计算机视觉:图像分类定位(单一目标检测)python实现
前言
目标检测:我们不仅要用算法判断图片中是不是猫还是狗, 还要在图片中标记出它的位置, 用边框或红色方框把猫狗圈起来, 这就是目标检测问题。其中“定位”的意思是判断猫狗在图片中的具体位置。
目标检测有两类任务:单一目标 ,多目标。
能力差,电气专业,又未怎么深入研究cv.
所以本文先探讨单一目标。
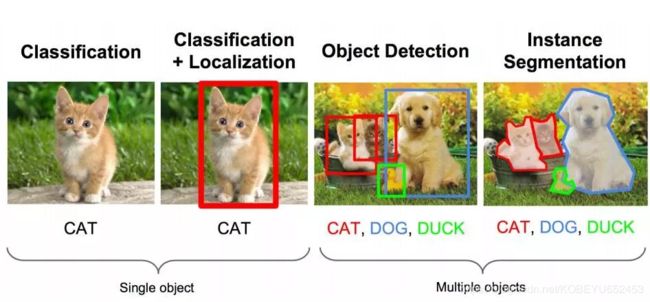
HOG+SVM实现行人检测
先讲解 opencv自带的行人检测例子
HOG原理见
计算机视觉:图像特征与描述大全 ,有代码(一篇博文带你简单了解完图像特征提取技术)
不多说,上代码
import cv2 as cv
# 读取图像
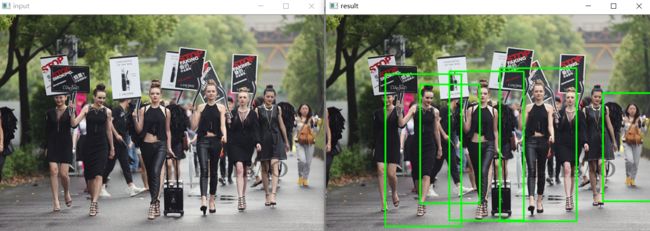
src = cv.imread("duoren.jpg")
cv.imshow("input", src)
# HOG + SVM
hog = cv.HOGDescriptor()
hog.setSVMDetector(cv.HOGDescriptor_getDefaultPeopleDetector())
# Detect people in the image
(rects, weights) = hog.detectMultiScale(src,winStride=(4, 4), padding=(8, 8),scale=1.25,useMeanshiftGrouping=False)
# 矩形框
for (x, y, w, h) in rects:
cv.rectangle(src, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示[添加链接描述](https://blog.csdn.net/kobeyu652453/article/details/107382227)
cv.imshow("result", src)
cv.waitKey(0)
cv.destroyAllWindows()
图像定位实现
python +keras实现图像分类(入门级例子讲解)
opencv进阶学习笔记12:轮廓发现和对象测量
目标检测算法很复杂。
我尝试用 图像分类+对象测量 来实现单目标的图像检测。
图像分类 对象测量 不多说了,参考上面给的链接。
1读取图片并去噪
import cv2 as cv
image= cv.imread("catdog/dog/dog.77.jpg")
image=cv.resize(image,None,fx=0.5,fy=0.5)
blurred = cv.GaussianBlur(image, (5, 5), 0) # 去噪
2二值化图像
gray = cv.cvtColor(blurred, cv.COLOR_BGR2GRAY)
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
3绘制轮廓边缘
contours, hireachy = cv.findContours(binary, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
cv2.findContours()函数第一个参数是要检索的图片,必须是为二值图,即黑白的(不是灰度图),所以读取的图像要先转成灰度的,再转成二值图,
参数讲解
contours,hierarchy=cv2.findContours(image,mode,method)
contours:轮廓
hierarchy:图像的拓扑信息(轮廓层次)(存储上一个轮廓,父轮廓…)
image:二值图像
mode:轮廓检索方式
method:轮廓的近似方法


4求得包含点集最小面积的矩形,这个矩形是可以有偏转角度的,可以与图像的边界不平行。
c = sorted(contours, key=cv.contourArea, reverse=True)[0]
rect = cv.minAreaRect(c)
box = np.int0( cv.boxPoints(rect))
# draw a bounding box arounded the detected barcode and display the image
cv.drawContours(image, [box], -1, (0, 255, 0), 3)
讲解
double cvContourArea( const CvArr* contour, CvSlice slice=CV_WHOLE_SEQ );
contour:轮廓(顶点的序列或数组)。
slice:感兴趣区轮廓部分的起点和终点,默认计算整个轮廓的面积。
c = sorted(contours, key=cv.contourArea, reverse=True)[0]
取出最大的轮廓面积,有些轮廓为噪声。
最大轮廓一般情况下能取到我们想要的目标物。
minAreaRect函数返回矩形的中心点坐标,长宽,旋转角度[-90,0),当矩形水平或竖直时均返回-90
使用cv2.boxPoints()可获取该矩形的四个顶点坐标。 浮点型数据
np.int0 取整
r=cv2.drawContours(image, contours, contourIdx, color[, thickness])
r:目标图像
image:原始图像
contours: 所有的输入轮廓边缘数组
contourIdx :需要绘制的边缘索引,如果全部绘制为-1。如果有多个目标,可以绘制第一个目标0,第二个目标1,第三个目标2.。。
color:绘制的颜色,为BGR格式的SCalar
thickness:可选,绘制的密度,即轮廓的画笔粗细
5找出四个顶点的x,y坐标的最大最小值。矩形框的高=maxY-minY,宽=maxX-minX。
由于前面的提到的 包含点集最小面积的矩形 有的矩形不与图像平行,是斜着的,如下图。我们调整矩形框。
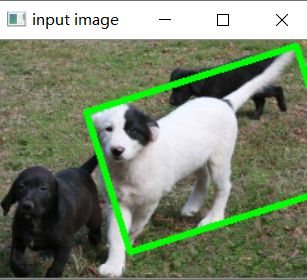
