python实践 爬取豆瓣各个标签的电影 爬虫
python实践 爬取豆瓣各个标签的电影
实践题目
爬取豆瓣电影中,华语、欧美、韩国、日本电影每个标签下按评价排序的全部电影,需要如下信息:
(1)每个电影的电影名、导演、编剧、主演、类型、国家、上映日期、片长、电影评分,以及每个星级评分的百分比数据。
(2)每个电影热门点评中的前10个评分及其评分人。
(3)进入每个评分人的主页,爬取其看过的电影信息,以及对电影的评分(几星评价)。(少于10部则全部爬取,多余10部则仅爬取前10个)。
(4)将上述数据均写入数据库,三张表:电影信息、用户(用户名、主页),用户对电影的评分表,写入数据时要注意电影与用户的去重。(电影数达到5000时可停止)。
代码自己写的,豆瓣有时候会跟换一些页面布局的代码,如果报错的话,可以对xpath中的内容分开测试一下,或者看一些页面元素布局的内容。
import requests
import json
from bs4 import BeautifulSoup
from lxml import etree
import pymysql
import re
from PIL import Image
class Movie(object):
def __init__(self):
self.start = 0
self.param = '&filter' #过滤掉不符合条件的元素
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36',
'Referer':'https://accounts.douban.com/login?alias=&redir=https%3A%2F%2Fwww.douban.com%2F&source=index_nav&error=1001'
}
self.url1 = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E5%8D%8E%E8%AF%AD&sort=rank&page_limit=20&page_start=0'
self.url2 = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E6%AC%A7%E7%BE%8E&sort=rank&page_limit=20&page_start=0'
self.url3 = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E9%9F%A9%E5%9B%BD&sort=rank&page_limit=20&page_start=0'
self.url4 = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E6%97%A5%E6%9C%AC&sort=rank&page_limit=20&page_start=0'
self.urlList = [self.url1,self.url2,self.url3,self.url4]
self.session = requests.Session()
self.session.headers.update(self.headers)
self.connet=pymysql.connect(host='localhost',user='root',passwd='yss10071007',db='python4',port=3306,charset='utf8')
self.cur=self.connet.cursor()
def get_url_page(self,url):
# urlx = requests.get(url).text
urlx = self.session.get(url)
if urlx.status_code==requests.codes.ok:
html=urlx.text
urly = etree.HTML(html)
return urly
def get_movie(self,movieurl):
moviex = self.get_url_page(movieurl)
listMovie = []
# 名字
moviename = moviex.xpath('//div[@id="wrapper"]/div[@id="content"]/h1/span[@property="v:itemreviewed"]/text()')
moviename1 = ''.join(moviename)
listMovie.append(moviename1)
# 导演
movieactor = moviex.xpath('//div[@class="subject clearfix"]/div[@id="info"]/span/span[@class="attrs"]/a[@rel="v:directedBy"]/text()')
movieactor1 = ' '.join(movieactor)
listMovie.append(movieactor1)
# 编剧
moviawriter = moviex.xpath('//div[@class="subject clearfix"]/div[@id="info"]/span/span[@class="pl" and contains(text(),"编剧")]/following-sibling::span/a/text()')
moviawriter1 = ' '.join(moviawriter)
listMovie.append(moviawriter1)
# 演员
moviestars = moviex.xpath('//div[@class="subject clearfix"]/div[@id="info"]/span[@class="actor"]/span[@class="attrs"]/a[@rel="v:starring"]/text()')
moviestars1 = ' '.join(moviestars)
listMovie.append(moviestars1)
# 类型
movietype = moviex.xpath('//div[@class="subject clearfix"]/div[@id="info"]/span[@property="v:genre"]/text()')
movietype1 = ' '.join(movietype)
listMovie.append(movietype1)
# 时长
movietime = moviex.xpath('//div[@class="subject clearfix"]/div[@id="info"]/span[@property="v:runtime"]/text()')
