Apache PDFbox开发指南之PDF文本内容挖掘
转载请注明来源:http://blog.csdn.net/loongshawn/article/details/51550383
相关文章:
- 《Apache PDFbox开发指南之PDF文本内容挖掘》
- 《 Apache PDFbox开发指南之PDF文档读取》
1、场景说明
上一篇文章《Apache PDFbox开发指南之PDF文档读取》讲述了如何读取PDF文档的内容,但这并不是止步,其实想做的是对特定的文本内容进行挖掘,以便获取结构性有价值数据。
2、需要什么
下面这是直接读出来的数据,虽说可以看出大概,但其中参考区间字段内容需要处理,当前不便数据库存储。
检查项目 缩写 测量结果 提示 参考区间 单位
白细胞计数 WBC 6.1 3.5 -- 9.5 10^9/L
淋巴细胞百分比 LYM% 39.3 20 -- 40 %
中间细胞百分比 MXD% 10.1 0 -- 15 %
中性粒细胞百分比 NEUT% 50.6 50 -- 70 %
淋巴细胞绝对值 LYM# 2.7 0.8 -- 4 10^9/L
中间细胞绝对值 MXD# 0.6 0.1 -- 1.4 10^9/L
中性粒细胞绝对值 NEUT# 2.8 2 -- 7 10^9/L
红细胞计数 RBC 5.6 4.3 -- 5.8 10^12/L
血红蛋白 HGB 171 130 -- 175 g/L
红细胞压积 HCT 0.49 0.40 -- 0.50 L/L
平均红细胞体积 MCV 83.5 82 -- 100 fL
平均红细胞血红蛋白含量 MCH 30.8 27 -- 34 pg
平均红细胞血红蛋白浓度 MCHC 354 316 -- 355 g/L
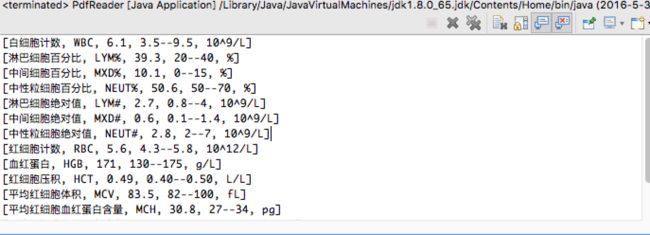
血小板计数 PLT 219 125 -- 350 10^9/L处理后的数据,便于数据库存储:
[白细胞计数, WBC, 6.1, 3.5--9.5, 10^9/L]
[淋巴细胞百分比, LYM%, 39.3, 20--40, %]
[中间细胞百分比, MXD%, 10.1, 0--15, %]
[中性粒细胞百分比, NEUT%, 50.6, 50--70, %]
[淋巴细胞绝对值, LYM#, 2.7, 0.8--4, 10^9/L]
[中间细胞绝对值, MXD#, 0.6, 0.1--1.4, 10^9/L]
[中性粒细胞绝对值, NEUT#, 2.8, 2--7, 10^9/L]
[红细胞计数, RBC, 5.6, 4.3--5.8, 10^12/L]
[血红蛋白, HGB, 171, 130--175, g/L]
[红细胞压积, HCT, 0.49, 0.40--0.50, L/L]
[平均红细胞体积, MCV, 83.5, 82--100, fL]
[平均红细胞血红蛋白含量, MCH, 30.8, 27--34, pg]
[平均红细胞血红蛋白浓度, MCHC, 354, 316--355, g/L]
[血小板计数, PLT, 219, 125--350, 10^9/L]3、代码片段
代码旨在将读取到的文本内容结构化输出。
package com.loongshaw;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import org.apache.pdfbox.io.RandomAccessBuffer;
import org.apache.pdfbox.pdfparser.PDFParser;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
public class PdfReader {
public static void main(String[] args){
File pdfFile = new File("/Users/dddd/Downloads/0571888890423456_182-9320151031326-2.pdf");
PDDocument document = null;
try
{
// 方式一:
/**
InputStream input = null;
input = new FileInputStream( pdfFile );
//加载 pdf 文档
PDFParser parser = new PDFParser(new RandomAccessBuffer(input));
parser.parse();
document = parser.getPDDocument();
**/
// 方式二:
document=PDDocument.load(pdfFile);
// 获取页码
int pages = document.getNumberOfPages();
// 读文本内容
PDFTextStripper stripper=new PDFTextStripper();
// 设置按顺序输出
stripper.setSortByPosition(true);
stripper.setStartPage(4);
stripper.setEndPage(4);
String content = stripper.getText(document);
//System.out.println(content);
BufferedReader bre = null;
String str = "";
int state = 0;
bre = new BufferedReader(new InputStreamReader(new ByteArrayInputStream(content.getBytes(Charset.forName("utf8"))), Charset.forName("utf8")));
while ((str = bre.readLine())!= null)
{
if(str.startsWith("·血常规")){
state = 1;
continue;
}
if(state == 1){
String[] array = str.split(" ");
List list = new ArrayList();
for(int i=0;ifor(int i=0;iif(one.equals("--")){
String one_b = (String) list.get(i-1);
String one_a = (String) list.get(i+1);
String new_one = one_b + one + one_a;
list.set(i, new_one);
list.remove(i-1);
list.remove(i);
System.out.println(list.toString());
}
}
//System.out.println(str + ",size-"+array.length);
}
}
}
catch(Exception e)
{
System.out.println(e);
}
}
} 运行结果:
4、小结
上面仅仅是做了个点皮毛,要想把特定文本内容处理得好一点,还需要深入开发。这篇文章对读者可能没有多大帮助,只是提供一种思考的角度,结构化的数据价值更大一点。