一、G1简介
G1全称Garbage-First,在JDK 7u4版本中正式面世,在JDK9中被提议设置为默认的垃圾收集器。G1垃圾收集算法主要应用在多CPU大内存的服务中,在满足高吞吐量的同时,竟可能的满足垃圾回收时的暂停时间,该设计主要针对如下应用场景:
- 垃圾收集线程和应用线程并发执行,和CMS一样
- 整理内存空间更快
- 需要gc停顿时间更好的预测
- 不希望gc时牺牲大量的吞吐性能
- 不需要更大的java堆空间
二、G1内存结构
传统CMS内存模型如下图,分为新生代、老年代、永久代,它们的存储逻辑地址是连续的。 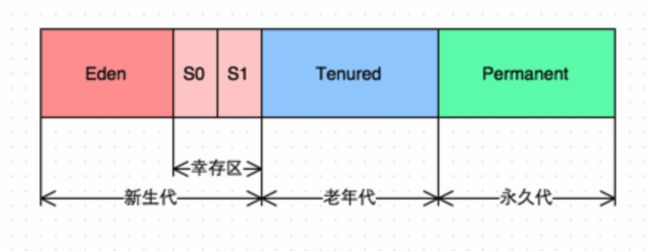
G1中的内存的基本单位是Region,逻辑上也分为新生代、老年代,每一代是有多个不连续的Region构成,其中Region的默认数量是2048,默认大小是堆内存大小/Region数量,Region的大小可以手动指定, 通过-XX:G1HeapRegionSize设定,取值范围从1M到32M,且是2的指数。其中permanent区改为了metaspace
图中H标识Humongous,这些区域用户存放大对象,在G1中如果申请一个对象所需要的堆空间超过Region大小的一半,就会把这个对象标记为大对象,并在老年代中找一个连续的Region来存放该对象,这样做的好处是:为了防止大对象存活时间过长,每次gc都需要来回copy,耗费的时间、空间较多。另外在JDK8u40版本前大对象只能通过Full gc才能清理,在JDK8u40版本后可以在global concurrent marking阶段的cleanup阶段回收。 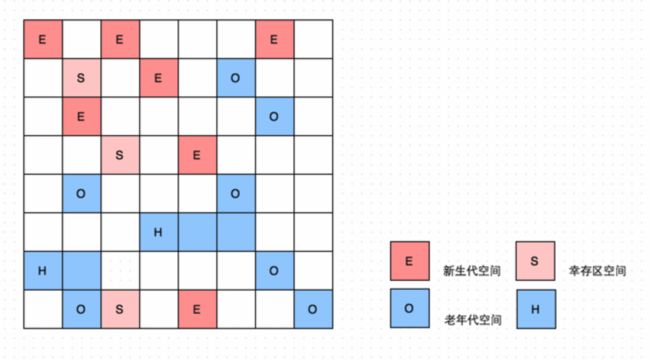
三、gc模式
G1中gc模式总共有Young GC和Mixed GC,其中Young GC和CMS中年轻代GC相似,都是采用的Copying gc算法,每次Young GC都是将年轻代中所有的Region中存活的对象,以及Surivors from区中存活的对象copy到 to-space区中。
Mixed GC的范围包括:所有的年轻代Region、部分老年代。G1中的一大特性是可以设定GC的停顿时间,可以通过参数-XX:MaxGCPauseMillis来设定,默认是200ms,这一参数主要是控制Mixed GC的停顿时间,不是硬性条件,只是一个期望值,GC过程中会尽量往这个值上靠拢,并根据这个值动态调整年轻代和老年代大小比例。G1中的时间停顿模型主要是以衰减标准偏差为理论基础实现的,根据历史数据来预算出本次收集所需要的Region数量。
Mixed GC过程和CMS过程很相似
- 初始标记(initial mark,STW),它标记了从GC Root可达的对象。
- 并发标记(Concurrent Marking)。这个阶段从GC Root开始对heap中的对象标记,标记线程与应用程序线程并行执行,并且收集各个Region的存活对象信息。
- 最终标记(Remark,STW)。标记那些在并发标记阶段发生变化的对象,将被回收。
- 清除垃圾(Cleanup)。清除空Region(没有存活对象的)
四、三色标记
在并发标记阶段,使用的是三色标记法来进行标记。
- 黑色:根对象,或者该对象与它的子对象都被扫描过(对象被标记了,且它的所有field也被标记完了)。
- 灰色:对象本身被扫描,但还没扫描完该对象中的子对象(它的field还没有被标记或标记完)。
- 白色:未被扫描对象,扫描完成所有对象之后,最终为白色的为不可达对象,既垃圾对象(对象没有被标记到)。
CMS和G1都是采用的三色标记,但是在并发标记阶段由于用户线程也在运行,那么对象的引用关系就会改变,如下图 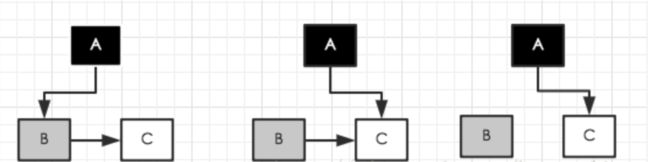
假设他们的引用关系是:A -> B -> C, A 是 GC Roots 关联的对象,那么首先会把 GC Roots 标记,也就是 A 标记成灰色,然后搜索 A 的引用,也就是 B,那么搜索了 B,把 B 变成了灰色,那么 A 就搜索完成了,那么 A 就变成了黑色了。然后就开始搜索B,此时,用户线程同时执行了,用户线程把原来 A -> B -> C 的引用改成了 A -> C,同时 B 不再引用C。然后又到 GC 线程执行了,GC 线程发现 B 没有引用的对象了(因为用户线程已经把 B -> C 去掉了),那么 B 就相当于搜索完成了,变成黑色了。最后,C 怎么办,C还是白色的呢,白色的是不会搜索,会当做垃圾处理的,但是C本身是存活的对象,这样就会出现问题。
解决方案有两种:
-
在并发标记阶段,记录黑色节点新增的引用关系。
-
记录灰色节点的删除关系。
这两种方案在最终标记阶段会整理并发标记阶段中的引用关系的变化,保证存活的对象会被搜索到。在CMS中采用的是第一个方案,叫做Incremental update,在G1中采用的是第二种方案,叫做STAB(Snapshot-At-Beginning)。
