python编程知识点简单总结
python编程知识点简单总结
- 一、python语言基础即特点
- 1、基本输入和输出
- 2、注释规则
- 注释类型
- (1)单行注释
- (2)多行注释
- 3、代码缩进
- 4、编码规范
- 5、保留字与标识符
- 保留字:python语言中已经被赋予特定意义的一些单词,开发程序时,不可作为变量、函数、类、模块、其他对象名称来使用。
- 标识符:由字母、下划线和数字组成。
- 6、变量
- 定义变量:
- 1、语法
- 2、标识符命名规则
- 3、命名习惯
- 二、Python程序控制结构
- 1、基本数据类型
- 1、数字类型
- 2、布尔类型
- 在数值上下文环境中,True被当作1,False被当作0
- 其他类型值转bool值时除了 [ ] 、( ) 、{ }、0 、0.0、 0.0+0.0j、’’、””、’’’’’’、””””””、None、False为False外,其他都为True,
- 3、字符串
- 转义字符
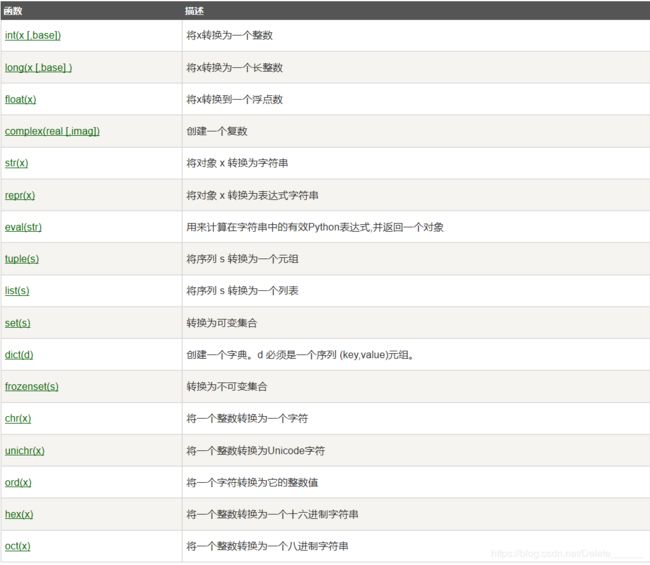
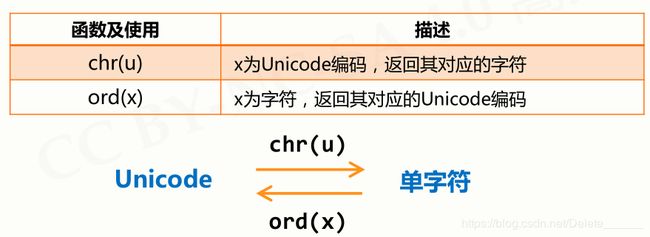
- 4、python数据类型的转换
- 二、Python程序控制结构
- 1、运算符
- 1、算术运算符
- 2、比较运算符
- 3、赋值运算符
- 4、逻辑运算符
- 数字之间进行逻辑运算:
- 5、位运算符
- 6、运算符优先级
- 2、条件结构
- 3.0
- 5.0
- 1.5
- 3、随机数
- 1、导入random模块
- 2、使用random模块中随机数功能
- 注意:包含开始位置和结束位置
- 4、循环结构
- 1、while循环
- 2、循环终止
- 3、for循环
- 2
- 4、循环结合else使用
- 三、Python组合数据类型
- 1、列表与元组
- 序列
- 序列通用操作符
- 序列处理函数和方法
- 列表
- 元组
- 序列类型应用场景
- 2、字典
- 1、定义
- 2、字典处理函数及方法
- 3、集合
- 1、定义
- 2、集合操作符
- 增强操作符
- 集合处理方法
- 4、字符串
- 表示方法
- 使用
- 转义字符
- 字符串运算符
- 字符串操作符
- 字符串处理函数
- 字符串处理方法
- 类型格式化
- 格式化符号
- 格式化操作符辅助指令
- 四、python函数
- 1、理解与定义
- 定义函数的规则
- 函数调用
- 2、参数传递与返回值
- 参数传递
- 调用函数时可使用的正式参数类型
- return语句
- 返回值
- 3、变量作用域
- 局部变量和全局变量
- 规则
- lambda函数
- 语法
- 4、递归
- 函数递归的调用过程
- 递归的2个关键特征
- 二分查找
- 五、python模块
- 1、定义
- 模块分为三种:
- 2、使用
- import语句
- 工作机制
- 注意:
- 3、探索
- 4、标准库
- 5、第三方库
- 六、文件及目录操作
- 1、打开文件
- File对象的属性
- 2、关闭文件
- 3、写入文件
- 4、读文件
- 5、文件定位
- 6、重命名和删除文件
- 7、python里的目录
- 七、异常处理
- 八、内置函数
一、python语言基础即特点
1、基本输入和输出
variable = input(“提示文字”)
print(输出内容)
2、注释规则
注释概念:在程序代码中添加的标注性的文字。
注释类型
(1)单行注释
只能注释一行
格式:#注释内容
快捷键:Ctrl + /
(2)多行注释
可以注释多行内容,一般用在注释一段代码的情况下
格式:1、6个引号

