[论文笔记] 领域自适应系列论文笔记
目录
1. 背景知识
2. Unsupervised Domain Adaptation by Backpropagation
3. Adversarial Discriminative Domain Adaptation
4. Conditional Adversarial Domain Adaptation
5. Transferable Attention for Domain Adaptation
6. GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation
7. Transfer Learning with Dynamic Adversarial Adaptation Network
8. 推荐入门资料
1. 背景知识
-
关于 Transfer Learning
关于 Transfer Learning,推荐大家看这篇综述::
- 《A Survey on Transfer Learning》
作者:Sinno Jialin Pan, Qiang Yang ,发表日期:2009
-
定义
在论文《A Survey on Transfer Learning》中,作者对迁移学习做出了如下定义: Given a source domain D S D_S DS and learning task T S T_S TS, a target domain D T D_T DT and learning task T T T_T TT , transfer learning aims to help improve the learning of the target predictive function f T ( ⋅ ) f_T (·) fT(⋅) in D T D_T DT using the knowledge in D S D_S DS and T S T_S TS, where D S ≠ D T D_S \neq D_T DS=DT , or T S ≠ T T T_S \neq T_T TS=TT .
其中,Domain 的定义为 D = { X , P ( X ) } D=\{\mathcal{X},P(X)\} D={X,P(X)},即由特征空间 X \mathcal{X} X 和边缘概率分布 P ( X ) P(X) P(X) 组成;Task 的定义为 T = { Y , P ( Y ∣ X ) } T=\{\mathcal{Y},P(Y|X)\} T={Y,P(Y∣X)},即由标签空间 Y \mathcal{Y} Y 和条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 组成。
PS: 随着人们对迁移学习领域的不断深入,许多过去所使用的名称已经淘汰或者其侧重点发生更变或者变成迁移学习的子领域,比如:learning to learn,life-long learning,multi-task learning 等等。
![[论文笔记] 领域自适应系列论文笔记_第1张图片](http://img.e-com-net.com/image/info8/6ce1bc354d6a425aa164929f5e8366a0.jpg)
图源自:A Survey on Transfer Learning, 2009, Sinno Jialin Pan and Qiang Yang -
子领域划分
在论文《A Survey on Transfer Learning》中,作者对迁移学习进行了划分:Inductive Transfer Learning,Transductive Transfer Learning,Unsupervised Transfer Learning。其中,各类别定义如下所示:
- Inductive Transfer Learning : Given a source domain D S D_S DS and a corresponding learning task T S T_S TS, a target domain D T D_T DT and a corresponding learning task T T T_T TT , inductive transfer learning aims to help improve the learning of the target predictive function f T ( ⋅ ) f_T (·) fT(⋅) in D T D_T DT using the knowledge in D S D_S DS and T S T_S TS, where T S ≠ T T T_S \neq T_T TS=TT .
- Transductive Transfer Learning : Given a source domain D S D_S DS and a corresponding learning task T S T_S TS, a target domain D T D_T DT and a corresponding learning task T T T_T TT , transductive transfer learning aims to improve the learning of the target predictive function f T ( ⋅ ) f_T (·) fT(⋅) in D T D_T DT using the knowledge in D S D_S DS and T S T_S TS, where D S ≠ D T D_S \neq D_T DS=DT and T S = T T T_S = T_T TS=TT . In addition, some unlabeled target domain data must be available at training time.
- Unsupervised Transfer Learning : Given a source domain D S D_S DS with a learning task T S T_S TS, a target domain D T D_T DT and a corresponding learning task T T T_T TT , unsupervised transfer learning aims to help improve the learning of the target predictive function f T ( ⋅ ) f_T (·) fT(⋅) in D T D_T DT using the knowledge in D S D_S DS and T S T_S TS, where T S ≠ T T T_S \neq T_T TS=TT and Y S Y_S YS and Y T Y_T YT are not observable.
