线程基础知识-必知必会
文章目录
- 什么是线程,什么是进程?
- 什么是并发,什么是并行?
- 线程有哪几种状态?
- start() 和 run() 区别
- sleep() 和wait() 的区别
- blocked 状态和waiting 状态的区别
- 线程的常用方法join() 和 yeild()
- 创建线程有哪些方式?你平时是怎么写的?
- 线程池的三个方法,七大参数,四种策略?
- 如何配置线程池核心线程数?
线程知识那么多,我们先来了解下简单的,必须掌握的!
什么是线程,什么是进程?
进程:在操作系统中能够独立运行,并且作为资源分配的基本单位。它表示运行中的程序 打开电脑的管理控制台,看到的运行的应用程序就是一个个进程!
线程:是进程中的一个实例,作为系统调度和分派的基本单位。
一个进程可以包含多个线程,一个进程至少有一个线程! Java程序至少有两个线程: GC、Main
什么是并发,什么是并行?
并发:多个线程操作同一个资源,交替执行的过程!
并行:多个线程同时执行!只有在多核CPU下才能完成!
关于最高效率:所有CPU同时执行!
所以我们使用多线程或者并发编程的目的:提高效率,让CPU一直工作,达到最高处理性能!
线程有哪几种状态?
根据State 常量类得知有NEW(创建),RUNNABLE(运行),BLOCKED(阻塞),WAITING(等待),TIMED_WAITING(延时等待),TERMINATED(终止)6种状态!
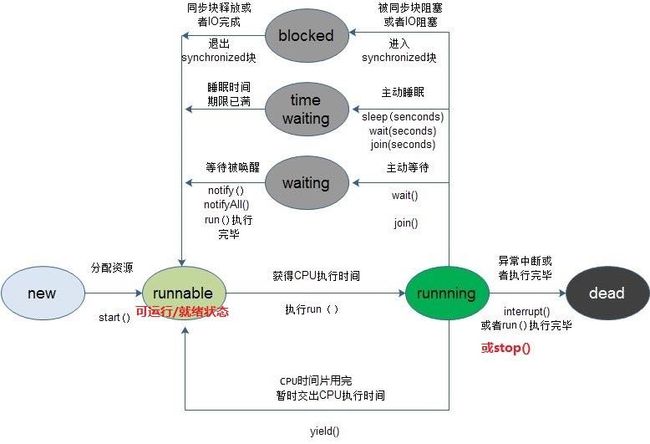
- new 新建状态,线程创建后尚未启动的状态
- runnable 就绪状态,表示可以运行的线程状态(注意这个可以描述),它表示可能在运行或者在排队等待cpu分配时间片
- blocked 阻塞等待锁的状态, 表示处于阻塞等待锁的线程正在等待监视器的锁;例如等待执行的synchronized 修饰的代码块或者方法
- waiting 等待状态,比如一个线程A 调用了
Object.wait(),那么它就处于了等待状态,此时线程A就让出了锁,需要其他线程调用Object.notify()或者Object.notifyAll()方法,线程A才会退出等待状态继续参与到锁的竞争中,需要注意的是其他线程调用notify()或notifyAll()并不是放弃锁,只是告知线程A 你可以来抢锁了; - time_wating 计时等待状态,类比于waiting状态,它只是多了个超时时间;线程A调用
Object.wait(Long timeout1)或者Thred.join(Long timeout2)将会进入此状态,它表示线程A 将让出锁一段时间,等这段时间过后不需要等谁通知,就会加入锁的竞争中! - terminal 终止状态,表示线程已执行完毕;
start() 和 run() 区别
start()源码如下:
public synchronized void start() {
// 判断线程是否是初始状态 即new 出来未启动的状态
// 不是,就抛异常!
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
// 不做任何处理,如果启动抛了异常就会传递到调用堆栈上
}
}
}
线程调用run()实际是因为Thred类 实现了Runnable接口,重写了其抽象run(),对应的源码如下:
public class Thread implements Runnable {
/* What will be run. */
private Runnable target;
@Override
public void run() {
if (target != null) {
target.run();
}
}
}
通过源码我们可以知道,start() 方法是Thread原有的方法,且加了关键字synchronized修饰,是一个同步的方法;而run()方式是一个重写的抽象方法,只是个普通的方法;且start()因为要做状态判断所以只能被调用一次,而run()可以被多次调用!
sleep() 和wait() 的区别
sleep() 是一个静态的本地方法,通过Thread.sleep()来调用,wait() 是一个final修饰的不可变的方法,由线程对应的实例来调用;且线程A调用sleep()表示 线程A进入假死状态,即让出CPU时间片,但是其还处于被监听的状态,即不会释放锁(即抱着对象睡)!而wait() 会释放锁,且让出时间片,等过了一段时间才会来争夺CPU资源!此外还有:
- 类不同
wait : Obejct 类 Sleep Thread
在juc编程中,线程休眠怎么实现!Thread.Sleep
// 时间单位
TimeUnit.SECONDS.sleep(3);
- 会不会释放资源
sleep:抱着锁睡得,不会释放锁!wait 会释放锁! - 使用的范围是不同的
wait 和 notify 是一组,一般在线程通信的时候使用!
sleep 就是一个单独的方法,在那里都可以用! - 关于异常
sleep 需要捕获异常,而wait不需要
blocked 状态和waiting 状态的区别
首先,waiting 是调用Object.wait() 触发的,是本线程主动让出锁后处于的一种状态需要被唤醒,而blocked 是指当前线程处于等待其他线程使用完某个锁资源的状态,可以理解为处于blocked 状态的线程一直活跃在争夺锁的状态中,只不过争夺锁的管道被阻塞了,导致它处于被阻塞的状态!