2、六个单引号

3、代码缩进
每一行代码左端空出一定长度的空白,从而可以更加清晰地从外观上看出程序的逻辑结构。
4、编码规范
(1)每个import语句只导入一个模板,尽量避免一次导入多个模块。
(2)不要在行尾添加分号“;”,也不要用分号将两条命令放在同一行。
(3)建议每行不超过80个字符。
(4)使用必要的空行可以增加代码的可读性。
(5)运算符两侧,函数参数之间,逗号“,”两侧建议使用空格 进行分隔。
(6)避免在循环中使用+和+=运算符累加字符串。
(7)适当使用异常处理结构提高程序容错性。
5、保留字与标识符
保留字:python语言中已经被赋予特定意义的一些单词,开发程序时,不可作为变量、函数、类、模块、其他对象名称来使用。
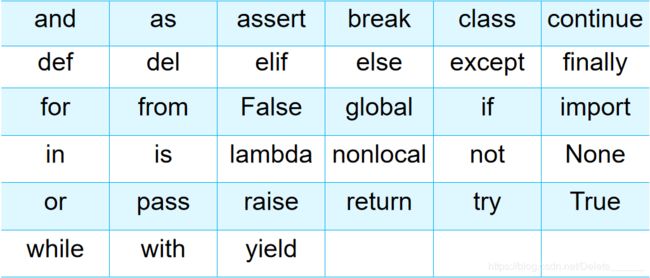
标识符:由字母、下划线和数字组成。
ps:类名单词首字母大写,模块名单词小写,中间用下划线表示空格。
6、变量
定义变量:
1、语法
(1)变量名 = 变量值
(2)变量名要符合标识符命名规则
2、标识符命名规则
(1)由数字、字母、下划线组成。
(2)不能以数字开头。
(3)不能使用内置关键字。
(4)严格区分大小写。
3、命名习惯
(1)见名知义
(2)驼峰命名法
大驼峰:即每个单词的首字母都大写
小驼峰:第二个(含)以后的单词首字母大写
(3)下划线
二、Python程序控制结构
1、基本数据类型
1、数字类型
(1)整数(int)——正或负整数,不带小数点。
(2)浮点数(float)——由整数部分和小数部分组成,可以用科学计数法表示(2.5•102=250)
(3)复数(complex)——由实部和虚部构成,可以用a + b j或者complex(a , b)表示,复数的实部和虚部都是浮点数。

2、布尔类型
概念:对于布尔值,只有两种结果即True和False,其分别对应与二进制中的1和0。而对于真即True的值太多了,我们只需要了解假即Flase的值有哪些—None、空(即 [ ] 、( ) 、”” 、{ }、0 、 0.0 、 0.0+0.0j 、’’ 、False)
在数值上下文环境中,True被当作1,False被当作0
例如:
>>>True + 6
7
>>>False + 6
6其他类型值转bool值时除了 [ ] 、( ) 、{ }、0 、0.0、 0.0+0.0j、’’、””、’’’’’’、””””””、None、False为False外,其他都为True,
例如:
>>>bool(6)
True
>>>bool([])
False3、字符串
概念:字符串是连续的字符序列,可以是计算机所能表示的一切字符的集合。

>>>s = 'RUNOOB
>>>S[1:5]
'UNOO'例如:
str = 'Happy everyday!'
print str #输出完整的字符串
print str[0] #输出字符串第一个字符
print str[2:7] #输出字符串第三个至第六个之间的字符串
print str[5:] #输出从第六个字符开始的字符串
print str * 3 #输出字符串三次
print str + "OK!" #输出连接的字符串输出结果如下:

转义字符
转义字符是指使用“\”对一些特殊字符进行转义。
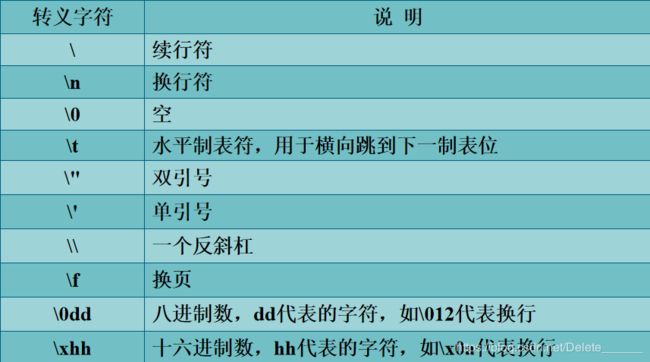
4、python数据类型的转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
二、Python程序控制结构
1、运算符
1、算术运算符
实例:
a = 6
b = 15
print(a + b)
print(a - b)
print(a * b)
print(a / b)
print(a % b)
print(a ** b)
print(a // b)输出结果如下:

2、比较运算符
比较两个对象或者返回是否
实例:
a = 6
b = 15
print(a == b)
print(a != b)
print(a <> b)
print(a > b)
print(a < b)
print(a >= b)
print(a <= b)输出结果如下:

3、赋值运算符
a = 6
b = 15
d = 98
e = 10
f = 4
g = 20
h = 0
i = 10
j = 7
c = a + b
d += a #等效于d = d + a
e -= a #等效于e = e - a
f *= a #等效于f = f * a
g /= a #等效于g = g / a
h %= a #等效于h = h % a
i **= a #等效于i = i ** a
j //= a #等效于j = j // a
print(c)
print(d)
print(e)
print(f)
print(g)
print(h)
print(i)
print(j)输出结果如下:

4、逻辑运算符
数字之间进行逻辑运算:
(1)and运算符
只要有一个值为0,则结果为0,否则结果为最后一个非0的数字
(2)or运算符
只有所有的值为0结果才为0,否则结果为第一个非0数字
(3)特殊情况
如果值为 True 则返回 False:如果值为 False 则返回 True。
5、位运算符
6、运算符优先级
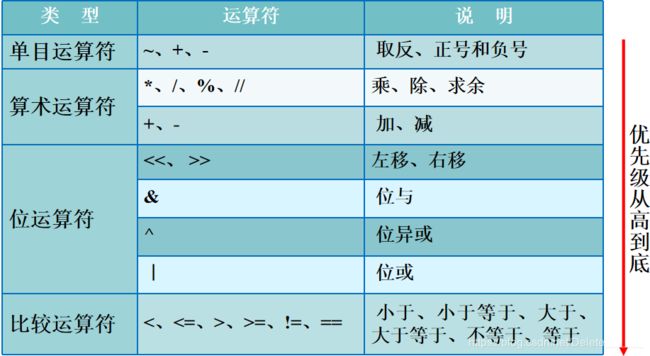
2、条件结构
(1)if 语句
a = 6
if a <= 8:
b = a / 2
print(b)输出结果为
3.0
(2)if-else语句
a = 15
if a <= 8:
a = a / 2
else:
a = a / 3
print(a)输出结果为
5.0
(3)if-elif-else语句
a = 6
if a >= 15:
a = a / 2
elif a >= 10:
a = a / 3
else:
a = a / 4
print(a)输出结果为
1.5
(4)if 嵌套
print("咣咣咣")
gender = input("请输入你的性别:")
if gender == "男": # = 赋值 ==判断
print("去隔壁.alex等着你")
else: # 不是男
ask = input("请问是不是包租婆?")
if ask == '是':
print("去隔壁,alex等着你,wusir也在!")
else:# 不是包租婆
height = int(input("请问你多高了"))
if height > 200:
print("太可怕了.去隔壁.去隔壁")
else:
print("请进.我家的西瓜.又大又甜!")其中一种输出结果如下:

3、随机数
1、导入random模块
import random
2、使用random模块中随机数功能
random.randint(开始,结束)
注意:包含开始位置和结束位置
4、循环结构
1、while循环

2、循环终止
break : 终止循环
continue: 退出当前一次循环,继续执行下次循环
3、for循环
def deduplication(self, nums):#找出排序数组的索引
for i in range(len(nums)):
if nums[i]==self:
return i
i=0
for x in nums:
if self>x:
i+=1
return i
print(deduplication(5, [1,3,5,6]))输出结果为
2
4、循环结合else使用
(1)while……else

