分析显著性目标检测--A Mutual Learning Method for Salient Object Detection with intertwined Multi-Supervision
分析显著性目标检测–A Mutual Learning Method for Salient Object Detection with intertwined Multi-Supervision
本文是在阅读A Mutual Learning Method for Salient Object Detection with intertwined Multi-Supervision后浅谈对于此模型方法的理解,做出部分解读,若有地方理解不对,欢迎提出批评与指正!
文章目录
1.摘要
2.相关工作
- 集成层次特征
- 利用边缘信息
3.方法解析 - 体系结构概述
- 交织监督方式
- 训练策略
4.实验解析 - 数据集
- 实现细节
- 性能比较
- 消融实验
- 边缘检测
5.总结
摘要与背景
显著目标检测是将给定图像中最具特色的目标区域分割出来,是完成图像字幕、视觉跟踪、视觉答疑、人物重新识别等视觉任务的重要预处理步骤。
前景轮廓检测(foreground contour detection):指在包含目标和背景的数字图像中,忽略背景和目标内部的纹理以及噪声干扰的影响,采用一定的技术和方法来实现目标轮廓提取的过程。它是目标检测、形状分析、目标识别和目标跟踪等技术的重要基础。
边缘检测:边缘检测的目的是标识数字图像中亮度变化明显的点。
现存方法的缺陷:由于对象内部的复杂性以及卷积和池化操作的跨步导致的边界不准确,预测的显著性映射仍然存在预测不完全的问题。该缺陷从下图可以看出:

提出的新方法:1.我们以一种交织的方式利用显著对象检测和前景轮廓检测任务来生成具有统一高亮的显著性地图;2.前景轮廓和边缘检测任务同时引导,从而实现前景轮廓的精确预测,减少边缘预测的局部噪声;3.我们开发了一个新的互学习模块(MLM)作为我们的方法的基石。每个MLM由多个网络分支机构组成,通过相互学习的方式进行培训,大大提高了MLM网络的性能;
1.首先,我们采用突出物检测和前景轮廓检测相互交织的方式,以产生完全均匀高亮的显著性地图。这两个任务是高度相关的,因为它们都要求精确的前景检测。然而,在显著性检测涉及密集标记的场景中,它们也是不同的。(如“填充”物体内部区域),更容易受到突出物体内部复杂性的影响,导致前景突出不均匀。相比之下,在给定前景对象的粗略位置后,可以根据低层次线索(如边缘和纹理)“提取”前景轮廓。因此,轮廓检测任务对物体内部结构的鲁棒性更强,但可能会被物体轮廓周围丰富的边缘信息所误导。
2.其次,为了缓解预测显著性地图中的模糊边界问题,提出了利用边缘检测任务的辅助监督来改进前景轮廓检测。为此,我们设计了一个边缘模块,并与我们的骨干网共同训练。边缘模块以主干网络的显著性特征作为输入,在这些显著性特征中编码语义信息,可以有效地抑制局部边缘的噪声。同时,边缘模块提取的边缘特征作为前景轮廓检测的附加输入,保证了低层次线索的检测结果更加准确。
3.第三,为了进一步提高性能,我们借鉴深度互学习(DML)的成功经验,提出了一种新的互学习模块(MLM)。MLM建立在我们的骨干网络的每个块上,并由多个子网组成,这些子网被训练在模仿的模仿策略,产生额外的性能增益;
相关工作(Related work)
有效地利用空间细节和语义信息是实现最先进的显著目标检测性能的关键因素。大多数现有的方法使用跃连接或递归结构来整合卷积神经网络(CNNs)的层次特征。它们可以粗略地检测出目标,但不能统一地突出整个目标,还存在边界模糊的问题。为了产生清晰的边界,一些方法尝试引入额外的边缘信息到显著性网络。
集成层次特征Integrating Hierarchical Features
跃连接(Skip-connection)