线程的常用方法join() 和 yeild()
join() 例如在A线程中,B线程调用了join()方法,这时候A 线程会让出执行权给B 线程,当B线程执行完或者超过超时时间后,A线程会继续执行当前线程! (其实join()底层还是wait()来实现的)
join()源码如下:
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
// 超时时间不能小于0
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
// 超时时间设置为0 表示无限等待 等待其他线程执行完为止
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
// 循环判断直到等于超时时间
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
yeild()也是native 修饰的,那它也是一个本地方法,是由C或C++来实现的。例如A线程调用了yeild(),它表示A线程 告诉线程调度器愿意让出CPU 的执行时间片,但是线程调度器不一定会让其让出,只是比正常情况下增加了让出CPU时间片的几率!
创建线程有哪些方式?你平时是怎么写的?
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 继承 Thread 类
- 使用线程池
对于不频繁创建线程的场景使用继承runnable()或callable()接口的方式,对于需要频繁创建且线程生命周期短的场景使用线程池。
实现runnable()接口:
public static void main(String[] args) {
MyRunnable instance = new MyRunnable();
Thread thread = new Thread(instance);
thread.start();
}
public class MyRunnable implements Runnable {
@Override
public void run() {
// ...
}
}
实现callbale()接口:
与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装
public static void main(String[] args)throws ExecutionException,
InterruptedException{
MyCallable mc = new MyCallable();
FutureTask<Integer> ft = new FutureTask<>(mc);
Thread thread = new Thread(ft);
thread.start();
System.out.println(ft.get());
}
public class MyCallable implements Callable<Integer> {
public Integer call() {
return 123;
}
}
阿里规约:

线程池:
public ThreadPoolExecutor(int corePoolSize, // 核心池线程数大小 (常用)
int maximumPoolSize, // 最大的线程数大小 (常用)
long keepAliveTime, // 超时等待时间 (常用)
TimeUnit unit, // 时间单位 (常用)
BlockingQueue<Runnable> workQueue, // 阻塞队列(常用)
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略(常用)) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
线程池的三个方法,七大参数,四种策略?
1.三大方法:
// 单例,只能有一个线程!
ExecutorService threadPool = Executors.newSingleThreadExecutor();
// 固定的线程数
ExecutorService threadPool = Executors.newFixedThreadPool(8);
// 遇强则强!可伸缩!
ExecutorService threadPool = Executors.newCachedThreadPool();
try {
// 线程池的使用方式!
for (int i = 0; i < 30; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName() + " ok");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 使用完毕后需要关闭!
threadPool.shutdown();
}
}
2.七大参数:
下面通过一张图来理解

corePoolSize:常用线程池大小,这个参数设置非常关键设置过大浪费资源,设置过小导致线程频繁创建或销毁。
maximumPoolSize: 常用连接加备用连接(CPU密集型:根据CPU的处理器数量来定!保证最大效率 Runtime.getRuntime().availableProcessors()获取cpu核数;IO密集型: 50 个线程都是进程操作大io资源, 比较耗时! > 这个是常用的 IO 任务数!)对照图表来说最大线程数等于常用连接数+备用连接数
keepAliveTime:表示线程池中的线程空闲时间,当空闲时间达到keepAliveTime值时,线程会被销毁,直到只剩下corePoolSize个线程为止,避免浪费内存和句柄资源
TimeUnit:时间单位,通常是TimeUnit.SECONDS
workQueue:阻塞队列,结合图来理解也就是等候区。当常用连接和等候区满了,会启用备用连接。当这些都满了,会根据拒绝策略来判定
threadFactory:线程工厂,用来创建线程的(不需要特殊配置)
handler:拒绝策略,当最大线程池和阻塞队列都满了,判定新来线程该执行哪种策略
3.四大策略
ThreadPoolExecutor.AbortPolicy(); 抛出异常,丢弃任务
ThreadPoolExecutor.DiscardPolicy();不抛出异常,丢弃任务
ThreadPoolExecutor.DiscardOldestPolicy(); 尝试获取任务,不一定执行!
ThreadPoolExecutor.CallerRunsPolicy(); 哪来的去哪里找对应的线程执行!
如何配置线程池核心线程数?
我们知道计算机的核数是和响应性能息息相关的,我们可以查看计算机的配置或者使用Runtime.getRuntime().availableProcessor()方法获取计算机的核数。
在确定了核数后我们需要知道目前项目中业务所对应的任务是IO密集型还是CPU密集型:
- IO密集型:指的是大量的读写操作。例如mysql数据库的读写,数据的清洗,文件的读写,附件服务器的读写,网络通信等任务。这类任务不会特别消耗cpu,但是单个任务由于执行io操作会特别耗时。
- CPU密集型:指的是依赖于cpu的计算的操作。例如人工智能算法,加解密算法,压缩等需要消耗大量CPU资源的任务,这些大部分场景下都纯CPU计算。
在确定任务类型后:
CPU密集型:核心线程数=CPU核数+1
IO密集型:核心线程数=CPU核心数*(1+IO耗时/CPU耗时) 或者核心线程数=CPU核心数/(1-阻塞系数)
其中CPU密集型阻塞系数为0,IO密集型阻塞系数接近于1,一般认为在0.8~0.9之间。例如:8核CPU,按照公式就是8(1-0.9)=80
如果还需要精确点,可以对任务进行压测,监控CPU的负载情况和JVM的线程情况,然后根据实际情况衡量应该创建的线程数!
小结:最近回过头来发现线程的知识真的很多,很多都可以抽出来单独写一篇博客。线程方面的知识又是必须掌握的,那就慢慢梳理一下吧。本篇就当是基础总结篇,更多后面会继续梳理!