简介: 说到散列,一般对应于散列表(哈希表)和散列函数。 我们今天不谈哈希表,仅谈下散列函数。
说到散列,一般对应于散列表(哈希表)和散列函数。
我们今天不谈哈希表,仅谈下散列函数。
定义
引一段百度百科关于散列函数的定义。
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。
这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
关于散列函数的定义有很多表述,大同小异,理解其概念和内涵即可。
性质
1、确定性
如果两个散列值是不相同的,那么这两个散列值的原始输入也是不相同的;
2、冲突(碰撞)
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同;
3、不可逆性
最后一个是关于是否可逆的,两者表述有所出入: 

维基百科中,很明确地提出“散列函数必须具有不可逆性”,而百度百科的表述则模棱两可,相比之下,后者显得太不严谨了。
笔者比较倾向于维基百科提到的不可逆性。
4、混淆性
在“散列函数的性质”一节,维基百科还提到一点:
输入一些数据计算出散列值,然后部分改变输入值,一个具有强混淆特性的散列函数会产生一个完全不同的散列值。
该表述中有两个词:“强混淆”, “完全不同”。就是什么含义呢?
先来了解一个概念:雪崩效应
其精髓在于“严格雪崩准则”:当任何一个输入位被反转时,输出中的每一位均有50%的概率发生变化。
再了解一个概念:Hamming distance。
有的译作“海明距离”,有的则是“汉明距离”。名字不重要,重要的内涵。
两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。举例如下:10101和00110从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。
对应于散列,如果“部分改变输入值”, 前后两个两个散列的海明距离为散列长度的一半(也就是有一半的bit不相同),则为“50%的概率发生变化”。
这样的散列函数,就是“具有强混淆特性的散列函数”。
散列函数举例
常见的散列函数有MD5和SHA家族等加密散列函数,CRC也该也算是散列。
两者都有用于数据校验,而前者还用于数字签名,访问认证等安全领域。
不过我们今天不对加密散列做太多展开,主要讲讲下面两个散列:
BKDRHash
这个散列函数大家应该见过,可能有的读者不知道它的名字而已。
JDK中String的hashCode()就是这个散列函数实现的:
public int hashCode() {
int h = hash;
final int len = length();
if (h == 0 && len > 0) {
for (int i = 0; i < len; i++) {
h = 31 * h + charAt(i);
}
hash = h;
}
return h;
}定义一个类,如果让IDE自动生成hashCode()函数的话,其实现也是类似的:
public static class Foo{
int a;
double b;
String c;
@Override
public int hashCode() {
int result;
long temp;
result = a;
temp = Double.doubleToLongBits(b);
result = 31 * result + (int) (temp ^ (temp >>> 32));
result = 31 * result + (c != null ? c.hashCode() : 0);
return result;
}
}为什么总是跟“31”过不去呢?为什么要这样迭代地求积和求和呢?
这篇文章讲到了其中一些原理:哈希表之bkdrhash算法解析及扩展
而知乎上也有很多大神做了分析:hash算法的数学原理是什么,如何保证尽可能少的碰撞
从第二个链接给出的评分对比可以看出,BKDRHash虽然实现简单,但是很有效(冲突率低)。 
低冲突,使得BKDRHash不仅仅用于哈希表,还用于索引对象。
这样的用法,最常见的还是MD5,有的网站可能会用文件的MD5作为检索文件的key,
像DiskLruCache也是用MD5作为key, 不过通常不是对文件本身计算MD5,而是对url做MD5(例如OkHttp, Glide)。
MD5生成的消息摘要有128bit, 如果要标识的对象不多,冲突率会很低;
当冲突率远远低于硬件损坏的概率,那么可以认为用MD5作为key是可靠的。
对于网站,如果要存储海量文件,不建议用MD5作为key。
顺便提一下,UUID其实也是128bit的精度,只是其为了方便阅读多加了几个分割线而已。
扯远了, 回归正题~
之所以看到BKDRHash用来索引对象,主要是看到这篇文章(笔者没有研究过Volley源码):
Android Volley 源码解析(二),探究缓存机制
里面提到Volley缓存的key的设计:
private String getFilenameForKey(String key) {
int firstHalfLength = key.length() / 2;
String localFilename = String.valueOf(key.substring(0, firstHalfLength).hashCode());
localFilename += String.valueOf(key.substring(firstHalfLength).hashCode());
return localFilename;
}由于JDK的hashCode()返回值是int型,这个函数可以说是64bit精度的。
不能说它是散列函数,因为其返回值长度并不固定,按照定义,不能称之为散列函数,虽然思想很接近。
其等价写法如下:
public static String getFilenameForKey(String key) {
byte[] bytes = key.getBytes();
int h1 = 0, h2 = 0;
int len = bytes.length;
int firstHalfLength = len / 2;
for (int i = 0; i < firstHalfLength; i++) {
byte ch = bytes[i];
h1 = 31 * h1 + ch;
}
for (int i = firstHalfLength; i < len; i++) {
byte ch = bytes[i];
h2 = 31 * h2 + ch;
}
long hash = (((long) h1 << 32) & 0xFFFFFFFF00000000L) | ((long) h2 & 0xFFFFFFFFL);
return Long.toHexString(hash);
}效果大约等价于64bit精度的BKDRHash。
64bit的BKDRHash如下:
public static long BKDRHash(byte[] bytes) {
long seed = 1313; // 31 131 1313 13131 131313 etc..