在HED中,作者提出建立跃接来利用多尺度深度特征进行边缘检测。边缘检测是一项比较容易的任务,因为它不太依赖高层信息。而显著性目标检测则需要大量的语义特征。因此,直接在显著目标检测中引入跳跃连接是不理想的。DSS[10]中提出的一个名为短连接的升级版本解决了这个问题,它将较深的层连接到较浅的层,并跳过中间的层。SRM[23]的另一项工作提出了分段细化模型和金字塔池模块来集成局部和全局上下文信息来进行显著性预测。这样,多尺度特征图可以帮助定位突出目标,更有效地恢复局部细节。
周期性架构(Recurrent Architecture)
为了提高推理的准确性,提出了一种循环完全卷积网络(RFCN)。它可以通过反复使用的架构来修正以前的错误,从而改进显著性映射。在DHS[16]中引入了递归卷积层(RCL),通过集成本地上下文信息逐步恢复显著性映射的图像细节。
利用边缘信息
最近有一些尝试利用额外边缘信息来进行显著性检测,以产生具有清晰边界的预测地图。在[30]中,对显著性目标、显著性目标边界和背景进行了新的密集标记,以提高显著性边界检测的准确性。此外,还引入了额外的手工边缘特征作为补充,有效地保留了边缘信息。在[25]和[26]中,边缘知识用于检测区域建议。他们首先利用预先训练好的边缘检测模型来检测物体的边缘。然后基于检测到的边缘,将输入图像分割成边缘区域(类似于超像素),并通过基于掩模的快速R-CNN生成每个区域的显著性评分图。利用基于边缘区域的方法,模型在显著性检测中成功地保留了目标的边界。
方法解析
体系结构概述
架构试图:网络采用了编解码器架构,由四个主要组件组成,分别是VGG[20]主干、互学习模块(MLM)、边缘模块(EM)和解码器块。下图显示了网络概况。

编码器部分:由VGG-16主干、6个互学习模块和3个边缘模块组成。对于vga -16主干,我们丢弃了pool5之后的层,并将剩余的块(conv1 ~ conv5, pool5)表示为block0 ~ block5。在每个图像块的基础上建立6个图像块,提取出图像的前景轮廓特征和显著性特征。另外,我们在每个块上应用一个EM提取边缘特征,每个EM与对应的VGG块中的所有卷积层相连接。我们使用残差架构在EM和相应的传销之间转移特征。
译码器部分:使用一个类似于U-net的深度监督框架来融合MLMs的多尺度特性并生成预测。这五个解码器块(D0 ~ D4)共享类似的结构。每个解码器块的目的是融合的特点,从MLM和前一个块的上采样特征。它合并输入特征和输出上采样特征到下一个块通过反褶积层。此外,为了深度监控,我们采用卷积层在每个区块生成一个预测图。
MLM:互学习模块(MLM)是在深度互学习(DML)成功的启发下,旨在提高显著性检测和前景轮廓检测的性能,MLM中的学习网络都是一个简单的子网络,由三个连续的层组成,目的是提取特征并生成预测,如下图所示:(为了获得全局的精细信息,我们设置了更大的带扩张的卷积核)
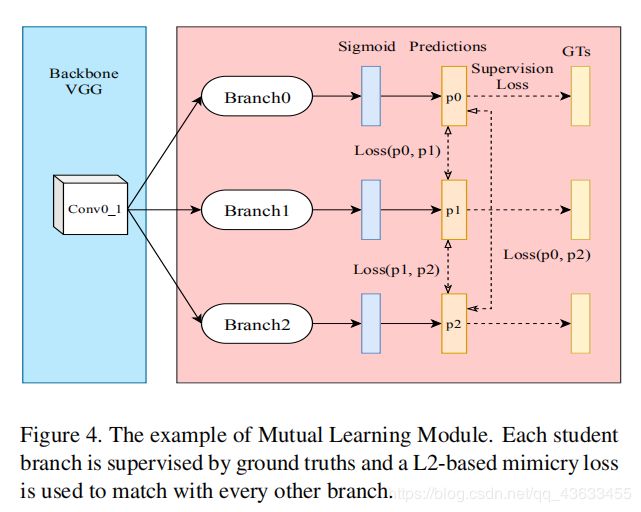
第i个块的预测公式为:
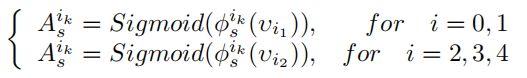
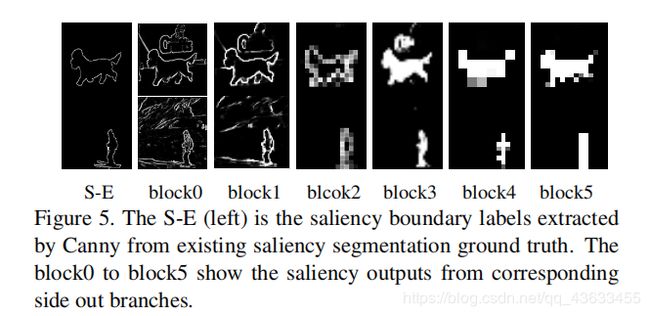
通过相互学习,每个子网的损失较小,使得每个学生网络的参数收敛到一个更好的局部极小值。具体地说,基于观测,在FC-gt的监督下,采用较浅的三个MLMs进行前景轮廓检测。较深的三个MLMs由S-gt监督,用于显著性检测。每个MLM的预测如图5所示。
边缘模块:在[9]中,作者在预先训练过的vgg19模型中对神经元的接受区进行了可视化,在此之前和之后进行了微调,以完成显著性检测任务。结果表明,对于显著性任务进行微调后,前三层池化神经元的响应基本没有变化。更重要的是,即使为了显著性检测而对网络进行微调,神经元在前三个卷积层的反应仍然与边缘模式有很多相似之处。这表明,预训练的VGG的前三个块适合同时捕获边缘信息和显著性信息。在此基础上,我们在MLM中每前三个VGG块上都使用一个额外的边缘模块(EM)来完成边缘检测和前景轮廓检测.