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
cropImg = image[y1:y1 + hight, x1:x1 + width]
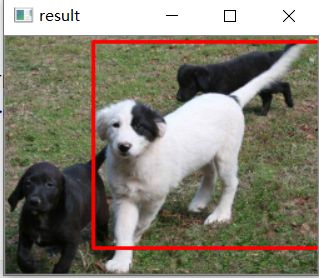
cv.rectangle(image, (x1, y1), (x1 + width, y1 +hight ), (0, 0, 255), 2) # 在原图上,给轮廓绘制矩形
cv.imshow('result',image)
所有代码
import cv2 as cv
import numpy as np
src= cv.imread("dog.16.jpg")
src=cv.resize(src,None,fx=0.5,fy=0.5)
image=src.copy()
#去噪
blurred = cv.GaussianBlur(image, (5, 5), 0) # 去噪
#灰度转换
gray = cv.cvtColor(blurred, cv.COLOR_BGR2GRAY)
#二值化
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
#轮廓发现
contours, hireachy = cv.findContours(binary, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
#取出最大轮廓
c = sorted(contours, key=cv.contourArea, reverse=True)[0]
#找到最大轮廓的最小外接矩形
rect = cv.minAreaRect(c)
#取出最小外接矩形的四个顶点
box = np.int0( cv.boxPoints(rect))
#绘制矩形框
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
cropImg = image[y1:y1 + hight, x1:x1 + width]
cv.rectangle(image, (x1, y1), (x1 + width, y1 + hight), (0, 0, 255), 2) # 在原图上,给轮廓绘制矩形
#显示
cv.imshow("input image", src)
cv.imshow('result', image)
cv.waitKey(0)
cv.destroyAllWindows()
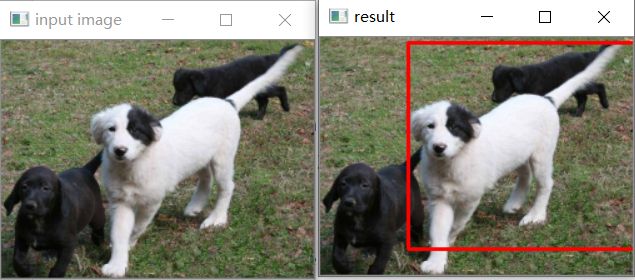
图像分类定位实现
我应用图像分类 加前面提到的定位 结合起来做 单目标的图像监测。
图像分类前面给出了链接,这里不再给啦,博文太多链接了,会被显示待审核。
PYQT 封装吧。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
# @Date : 2020/8/1
import sys
from PyQt5 import QtWidgets, QtCore, QtGui
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
import cv2
import keras
from keras .models import load_model
import numpy as np
import re
class picture(QWidget):
def __init__(self):
super(picture, self).__init__()
self.resize(600, 400)
self.setWindowTitle("猫狗分类")
self.btn = QPushButton()
self.btn.setText("打开图片")
self.btn.clicked.connect(self.openimage)
self.label = QLabel()
self.label.setText('图片路径')
self.labelimage = QLabel()
self.labelimage.setText("显示图片")
#self.labelimage.setFixedSize(500, 400)#设置尺寸
self.labelimage.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:10px;font-weight:bold;font-family:宋体;}"
)
#预测按钮
self.btnclass=QPushButton()
self.btnclass.setText('点击预测分类')
self.btnclass.clicked.connect(self.fenlei)
self.labelclass=QLabel()
self.labelclass.setText('预测类别')
self.labelclass.setStyleSheet("font:16pt '楷体';border-width:2px;border-style: inset;border-color:gray")
layout1=QVBoxLayout()
layout1.addWidget(self.btn)
layout1.addWidget(self.label)
layout1.addWidget(self.labelimage)
layout2 = QVBoxLayout()
layout2.addWidget(self.btnclass)
layout2.addWidget(self.labelclass)
layout=QVBoxLayout()
layout.addLayout(layout1)
layout.addLayout(layout2)
self.setLayout(layout)
def openimage(self):