long hash = 0;
int len = bytes.length;
for (int i = 0; i < len; i++) {
hash = (hash * seed) + bytes[i];
}
return hash;
}笔者编了程序比较其二者的冲突率,前者比后者要高一些(篇幅限制,不贴测试代码了,有兴趣的读者可自行测试)。
32bit的散列,无论哪一种,只要数据集(随机数据)上10^6, 基本上每次跑都会有冲突。
64bit的散列,只要性能不是太差,如果数据的长度是比较长的(比方说20个字节的随机数组),即使千万级别的数据集也很难出现冲突(笔者没有试过上亿的,机器撑不住)。
笔者曾经也是BKDRHash的拥趸,并在项目中使用了一段时间(作为缓存的key)。
直到看到上面那篇知乎的讨论,的一个回答: 
看了知乎心里一惊,回头修改了下测试用例,构造随机数据时用不定长的数据,比方说1-30个随机字节,
测试于上面写的64bitBKDRHash, 其结果是:
数据集上5万就可以看到冲突了。
之前是知道BKDRHash的混淆性不足的(比方说最后一个字节的值加1,hash值也只是加1而已,如果未溢出的话);
但是由于其实现简单,以及前面那个不合理的测试结果,就用来做缓存的key了,毕竟Volley也这么干了。
实际上也没有太大的问题,因为用的地方输入通常比较长,而且要缓存的文件也不是很多(几百上千的级别),所以应该不会有冲突。
但是心里面还是不踏实,最终还是很快换了另一个散列函数。
MurmurHash
初次看到这个散列函数,也是被它的名字雷到了。
不过也有觉得这个名字很“萌”的: 
不过有道是“人不可貌相”,算法也不可以名字来评判,还是要看其效果。
如截图所示,很多大名鼎鼎的开源组件都用到这个散列,那其究竟是何方神圣呢?让我们来一探究竟。
先看源码:https://sites.google.com/site/murmurhash/
源码是用C++写的:
uint64_t MurmurHash64A ( const void * key, int len, unsigned int seed )
{
const uint64_t m = 0xc6a4a7935bd1e995;
const int r = 47;
uint64_t h = seed ^ (len * m);
const uint64_t * data = (const uint64_t *)key;
const uint64_t * end = data + (len/8);
while(data != end)
{
uint64_t k = *data++;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
}
const unsigned char * data2 = (const unsigned char*)data;
switch(len & 7)
{
case 7: h ^= uint64_t(data2[6]) << 48;
case 6: h ^= uint64_t(data2[5]) << 40;
case 5: h ^= uint64_t(data2[4]) << 32;
case 4: h ^= uint64_t(data2[3]) << 24;
case 3: h ^= uint64_t(data2[2]) << 16;
case 2: h ^= uint64_t(data2[1]) << 8;
case 1: h ^= uint64_t(data2[0]);
h *= m;
};
h ^= h >> r;
h *= m;
h ^= h >> r;
return h;
} 总的来说也不是很复杂,BKDHHash相比,都是一遍循环的事。
而且C++可以将int64的指针指向char数组,可以一次算8个字节,对于长度较长的数组,运算更快。
而对于java来说,就相对麻烦一些了:
public static long hash64(final byte[] data) {
if (data == null || data.length == 0) {
return 0L;
}
final int len = data.length;
final long m = 0xc6a4a7935bd1e995L;
final long seed = 0xe17a1465;
final int r = 47;
long h = seed ^ (len * m);
int remain = len & 7;
int size = len - remain;
for (int i = 0; i < size; i += 8) {
long k = ((long) data[i+7] << 56) +