movietime1 = ''.join(movietime)
listMovie.append(movietime1)
# 地区
moviearea = moviex.xpath('//div[@class="subject clearfix"]/div[@id="info"]/span[@class="pl" and contains(text(),"制片国家/地区")]/following::text()[1]')
moviearea1 = ''.join(moviearea)
listMovie.append(moviearea1)
# 上映日期
moviedate = moviex.xpath('//div[@class="subject clearfix"]/div[@id="info"]/span[@property="v:initialReleaseDate"]/text()')
moviedate1 = ' '.join(moviedate)
listMovie.append(moviedate1)
# 评分
moviagrade = moviex.xpath('//div[@id="interest_sectl"]/div[@class="rating_wrap clearbox"]/div[@class="rating_self clearfix"]/strong/text()')
moviagrade1 = ''.join(moviagrade)
listMovie.append(moviagrade1)
# 5星制评分
moviagrade5 = moviex.xpath('//div[@id="interest_sectl"]/div[@class="rating_wrap clearbox"]/div[@class="ratings-on-weight"]/div/span[@class="rating_per"]/text()')
listMovie.append(moviagrade5)
# insert进数据库中
try:
self.add_information(listMovie)
except Exception:
print("add_information")
pass
print(listMovie)
return listMovie
def add_information(self,list1):
# connet=pymysql.connect(host='localhost',user='root',passwd='yss10071007',db='python3',port=3306,charset='utf8')
# cur=connet.cursor()
try:
insert1 = 'insert ignore into movie (movie_name,movie_actor,movie_writers,movie_stars,movie_type,movie_time,movie_area,movie_date,movie_grade,movie_5star,movie_4star,movie_3star,movie_2star,movie_1star) values("%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")' %(list1[0],list1[1],list1[2],list1[3],list1[4],list1[5],list1[6],list1[7],list1[8],list1[9][0],list1[9][1],list1[9][2],list1[9][3],list1[9][4])
self.cur.execute(insert1);
self.connet.commit()
except Exception as e:
print("插入异常movie",e)
self.connet.rollback()
# cur.close()#关闭操作游标
# connet.close()#释放数据库资源
def add_user(self,list1):
# connet=pymysql.connect(host='localhost',user='root',passwd='yss10071007',db='python3',port=3306,charset='utf8')
# cur=connet.cursor()
try:
insert1 = 'insert ignore into db_user (username,userurl) values("%s","%s");' %(list1[0],list1[1])
self.cur.execute(insert1);
self.connet.commit()
except Exception as e:
print("插入异常user",e)
self.connet.rollback()
# cur.close()#关闭操作游标
# connet.close()#释放数据库资源
def add_grade(self,username,movie,grade):
try:
insert1 ='insert into db_grade (user,movie,grade) values("%s","%s","%s"); '%(username,movie,grade)
self.cur.execute(insert1);
self.connet.commit()
except Exception as e:
print("插入异常grade",e)
self.connet.rollback()
# cur.close()#关闭操作游标
# connet.close()#释放数据库资源
def get_type_movie(self,url1):
# wbdata = requests.get(url1).text
wbdata = self.session.get(url1).text
data = json.loads(wbdata)
news = data['subjects']
return news
def get_user(self,movieurl):
# 得到电影页面
userhtml = self.get_url_page(movieurl)
listuser = []
user_name = userhtml.xpath('//header[@class="main-hd"]/a[@class="name"]/text()')
