Hive
一、Hive
什么是Hive(一)
- Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
什么是Hive(二)
- Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
- Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
- Hive相当于hadoop的客户端工具,部署时不放在不一定放在集群节点中,可以放在某个节点上。
Hive的数据存储
- Hive的数据存储基于Hadoop HDFS
- Hive没有专门的数据存储格式
- 存储结构主要包括:数据库、文件、表、视图、索引
- Hive默认可以直接加载文本文件(TextFile),还支持SequenceFile、RCFile
- 创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据
Hive的系统架构

•用户接口,包括 CLI,JDBC/ODBC,WebUI
•元数据存储,通常是存储在关系数据库如 mysql, derby 中
•解释器、编译器、优化器、执行器
•Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
Hive的系统架构
- 用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
- CLI,即Shell命令行
- JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
- WebGUI是通过浏览器访问 Hive
- Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
Hive的metastore
- metastore是hive元数据的集中存放地。
- metastore默认使用内嵌的derby数据库作为存储引擎
- Derby引擎的缺点:一次只能打开一个会话
- 使用Mysql作为外置存储引擎,多用户同时访问
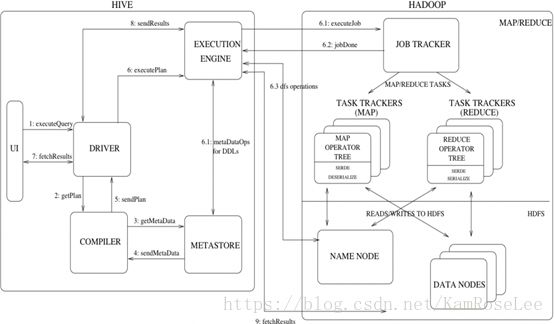
Hive与Hadoop的调用关系
Hive的安装
- 下载hive源文件
- 解压hive文件
- 进入$HIVE_HOME/conf/修改文件
- cp hive-env.sh.template hive-env.sh
- cp hive-default.xml.template hive-site.xml
- 修改$HIVE_HOME/bin的hive-env.sh,增加以下三行
- export JAVA_HOME=/usr/local/jdk1.7.0_45
- export HIVE_HOME=/usr/local/hive-0.14.0
- export HADOOP_HOME=/usr/local/hadoop-2.6.0
配置MySQL的metastore
修改$HIVE_HOME/conf/hive-site.xml
createDatabaseIfNotExist=true
临时目录的配置
修改$HIVE_HOME/conf/hive-site.xml\
Hive运行模式
- Hive的运行模式即任务的执行环境
- 分为本地与集群两种
我们可以通过mapred.job.tracker 来指明
设置方式:
hive > SET mapred.job.tracker=local;
set hive.exec.mode.local.auto=true
hive.exec.mode.local.auto.inputbytes.max
hive.exec.mode.local.auto.inputbytes.max
hive使用
- 命令行方式cli:控制台模式
- 脚本文件方式:实际生产中用的最多的方式
- JDBC方式:hiveserver
- web GUI接口 hwi方式
Hive命令行模式
- 直接输入#/hive/bin/hive的执行程序,
- 或者输入 #hive --service cli 启动
hive>show tables;
hive>create table test(id int,name string);
hive>quit;
观察:#hadoop fs -ls /user/hive/warehouse/修改参数:hive.metastore.warehouse.dir
表与目录的对应关系
hive参数配置使用
- 显示或者修改变量值
-

- 在代码中引用时使用${...};
-
hive的脚本执行
- $>hive -e ""
- $>hive -e "">aaa
- $>hive -S -e "">aaa
- $>hive -f file
- $>hive -i /home/my/hive-init.sql
- hive>source file
-
hive与依赖环境的交互
- 与linux交互命令 !