imgName, imgType = QFileDialog.getOpenFileName(self, "打开图片", "", "*.jpg;;*.png;;All Files(*)")
#jpg = QtGui.QPixmap(imgName).scaled(self.labelimage.width(), self.label.height())#适应labelimage尺寸,前提是label设置了尺寸
jpg = QtGui.QPixmap(imgName)
self.labelimage.setPixmap(jpg)
self.label.setText(str(imgName))
def fenlei(self):
biaoqian = {'1': '猫', '0': '狗'}
path=self.label.text()
newName = re.sub('(D:/机器学习/学习草稿/)','', path)
#print(newName)
img = cv2.imread(str(newName))
img = cv2.resize(img, (100, 100)) # 使尺寸大小一样
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = np.array(img) / 255
img = img.astype(np.float64)
img = img.reshape(-1, 100, 100, 1)
model = load_model('猫狗分类.h5')
predict_y = model.predict(img)
pred_y = int(np.round(predict_y))
#print(pred_y)
self.labelclass.setText(biaoqian[str(pred_y)])
########图像定位
src = cv2.imread(str(newName))
src = cv2.resize(src, None, fx=0.5, fy=0.5)
image = src.copy()
# 去噪
blurred = cv2.GaussianBlur(image, (5, 5), 0) # 去噪
# 灰度转换
gray = cv2.cvtColor(blurred, cv2.COLOR_BGR2GRAY)
# 二值化
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 轮廓发现
contours, hireachy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 取出最大轮廓
c = sorted(contours, key=cv2.contourArea, reverse=True)[0]
# 找到最大轮廓的最小外接矩形
rect = cv2.minAreaRect(c)
# 取出最小外接矩形的四个顶点
box = np.int0(cv2.boxPoints(rect))
# 绘制矩形框
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
cropImg = image[y1:y1 + hight, x1:x1 + width]
cv2.rectangle(image, (x1, y1), (x1 + width, y1 + hight), (0, 0, 255), 2) # 在原图上,给轮廓绘制矩形
#显示在lableimage上
res = image
res = cv2.resize(res, (400, 300), interpolation=cv2.INTER_CUBIC) # 用cv2.resize设置图片大小
img2 = cv2.cvtColor(res, cv2.COLOR_BGR2RGB) # opencv读取的bgr格式图片转换成rgb格式
_image = QtGui.QImage(img2[:], img2.shape[1], img2.shape[0], img2.shape[1] * 3,
QtGui.QImage.Format_RGB888) # pyqt5转换成自己能放的图片格式
jpg_out = QtGui.QPixmap(_image) # 转换成QPixmap
self.labelimage.setPixmap(jpg_out) # 设置图片显示
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
my = picture()
my.show()
sys.exit(app.exec_())
说明:
model = load_model(‘猫狗分类.h5’)
导入训练好的分类模型
在PYQT中显示opencv图 核心代码
def setImage(self):
img = cv2.imread('test.jpg') #opencv读取图片
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #opencv读取的bgr格式图片转换成rgb格式
_image = QtGui.QImage(img2[:], img2.shape[1], img2.shape[0], img2.shape[1] * 3, QtGui.QImage.Format_RGB888) #pyqt5转换成自己能放的图片格式
jpg_out = QtGui.QPixmap(_image).scaled(self.imgLabel.width(), self.imgLabel.height()) #设置图片大小
self.imgLabel.setPixmap(jpg_out) #设置图片显示
结果演示

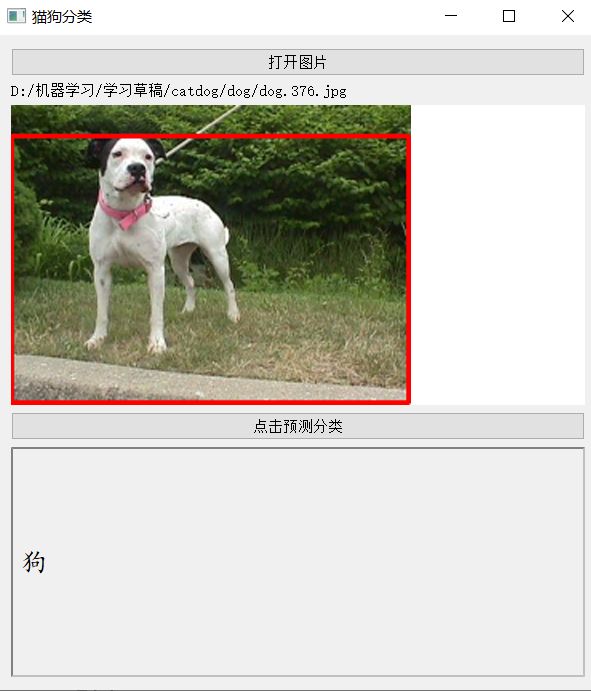
本文给出的方法不是纯粹的目标检测算法。定位有的图有所缺陷。
只是图像分类+对象测量 来实现单一目标检测功能
等我有时间研究下目标检测算法后,再来写博文。
电气专业的计算机萌新,写博文不容易,如果你觉得本文对你有用,请点个赞支持下,谢谢。
![]()