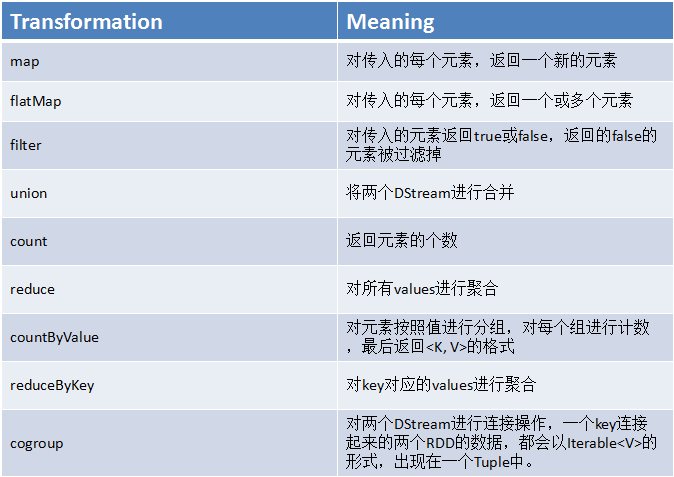
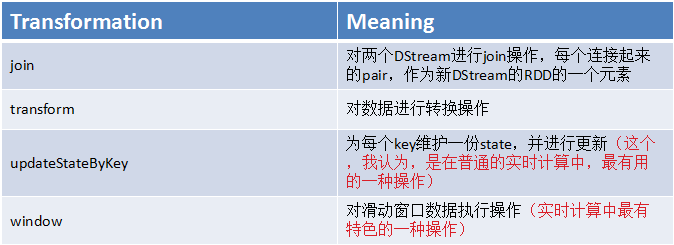
1、updateStateByKey
作用
可以让我们为每个key维护一份state,并持续不断的更新该state;使用
1、首先,要定义一个state,可以是任意的数据类型;
2、其次,要定义state更新函数——指定一个函数如何使用之前state和新值来更新state;注意:
1、对于每个batch,Spark都会为每个之前已经存在的key去应用一次state更新函数,无论这个key在batch中是否有新的数据;
2、如果state更新函数返货none,那么key对应state就会被删除;
3、对于每个新出现的key,也会执行state更新函数;
4、updateStateByKey操作,要求必须开启Checkpoint机制;Demo
package cn.spark.study.streaming;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import com.google.common.base.Optional;
import scala.Tuple2;
/**
* 基于updateStateByKey算子实现缓存机制的实时wordcount程序
*/
public class UpdateStateByKeyWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("UpdateStateByKeyWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
// 如果要使用updateStateByKey算子,就必须设置一个checkpoint目录,开启checkpoint机制
// 因为要长期保存一份key的state的话,那么spark streaming是要求必须用checkpoint的,
//以便于在内存数据丢失的时候,可以从checkpoint中恢复数据
// 开启checkpoint机制
jssc.checkpoint("hdfs://spark1:9000/wordcount_checkpoint");
// 然后先实现wordcount逻辑
JavaReceiverInputDStream lines = jssc.socketTextStream("localhost", 9999);
JavaDStream words = lines.flatMap(new FlatMapFunction() {
private static final long serialVersionUID = 1L;
@Override
public Iterable call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairDStream pairs = words.mapToPair(
new PairFunction() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(String word)
throws Exception {
return new Tuple2(word, 1);
}
});
// 关键点在这里,之前的话,直接就是pairs.reduceByKey
// 然后,就可以得到每个时间段的batch对应的RDD,计算出来的单词计数
// 然后,可以打印出那个时间段的单词计数
// 但是,如果要统计每个单词的全局的计数呢?