Incremental update关注的是第一个条件的打破,即引用关系的插入。Incremental update利用write barrier将所有新插入的引用关系都记录下来,最后以这些引用关系的src为根STW地重新扫描一遍即避免了漏标问题。
SATB关注的是第二个条件的打破,即引用关系的删除。SATB利用pre write barrier将所有即将被删除的引用关系的旧引用记录下来,最后以这些旧引用为根STW地重新扫描一遍即可避免漏标问题。
五、Rset
由于新生代的垃圾收集通常很频繁,如果老年代对象引用了新生代的对象,那么,需要跟踪从老年代到新生代的所有引用,从而避免每次YGC时扫描整个老年代,减少开销。JVM使用一个结构叫做Card Table来记录谁引用了我(point-in),这样在YGC阶段只需要扫描年轻代中各个Card Table中记录的老年代对象即可。
在G1中又使用了一个新的结构Rset来记录我引用了谁(point-out),一个Region被分为多个Card Table,维护一个Rset,记录着引用到本region中的对象的其他region的Card。这样的好处是可以对region进行单独回收,这要求RSet不只是维护老年代到年轻代的引用,也要维护这老年代到老年代的引用,对于跨代引用的每次只要扫描这个region的RSet上的Card即可。
六、G1与CMS比较
在上面的介绍中已经提到了不少G1和CMS的区别,在这里再次总结一下
-
G1使用停顿预测
-
内存结构的不够
-
CMS只能用在老年代,G1在新生代老年代都可以使用
-
CMS会产生内存碎片,G1整体上使用的是标记-整理算法,避免的内存碎片的产生
-
在并发标记阶段采用的技术不同,CMS使用Incremental update,G1使用STAB
-
在remark阶段G1耗时更小
-
G1和CMS都会产生浮动垃圾
七、G1日志
2019-08-08T17:18:00.733+0800: 178504.896: [GC pause (G1 Evacuation Pause) (young)
Desired survivor size 301989888 bytes, new threshold 15 (max 15)
- age 1: 1385360 bytes, 1385360 total
- age 2: 389088 bytes, 1774448 total
- age 3: 455928 bytes, 2230376 total
- age 4: 620632 bytes, 2851008 total
- age 5: 27168 bytes, 2878176 total
- age 6: 394680 bytes, 3272856 total
- age 7: 12400 bytes, 3285256 total
- age 8: 608 bytes, 3285864 total
- age 9: 236688 bytes, 3522552 total
- age 10: 336 bytes, 3522888 total
- age 11: 489064 bytes, 4011952 total
- age 12: 316944 bytes, 4328896 total
- age 13: 12120 bytes, 4341016 total
- age 14: 2072 bytes, 4343088 total
- age 15: 512 bytes, 4343600 total
178504.897: [G1Ergonomics (CSet Construction) start choosing CSet, _pending_cards: 6803, predicted base time: 11.03 ms, remaining time: 88.97 ms, target pause time: 100.00 ms]
178504.897: [G1Ergonomics (CSet Construction) add young regions to CSet, eden: 1147 regions, survivors: 3 regions, predicted young region time: 12.85 ms]
178504.897: [G1Ergonomics (CSet Construction) finish choosing CSet, eden: 1147 regions, survivors: 3 regions, old: 0 regions, predicted pause time: 23.88 ms, target pause time: 100.00 ms]