![[论文笔记] 领域自适应系列论文笔记_第2张图片](http://img.e-com-net.com/image/info8/aeddaf0dd0614f0c8625580cc002553b.jpg)
![[论文笔记] 领域自适应系列论文笔记_第3张图片](http://img.e-com-net.com/image/info8/db39121a47284cd39cf71d3e558956dc.jpg)
图源自:A Survey on Transfer Learning, 2009, Sinno Jialin Pan and Qiang Yang -
常见方法的分类
- 基于样本迁移(Instance based Transfer Learning):根据一定的权重生成规则,对源域样本数据进行权重调整,以此在目标域的学习过程中重新使用,从而进行迁移学习。
- 基于特征迁移(Feature based Transfer Learning):通过学习“好”的特征表达(Feature Representation),缩小源域与目标域特征分布的差距,从而提高模型在目标域的表现效果。如何判断所学的特征表达是否“好”,是这一类方法的核心,常用的手段是以最大均值差异(Maximum Mean Discrepancy, MMD)作为度量准则,将源域与目标域的特征分布的差异最小化。
- 基于参数迁移(Parameter based Transfer Learning):假设源域与目标域的数据可以共享部分模型的参数,通过所设计算法找到可共享的模型参数,从而进行迁移学习。平时所经常提及的参数微调(Fine-tune)也属于此,有篇文章专门对此进行了实验讨论:《How transferable are features in deep neural networks》。
- 基于关系迁移(Relation Based Transfer Learning):假设源域数据之间的关系与目标域数据之间的关系相似,通过挖掘源域和目标域的样本之间的关系,进行迁移学习。
![[论文笔记] 领域自适应系列论文笔记_第4张图片](http://img.e-com-net.com/image/info8/49eed89ae8b3474885fed4d75616dc28.jpg)
图源自:A Survey on Transfer Learning, 2009, Sinno Jialin Pan and Qiang Yang
- 《A Survey on Transfer Learning》
-
关于 Domain Adaptation
关于Domain Adaptation,推荐大家看这篇综述:
- Deep Visual Domain Adaptation: A Survey
作者:Mei Wang, Weihong Deng ,发表日期:2018
-
定义
在论文《A Survey on Transfer Learning》中,作者指出 Domain Adaptation 属于 Transductive Transfer Learning,即 T S = T T T_S = T_T TS=TT, D S ≠ D T D_S \neq D_T DS=DT。在《Deep Visual Domain Adaptation: A Survey》中,作者将 Domain Adaptation 划分为 Homogeneous Domain Adaptation 和 Heterogeneous Domain Adaptation,前者 X S = X T \mathcal{X_S} = \mathcal{X_T} XS=XT, P ( X S ) ≠ P ( X T ) P(X_S) \neq P(X_T) P(XS)=P(XT),后者 X S ≠ X T \mathcal{X_S} \neq \mathcal{X_T} XS=XT。
![[论文笔记] 领域自适应系列论文笔记_第5张图片](http://img.e-com-net.com/image/info8/d66e40a62f0c4f76ac9fe54b1ebf91cb.jpg)
图源自:Deep Visual Domain Adaptation: A Survey, 2018, Mei Wang and Weihong Deng -
常见方法的分类
在论文《Deep Visual Domain Adaptation: A Survey》,作者将 Domain Adaptation 的方法分为了三类,分别如下所示:
- 基于差异自适应(Discrepancy based Domain Adaptation):利用源域与目标域数据对模型进行微调,以此缩小域偏差(Domain Shift),从而进行领域自适应。
- 基于对抗学习自适应(Adversarial based Domain Adaptation):通过与判别器的对抗,生成器将源域和目标域数据在数据空间或者特征空间对齐,以此学习具有域不变性的特征,从而进行领域自适应。
- 基于数据重构自适应(Reconstruction based Domain Adaptation):使用数据重构作为辅助任务,以此确保所学到的特征不变,从而进行领域自适应。
![[论文笔记] 领域自适应系列论文笔记_第6张图片](http://img.e-com-net.com/image/info8/136034bf99d04956a5687f0cb1b6f8c4.jpg)