- !ls
- !pwd
- 与hdfs交互命令
- dfs -ls /
- dfs -mkdir /hive
-
hive的JDBC模式
- JAVA API交互执行方式
- hive 远程服务 (端口号10000) 启动方式
- #hive --service hiveserver2
- org.apache.hive.jdbc.HiveDriver
- 在java代码中调用hive的JDBC建立连接
-
hive web界面模式
web界面安装:
-
- 下载apache-hive-0.14.0-src.tar.gz
- 制作war包放在HIVE_HOME/lib/ : hwi/web/*里面所有的文件打成war包
- 复制tool.jar(jdk的lib包下面的jar包)到hive/lib下
- 修改hive-site.xml
-
hive.hwi.listen.host -
0.0.0.0 -
-
hive.hwi.listen.port -
9999 -
-
hive.hwi.war.file -
lib/hive-hwi-0.14.0.war
- hive web界面的 (端口号9999) 启动方式
-
#hive --service hwi &
- 用于通过浏览器来访问hive
-
http://hadoop0:9999/hwi/
set命令使用
- hive控制台set命令:
- set hive.cli.print.current.db=true;
- set hive.cli.print.header=true;
- set hive.metastore.warehouse.dir=/hive;
- hive参数初始化配置set命令:
- ~/.hiverc
- 补充:
- hive历史操作命令集
- ~/.hivehistory
-
二、基本数据类型

复合数据类型
- 创建学生表
hive>CREATE TABLE student(
id INT,
name STRING,
favors ARRAY
scores MAP
);
hive记录中默认分隔符

复合类型—Struct使用
- structs内部的数据可以通过DOT(.)来存取,例如,表中一列c的类型为STRUCT{a INT; b INT},我们可以通过c.a来访问域a
- hive> create table student_test(id INT, info struct
复合类型—Array使用
- array中的数据为相同类型,例如,假如array A中元素['a','b','c'],则A[1]的值为'b'
- create table class_test(name string, student_id_list array
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY ':';
复合类型—Map使用
- 访问指定域可以通过["指定域名称"]进行,例如,一个Map M包含了一个group-》gid的kv对,gid的值可以通过M['group']来获取
- create table employee(id string, perf map
三、数据定义
- 数据库定义
- 默认数据库"default"
- 使用#hive命令后,不使用hive>use <数据库名>,系统默认的数据库。可以显式使用hive> use default;
- 创建一个新库
hive>CREATE DATABASE
[IF NOT EXISTS] mydb
[LOCATION] '/.......'
[COMMENT] '....';
hive>SHOW DATABASES;
hive>DESCRIBE DATABASE [extended] mydb;
hive>DROP DATABASE [IF EXISTS] mydb [CASCADE];
表定义
hive>CREATE TABLE IF NOT EXISTS t1(...)
[COMMENT '....']
[LOCATION '...']
hive>SHOW TABLES in mydb;
hive>CREATE TABLE t2 LIKE t1;
hive>DESCRIBE t2;
列定义
- 修改列的名称、类型、位置、注释
hive>ALTER TABLE t3 CHANGE COLUMN old_name new_name String COMMENT '...' AFTER column2;
- 增加列
hive>ALTER TABLE t3 ADD COLUMNS(gender int);
Hive的数据模型-管理表
- 创建数据文件inner_table.dat
- 创建表
hive>create table inner_table (key string);
- 加载数据
hive>load data local inpath '/root/inner_table.dat' into table inner_table;
- 查看数据
select * from inner_table
select count(*) from inner_table
- 删除表 drop table inner_table
Hive的数据模型-管理表
- 管理表,也称作内部表,受控表
- 所有的 Table 数据(不包括 External Table)都保存在warehouse这个目录中。
- 删除表时,元数据与数据都会被删除
- 创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除
Hive的数据模型-外部表
- 创建数据文件external_table.dat
- 创建表
hive>create external table external_table1 (key string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/home/external';
在HDFS创建目录/home/external
#hadoop fs -put /home/external_table.dat /home/external
- 加载数据
LOAD DATA INPATH '/home/external_table1.dat' INTO TABLE external_table1;
- 查看数据
select * from external_table
select count(*) from external_table
- 删除表
drop table external_table
Hive的数据模型-外部表
- 包含External 的表叫外部表
- 删除外部表只删除metastore的元数据,不删除hdfs中的表数据
- 外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接
- 指向已经在 HDFS 中存在的数据,可以创建 Partition
- 它和 内部表 在元数据的组织上是相同的,而实际数据的存储则有较大的差异
Hive的数据模型-外部表语法
CREATE EXTERNAL TABLE page_view
( viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination‘
)
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION 'hdfs://centos:9000/user/data/staging/page_view';
Hive的数据模型-分区表
