python网络爬虫学习(三)正则表达式的使用之re.match方法
一.为什么要学习正则表达式
很好,我们现在已经能够写出获得网站源代码的程序了,我们有了第一个问题:如何从杂乱的代码中找到我们所需的信息呢?此时,正则表达式的学习就显得很有必要了。有人打趣说,当你想到用正则表达式解决一个问题时,你就拥有了两个问题。从这句话中可以看出正则表达式学习的困难程度,但是为了写出好的爬虫,我们必须对其进行学习。
二.正则表达式的语法规则
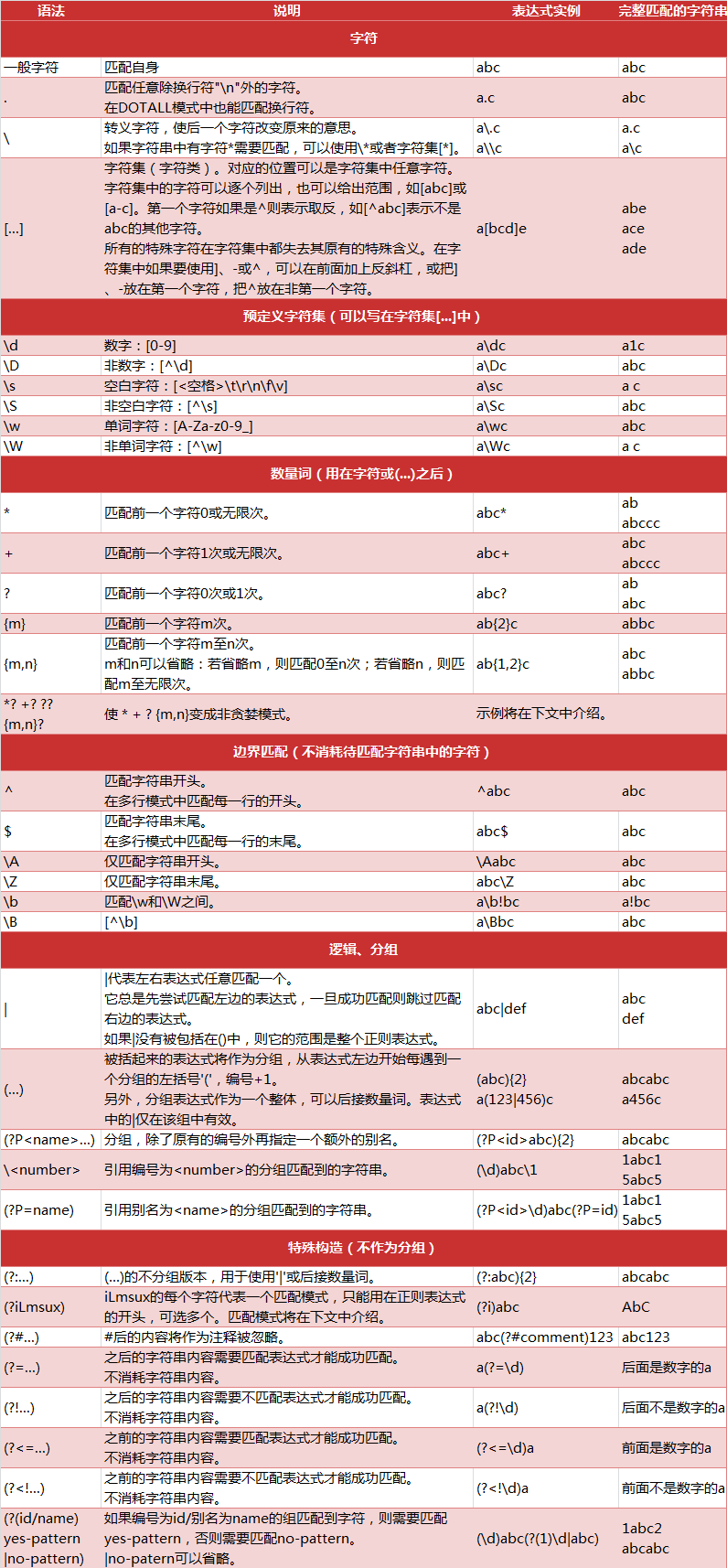 ’>图片转自http://cuiqingcai.com/tag/%E7%88%AC%E8%99%AB
’>图片转自http://cuiqingcai.com/tag/%E7%88%AC%E8%99%AB
1.正则表达式的一些注解
(一)贪婪与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式”ab*”如果用于查找”abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab*?”,将找到”a”。
注:我们一般使用非贪婪模式来提取。
(二)反斜杠问题
与大多数编程语言相同,正则表达式里使用”\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\”表示。同样,匹配一个数字的”\d”可以写成r”\d”。有了原生字符串,写出来的表达式更加直观。
2.python的Re模块
python的Re模块提供对正则表达式的支持,主要用到下列几种方法
#返回pattern对象
re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags])
re.search(pattern, string[, flags])
re.split(pattern, string[, maxsplit])
re.findall(pattern, string[, flags])
re.finditer(pattern, string[, flags])
re.sub(pattern, repl, string[, count])
re.subn(pattern, repl, string[, count])我们注意到代码中的pattern,下面对pattern进行介绍。pattern是一个匹配模式,所谓模式,是正则表达式最基本的元素,它们是一组描述字符串特征的字符,是之后用来匹配字符的基础。那么如何得到pattern模式呢,我们可以使用re中的compile方法,见代码:
pattern=re.compile(r'hello')我们传进一个原生字符串’hello’,通过compile方法编译出一个pattern对象,之后我们将用这个对象进行匹配。也就是说之后要做的事就是对要匹配的字符串与’hello’作比较。
下面我们看看刚才提到的re模块中的几种方法
1.re.match(pattern, string[, flags])
这个方法从我们要匹配的字符串的头部开始,当匹配到string的尾部还没有匹配结束时,返回None;
当匹配过程中出现了无法匹配的字母,返回None。
下面给出一组代码来进行具体认识
# -*- coding=utf-8 -*-
import re
pattern=re.compile(r'hello')
result1=re.match(pattern,'hello')
result2=re.match(pattern,'helloc')
result3=re.match(pattern,'helo')
