Python2.7 语言简介
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。解释型,意味着开发过程中没有了编译这个环节。面向对象,则意味着Python支持面向对象的风格或代码封装在对象的编程技术。另外,其交互性意味着可以在一个Python提示符后,直接互动写和执行程序。
1、环境变量
下面几个重要的环境变量,它应用于Python:
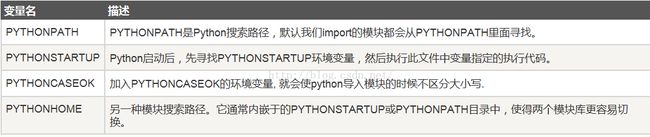
Note:关于Python默认路径的问题,可查阅其他博客,其中最理想的办法(windows下)总结如下:
a. 新建 *.py文件,名字*随意,在其中写入经常运行py文件的文件夹,如我的F:\ResearchData\MyCode\Python
b. 将其保存后,再将文件后缀由py改成pth,并将文件放到你Python安装文件夹下的某个文件夹中,如我的D:\Python27\Lib\site-packages
c. 重启Python IDE,进入后可查看sys.path已经有这条路径了,以后保存运行文件都可以在F:\ResearchData\MyCode\Python这个文件夹中进行了
2、关于Python的运行方式
2.1 交互式解释器Shell
可以通过命令行窗口进入python并开在交互式解释器中开始编写Python代码。
常用Python命令行参数:
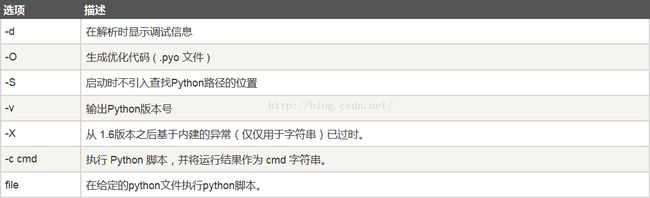
2.2 命令行脚本
在应用程序中通过引入解释器可以在命令行中执行Python脚本。
2.3 集成开发环境IDE
可以使用图形用户界面(GUI)环境来编写及运行Python代码。
3、基础格式
3.1 中文输入问题
Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字(包括注释中的汉字),所以在读取中文时会报错。
只需在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8表明编码方式就行了。
而Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
3.2 Python标识符
a. 在python里,标识符有字母、数字、下划线组成。
b. 在python中,所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头。
c. python中的标识符是区分大小写的。
d. 以下划线开头的标识符是有特殊意义的:以单下划线开头(_foo)的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用"from xxx import *"而导入;
以双下划线开头的(__foo)代表类的私有成员;以双下划线开头和结尾的(__foo__)代表python里特殊方法专用的标识,如__init__()代表类的构造函数。
3.3 行和缩进
学习Python与其他语言最大的区别就是,Python的代码块不使用大括号({})来控制类、函数以及其他逻辑判断。python最具特色的就是用缩进来写模块。缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
IndentationError: unexpected indent 此错误表示文件格式有问题,可能是tab和空格没对齐的问题。
IndentationError: unindent does not match any outer indentation level 此错误表明,使用的缩进方式不一致,有的是 tab 键缩进,有的是空格缩进,改为一致即可。
因此,在Python的代码块中必须使用相同数目的行首缩进空格数。
建议你在每个缩进层次使用 单个制表符 或 两个空格 或 四个空格 ,切记不能混用。
3.4 多行语句
Python语句中一般以新行作为为语句的结束符,但是我们可以使用斜杠( \)将一行的语句分为多行显示。
语句中包含[], {} 或 () 括号就不需要使用多行连接符,如下例:
days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
3.5 引号
Python 接受单引号('),双引号("),三引号(''')(“”“) 来表示字符串,引号的开始与结束必须是相同类型的。
其中三引号可以由多行组成,每行不用添加斜杠作分行(双引号间如换行需斜杠),编写多行文本的快捷语法,甚至可以加入注释常用语文档字符串,在文件的特定地点,被当做注释。
3.6 注释
python中单行注释采用 # 开头。
python 中多行注释使用三个单引号(''')或三个双引号(""")。
3.7 空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。
类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割。
NOTE:空行也是程序代码的一部分。
3.8 代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
我们将首行及后面的代码组称为一个子句(clause)。
4、变量类型
变量是存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