- 分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。
- 分类的标准就是分区字段,可以一个,也可以多个。
- 分区表的意义在于优化查询。查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
- hive>CREATE TABLE t3(...) PARTITIONED BY (province string);
- hive>SHOW PARTITIONS t3 [partition (province='beijing')];
- hive>ALTER TABLE t3 ADD [IF NOT EXISTS] PARTITION(...) LOCATION '...';
- hive>ALTER TABLE t3 DROP PARTITION(...);
Hive的数据模型-分区表
- 创建数据文件partition_table.dat
- 创建表
create table partition_table(rectime string,msisdn string) partitioned by(daytime string,city string) row format delimited fields terminated by '\t' stored as TEXTFILE;
- 加载数据到分区
load data local inpath '/home/partition_table.dat' into table partition_table partition (daytime='2013-02-01',city='bj');
- 查看数据
select * from partition_table
select count(*) from partition_table
•删除表 drop table partition_table
Hive的数据模型-分区表语法
CREATE TABLE tmp_table #表名
(
title string, # 字段名称 字段类型
minimum_bid double,
quantity bigint,
have_invoice bigint
)COMMENT '注释:XXX' #表注释
PARTITIONED BY(pt STRING) #分区表字段(如果你文件非常之大的话,采用分区表可以快过滤出按分区字段划分的数据)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001' # 字段是用什么分割开的
STORED AS SEQUENCEFILE; #用哪种方式存储数据,SEQUENCEFILE是hadoop自带的文件压缩格式
一些相关命令
SHOW TABLES; # 查看所有的表
SHOW TABLES '*TMP*'; #支持模糊查询
SHOW PARTITIONS TMP_TABLE; #查看表有哪些分区
DESCRIBE TMP_TABLE; #查看表结构
Hive的数据模型—桶表
- 桶表是对数据进行哈希取值,然后放到不同文件中存储。
- 创建表
create table bucket_table(id string) clustered by(id) into 4 buckets;
- 加载数据
set hive.enforce.bucketing = true;
insert into table bucket_table select name from stu;
insert overwrite table bucket_table select name from stu;
- 数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。
- 注意:
- 物理上,每个桶就是表(或分区)目录里的一个文件
- 一个作业产生的桶(输出文件)和reduce任务个数相同
Hive的数据模型—桶表
- 桶表的抽样查询
- select * from bucket_table tablesample(bucket 1 out of 4 on id);
- tablesample是抽样语句
- 语法解析:TABLESAMPLE(BUCKET x OUT OF y)
- y必须是table总bucket数的倍数或者因子。
- hive根据y的大小,决定抽样的比例。
- 例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。
- 例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
hive视图的操作
- 使用视图可以降低查询的复杂度
- 视图的创建
- create view v1 AS select t1.name from t1;
- 视图的删除
- drop view if exists v1;
hive索引的操作
- 创建索引
- create index t1_index on table t1(name)as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild in table t1_index_table;
- as指定索引器,
- 重建索引
- alter index t1_index on t1 rebuild;
- 显示索引
- show formatted index on t1;
- 删除索引
- drop index if exists t1_index on t1;
装载数据
- 从文件中装载数据
hive>LOAD DATA [LOCAL] INPATH '...' [OVERWRITE] INTO TABLE t2 [PARTITION (province='beijing')];
- 通过查询表装载数据
hive>INSERT OVERWRITE TABLE t2 PARTITION (province='beijing') SELECT * FROM xxx WHERE xxx
hive>FROM t4
INSERT OVERWRITE TABLE t3 PARTITION (...) SELECT ...WHERE...
INSERT OVERWRITE TABLE t3 PARTITION (...) SELECT ...WHERE...
INSERT OVERWRITE TABLE t3 PARTITION (...) SELECT ...WHERE...
动态分区装载数据
- 不开启只支持
hive>INSERT OVERWRITE TABLE t3 PARTITION(province='bj', city)
SELECT t.province, t.city FROM temp t WHERE t.province='bj';
- 开启动态分区支持
hive>set hive.exec.dynamic.partition=true;
hive>set hive.exec.dynamic.partition.mode=nostrict;
hive>set hive.exec.max.dynamic.partitions.pernode=1000;
#查询字段一样
hive>INSERT OVERWRITE TABLE t3 PARTITION(province, city)
SELECT t.province, t.city FROM temp t;
- 单语句建表并同时装载数据
hive>CREATE TABLE t4 AS SELECT ....