(2)for……else
for num in range(10,20): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
print '%d 等于 %d * %d' % (num,i,j)
break # 跳出当前循环
else: # 循环的 else 部分
print num, '是一个质数'
三、Python组合数据类型
1、列表与元组
序列
概念:Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1。
序列通用操作符

序列处理函数和方法

列表
(1)一种序列类型,创建后可以随意被修改。
(2)使用方括号 [] 或list() 创建,元素间用逗号 , 分隔。
(3)列表中各元素类型可以不同,无长度限制。
(4)创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
>>>ls = [chenxiaoyan,yuweitong,dengyifan,chensihui]
>>>ls[3] = piaoliang
[chenxiaoyan,yuweitong,dengyifan,piaoliang]
>>>ls[1:2] = [keai,shanliang]
[chenxiaoyan,keai,shanliang,piaoliang]
>>>del ls[0]
[keai,shanliang,piaoliang]
>>>del ls[0:1]
[piaoliang]
>>>ls += [chenxiaoyan,yuweitong,dengyifan,chensihui]
[piaoliang,chenxiaoyan,yuweitong,dengyifan,chensihui]
>>>ls *2
[piaoliang,chenxiaoyan,yuweitong,dengyifan,chensihui,piaoliang,chenxiaoyan,yuweitong,dengyifan,chensihui]或者
>>>ls = ['chenxiaoyan','yuweitong','dengyifan','chensihui']
>>>ls.append('piaoliang')
['chenxiaoyan','yuweitong','dengyifan','chensihui','piaoliang']
>>>ls.clear()
>>>ls.copy()
[]
>>>ls = ['chenxiaoyan','yuweitong','dengyifan','chensihui']
>>>ls.insert(3,'keai')
['chenxiaoyan','yuweitong','dengyifan','keai']
>>>ls.pop(1)
['chenxiaoyan','dengyifan','keai']
>>>ls.remove('keai')
['chenxiaoyan','dengyifan']
>>>ls.reverse()
['dengyifan','chenxiaoyan']元组
(1)元组是一种序列类型,一旦创建就不能被修改
(2)使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
(3)可以使用或不使用小括号
(4)元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用。[ps:不加逗号,类型为整数:加了逗号,类型为元组。]
(5)元组中的元素值是不允许修改的,但我们可以对元组进行连接组合。
(6)元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组。
实例:
tup1 = () #创建空元组
>>> tup1 = (50)
type(tup1)
<class 'int'>
>>> tup1 = (50,)
type(tup1)
<class 'tuple'>tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
tup3 = tup1 + tup2
print ("tup1[0]: ", tup1[0])
print ("tup2[1:5]: ", tup2[1:5])
print (tup3)
del tup3
print ("删除后的元组 tup : ")
print (tup3)以上实例元组被删除后,输出变量会有异常信息
序列类型应用场景
(1)元组用于元素不改变的应用场景,更多用于固定搭配场景
如数据保护,将列表类型转换成元组类型 lt = tuple(ls)
(2)列表更加灵活,它是最常用的序列类型
(3)最主要作用:表示一组有序数据,进而操作它们
如元素遍历,for item in ls(lt): <语句块>
2、字典
1、定义
(1)通过任意键信息查找一组数据中值信息的过程叫映射(映射是一种键(索引)和值(数据)的对应
)
(2) 字典是键值对的集合,键值对之间无序(键值对:键是数据索引的扩展)
(3)键必须是唯一的,但值则不必。
(4)值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
(5)采用大括号{}和dict()创建,键值对用冒号: 表示{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
(6)在字典变量中,通过键获得值
<字典变量> = {<键1>:<值1>, … , <键n>:<值n>}
<值> = <字典变量>[<键>] <字典变量>[<键>] = <值>
[ ] 用来向字典变量中索引或增加元素
(7)映射无处不在,键值对无处不在。
(8)最主要作用:表达键值对数据,进而操作它们。
2、字典处理函数及方法
>>>k = {"chenxiaoyan":"1","yuweitong":"2","dengyifan":"3","chensihui":"4"}
>>>del k[chenxiaoyan]
{"chenxiaoyan","yuweitong":"2","dengyifan":"3","chensihui":"4"}
>>>'dengyifan' in k
True
>>>k.keys()
dict_keys(['chenxiaoyan','yuweitong','dengyifan','chensihui'])
>>>k.values()
dict_values(['2','3','4'])
>>>k.items()
{"chenxiaoyan","yuweitong":"2","dengyifan":"3","chensihui":"4"}
>>>k.get("dengyifan","liuyuan")
'3'
>>>k.get("yehuihui","liuyuan")
'liuyuan'
>>>k.popitem()
('chensihui','4')
>>>k.clear()
>>>len(k)
03、集合
1、定义
(1)集合是多个元素的无序组合。
(2)集合元素之间无序,每个元素唯一,不存在相同元素。
(3)集合元素不可更改,不能是可变数据类型。
(4)集合用大括号 {} 表示,元素间用逗号分隔。
(5)建立集合类型用 {} 或 set()。
(6)建立空集合类型,必须使用set()。
(7)数据去重:集合类型所有元素无重复。
2、集合操作符