Python中的变量不需要声明,变量的赋值操作既是变量声明和定义的过程。每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
4.1 数字
数字数据类型用于存储数值。
他们是不可改变的数据类型,这意味着改变数字数据类型会分配一个新的对象。
您也可以使用del语句删除一些对象引用。
del语句的语法是:
del var del var_a, var_b
4.2 字符串
字符串或串(String)是由数字、字母、下划线组成的一串字符。单字符也在Python也是作为一个字符串使用。
定义用s=“ ”标示,读取字符用s[]表示,无论读串还是读单元素,返回变量还是个str类型。支持顺序和倒序读取。
可以对已存在的字符串进行修改,并赋值给另一个变量。
加号(+)是字符串连接运算符,星号(*)是重复操作。
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。如
>>> print "My name is %s and weight is %d kg!" % ('Zara', 21) My name is Zara and weight is 21 kg!python字符串格式化符号:
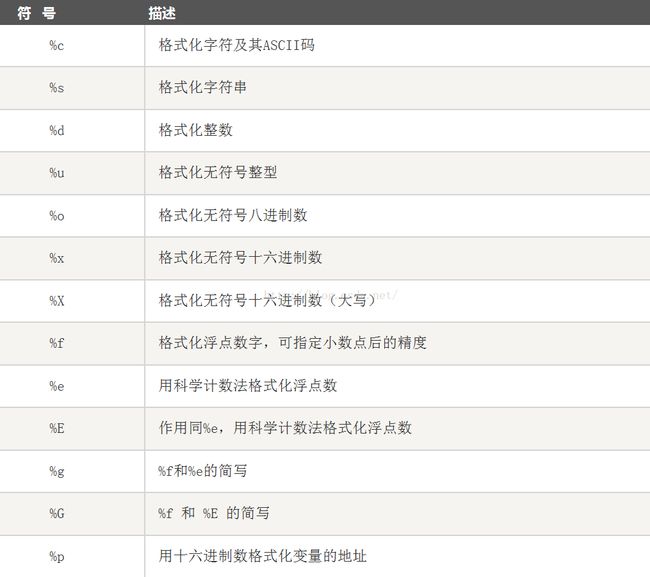
4.3 列表
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(所谓嵌套)。
列表用s=[ ]标示,读取元素用s[]标示,读取特定元素则返回变量为对应元素类型,读取list中某串序列,则返回list类型。支持顺序和倒叙读取。
加号(+)是列表连接运算符,星号(*)是重复操作。
4.4 元祖
tuple是另一个数据类型,类似于List。
元组用s=( )标识,内部元素用逗号分隔,读取用s[],返回变量类型和该元素对应,串则tuple型。
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合。元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组。
元组中只包含一个元素时,需要在元素后面添加逗号。
加号(+)是列表连接运算符,星号(*)是重复操作。
4.5 字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
键必须独一无二,同一个键出现两次,创建时后一个会被记住,但值则不必。
键值可以取任何数据类型,但必须是不可变的,如字符串,数或元组,而列表不行。
字典用s={ }标识,读取用s[]标示,返回变量类型为其元素的对应类型,不像其它类型,无法读串。字典由索引(key)和它对应的值value组成。
>>> dict = {} >>> dict['one'] = "This is one" >>> dict[2] = "This is two" >>> dict[3] = 4 >>> dict {2: 'This is two', 3: 4, 'one': 'This is one'} >>> dict[2] 'This is two' >>> dict['one'] 'This is one' >>> type(dict[3])
5、运算符
5.1 算术运算符
% 取模
** 幂
// 相除取整
6、函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以def关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- Return[expression]结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
6.1 按值传递参数和按引用传递参数
所有参数(自变量)在Python里都是按引用传递。如果你在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了。例如:
# 可写函数说明 def changeme( mylist ): "修改传入的列表" mylist.append([1,2,3,4]); print "函数内取值: ", mylist return # 调用changeme函数 mylist = [10,20,30]; changeme( mylist ); print "函数外取值: ", mylist传入函数的和在末尾添加新内容的对象用的是同一个引用。故输出结果如下:
函数内取值: [10, 20, 30, [1, 2, 3, 4]] 函数外取值: [10, 20, 30, [1, 2, 3, 4]]
6.2 参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 命名参数
- 缺省参数
- 不定长参数
A. 必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
调用printme()函数,你必须传入一个参数,不然会出现语法错误:
#可写函数说明 def printme( str ): "打印任何传入的字符串" print str; return; #调用printme函数 printme();
B. 命名参数
命名参数和函数调用关系紧密,调用方用参数的命名确定传入的参数值。你可以跳过不传的参数或者乱序传参,因为Python解释器能够用参数名匹配参数值。