具体来说,对于输入图像E,每个EM都会生成一个边缘概率图Aie,输出会被收集并合并到最终的边缘预测E∗对于输入图像S, EM仅为MLM提供边缘特征映射aie。两个模块以残差方式连接,旨在降低前景轮廓检测中边缘特征的噪声。对于第i块,将EM的函数表示为阶次i,其输出特征图aie和边缘概率图aie可表示为:
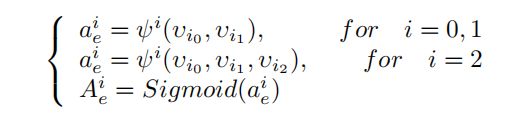
交织监督方式(intertwined supervision method)
在提出的MLM中,我们在较浅的三个MLM中使用FC-gt作为监督,以保持轮廓的精细细节信息,在较深的三个MLM中使用S-gt作为监督,以关注语义信息。我们进一步以交织的方式在不同的解码器块上交替地应用两个任务。S-gt在D0、D2、D4处进行监督,FC-gt在D1、D3处进行监督。每个解码器块的目的是融合来自前一个块和相应传销的特征,然后将特征传输到下一个块。
D1:D1块接收高层语义信息,在FC-gt的监督下将其传输到前景轮廓特征中,最终丢弃了目标的内部噪声,提取的轮廓特征更加清晰。
D2:D2块在一个“填充”方案中工作,接受轮廓特征,然后将它们传输到显著特征。它需要根据轮廓特征检索内部信息,这就迫使D2对轮廓内的每个像素产生统一的预测分数,就像一个“填充”的过程。
D3:接收D2的相对干净的语义信息和来自于浅层MLM的低层轮廓信息发送到D3块。在FC-gt的监督下,D3块的目标是保持前景轮廓的精确,并利用高级语义知识去除低层轮廓信息中多余的噪声。
D4:D4与D2工作类似,在S-gt的监督下,尝试基于前景信息填充显著性图。
结果:在FC-gt和S-gt的这种交织的监督下,我们的方法成功地产生了具有完整均匀高亮的显著性预测,同时保持了良好的前景轮廓。
训练策略(Training Strategy)
损失函数
在深监督之下,缩放三种真值到对应的尺度。总损失包含两部分,即编码损失和解码损失;
编码损失可表示为:(此处,LS, LE, and Lmimicry为显著目标检测、边缘检测和模拟损失的损失函数, θs为他们的权重,分别设置为:0.7,0.2,0.1)
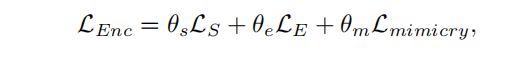
LS, LE, and Lmimicry的计算公式:
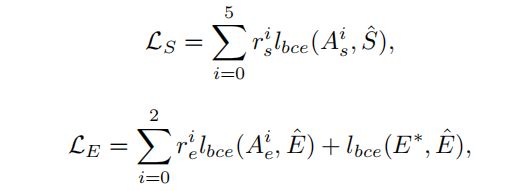
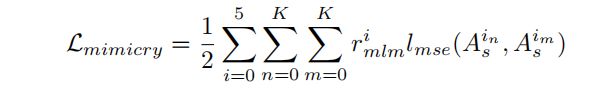
解码损失:第i个解码块的权重表示为ri,解码损失表示为:
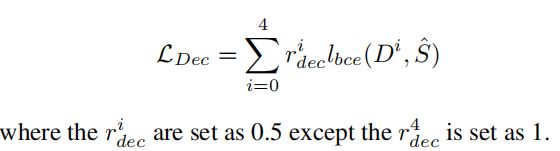
训练步骤:
最终使用交替训练的方式来训练编码器和解码器网络:
Step1:首先训练编码器网络,此时损失使用LEnc。
Step2:调整编码器,馈送MLM的特征到解码器网络来训练解码器网络,此时损失使用LDec。
Step3:在训练了解码器之后,固定解码器,微调编码器,使用解码器的监督来训练。此时损失使用的是LDec,进一步优化编码器。
实际中迭代重复以上步骤,在训练中,每10个周期便切换到下一个步骤。
实验解析
数据集
- 显著性检测任务:使用DUTS的训练集训练,测试在DUTS的测试集和其他的显著性检测的数据集
- 边缘检测任务:使用BSD500数据集来训练和测试
实现细节
利用预先训练好的vgg16模型对主干网中的卷积层进行初始化。其他卷积层中的参数是随机初始化的。所有的训练和测试图像在输入网络之前都被调整为256×256。我们使用“亚当”方法,其重量衰减为0.005。编码器的学习率设置为0.0004,解码器设置为0.0001。
性能比较