增强操作符

集合处理方法
>>>k = {"chenxiaoyan","yuweitong","dengyifan","chensihui"}
>>>k
{'dengyifan', 'chenxiaoyan', 'yuweitong', 'chensihui'}
>>>k.add('piaoliang')
>>>k
{'dengyifan', 'chenxiaoyan', 'yuweitong', 'chensihui','piaoliang'}
>>>k.discard('piaoliang')#如果不在集合内,不报错
>>>k
{'chenxiaoyan','yuweitong','dengyifan','chensihui'}
>>>k.remove('yuweitong')#如果不在集合内,产生KeyError异常
{'chenxiaoyan','dengyifan','chensihui'}
>>>k.clear()
>>>k
set()
>>>k.pop()
Traceback (most recent call last):
File "" , line 1, in <module>
k.pop()
KeyError: 'pop from an empty set' #k为空,所以出现了异常
>>>k = {"chenxiaoyan","yuweitong","dengyifan","chensihui"}
>>>k.pop()
{'chensihui'}
>>>k = {"chenxiaoyan","yuweitong","dengyifan","chensihui"}
>>>k.copy()
{'dengyifan', 'chenxiaoyan', 'yuweitong', 'chensihui'}
>>>len(k)
4
>>>'dengyifan' in k
True
>>>'liuyuan' in k
False
>>>'dengyifan' not in k
False
>>>'liuyuan' not in k
True
>>>k = {"chenxiaoyan","yuweitong",'dengyifan',"chensihui"}
>>>set(k)
{'dengyifan', 'chenxiaoyan', 'yuweitong', 'chensihui'}4、字符串
表示方法
(1)由一对单引号或双引号表示,仅表示单行字符串。
例如:“请输入带有符号的温度值: “或者 ‘C‘
(2)由一对三单引号或三双引号表示,可表示多行字符串。
例如:
‘’’ Python
语言 ‘’’
(3)在字符串中包含双引号或单引号。
例如:'这里有个双引号(”)’ 或者 “这里有个单引号(’)”
(4)在字符串中既包括单引号又包括双引号。
例如:’’’ 这里既有单引号(’)又有双引号 (”) ‘’’
使用
(1)使用[ ]获取字符串中一个或多个字符
(2)索引:返回字符串中单个字符 <字符串>[M]
(3)切片:返回字符串中一段字符子串 <字符串>[M: N]
(4)<字符串>[M: N: K],根据步长K对字符串切片
转义字符
转义符表达特定字符的本意: " 这里有个双引号(")" 结果为 这里有个双引号(")
转义符形成一些组合,表达一些不可打印的含义: "\b"回退 "\n"换行(光标移动到下行首) “\r” 回车(光标移动到本行首)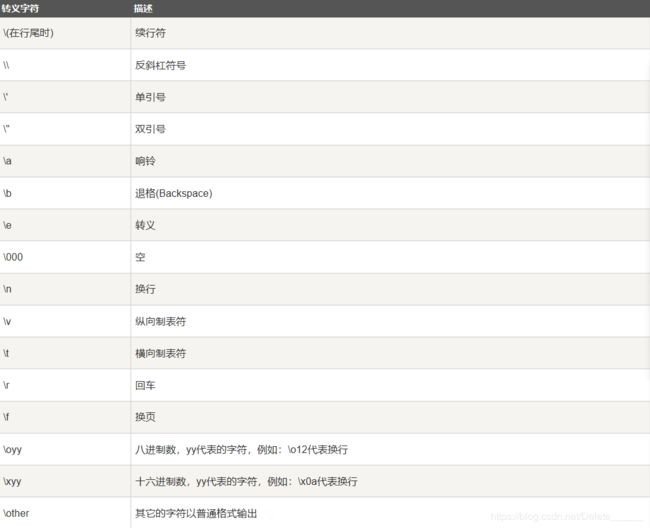
字符串运算符