2019-08-08T17:18:00.745+0800: 178504.908: [SoftReference, 0 refs, 0.0015087 secs]2019-08-08T17:18:00.747+0800: 178504.910: [WeakReference, 0 refs, 0.0004373 secs]2019-08-08T17:18:00.747+0800: 178504.910: [FinalReference, 19154 refs, 0.0012160 secs]2019-08-08T17:18:00.748+0800: 178504.911: [PhantomReference, 0 refs, 168 refs, 0.0008367 secs]2019-08-08T17:18:00.749+0800: 178504.912: [JNI Weak Reference, 0.0000690 secs], 0.0187290 secs]
[Parallel Time: 10.9 ms, GC Workers: 15]
[GC Worker Start (ms): Min: 178504897.0, Avg: 178504897.1, Max: 178504897.3, Diff: 0.3]
[Ext Root Scanning (ms): Min: 1.8, Avg: 2.0, Max: 2.6, Diff: 0.8, Sum: 30.6]
[Update RS (ms): Min: 0.0, Avg: 0.6, Max: 0.7, Diff: 0.7, Sum: 9.4]
[Processed Buffers: Min: 0, Avg: 13.4, Max: 26, Diff: 26, Sum: 201]
[Scan RS (ms): Min: 0.1, Avg: 0.2, Max: 0.2, Diff: 0.1, Sum: 2.9]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 7.1, Avg: 7.2, Max: 7.2, Diff: 0.1, Sum: 108.0]
[Termination (ms): Min: 0.4, Avg: 0.4, Max: 0.5, Diff: 0.1, Sum: 6.6]
[Termination Attempts: Min: 257, Avg: 290.2, Max: 313, Diff: 56, Sum: 4353]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 1.4]
[GC Worker Total (ms): Min: 10.4, Avg: 10.6, Max: 10.8, Diff: 0.4, Sum: 159.0]
[GC Worker End (ms): Min: 178504907.7, Avg: 178504907.7, Max: 178504907.8, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 7.3 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 4.3 ms]
[Ref Enq: 0.2 ms]
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.1 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 1.1 ms]
[Eden: 4588.0M(4588.0M)->0.0B(4596.0M) Survivors: 12.0M->8192.0K Heap: 7347.2M(8192.0M)->2758.0M(8192.0M)]
[Times: user=0.19 sys=0.00, real=0.02 secs]
- [GC pause (G1 Evacuation Pause) (young):GC的原因是YGC
- Desired survivor size 301989888 bytes, new threshold 15 (max 15):surivivor区大小为301989888字节,年龄超过15的对象才进入老年代 age 1: 1385360 bytes, 1385360 total:survivor区各个年龄带对象的大小
- [G1Ergonomics (CSet Construction) start choosing CSet, _pending_cards: 6803, predicted base time: 11.03 ms, remaining time: 88.97 ms, target pause time: 100.00 ms]:会根据目标停顿时间动态选择部分垃圾对并多的Region回收,这一步就是选择Region。_pending_cards是关于RSet的Card Table。predicted base time是预测的扫描card table时间。
- [G1Ergonomics (CSet Construction) add young regions to CSet, eden: 1147 regions, survivors: 3 regions, predicted young region time: 12.85 ms]:这一步是添加Region到collection set