use_url = userhtml.xpath('//header[@class="main-hd"]/a[@class="avator"]//@href')
# @class="pl" and contains(text(),"编剧")@class="allstar50 main-title-rating"
user_grade2 = userhtml.xpath('//header[@class="main-hd"]/span[1]//@title')
# user_name = userhtml.xpath('//header[@class="main-hd"]/a[@property="v:reviewer"]/text()')
# use_url = userhtml.xpath('//header[@class="main-hd"]/a[@class="avator"]//@href')
# user_grade2 = userhtml.xpath('//header[@class="main-hd"]/span[@property="v:rating"]//@title')
idict={'力荐':'10', '推荐':'8','还行':'6','较差':'4','很差':'2'}
for i in range(len(use_url)):
list2 = []
list2.append(user_name[i])
list2.append(use_url[i])
grade = self.multiple_replace(user_grade2[i], idict)
list2.append(grade)
try:
self.add_user(list2)
except Exception:
print("add_user")
pass
listuser.append(list2)
print("插入用户成功",list2)
return listuser
def user_saw(self,userurl):
# user = requests.get(url1).text
# userhtml = etree.HTML(user)
# 得到用户网页
# print("sessionss",self.session.cookies.items())
userhtml = self.get_url_page(userurl)
# if(userhtml):
# 用户名 和 看过的的电影链接
htmlname = userhtml.xpath('//div[@id="db-usr-profile"]/div[@class="pic"]/a/img//@alt')
if (len(htmlname) == 0 ):
htmlname = userhtml.xpath('//div[@id="db-usr-profile"]/div[@class="pic"]/a/div//@title')
usermovie = userhtml.xpath('//div[@class="article"]/div[@id="movie"]/h2/span[@class="pl"]/a[contains(text(),"看过")]//@href')
if(len(htmlname) and len(usermovie)):
sawmovie = usermovie[0]+'?sort=time&start=0&mode=grid&tags_sort=count'
showuserhtml = self.get_url_page(sawmovie)
# //用户里面的看过的电影链接
saw = showuserhtml.xpath('//div[@class="grid-view"]/div[@class="item"]/div[@class="info"]/ul/li[@class="title"]/a//@href')
# //用户里面的看过的电影 的评分
sawgrade = showuserhtml.xpath('//div[@class="grid-view"]/div[@class="item"]/div[@class="info"]/ul/li[3]/span[1]//@class')
idict={'rating5-t':'10', 'rating4-t':'8','rating3-t':'6','rating2-t':'4','rating1-t':'2','date':'0'}
print(len(saw))
if len(saw) >= 10:
for i in range(10):
sawgrade2 = self.multiple_replace(sawgrade[i], idict)
listmovie = self.get_movie(saw[i])
if(len(listmovie)):
print(htmlname[0], listmovie[0], sawgrade2)
try:
self.add_grade(htmlname[0], listmovie[0], sawgrade2)
except Exception:
print("add_grade")
pass
else:
for i in range(len(saw)):
sawgrade2 = self.multiple_replace(sawgrade[i], idict)
listmovie = self.get_movie(saw[i])
if(len(listmovie)):
print(htmlname[0], listmovie[0], sawgrade2)
try:
self.add_grade(htmlname[0], listmovie[0], sawgrade2)
except Exception:
print("add_grade")
pass
# print(saw)
# print(sawgrade)
return sawmovie
return False
def multiple_replace(self,text, idict):
rx = re.compile('|'.join(map(re.escape, idict)))
def one_xlat(match):
return idict[match.group(0)]
return rx.sub(one_xlat, text)
def _get_captcha_info(self,url):
"""获取验证码图片和验证码id"""
captcha_info=dict()
resp=requests.get(url,headers=self.headers)
if resp.status_code==requests.codes.ok:
html=resp.text