字符串操作符
可以通过 for 和 in 组成的循环来遍历字符串中每个字符
for csh in "BJLGDXZHXY":
print(csh)输出结果为
BJLGDXZHXY
字符串处理函数

字符串处理方法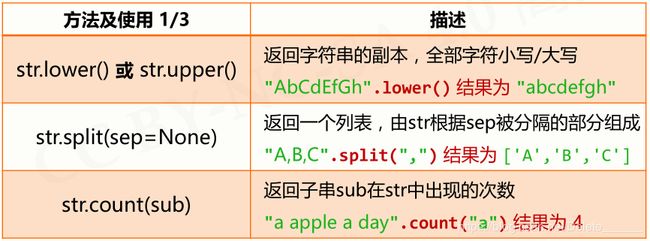


类型格式化
概念:格式化是对字符串进行格式表达的方式
字符串format()方法的基本使用格式是:(<模板字符串>.format(<逗号分隔的参数>)
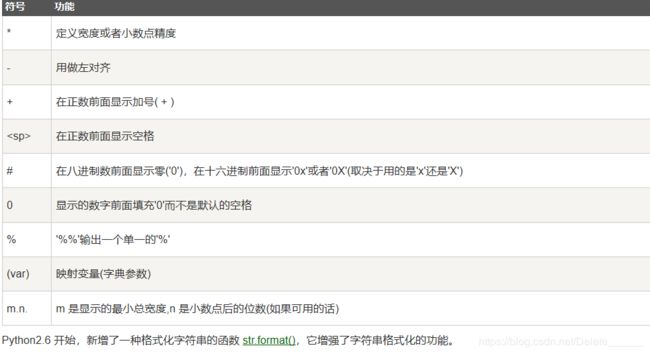
格式化符号
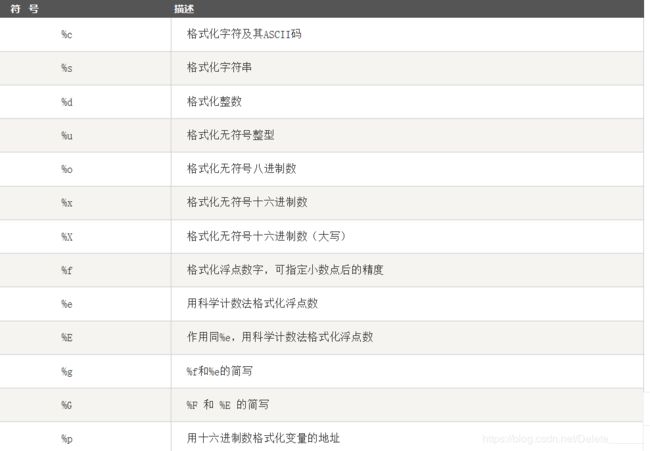
格式化操作符辅助指令
四、python函数
1、理解与定义
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
定义函数的规则
(1)函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
(2)任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
(3)函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
(4)函数内容以冒号起始,并且缩进。
(5)return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
ps:默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
函数调用
(1)函数里包含的参数,和代码块结构
(2)这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行
#定义函数
def p(a):
print(a.upper())
print(a[:-1},'+'.join(a))
print(a.replace('p','==')
#调用函数
a = input('请输入字符串')
Csh.p(a)2、参数传递与返回值
参数传递
调用函数时可使用的正式参数类型
(1)必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。[调用printme()函数,你必须传入一个参数,不然会出现语法错误]
(2)关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值
(3)默认参数
调用函数时,默认参数的值如果没有传入,则被认为是默认值。
(4)不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名
return语句
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。
s = {"chenxiaoyan":"1","yuweitong":"2","dengyifan":"3","chensihui":"4"}
def p(x):
global s
k = s.get(x,"您输入的键不存在")
return k
#调用函数
f = input("请您输入")
g = Csh.p(f)
print(g)返回值
概念:函数可以返回0个或多个结果
(1)return保留字用来传递返回值
(2)函数可以有返回值,也可以没有
(3)可以有return,也可以没有
(4)return可以传递0个返回值,也可以传递任意多个返回值
3、变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
局部变量和全局变量
全局变量指在函数之外定义的变量,一般没有缩进,在程序执行全过程有效。
局部变量指在函数内部使用的变量,仅在函数内部有效,当函数退出时变量将不存在。
规则
(1)局部变量和全局变量是不同变量。当函数执行完退出后,其内部变量将被释放。 函数func()内部使用了变量n,并且将变量参数b赋值给变量n。
(2)局部变量为组合数据类型且未创建新变量,等同于全局变量。
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print "函数内是局部变量 : ", total
return total
#调用sum函数
sum( 10, 20 )
print "函数外是全局变量 : ", total输出结果为
函数内是局部变量 : 30
函数外是全局变量 : 0
lambda函数
(1)lambda只是一个表达式,函数体比def简单很多。
(2)lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
(3)lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
(4)虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
ladbda[arg1[,arg2,......argn]]:expression
>>> f = lambda x, y : x + y
>>> f(10, 15)
25
>>> f = lambda : "lambda函数"
>>> print(f())
lambda函数4、递归
概念:函数作为一种代码封装,可以被其他程序调用,当然,也可以被函数内部代码调用。这种函数定义中调用函数自身的方式称为递归。
函数递归的调用过程

