hadoop 2.x简单介绍
hadoop
Hadoop是什么?Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算.
大数据的四个特征:
海量的数据规模,多样的数据类型,快速的数据流转,数据价值的体现。
hadoop2x的核心模块
Hadoop Comon:
为其他Hadoop模块提供基础设施
Hadoop HDFS
一个高可靠,高吞吐量的分布式文件系统
Hadoop MapReduce:
一个分布式的离线并行计算框架
Hadoop YARN:
一个新的MapReduce框架,任务调度与资源管理
HDFS
Hadoop的设计思想受到Google公司的GFS设计思想的启示,基于一种开源的理念实现的分布式分布式文件系统。HDFS的设计基础与目标如下。
1)硬件错误(Hardware Failure)是常态,因而需要数据冗余技术。
2)流失数据访问(Streaming Data Access),即数据批量读取而非随机读写,Hadoop擅长做数据分析而不是事务处理。
3)大规模数据集(Large Data Sets)。
4)简单一致性模型(Simple Coherency Model),即为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,也就是文件一经写入,关闭,就再不要修改。
5)“Moving Computation is Cheaper than Moving Data”,通俗理解,程序采用“数据就近”原则分配节点执行。
6)Portability Across Heterogeneous Hardware and Software Platforms,即有着很强的可扩展性。

HDFS体系结构
HDFS体系结构如图1所示,它采用主从结构,Namenode属于主段,Datanode属于从端。
Namenode
1)管理文件系统的命名空间。
2)记录 每个文件数据快在各个Datanode上的位置和副本信息。
3)协调客户端对文件的访问。
4)记录命名空间内的改动或者空间本省属性的改动。
5)Namenode 使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
从社会学来看,Namenode是HDFS里面的管理者,发挥者管理、协调、操控的作用。
Datanode
1)负责所在物理节点的存储管理。
2)一次写入,多次读取(不修改)。
3)文件由数据库组成,一般情况下,数据块的大小为64MB。
4)数据尽量散步到各个节点。
从社会学的角度来看,Datanode是HDFS的工作者,发挥按着Namenode的命令干活,并且把干活的进展和问题反馈到Namenode的作用。
客户端如何访问HDFS中一个文件呢?具体流程如下。
1)首先从Namenode获得组成这个文件的数据块位置列表。
2)接下来根据位置列表知道存储数据块的Datanode。
3)最后访问Datanode获取数据。
注意:Namenode并不参与数据实际传输。
数据存储系统,数据存储的可靠性至关重要。HDFS是如何保证其可靠性呢?它主要采用如下机理。
1)冗余副本策略,即所有数据都有副本,副本的数目可以在hdfs-site.xml中设置相应的复制因子。
2)机架策略,即HDFS的“机架感知”,一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时丢失数据,也可以提供带宽利用率。
3)心跳机制,即Namenode周期性从Datanode接受心跳信号和快报告,没有按时发送心跳的Datanode会被标记为宕机,不会再给任何I/O请求,若是Datanode失效造成副本数量下降,并且低于预先设置的阈值,Namenode会检测出这些数据块,并在合适的时机进行重新复制。
4)安全模式,Namenode启动时会先经过一个“安全模式”阶段。
5)校验和,客户端获取数据通过检查校验和,发现数据块是否损坏,从而确定是否要读取副本。
6)回收站,删除文件,会先到回收站/trash,其里面文件可以快速回复。
7)元数据保护,映像文件和事务日志是Namenode的核心数据,可以配置为拥有多个副本。
8)快照,支持存储某个时间点的映像,需要时可以使数据重返这个时间点的状态。
Mapreduce
是一个计算框架,既然是做计算的框架,那么表现形式就是有个输入(input),mapreduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
MapReduce将计算过程分为两个阶段:Map和Reduce Map阶段并行处理输入数据,Reduce阶段对Map结果进行汇总。
Shuffle链接Map和Reduce两个阶段: Map Task将数据写到本地磁盘,Reduce Task从每个Map Task上读取一份数据
仅适合离线批处理:具有良好的容错性和扩展性,适合简单的批处理任务
缺点明显: 启动开销大,过多使用磁盘导致效率低下等
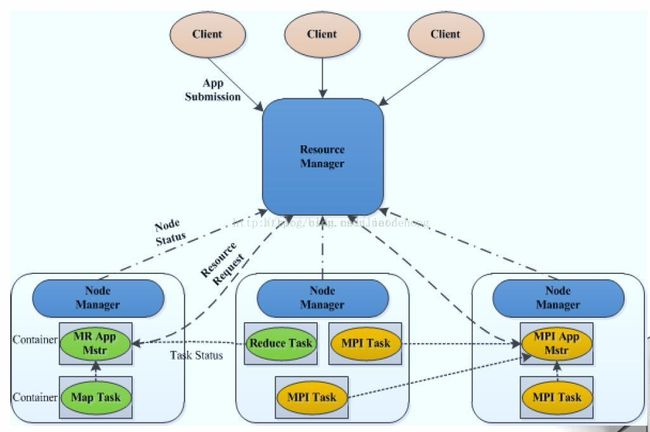
YARN
YARN是资源管理系统,理论上支持多种资源,目前支持CPU和内存两种资源
YARN基本架构