ele_html=etree.HTML(html)
# 验证码图片链接
captcha_link=ele_html.xpath('//img[@id="captcha_image"]/@src')
if len(captcha_link):
img_html = self.session.get(captcha_link[0])
with open('caprcha.jpg','wb') as f:
f.write(img_html.content)
try:
im = Image.open('caprcha.jpg')
im.show()
im.close()
except:
print('打开错误')
captcha_solution=input('验证码:{} '.format(captcha_link[0]))
captcha_info['captcha-solution']=captcha_solution
# 验证码id
captcha_id=ele_html.xpath('//input[@name="captcha-id"]/@value')
if len(captcha_id):
captcha_info['captcha-id']=captcha_id[0]
return captcha_info
# print(self.session.cookies.get_dict())
def login_user(self,username,password,url):
req_data={
'source':'index_nav',
'redir': 'https://www.douban.com/',
'login':'登录',
'form_email':username,
'form_password':password
}
# 添加验证码信息到请求体中
captcha_info=self._get_captcha_info(url)
if captcha_info:
req_data.update(captcha_info)
# 使用Session post数据
session=requests.Session()
resp=self.session.post(url,data=req_data,headers=self.headers)
return session
if __name__ == '__main__':
db = Movie()
# print("ddd",db.session)
# username = input('请输入你的用户名:')
# password = input('请输入你的密码:')
username = ' xxxxx' #豆瓣的账号和密码
password = ' yyyyy'
url = 'https://accounts.douban.com/login'
sessionuser = db.login_user(username,password,url)
# 得到多个电影 按照种类 eg欧美 华语 日本 韩国 url1----url4
for a in db.urlList:
news = db.get_type_movie(a)
for i in range(8):
listmovie = []
# 电影名字
title = news[i]['title']
# 电影的url
movieurl = news[i]['url']
# 得到电影的list信息
listmovie = db.get_movie(movieurl)
# 插入第一层电影
# 跳转到用户一层 得到用户list 包括名字 链接 和 评价
userlist = db.get_user(movieurl)
# //插入用户和对电影的评价
for user in userlist:
db.add_grade(user[0], listmovie[0], user[2])
# user[1]为用户url 得到看过的电影的网页链接 然后得到看过的电影的链接 并且上传
listuser = db.user_saw(user[1])
if (listuser == False):
print("得不到用户信息")
print("========================")
db.cur.close()#关闭操作游标
db.connet.close()#释放数据库资源
CREATE TABLE `python4`.`movie` (
`id` INT NOT NULL AUTO_INCREMENT,
`movie_name` VARCHAR(100) NULL unique,
`movie_actor` VARCHAR(100) NULL,
`movie_writers` VARCHAR(200) NULL,
`movie_stars` VARCHAR(500) NULL,
`movie_type` VARCHAR(60) NULL,
`movie_time` VARCHAR(80) NULL,
`movie_area` VARCHAR(100) NULL,
`movie_date` VARCHAR(100) NULL,
`movie_grade` VARCHAR(45) NULL,
`movie_5star` VARCHAR(45) NULL,
`movie_4star` VARCHAR(45) NULL,
`movie_3star` VARCHAR(45) NULL,
`movie_2star` VARCHAR(45) NULL,
`movie_1star` VARCHAR(45) NULL,
PRIMARY KEY (`id`));
CREATE TABLE `python4`.`db_user` (
`id` INT NOT NULL AUTO_INCREMENT,
`username` VARCHAR(45) NULL,
`userurl` VARCHAR(100) NULL unique,
PRIMARY KEY (`id`));
CREATE TABLE `python4`.`db_grade` (
`id` INT NOT NULL AUTO_INCREMENT,
`user` VARCHAR(45) NULL,
`movie` VARCHAR(100) NULL,
`grade` VARCHAR(45) NULL,
PRIMARY KEY (`id`));
实验结果
控制台打印的结果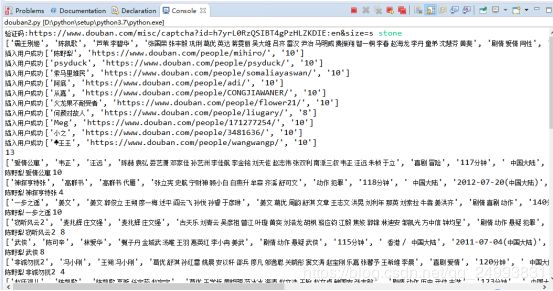
数据库中的内容:
movie表:
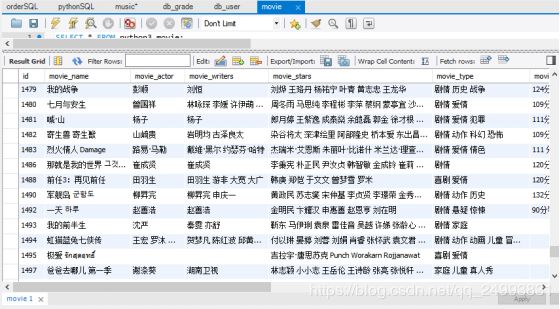

db_user表

db_grade表(评分表)