递归的2个关键特征
(1)基线条件:存在一个或多个基例,基例不需要再次递归,它是确定的表达式
(2)递归条件:包含一个或多个调用,所有递归链要以一个或多个基例结尾。
二分查找
(1)如果序列索引最大值与最小值相等,判断是否为要查找的数值。
(2)如果上下限不同,判断数值在上下限平均值的哪一侧,再做查找。
五、python模块
1、定义
模块是一个包含所有你定义的函数和变量的文件
其后缀名是.py
模块可以被别的程序引入,以使用该模块中的函数等功能
模块分为三种:
(1)内置模块:如sys, os, subprocess, time, json 等等
(2)自定义模块:自定义模块时要注意命名,不能和Python自带模块名称冲突。
(3)开源模块:公开的第三方模块, 如 https://pypi.org,可以使用pip install 安装,类似于yum 安装软件
2、使用
import语句
(1)import 语句, 用于导入整个模块
import module1, module2… # 建议一个import语句只导入一个模块
import module as module_alias # 别名(也就是自定义的模块名称空间)
(2)from-import 语句 , 常用于只导入指定模块的部分属性或模糊导入
from module import name1,name2…
工作机制
(1)找到模块文件:在模块搜索路径下搜索模块文件
程序的主目录
PYTHONPATH目录
标准链接库目录
(2)编译成字节码:文件导入时会编译,因此,顶层文件的.pyc字节码文件在内部使用后会被丢弃,只有被导入的文件才会留下.pyc文件
(3)执行模块的代码来创建其所定义的对象:模块文件中的所有语句从头至尾依次执行,而此步骤中任何对变量名的赋值运算,都会产生所得到的模块文件的属性
注意:
(1)模块只在第一次导入时才会执行如上步骤,后续的导入操作只不过是提取内存中已加载的模块对象,reload()可用于重新加载模块
(2)(–name–)每个模块都有一个__name__属性,当其值是’main’时,表明该模块自身在运行,否则是被引入
3、探索
dir()
列出对象的所有属性
对于模块,列出所有的函数、类及变量等
help
获取模块信息,包括函数参数,
不同方法之间的区别等
4、标准库
sys:访问与python解释器紧密相关的变量和函数