// 就是说,统计从程序启动开始,到现在为止,一个单词出现的次数,那么就之前的方式就不好实现
// 就必须基于redis这种缓存,或者是mysql这种db,来实现累加
// 但是,我们的updateStateByKey,就可以实现直接通过Spark维护一份每个单词的全局的统计次数
JavaPairDStream wordCounts = pairs.updateStateByKey(
// 这里的Optional,相当于Scala中的样例类,就是Option,
// 可以这么理解,它代表了一个值的存在状态,可能存在,也可能不存在
new Function2, Optional, Optional>() {
private static final long serialVersionUID = 1L;
// 这里两个参数
// 实际上,对于每个单词,每次batch计算的时候,都会调用这个函数
// 第一个参数,values,相当于是这个batch中,这个key的新的值,可能有多个
// 比如说一个hello,可能有2个,(hello, 1) (hello, 1),那么传入的是(1,1)
// 第二个参数,就是指的是这个key之前的状态,state,其中泛型的类型是你自己指定的
@Override
public Optional call(List values,
Optional state) throws Exception {
// 首先定义一个全局的单词计数
Integer oldValue = 0;
// 其次,判断,state是否存在,如果不存在,说明是一个key第一次出现
// 如果存在,说明这个key之前已经统计过全局的次数了
if(state.isPresent()) {
oldValue = state.get();
}
// 接着,将本次新出现的值,都累加到newValue上去,就是一个key目前的全局的统计
// 次数
for(Integer value : values) {
oldValue += value;
}
return Optional.of(oldValue );
}
});
// 到这里为止,相当于是,每个batch过来先计算到pairs DStream,
// 然后就会执行全局的updateStateByKey算子,updateStateByKey返回的JavaPairDStream,
// 其实就代表了每个key的全局的计数
wordCounts.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}
package cn.spark.study.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
object UpdateStateByKeyWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("UpdateStateByKeyWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("hdfs://spark1:9000/wordcount_checkpoint")
val lines = ssc.socketTextStream("spark1", 9999)
val words = lines.flatMap { _.split(" ") }
val pairs = words.map { word => (word, 1) }
val wordCounts = pairs.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
var oldValue = state.getOrElse(0)
for(value <- values) {
oldValue += value
}
Option(oldValue )
})
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
2、transform
transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作;
它可以用于实现,DStream API中所没有提供的操作;比如说,DStream API中,并没有提供将一个DStream中的每个batch,与一个特定的RDD进行join的操作。但是我们自己就可以使用transform操作来实现该功能。
DStream.join(),只能join其他DStream,表示在DStream每个batch的RDD计算出来之后,会去跟其他DStream的RDD进行join。
package cn.spark.study.streaming;
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import com.google.common.base.Optional;
import scala.Tuple2;
/**
* 基于transform的实时广告计费日志黑名单过滤
* 用户对我们的网站上的广告可以进行点击
* 点击之后,要进行实时计费,点一下,算一次钱
* 但是,对于那些帮助某些无良商家刷广告的人,那么我们有一个黑名单
* 只要是黑名单中的用户点击的广告,我们就给过滤掉
*/
public class TransformBlacklist {
@SuppressWarnings("deprecation")
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("TransformBlacklist");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
// 先做一份模拟的黑名单RDD
List> blacklist = new ArrayList>();
blacklist.add(new Tuple2("tom", true));
final JavaPairRDD blacklistRDD = jssc.sc().parallelizePairs(blacklist);
// 这里的日志格式,简化一下,就是date username的方式
JavaReceiverInputDStream adsClickLogDStream = jssc.socketTextStream("hadoop1", 9999);
// 所以,要先对输入的数据,进行一下转换操作,变成(username, date username)
// 以便于后面对每个batch RDD,与定义好的黑名单RDD进行join操作
JavaPairDStream userAdsClickLogDStream = adsClickLogDStream.mapToPair(
new PairFunction() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(String adsClickLog)
throws Exception {
return new Tuple2(
adsClickLog.split(" ")[1], adsClickLog);
}
});
// 然后,执行transform操作,将每个batch的RDD,与黑名单RDD进行join、filter、map等操作
// 实时进行黑名单过滤
JavaDStream validAdsClickLogDStream = userAdsClickLogDStream.transform(
new Function, JavaRDD>() {
private static final long serialVersionUID = 1L;
@Override
public JavaRDD call(JavaPairRDD userAdsClickLogRDD)
throws Exception {
// 这里为什么用左外连接?