#可写函数说明 def printinfo( name, age ): "打印任何传入的字符串" print "Name: ", name; print "Age ", age; return; #调用printinfo函数 printinfo( age=50, name="miki" );
C. 缺省参数
调用函数时,缺省参数的值如果没有传入,则被认为是默认值。下例会打印默认的age,如果age没有被传入:
#可写函数说明 def printinfo( name, age = 35 ): "打印任何传入的字符串" print "Name: ", name; print "Age ", age; return; #调用printinfo函数 printinfo( age=50, name="miki" ); printinfo( name="miki" );
运行结果如下:
Name: miki Age 50 Name: miki Age 35
D. 不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。
def functionname([formal_args,] *var_args_tuple ): "函数_文档字符串" function_suite return [expression]
加了星号(*)的变量名会存放所有未命名的变量参数。选择不多传参数也可。如下实例:# 可写函数说明 def printinfo( arg1, *vartuple ): "打印任何传入的参数" print "输出: " print arg1 for var in vartuple: print var return; # 调用printinfo 函数 printinfo( 10 ); printinfo( 70, 60, 50 );
运行结果如下:
输出: 10 输出: 70 60 50
6.3 匿名函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的名字空间,且不能访问自有参数列表之外或全局名字空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
如下实例
# 可写函数说明 sum = lambda arg1, arg2: arg1 + arg2; # 调用sum函数 print "相加后的值为 : ", sum( 10, 20 ) print "相加后的值为 : ", sum( 20, 20 )输出:
相加后的值为 : 30 相加后的值为 : 40
6.4 return语句
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。
6.5 变量作用域
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。
7、模块
模块让你能够有逻辑地组织你的Python代码段。把相关的代码分配到一个 模块里能让你的代码更好用,更易懂。
模块也是Python对象,具有随机的名字属性用来绑定或引用。
简单地说,模块就是一个保存了Python代码的文件。模块能定义函数,类和变量。模块里也能包含可执行的代码。
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
7.1 dir()函数
dir()函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如下一个简单的实例:
# 导入内置math模块 import math content = dir(math) print content;输出为
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan', 'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp', 'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log', 'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh']
在这里,特殊字符串变量__name__指向模块的名字,__file__指向该模块的导入文件名。
7.2 globals()函数和locals()函数
根据调用地方的不同,globals()和locals()函数可被用来返回全局和局部命名空间里的名字。
如果在函数内部调用locals(),返回的是所有能在该函数里访问的命名。
如果在函数内部调用globals(),返回的是所有在该函数里能访问的全局名字。
两个函数的返回类型都是字典。所以名字们能用keys()函数摘取。
7.3 reload()函数
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。
因此,如果你想重新执行模块里顶层部分的代码,可以用reload()函数。该函数会重新导入之前导入过的模块。
7.4 包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的Python的应用环境。
考虑一个在Phone目录下的pots.py文件。这个文件有如下源代码:
def Pots(): print "I'm Pots Phone"
同样地,我们有另外两个保存了不同函数的文件:
- Phone/Isdn.py 含有函数Isdn()
- Phone/G3.py 含有函数G3()
现在,在Phone目录下创建文件 __init__.py:
- Phone/__init__.py
当你导入Phone时,为了能够使用所有函数,你需要在__init__.py里使用显式的导入语句,如下:
from Pots import Pots from Isdn import Isdn from G3 import G3
当你把这些代码添加到__init__.py之后,导入Phone包的时候这些类就全都是可用的了。# 导入 Phone 包 import Phone Phone.Pots() Phone.Isdn() Phone.G3()
为了举例,我们只在每个文件里放置了一个函数,但其实你可以放置许多函数。你也可以在这些文件里定义Python的类,然后为这些类建一个包。
8、 I/O文件操作
8.1 打印到屏幕
最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式。此函数把你传递的表达式转换成一个字符串表达式,并将结果写到标准输出。
8.2 读取键盘输入
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
- raw_input
- input
raw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符)。
input([prompt]) 函数和raw_input([prompt]) 函数基本可以互换,但是input会假设你的输入是一个有效的Python表达式,并返回运算结果。
str = input("Enter your input: "); print "Received input is : ", str
8.3 打开和关闭文件结果如下:
Enter your input: [x*5 for x in range(2,10,2)] Recieved input is : [10, 20, 30, 40]
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的辅助方法才可以调用它进行读写。
file object = open(file_name [, access_mode][, buffering])
各个参数的细节如下:9、 Python标准异常
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
File对象的close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python会关闭之前的文件。用close()方法关闭文件是一个很好的习惯。
fileObject.close();
BaseException 所有异常的基类 SystemExit 解释器请求退出 KeyboardInterrupt 用户中断执行(通常是输入^C) Exception 常规错误的基类 StopIteration 迭代器没有更多的值 GeneratorExit 生成器(generator)发生异常来通知退出 StandardError 所有的内建标准异常的基类 ArithmeticError 所有数值计算错误的基类 FloatingPointError 浮点计算错误 OverflowError 数值运算超出最大限制 ZeroDivisionError 除(或取模)零 (所有数据类型) AssertionError 断言语句失败 AttributeError 对象没有这个属性 EOFError 没有内建输入,到达EOF 标记 EnvironmentError 操作系统错误的基类 IOError 输入/输出操作失败 OSError 操作系统错误 WindowsError 系统调用失败 ImportError 导入模块/对象失败 LookupError 无效数据查询的基类 IndexError 序列中没有此索引(index) KeyError 映射中没有这个键 MemoryError 内存溢出错误(对于Python 解释器不是致命的) NameError 未声明/初始化对象 (没有属性) UnboundLocalError 访问未初始化的本地变量 ReferenceError 弱引用(Weak reference)试图访问已经垃圾回收了的对象 RuntimeError 一般的运行时错误 NotImplementedError 尚未实现的方法 SyntaxError Python 语法错误 IndentationError 缩进错误 TabError Tab 和空格混用 SystemError 一般的解释器系统错误 TypeError 对类型无效的操作 ValueError 传入无效的参数 UnicodeError Unicode 相关的错误 UnicodeDecodeError Unicode 解码时的错误 UnicodeEncodeError Unicode 编码时错误 UnicodeTranslateError Unicode 转换时错误 Warning 警告的基类 DeprecationWarning 关于被弃用的特征的警告 FutureWarning 关于构造将来语义会有改变的警告 OverflowWarning 旧的关于自动提升为长整型(long)的警告 PendingDeprecationWarning 关于特性将会被废弃的警告 RuntimeWarning 可疑的运行时行为(runtime behavior)的警告 SyntaxWarning 可疑的语法的警告 UserWarning 用户代码生成的警告