图源自:Deep Visual Domain Adaptation: A Survey, 2018, Mei Wang and Weihong Deng Discrepancy based Domain Adaptation 可以根据所使用准则(Criterion)进行划分,具体如下所示:
- Class Criterion:利用标签信息作为迁移的指导。在 supervised DA 中,除了直接使用标签外,可以采用 soft label 和 metric learning;在 semi-supervised DA 和 unsupervised DA 中,可以采用 pseudo label 和 attribute representation。
- Statistic Criterion:对齐源域与目标域的统计分布,常用的度量准则为 MMD。
- Architecture Criterion:通过调整模型的结构/参数,提高模型迁移特征的能力。
- Geometric Criterion:利用源域与目标域的几何特性进行领域自适应。该准则假设源域与目标域的几何结构的关系可以减少域偏移。
Adversarial based Domain Adaptation 可以根据是否使用生成式模型(Generative Model)进行划分,具体如下所示:
- Generative Model:使用生成式模型。
- Non-Generative Model:不使用生成式模型。
Reconstruction based Domain Adaptation 可以根据数据重构的方式进行划分,具体如下所示:
- Encoder-Decoder Reconstruction:使用自编码器进行数据重构。
- Adversarial Reconstruction:使用生成对抗网络进数据重构。
- Deep Visual Domain Adaptation: A Survey
2. Unsupervised Domain Adaptation by Backpropagation
论文链接:Unsupervised Domain Adaptation by Backpropagation,发表时间:ICML 2015
这篇论文令对抗学习(Adversarial Learning)与领域自适应(Domain Adaptation)相结合,并提出了梯度反转层(Gradient Reversal Layer),使得模型的训练不需要如同 GAN 的训练过程复杂。(这篇文章应该是 Unsupervised Domain Adaptation 中 Adversarial based Domain Adaptation 的发展源头之一,目前常见方法的框架基本与其相同)
其中,梯度反转层非常容易实现,比如:利用 PyTorch 的 Hook 机制或者定义 Module 的 Backward 即可。
![[论文笔记] 领域自适应系列论文笔记_第7张图片](http://img.e-com-net.com/image/info8/bba9bd4494974ed7bf8d9d2f822ac2b3.jpg)
PS : 作者对该文进行修改与整理后,又发表了该文章的期刊版本:Domain-Adversarial Training of Neural Networks,发表于 JMLR。在该版本中,作者将所提出的框架命名为 Domain-Adversarial Neural Networks(DANN)。
3. Adversarial Discriminative Domain Adaptation
论文链接:Adversarial Discriminative Domain Adaptation,发表时间:CVPR 2017
作者对于 Adversarial Domain Adaptation 提出了统一框架,认为常见的 Adversarial Domain Adaptation 的方法都是通过修改该框架中不同变量所得到的,比如:使用生成式模型或是判别式模型,源域特征提取器与目标域特征提取器的参数是否保持一致等等。框架具体详情,如下图所示。
![[论文笔记] 领域自适应系列论文笔记_第8张图片](http://img.e-com-net.com/image/info8/5eb2298aaec6483f9630d5b4f332e7f0.jpg)
此外,作者基于该统一框架,提出了新的方法 Adversarial Discriminative Domain Adaptation(ADDA),用于解决 Unsupervised Domain Adaptation 问题。对比作者所提出的统一框架,该方法的关键点有:使用判别式模型、源域特征提取器与目标域特征提取器的参数无限制共享、使用 GAN Loss。
![[论文笔记] 领域自适应系列论文笔记_第9张图片](http://img.e-com-net.com/image/info8/1f6069780f10411f88234087af0d9dfa.jpg)
ADDA 的训练过程分为两个阶段:
- 利用源域的图像数据与标签数据对 Source CNN 和 Classifier 进行训练。
- 利用已训练好的 Source CNN 的参数对 Target CNN 进行初始化。接着,固定 Source CNN 的参数,利用源域/目标域的图像数据和领域标签数据,对 Target CNN 和 Discriminator 进行对抗式训练。
其中,作者对其框架设计的细节做了解释:
-
为何不直接令 Source CNN 与 Target CNN 相等?