// 因为,并不是每个用户都存在于黑名单中的
// 所以,如果直接用join,那么没有存在于黑名单中的数据,会无法join到
// 就给丢弃掉了
// 所以,这里用leftOuterJoin,就是说,哪怕一个user不在黑名单RDD中,没有join到
// 也还是会被保存下来的
JavaPairRDD>> joinedRDD =
userAdsClickLogRDD.leftOuterJoin(blacklistRDD);
// 连接之后,执行filter算子
JavaPairRDD>> filteredRDD =
joinedRDD.filter(
new Function>>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(
Tuple2>> tuple)
throws Exception {
// 这里的tuple,就是每个用户,对应的访问日志,和在黑名单中
// 的状态
if(tuple._2._2().isPresent() &&
tuple._2._2.get()) {
return false;
}
return true;
}
});
// 此时,filteredRDD中,就只剩下没有被黑名单过滤的用户点击了
// 进行map操作,转换成我们想要的格式
JavaRDD validAdsClickLogRDD = filteredRDD.map(
new Function>>, String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(
Tuple2>> tuple)
throws Exception {
return tuple._2._1;
}
});
return validAdsClickLogRDD;
}
});
// 打印有效的广告点击日志
// 其实在真实企业场景中,这里后面就可以走写入kafka、ActiveMQ等这种中间件消息队列
// 然后再开发一个专门的后台服务,作为广告计费服务,执行实时的广告计费,这里就是只拿到了有效的广告点击
validAdsClickLogDStream.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}
package cn.spark.study.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
object TransformBlacklist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("TransformBlacklist")
val ssc = new StreamingContext(conf, Seconds(5))
val blacklist = Array(("tom", true))
val blacklistRDD = ssc.sparkContext.parallelize(blacklist, 5)
val adsClickLogDStream = ssc.socketTextStream("spark1", 9999)
val userAdsClickLogDStream = adsClickLogDStream
.map { adsClickLog => (adsClickLog.split(" ")(1), adsClickLog) }
val validAdsClickLogDStream = userAdsClickLogDStream.transform(userAdsClickLogRDD => {
val joinedRDD = userAdsClickLogRDD.leftOuterJoin(blacklistRDD)
val filteredRDD = joinedRDD.filter(tuple => {
if(tuple._2._2.getOrElse(false)) {
false
} else {
true
}
})
val validAdsClickLogRDD = filteredRDD.map(tuple => tuple._2._1)
validAdsClickLogRDD
})
validAdsClickLogDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
3、window滑动窗口
Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。比如下图中,就是对每三秒钟的数据执行一次滑动窗口计算,这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。(Spark Streaming对滑动窗口的支持,是比Storm更加完善和强大的)
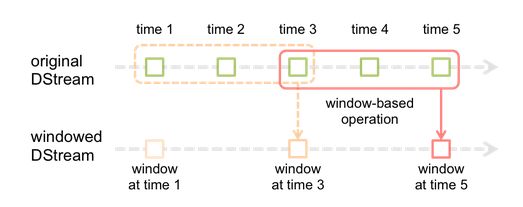

Demo:热点搜索词滑动统计,每隔10秒钟,统计最近60秒钟的搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及出现次数
package cn.spark.study.streaming;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
/**
* 基于滑动窗口的热点搜索词实时统计
*/
public class WindowHotWord {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
// 这里的搜索日志的格式是
// leo hello
// tom world
JavaReceiverInputDStream searchLogsDStream = jssc.socketTextStream("spark1", 9999);
// 将搜索日志给转换成,只有一个搜索词,即可
JavaDStream searchWordsDStream = searchLogsDStream.map(new Function() {
private static final long serialVersionUID = 1L;
@Override
public String call(String searchLog) throws Exception {
return searchLog.split(" ")[1];
}
});
// 将搜索词映射为(searchWord, 1)的tuple格式
JavaPairDStream searchWordPairDStream = searchWordsDStream.mapToPair(
new PairFunction() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(String searchWord)