os:可访问多个操作系统服务

fileinput:文件处理
sets、heapq和deque:集合,堆,双端栈
time、datetime:时间处理
random:随机数
shelve:用于创建永久性映射
re:正则表达式
csv:处理csv文件
enum:枚举类型
logging:日志处理
5、第三方库
三种安装方法:
方法1(主要方法): 使用pip命令
方法2: 集成安装方法
方法3: 文件安装方法
六、文件及目录操作
1、打开文件
使用文件之前,须首先打开文件,然后进行读、写、添加等操作。Python打开文件使用open函数,其语法格式为:open(name[,mode[,buffering]])
其中,文件名(name)为必选参数,模式(mode)和缓冲(buffering)参数是可选的。该函数返回一个文件对象。
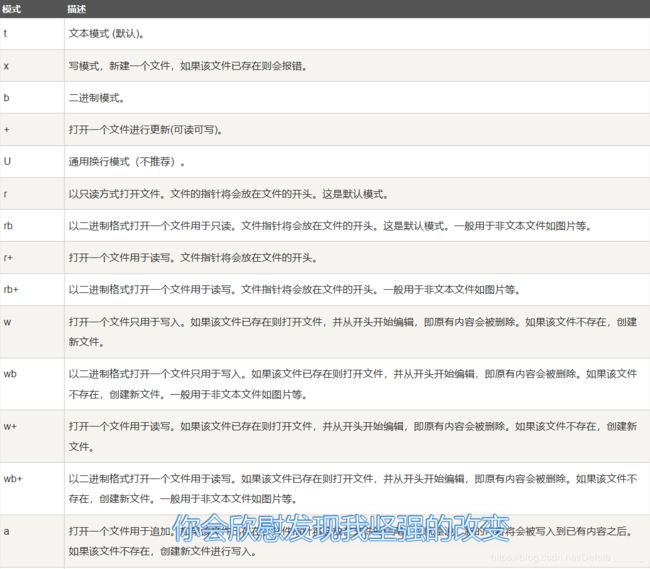
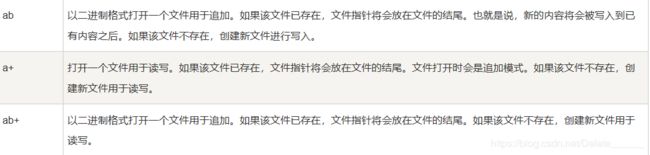
下图很好的总结了这几种模式:

File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表: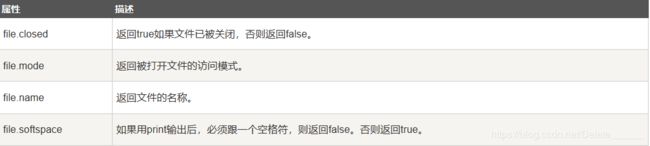
2、关闭文件
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:fileObject.close()
3、写入文件
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符(’\n’
语法:fileObject.write(string)
4、读文件
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
5、文件定位
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。

6、重命名和删除文件
rename()方法:
需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)
remove()方法:
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数
语法:os.remove(file_name)
7、python里的目录
mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir(“newdir”)

chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
os.chdir(“newdir”)
getcwd()方法
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:os.rmdir(‘dirname’)
七、异常处理
异常是一个事件,此事件会在程序执行过程中发生,影响程序的正常执行。一般情况下,Python在无法正常处理程序时就会产生异常。
Python用异常对象(exceptionobject)表示异常情况。当发生异常时,我们需要捕捉它,否则程序会用回溯(traceback)停止运行。
在Python中标准异常情况如下表所示。
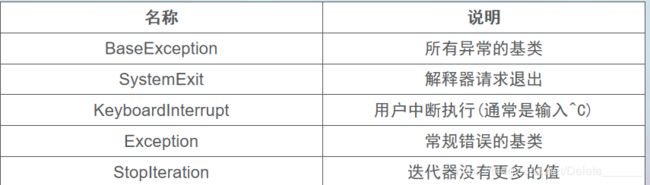
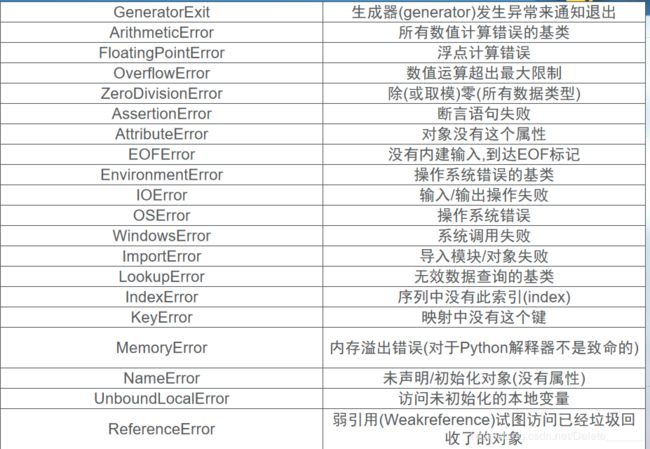

捕捉异常可以使用try、except、else、finally语句。
try/except语句用来检测try语句块中的错误,从而使except语句捕捉异常信息并处理,若使程序不在异常发生时就停止运行,只需在try中捕捉它。
实例:
try:
print(8/'0')
except(ZeroDivisionError,Exception):
print('发生了一个异常')
else:
print(‘正常运行’)
finally:
print(‘cleaning up’)输出结果为

八、内置函数