((long) (data[i + 6] & 0xFF) << 48) +
((long) (data[i + 5] & 0xFF) << 40) +
((long) (data[i + 4] & 0xFF) << 32) +
((long) (data[i + 3] & 0xFF) << 24) +
((data[i + 2] & 0xFF) << 16) +
((data[i + 1] & 0xFF) << 8) +
((data[i] & 0xFF));
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
switch (remain) {
case 7: h ^= (long)(data[size + 6] & 0xFF) << 48;
case 6: h ^= (long)(data[size + 5] & 0xFF) << 40;
case 5: h ^= (long)(data[size + 4] & 0xFF) << 32;
case 4: h ^= (long)(data[size + 3] & 0xFF) << 24;
case 3: h ^= (data[size + 2] & 0xFF) << 16;
case 2: h ^= (data[size + 1] & 0xFF) << 8;
case 1: h ^= (data[size] & 0xFF);
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
return h;
}以上实现参考:
https://github.com/tnm/murmurhash-java
https://github.com/tamtam180/MurmurHash-For-Java/
做了一下测试,随机数组,个数10^7,长度1-30, 结果如下:
散列函数
冲突个数
运算时间(毫秒)
BKDRHash
1673
1121
CRC64
1673
1331
MurmurHash
0
1119
该测试把另一个64bit的hash, CRC64掺和进来了。
很神奇的是,CRC64和BKDRHash的冲突率是一样的(测了很多次,都是一样),可能是都存在溢出问题的原因。
至于运算时间,差别不大。
如果把随机数组的长度调整为1-50,则前者(BKDRHash & CRC64)的冲突率会相对降低,而后者的运算效率会稍胜于前者。
我想MurmurHash之所以应用广泛,应该不仅仅是因为其冲突率低,还有一个很重要的特性:
前面提到的“强混淆性”。
编写一个计算码距的函数如下:
private static int getHammingDistance(long a, long b) {
int count = 0;
long mask = 1L;
while (mask != 0) {
if ((a & mask) != (b & mask)) {
count += 1;
}
mask <<= 1;
}
return count;
}构造随机数组,每次改变其中一个bit,计算MurmurHash,码距在31-32之间。
对于64bit的散列,正好在50%左右,说明该散列函数具备雪崩效应。
或者从另一个角度看,MurmurHash算出的散列值比较“均匀”,这个特点很重要。
比如如果用于哈希表,布隆过滤器等, 元素就会均匀分布。
生日悖论
最后了解一下冲突概率的估算: 生日悖论 。
生日悖论讲的是给定一群人,其中有至少有两个人生日相同的概率。
以一年365天算,23人(及以上),有两人生日相同的概率大约50%;而如果到了60人以上,则概率已经大于99%了。
同样的,给定一组随机数,也可以算出有相同数值(冲突)的概率。
根据维基百科生日攻击中的描述,其冲突分布如下表: 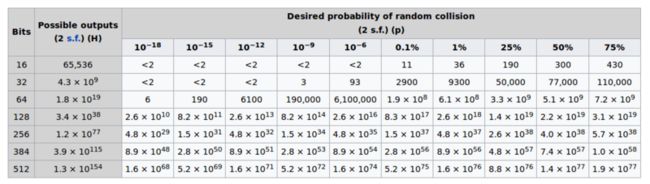
如果随机数是32位,那么可能性有约43亿种,但是只要数量达到50000个,其冲突概率就有25%。
我们常看到MD5作为文件索引,SHA,MD5用于文件校验,就是因为其冲突概率很低,想要篡改文件还保持Hash不变,极其困难。
不过困难不意味着不可能,例如,Google建议不要使用SHA-1加密了,
参见:为什么Google急着杀死加密算法SHA-1 。
扯远了,回到前面说的缓存key,64bit的MurmurHash, 当缓存数量在10^4这个级别时,
有两个缓存的key冲突的概率是10^-12(万亿份之一)的量级,应该是比较可靠的。
如果觉得还不够,可以用128bit的MurmurHash,仅做索引的话,应该比MD5要更合适(运算快,低碰撞,高混淆)
结语
散列广泛应用于计算机的各个领域,了解散列函数的一些性质,对于解决工程问题或有帮助,
故而有了这篇“漫谈”,希望对读者有所启发。