作者认为强制模型学习学习对称变换会使得优化条件不佳,因为同一网络必须处理来自两个单独域的图像。 -
为何不像 DANN 那样直接令 L a d v M = − L a d v D \mathcal{L}_{adv_M}=-\mathcal{L}_{adv_D} LadvM=−LadvD?
作者认为这样的设置会使得模型的优化出现问题,尤其是训练前期判别器极其容易收敛,从而导致梯度消失。
ADDA 的目标函数如下图所示:
![[论文笔记] 领域自适应系列论文笔记_第10张图片](http://img.e-com-net.com/image/info8/0c11829696334b17931f3fa63b6eea01.jpg)
PS:官方开源项目地址 erictzeng/adda,支持 Tensorflow;第三方开源项目地址 corenel/pytorch-adda,支持 PyTorch。
4. Conditional Adversarial Domain Adaptation
论文链接:Conditional Adversarial Domain Adaptation,发表时间:NIPS 2018
作者认为大部分现有方法无法有效的对齐不同域的多峰分布(Multimodel Distribution),于是作者受到 Conditional Generative Adversarial Networks 的启发,提出框架 Conditional Adversarial Domain Adaptation(CDAN),用于解决 Unsupervised Domain Adaptation 问题。
其中,该框架主要有两个新颖的调整策略(Conditioning Strategy):Multi-linear Conditioning,利用模型所提取的特征表达与其所预测的结果概率向量对互协方差(Cross-Covariance)进行提取,从而对模型进行调整;Entropy Conditioning,调整模型所预测结果的不确定性,以此保证其迁移能力。
PS : 该文章的第一作者为清华大学的龙明盛副教授,其研究方向为迁移学习,感兴趣的可以看看其个人主页。
![[论文笔记] 领域自适应系列论文笔记_第11张图片](http://img.e-com-net.com/image/info8/b4c1e46eac354db9b888dcfe4912e997.jpg)
- Multi-linear Conditioning
CDAN 的目标函数的数学表达如下所示:
![[论文笔记] 领域自适应系列论文笔记_第12张图片](http://img.e-com-net.com/image/info8/dc3a37445d644812812082fa66de34b9.jpg)
其中, h h h 由模型的特征表达 f f f 和模型预测结果的概率向量 g g g 映射所得。
在文章中,作者介绍了两种映射方法:Multi-linear Map ⨂ \bigotimes ⨂ 和 Random Multi-linear Map ⨀ \bigodot ⨀。其中,Multi-linear Map 通过矩阵乘法 f f f 和 g g g 进行映射(假设 f f f 的尺寸为 b a t c h ∗ 1 ∗ F batch * 1 * F batch∗1∗F和 g g g 的 尺寸为 b a t c h ∗ G ∗ 1 batch * G * 1 batch∗G∗1,最终所得映射结果的尺寸为 b a t c h ∗ G ∗ F batch * G * F batch∗G∗F);Random Multi-linear Map 通过构建 Random Layer 对 f f f 和 g g g 进行随机映射。
如下图所示,作者给出了如何判断使用何种映射方式的准则:
![[论文笔记] 领域自适应系列论文笔记_第13张图片](http://img.e-com-net.com/image/info8/7c061356ce9b461bbaaedbc7e6ff5b90.jpg)
- Entropy Conditioning
作者将模型预测结果的概率向量进行熵值计算,并将其作为领域判别器损失函数的权重值。作者称利用 Entropy Conditioning 的 CDAN 为 CDAN+E,其目标函数的数学表达如下所示:
![[论文笔记] 领域自适应系列论文笔记_第14张图片](http://img.e-com-net.com/image/info8/4f46fafc51d34c80a6c00cd2eff3a2f0.jpg)
PS : 该论文的官方开源项目地址为 thuml/CDAN,支持 PyTorch/Tensorflow/Caffe 三种深度学习框架。
5. Transferable Attention for Domain Adaptation