result4=re.match(pattern,'hello world')
if result1:
print result1.group()
else:
print '1匹配失败'
if result2:
print result2.group()
else:
print '2失败'
if result3:
print result3.group()
else:
print '3失败'
if result4:
print result4.group()
else:
print '4失败'
运行结果:
hello
hello
3失败
hello对匹配结果进行分析:
1.string与pattern完全相同,成功匹配
2.string虽然多出一个字母,但pattern匹配完成时,匹配成功,后面的c不再匹配。
3.string匹配到最后一个字母时,发现仍然无法完全匹配,匹配失败。
4.原理同2
下面解释一下result.group的含义,match是一次匹配的结果,包含很多关于这次匹配的信息,我们可以通过match提供的属性和方法读取到。
下面给出几个例子对match提供的一些方法加以解释,代码如下
# -*- coding=utf-8 -*-
import re
m=re.match(r'(\w+) (\w+)(?P.*)' ,'hello world!')
print 'm.string',m.string
print 'm.start:',m.start()
print 'm.start:',m.start(2)
print 'm.end:',m.end()
print 'm.end:',m.end(2)
print 'm.pos:',m.pos
print 'm.endpos:',m.endpos
print 'm.group:',m.group(2)
print 'm.groupdict:',m.groupdict()
print 'm.lastgroup:',m.lastgroup
print 'm.lastindex',m.lastindex
print 'm.span:',m.span(2)
print 'm.span',m.span()
print 'm.re:',m.re
print m.expand(r'\2 \1 \3')运行结果:
m.start: 0
m.start: 0
m.end: 12
m.end: 11
m.pos: 0
m.endpos: 12
m.group: world
m.groupdict: {'char': '!'}
m.lastgroup: char
m.lastindex 3
m.span: (6, 11)
m.span (0, 12)
m.re: <_sre.SRE_Pattern object at 0x02669760>
m.string hello world!
world hello !
结果分析:
1.string是匹配时所用的文本
2.start可以返回指定的组在字符串中开始匹配的位置,默认值为0
3.end返回指定的组在字符串中开始匹配的位置,默认值为0
4.pos,endpos用于返回起始和终止匹配位置
5.group可以返回指定组的起始匹配位置
6.groupdict返回有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。
7.lastgroup返回最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
8.lastindex返回最后一个分组在文本中的索引
9.span 返回(start(group), end(group)),即该组的起始和终止位置
10.expand可以实现分组之间顺序的调整