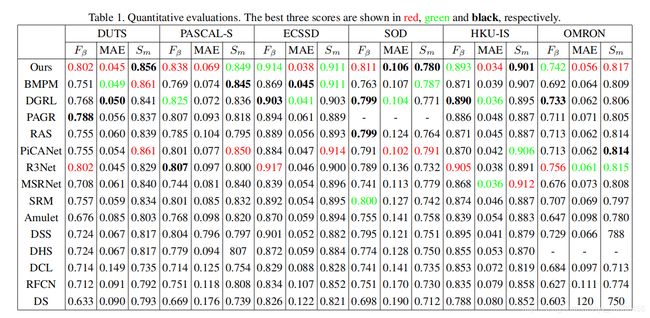
显著目标检测任务定量评价:将提出的新方法与14个优秀的显著目标检测方法比较,测试结果如下图:
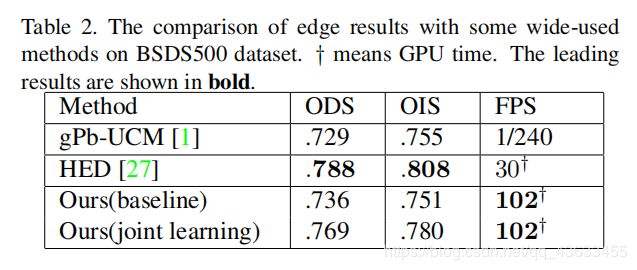
边缘检测比较结果:
消融实验
通过删除部分部分网络研究网络性能来研究实验(个人理解为类似于控制变量法),四种训练模型如下:
1)baseline: a network with simple encoder-decoder architecture as proposed using only S-gt for supervision, and removes the EMs and redundant student branches in MLMs
2)+MLM: adding three student branches in each MLM
3)+FC: applying S-gt and FC-gt for supervision in intertwined manner
4)+EM: the proposed whole network with S-gt and FC-gt for supervision in intertwined manner and employing the EM for edge detection simultaneously.
在数据集上测测试结果如下图:

此外,这里进一步计算了两个额外的指标,一个是the average score of the highlight pixel in saliency maps (ASHP),一个是the accuracy of foreground contour predictions (AFCP),二者的公式如下:
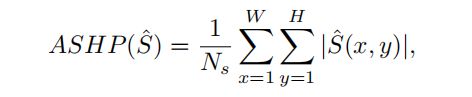
这里的式子中的hatS表示预测的显著性图,这里的Ns表示在hatS上取值大于0的像素数量。也就是计算了在预测的显著性图上的显著性区域均匀高亮的程度。
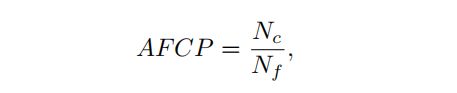
这里的式子中的Nc表示在给定的前景轮廓预测图F和显著性预测图hatS中,满足二者差距小于60的且对应的显著性图中值大于200的像素数量。而Nf表示显著性图上像素值大于200的像素数量。这里实际上衡量了对于预测的显著性图的轮廓的预测能力,一定程度上反映了预测的显著性图的边界的饱满程度。

从图中可以看出:
- MLMs可以将基准模式的低准确率提高到具有竞争力的规模;
- +FC较高的ASHP表明,相互交织的监督有助于产生具有统一亮点的预测;
- +EM在AFCP上的改进表明,EMs有利于生成更精确的前景轮廓;
边缘检测
为了研究联合学习方法在边缘检测中的有效性,我们评估了仅使用边缘监督和特殊任务训练的整体性能。对比结果如下图所示。我们发现,边缘检测网络通过与突出任务的联合学习,能够获得更好的语义信息。该策略抑制了局部冗余细节的噪声,显著提高了边缘性能。

总结
1.这篇文章中,提出了一种综合显著目标检测、前景轮廓检测和边缘检测的多任务算法,使用显著目标检测和前景轮廓检测交织监督的策略,使网络在整个目标物体产生较高预测分数;
2.此外,显著目标检测与边缘检测互相指导,互相受益;
3.提出了一种互相学习模型(MLM),允许网络参数收敛到一个更好的局部极小值,从而提高性能;
通过这种方式,模型能够产生预测突出物体内部具有统一的突出区域和准确的边界。实验证明这些机制可以导致更精确的显著性地图上的各种图像,同时,我们的模型能够更快地检测出满意的边缘。