论文链接:Transferable Attention for Domain Adaptation ,发表时间:AAAI 2019
作者认为现有的 Adversarial Domain Adaptation 方法有两点不足之处:直接使用全局特征进行对齐,没有考虑“不同局部区域的特征的可迁移的难易程度不同”这一情况;默认使用所有图像进行迁移,没有考虑“并不是所有图像都适合进行迁移”这一情况。
因此,作者在现有的 Adversarial Domain Adaptation 方法的基础上引入注意力机制,提出了新的框架:Transferable Attention for Domain Adaptation(TADA),该框架用于解决 Unsupervised Domain Adaptation 问题。在该框架中,作者分别利用注意机制对更适合迁移的局部区域和更适合迁移的图像进行挑选:Transferable Local Attention 和 Transferable Global Attention。
PS : 该文章的通讯作者为清华大学的龙明盛副教授。
![[论文笔记] 领域自适应系列论文笔记_第15张图片](http://img.e-com-net.com/image/info8/bf82d06b52a4496a97979c3aec71d070.jpg)
- Transferable Local Attention
作者将 ResNet-50 最后一层卷积层所输出的 Feature Map (其尺寸为 7 × 7 × 2048 7 \times 7 \times 2048 7×7×2048)作为 Local Feature,分别将对应区域的特征输入到相应的局部领域判别器 G d k ( i ∈ [ 1 , K ] , 本 文 中 K = 49 ) G_d^k (i \in [1, K],本文中 K = 49) Gdk(i∈[1,K],本文中K=49) 中,得到各个区域属于源域的概率 d ^ i k = G d k ( f i k ) \hat{d}_i^k=G_d^k(f_i^k) d^ik=Gdk(fik)。因此,局部领域判别器的损失函数 Local Transfer Loss 为:
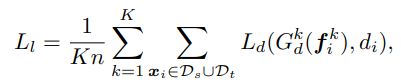
然后,作者根据局部区域的概率值计算其相应熵值,并以此计算其对应的局部区域的注意力系数:

PS : 个人认为这个公式中的负号应该为正号。按照作者思路应该提高更容易迁移的局部区域的注意力,而更容易迁移的局部区域的表现就是其熵值大(即局部判断器的不确定性大),所以应该是熵值越大的区域,其注意力系数应该越大。另一证据为该文中的公式 (6)(该公式描述全局图像的注意力系数)与该公式矛盾。
此外,为避免错误的局部注意力机制对于迁移的负面影响,作者还加入了残差机制,以此得到最终的局部特征:
- Transferable Global Attention
与其他方法类似,全局领域判别器的损失函数 Global Transfer Loss 为:
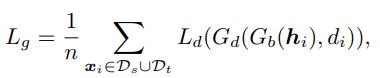
PS : 个人认为该公式中 G d ( G b ( H i ) , d i ) G_d(G_b(H_i),d_i) Gd(Gb(Hi),di) 应该为 G d ( G b ( H i ) ) , d i G_d(G_b(H_i)),d_i Gd(Gb(Hi)),di。
与局部区域的注意力机制相似,全局图像的注意力系数同样由其概率值计算熵值而得:
故,注意力机制的损失函数 Attentison Entropy Loss 为:

其中, p i , j p_{i,j} pi,j 为样本 x i x_i xi 的预测标签类别为 j j j 的概率。
PS : 作者在文中承诺将会在 THUML: Machine Learning Group 上公开源码,但我尚未看到相应的开源项目。我对文中所描述的模型的实现细节比较好奇,比如:文中所使用的局部领域监督器 G d i ( i ∈ [ 1 , K ] ) G_d^i (i \in [1, K]) Gdi(i∈[1,K]) 所占用的资源,是否像 DANN 一样使用 GRL(Gradient Reversal Layer,梯度反转层)等等。
6. GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation
论文链接:GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation ,发表时间:CVPR 2019
作者认为在 Domain Adaptation 常见方法中,有三种重要信息经常被使用:Data Struct(数据结构信息)、Domain Label(领域标签信息)、Class Label(类别标签信息)。