导出数据
- 在hdfs复制文件(夹)
$ hadoop fs -cp source destination
- 使用DIRECTORY
hive>INSERT OVERWRITE 【LOCAL】 DIRECTORY '...' SELECT ...FROM...WHERE ...;
读模式与写模式
- RDBMS是写模式
- Hive是读模式
完整建表语句语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) ON ([(col_value, col_value, ...), ...|col_value, col_value, ...])
[STORED AS DIRECTORIES] ]
[ [ROW FORMAT row_format]
[STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] ]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement] (Note: not supported when creating external tables.)
文件格式
- TextFile
- SequenceFile
- RCFile
- ORC
使用SequenceFile存储
- > create table test2(str STRING) STORED AS SEQUENCEFILE;
- hive> set hive.exec.compress.output=true;
- hive> set mapred.output.compress=true;
- hive> set mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
- hive> set io.seqfile.compression.type=BLOCK;
- hive> set io.compression.codecs=com.hadoop.compression.lzo.LzoCodec;
- hive> INSERT OVERWRITE TABLE test2 SELECT * FROM test1;
使用RCFile存储
- RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
- hive> create table test3(str STRING) STORED AS RCFILE;
- hive> set hive.exec.compress.output=true;
- hive> set mapred.output.compress=true;
- hive> set mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
- hive> set io.compression.codecs=com.hadoop.compression.lzo.LzoCodec;
- hive> INSERT OVERWRITE TABLE test3 SELECT * FROM test1;
使用ORC存储
- hive> create table t1_orc(id int, name string) row format delimited fields terminated by '\t' stored as orc tblproperties("orc.compress"="ZLIB");
- ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC
- hive> SET hive.default.fileformat=Orc;
- hive> insert overwrite table t1_orc select * from t1;

Hive SerDe
- What is a SerDe?
- SerDe 是 "Serializer and Deserializer."的缩写
- Hive 使用 SerDe和FileFormat进行行内容的读写.
- HDFS文件 --> InputFileFormat -->
- 行对象 --> Serializer -->
- 注意: 数据全部存在在value中,key内容无意义。
- Hive 使用如下FileFormat 类读写 HDFS files:
- TextInputFormat/HiveIgnoreKeyTextOutputFormat: 读写普通HDFS文本文件.
- SequenceFileInputFormat/SequenceFileOutputFormat: 读写SequenceFile格式的HDFS文件.
- Hive 使用如下SerDe 类(反)序列化数据:
- MetadataTypedColumnsetSerDe: 读写csv、tsv文件和默认格式文件
- ThriftSerDe: 读写Thrift 序列化后的对象.
- DynamicSerDe: 读写Thrift序列化后的对象, 不过不需要解读schema中的ddl.
使用CSV Serde
- CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
- 默认的分隔符是
- DEFAULT_ESCAPE_CHARACTER \
- DEFAULT_QUOTE_CHARACTER " ---如果没有,则不需要指定
- DEFAULT_SEPARATOR ,
- CREATE TABLE csv_table(a string, b string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = "\t", "quoteChar" = "'", "escapeChar" = "\\") STORED AS TEXTFILE;
- separatorChar:分隔符
- quoteChar:引号符
- escapeChar:转意符
存储总结
- textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高
- sequencefile 存储空间消耗大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载
- rcfile 存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低
Lateral View语法
- lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
- 创建表
- create table t8(name string,nums array
)row format delimited fields terminated by "\t" COLLECTION ITEMS TERMINATED BY ':';
- 数据切割
- SELECT name,new_num FROM t8 LATERAL VIEW explode(nums) num AS new_num;
四、hive的高级函数
- 简单查询
select ... from...where...
- 使用各种函数
hive>show functions;
hive>describe function explode;
- LIMIT语句
- 列别名
- 嵌套select语句
- 标准函数
- reverse()
- upper()
- 聚合函数
- avg()
- sum()
- 自定义函数
- UDF
hive性能调优
- 什么时候可以避免执行MapReduce?
- select * or select field1,field2
- limite 10
- where语句中只有分区字段
- 使用本地set hive.exec.mode.local.auto=true;
- group by语句:
- 通常和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每组执行聚合操作
- having语句:
- 限制结果的输出
- hive将查询转化为MapReduce执行,hive的优化可以转化为mapreduce的优化!
- hive是如何将查询转化为MapReduce的?
