.isEmpty()) {
Integer[] pos = queue.poll();
if (pos != null) {
// 取出当前点
x = pos[0]; y = pos[1]; z = pos[2];
// 如果遇到了目的地就立即返回步数
if (x == B[0] && y == B[1]) {
return steps;
}
// 朝四个方向尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
if (!isSafe(maze, i, j, z, visited)) {
continue;
}
// 如果在当前层遇到了墙,尝试打通它
int k = getLayer(maze, w, i, j, z);
if (k >= 0) {
// 如果能打通墙,就在下一层尝试
visited[i][j][k] = true;
queue.add(new Integer[] {i, j, k});
}
}
} else {
steps++;
if (!queue.isEmpty()) {
queue.add(null);
}
}
}
return -1;
}
注意:
初始化队列的时候,除了把在第一层里的起始点 A 加入到队列中,还加入了一个 null,这是使用 BFS 的一个小技巧,用来帮助我们计算当前遍历了多少步数。
其中,利用 getLayer 函数判断是否遇到了墙壁,以及是否能打通墙壁到下一层。
最后,如果当前点是 null,表明已经处理完当前的步数,继续下一步。
getLayer 函数的代码实现如下。
int getLayer(int[][] maze, int w, int x, int y, int z) {
if (maze[x][y] == -1) {
return z < w ? z + 1 : -1;
}
return z;
}
getLayer 的思想很简单,如果当前遇到的是一堵墙,那么看打通的墙壁个数是否已经超出了规定,如果没有,就继续打通它,否则返回 -1。另外,如果当前遇到的不是一堵墙,就继续在当前的平面里进行 BFS。
结语
这节课学习了深度优先和广度优先这两种搜索算法。它们都是算法面试中常考的知识点。建议对二者比较学习。
LeetCode 上对 DFS 以及 BFS 有非常好的分类和题库,而且对于时间复杂度和空间复杂度都有考察,是很好的练手的平台,希望大家多多练习。
#开始刷leetcode 深度优先和宽度优先的题目