- Data Struct:包括边缘概率分布、条件概率分布、数据统计分布、数据几何结构。
- Domain Label:对样本赋予源域/目标域标签,常用于 Adversarial Domain Adaptation 方法。
- Class Label:除源域的标签信息外,还包括目标域的伪标签信息。
然而,大多数方法仅使用其中的一到两种,作者自然而然思考如何同时使用这三种信息进行迁移。于是,作者提出了框架 Graph Convolutional Adversarial Network(GCAN),用于解决 Unsupervised Domain Adaptation 问题。
![[论文笔记] 领域自适应系列论文笔记_第16张图片](http://img.e-com-net.com/image/info8/b22855385ea2434eb39e839229d897b9.jpg)
根据所使用信息的类别,该框架可以分为三个部分:Structure-aware Alignment、Domain Alignment、Class Centroid Alignment。所使用的总损失函数如下所示:
![[论文笔记] 领域自适应系列论文笔记_第17张图片](http://img.e-com-net.com/image/info8/4369a70fc47145a4925f39e0b6b34469.jpg)
- Domain Alignment
与其他 Adversarial Domain Adaptation 方法类似,Domain Alignment Loss 为:
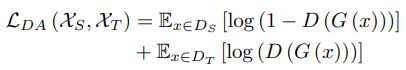
- Structure-aware Alignment
作者利用 CNN 对图像提取 CNN Feature,利用 Data Structure Analyzer(DSA)提取 Structure Score,将 CNN Feature 作为 GCN 的输入,Structure Score 作为 GCN 的邻接矩阵,从而得到 GCN Feature,以此作为最终的图像特征。
PS : 阅读该论文的实验部分,作者实现 DSA 使用的是 AlexNet(修改其最终输出的维度为 1000),与其所使用的 CNN 一样。并没有详细解释何为 DSA,与其所使用的 CNN 有何不同,为何其输出称为 Structure Score。
与 Triplet Loss 相似,作者所使用的 Domain Alignment Loss 为:
![[论文笔记] 领域自适应系列论文笔记_第18张图片](http://img.e-com-net.com/image/info8/c87b6bdab6394a72af9d80750f2eba8d.jpg)
- Class Centroid Alignment
作者指出,特征具有领域不变性(Domain Invariance)与结构一致性(Structure Consistency)并不意味着其具有判别性(Discriminability)。于是,作者利用构建源域/目标域特征的聚类中心保证所学特征的判别能力。
由于目标域无标签信息,故作者使用分类器的预测结果作为目标域的伪标签(Pseudo Label)。因此,Class Alignment Loss 为:
![[论文笔记] 领域自适应系列论文笔记_第19张图片](http://img.e-com-net.com/image/info8/8f24ec67b24544768f9c4c79043bb834.jpg)
作者指出通过构建源域/目标域特征的聚类中心来提高所学特征的判别能力(或者说丰富所学特征所含的语义信息)的想法来自于:Learning Semantic Representations for Unsupervised Domain Adaptation (该文章发表于 ICML 2018,通讯作者为中山大学的郑子彬教授,官方开源项目地址为:Mid-Push/Moving-Semantic-Transfer-Network)。(个人感觉与 CVPR 2018 的 Unsupervised Domain Adaptation with Similarity Learning 思路相似,都是通过构建特征的聚类中心提高模型的判别能力,只不过形式略有差别)
关于文章中所使用的超参数,作者指出: α T \alpha_T αT=1, η \eta η=0.001, θ \theta θ=0.7, λ = γ = 2 1 + e x p ( − k ⋅ p ) \lambda=\gamma=\frac{2}{1+exp(-k \cdot p)} λ=γ=1+exp(−k⋅p)2(其中, k k k 等于10, p p p 由 0 变换到1)。