- EXPLAIN的使用
- hive对sql的查询计划信息解析
- EXPLAIN SELECT COUNT(1) FROM T1;
- EXPLAIN EXTENDED
- 显示详细扩展查询计划信息
性能调优—本地mr
- 本地模式设置方式:
- set mapred.job.tracker=local;
- set hive.exec.mode.local.auto=true;
- 测试 select 1 from wlan limit 5;
- 下面两个参数是local mr中常用的控制参数:
1,hive.exec.mode.local.auto.inputbytes.max默认134217728
设置local mr的最大输入数据量,当输入数据量小于这个值的时候会采用local mr的方式
2,hive.exec.mode.local.auto.input.files.max默认是4
设置local mr的最大输入文件个数,当输入文件个数小于这个值的时候会采用local mr的方式
- 开启并行计算,增加集群的利用率
- set hive.exec.parallel=true
- 设置严格模式
- set hive.mapred.mode=strict | nostrict;
- strict可以禁止三种类型的查询:
- 一、强制分区表的where条件过滤
- 二、Order by语句必须使用limit
- 三、限制笛卡尔积查询
- 调整mapper和reducer的数量
- 太多map导致启动产生过多开销
- 按照输入数据量大小确定reducer数目,
- set mapred.reduce.tasks= 默认3
- dfs -count /分区目录/*
- hive.exec.reducers.max设置阻止资源过度消耗
- JVM重用
- 小文件多或task多的业务场景
- set mapred.job.reuse.jvm.num.task=10
- 会一直占用task槽
- order by 语句: 是全局排序
- sort by 语句: 是单reduce排序
- distribute by语句: 是分区字段排序;
- cluster by语句:
- 可以确保类似的数据的分发到同一个reduce task中,并且保证数据有序防止所有的数据分发到同一个reduce上,导致整体的job时间延长
- cluster by语句的等价语句:
- distribute by Word sort by Word ASC
性能调优—Map-side聚合
- set hive.map.aggr=true;
- 这个设置可以将顶层的聚合操作放在Map阶段执行,从而减轻清洗阶段数据传输和Reduce阶段的执行时间,提升总体性能。
- 缺点:该设置会消耗更多的内存。
- 执行select count(1) from wlan;
性能调优-jion优化
- 驱动表最右边
- 查询表表的大小从左边到右边依次增大
- 标志机制
- 显示的告知查询优化器哪张表示大表
- /*+streamtable(table_name)*/
表连接 (只支持等值连接)
- INNER JOIN
- 两张表中都有,且两表符合连接条件
- select t1.name,t1.age,t9.age from t9 join t1 on t1.name=t9.name;
- LEFT OUTER JOIN
- 左表中符合where条件出现,右表可以为空
- RIGHT OUTER JOIN
- 右表中符合where条件出现,左表可以为空
- FULL OUTER JOIN
- 返回所有表符合where条件的所有记录,没有NULL替代
- LEFT SEMI-JOIN
- 左表中符合右表on条件出现,右表不出现
- select t1.name,t1.age from t9 LEFT SEMI JOIN t1 on t1.name=t9.name;
- 笛卡尔积
- 是m x n的结果
- map-side JOIN
- 只有一张小表,在mapper的时候将小表完全放在内存中
- select /*+ mapjoin(t9) */t1.name,t1.age from t9 JOIN t1on t1.name=t9.name;
hive的UDF操作
1、UDF函数可以直接应用于select语句,对查询结构做格式化处理后,再输出内容。
2、编写UDF函数的时候需要注意一下几点:
a)自定义UDF需要继承org.apache.hadoop.hive.ql.UDF。
b)需要实现evaluate函数,evaluate函数支持重载。
4、步骤
a)把程序打包放到目标机器上去;
b)进入hive客户端,添加jar包:hive>add jar /run/jar/udf_test.jar;
c)创建临时函数:hive>CREATE TEMPORARY FUNCTION add_example AS 'hive.udf.Add';
d)查询HQL语句:
SELECT add_example(8, 9) FROM scores;
SELECT add_example(scores.math, scores.art) FROM scores;
SELECT add_example(6, 7, 8, 6.8) FROM scores;
e)销毁临时函数:hive> DROP TEMPORARY FUNCTION add_example;
注:UDF只能实现一进一出的操作,如果需要实现多进一出,则需要实现UDAF
Hive与传统数据库比较

总结
- MapReduce程序计算KPI
- HBASE详单查询
- HIVE数据仓库多维分析