throws Exception {
return new Tuple2(searchWord, 1);
}
});
// 针对(searchWord, 1)的tuple格式的DStream,执行reduceByKeyAndWindow,滑动窗口操作
// 第二个参数,是窗口长度,这里是60秒
// 第三个参数,是滑动间隔,这里是10秒
// 也就是说,每隔10秒钟,将最近60秒的数据,作为一个窗口,进行内部的RDD的聚合,
// 然后统一对一个RDD进行后续计算
// 所以,到之前的searchWordPairDStream为止,其实,都是不会立即进行计算的
// 而是只是放在那里
// 然后,等待我们的滑动间隔到了以后,10秒钟到了,会将之前60秒的RDD,因为一个batch间隔是,5秒,
//所以之前 60秒,就有12个RDD,给聚合起来,然后,统一执行redcueByKey操作
// 所以这里的reduceByKeyAndWindow,是针对每个窗口执行计算的,而不是针对某个DStream中的RDD
JavaPairDStream searchWordCountsDStream =
searchWordPairDStream.reduceByKeyAndWindow(new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}, Durations.seconds(60), Durations.seconds(10));
// 把之前60秒收集到的单词的统计次数执行transform操作,
// 因为,一个窗口,就是一个60秒钟的数据,会变成一个RDD,然后,对这一个RDD
// 根据每个搜索词出现的频率进行排序,然后获取排名前3的热点搜索词
JavaPairDStream finalDStream = searchWordCountsDStream.transformToPair(
new Function, JavaPairRDD>() {
private static final long serialVersionUID = 1L;
@Override
public JavaPairRDD call(
JavaPairRDD searchWordCountsRDD) throws Exception {
// 执行搜索词和出现频率的反转
JavaPairRDD countSearchWordsRDD = searchWordCountsRDD
.mapToPair(new PairFunction, Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(
Tuple2 tuple)
throws Exception {
return new Tuple2(tuple._2, tuple._1);
}
});
// 然后执行降序排序
JavaPairRDD sortedCountSearchWordsRDD = countSearchWordsRDD
.sortByKey(false);
// 然后再次执行反转,变成(searchWord, count)的这种格式
JavaPairRDD sortedSearchWordCountsRDD = sortedCountSearchWordsRDD
.mapToPair(new PairFunction, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(
Tuple2 tuple)
throws Exception {
return new Tuple2(tuple._2, tuple._1);
}
});
// 然后用take(),获取排名前3的热点搜索词
List> hogSearchWordCounts =
sortedSearchWordCountsRDD.take(3);
for(Tuple2 wordCount : hogSearchWordCounts) {
System.out.println(wordCount._1 + ": " + wordCount._2);
}
return searchWordCountsRDD;
}
});
// 这个无关紧要,只是为了触发job的执行,所以必须有output操作
finalDStream.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}
package cn.spark.study.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
object WindowHotWord {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord")
val ssc = new StreamingContext(conf, Seconds(1))
val searchLogsDStream = ssc.socketTextStream("spark1", 9999)
val searchWordsDStream = searchLogsDStream.map { _.split(" ")(1) }
val searchWordPairsDStream = searchWordsDStream.map { searchWord => (searchWord, 1) }
val searchWordCountsDSteram = searchWordPairsDStream.reduceByKeyAndWindow(
(v1: Int, v2: Int) => v1 + v2,
Seconds(60),
Seconds(10))
val finalDStream = searchWordCountsDSteram.transform(searchWordCountsRDD => {
val countSearchWordsRDD = searchWordCountsRDD.map(tuple => (tuple._2, tuple._1))
val sortedCountSearchWordsRDD = countSearchWordsRDD.sortByKey(false)
val sortedSearchWordCountsRDD = sortedCountSearchWordsRDD.map(tuple => (tuple._1, tuple._2))
val top3SearchWordCounts = sortedSearchWordCountsRDD.take(3)
for(tuple <- top3SearchWordCounts) {
println(tuple)
}
searchWordCountsRDD
})
finalDStream.print()
ssc.start()
ssc.awaitTermination()
}
}