PS : 尚未找到相关开源代码。
7. Transfer Learning with Dynamic Adversarial Adaptation Network
论文链接:Transfer Learning with Dynamic Adversarial Adaptation Network,发表时间:ICDM 2020
在 Domain Adaptation 中,所有方法的目的都是为了对齐源域与目标域的边缘概率分布或者条件概率分布,亦或两者都有。但是,很少有方法动态的、定量的分析两者对于迁移的相对重要性。因此,作者从该想法出发,提出框架 Dynamic Adversarial Adaptation Network (DAAN),用于解决 Unsupervised Domain Adaptation 问题。
![[论文笔记] 领域自适应系列论文笔记_第20张图片](http://img.e-com-net.com/image/info8/3b68084535144b4985f846d1fe44f2f3.jpg)
- Global Domain Discriminator
Global Domain Discriminator 的损失函数如下所示:
![[论文笔记] 领域自适应系列论文笔记_第21张图片](http://img.e-com-net.com/image/info8/6ce361e2f49a4820a59e8c1e8d9e7de7.jpg)
- Local Subdomain Discriminator
Local Subdomain Discriminator 的损失函数如下所示:
![[论文笔记] 领域自适应系列论文笔记_第22张图片](http://img.e-com-net.com/image/info8/d015a3d73d0e4aa3b86c2ed373a23712.jpg)
- Dynamic Adversarial Factor w \mathcal{w} w
作者通过 Global Domain Discriminator 和 Local Subdomain Discriminator 的损失函数定义其距离:
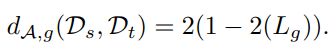
PS : 关于公式中的系数 2,个人尚未理解其含义,感觉 1 − L g 1-L_g 1−Lg 和 1 − L l c 1-L_l^c 1−Llc 就可以了。
并通过 Global Domain Discriminator 和 Local Subdomain Discriminator 的距离计算 w \mathcal{w} w:

根据后续的讲解, w \mathcal{w} w 为的 L l L_l Ll 权重值:
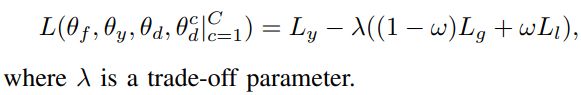
换句话说, w \mathcal{w} w 越大,则条件概率分布越重要,反之,则边缘概率分布重要。
此外,注意到模型对目标域样本的损失函数的计算,需要利用伪标签信息。
PS : 尚未找到相关开源代码。
8. 推荐入门资料
- zhaoxin94/awesome-domain-adaptation Github 上的论文整理项目,内容丰富,条理清晰,能了解 DA 近几年的发展过程。
- 知乎 | 种豆南山下 知乎上的一位用户,其专栏 迁移学习 整理的较为详细,值得阅读。其中,推荐阅读以下文章:
- Deep Domain Adaptation论文集(一):基于label迁移知识
- Deep Domain Adaptation论文集(二):基于统计差异
- Deep Domain Adaptation论文集(三):基于深度网络结构差异&几何差异
- Deep Domain Adaptation论文集(四):基于生成对抗网络GAN
- Deep Domain Adaptation论文集(五):基于数据重构的迁移方法
- Deep Domain Adaptation论文集(六):源域与目标域特征空间不一致的处理方法
- 知乎 | 王晋东不在家 知乎上的一位用户,其专栏 机器有颗玻璃心 中的 《小王爱迁移》系列的文章整理的非常详细(比如:《小王爱迁移》系列之一:迁移成分分析(TCA)方法简介),值得阅读。该用户不仅整理了迁移学习的相关资料:jindongwang/transferlearning,还编写了 《迁移学习简明手册》,适合入门者阅读,以便简单了解背景知识以及常见方法。
参考资料:
- 什么是迁移学习 (Transfer Learning)?这个领域历史发展前景如何? - 知乎
如果你看到了这篇文章的最后,并且觉得有帮助的话,麻烦你花几秒钟时间点个赞,或者受累在评论中指出我的错误。谢谢!
作者信息:
知乎:没头脑
CSDN:Code_Mart
Github:Tao Pu