- [G1Ergonomics (CSet Construction) finish choosing CSet, eden: 1147 regions, survivors: 3 regions, old: 0 regions, predicted pause time: 23.88 ms, target pause time: 100.00 ms]:这一步是对上面两步的总结。预计总收集时间23.88ms
- [SoftReference, 0 refs, 0.0015087 secs]2019-08-08T17:18:00.747+0800: 178504.910: [WeakReference, 0 refs, 0.0004373 secs]2019-08-08T17:18:00.747+0800: 178504.910: [FinalReference, 19154 refs, 0.0012160 secs]2019-08-08T17:18:00.748+0800: 178504.911: [PhantomReference, 0 refs, 168 refs, 0.0008367 secs]2019-08-08T17:18:00.749+0800: 178504.912: [JNI Weak Reference, 0.0000690 secs], 0.0187290 secs]:各种引用的统计
- [Parallel Time: 10.9 ms, GC Workers: 15]使用15个线程并行进行,总共耗时10.9ms
- [GC Worker Start (ms): Min: 178504897.0, Avg: 178504897.1, Max: 178504897.3, Diff: 0.3]:收集线程开始的时间,使用的是相对时间,Min是最早开始时间,Avg是平均开始时间,Max是最晚开始时间,Diff是Max-Min(下同)
- [Ext Root Scanning (ms): Min: 1.8, Avg: 2.0, Max: 2.6, Diff: 0.8, Sum: 30.6]:gc root扫描耗时
- [Update RS (ms): Min: 0.0, Avg: 0.6, Max: 0.7, Diff: 0.7, Sum: 9.4]:更新Remembered Set上的时间
- [Processed Buffers: Min: 0, Avg: 13.4, Max: 26, Diff: 26, Sum: 201]:处理buffer记录消耗的时间
- [Scan RS (ms): Min: 0.1, Avg: 0.2, Max: 0.2, Diff: 0.1, Sum: 2.9]:扫描CS中的region对应的RSet,因为RSet是points-into,所以这样实现避免了扫描old generadion region,但是会产生float garbage
- [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]:扫描code root耗时。code root指的是经过JIT编译后的代码里,引用了heap中的对象。引用关系保存在RSet中。
- [Object Copy (ms): Min: 7.1, Avg: 7.2, Max: 7.2, Diff: 0.1, Sum: 108.0]:拷贝活的对象到新region的耗时
- [Termination (ms): Min: 0.4, Avg: 0.4, Max: 0.5, Diff: 0.1, Sum: 6.6]:线程结束,在结束前,它会检查其他线程是否还有未扫描完的引用,如果有,则”偷”过来,完成后再申请结束,这个时间是线程之前互相同步所花费的时间
- [GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 1.4]:花费在其他工作上的时间
- [GC Worker Total (ms): Min: 10.4, Avg: 10.6, Max: 10.8, Diff: 0.4, Sum: 159.0]:每个线程花费的时间和
- [GC Worker End (ms): Min: 178504907.7, Avg: 178504907.7, Max: 178504907.8, Diff: 0.1]:每个线程结束的时间
- [Code Root Fixup: 0.0 ms]:用来将code root修正到正确的evacuate之后的对象位置所花费的时间
- [Code Root Purge: 0.0 ms]:清除code root的耗时,code root中的引用已经失效,不再指向Region中的对象,所以需要被清除
- [Clear CT: 0.4 ms]:清除card table的耗时
- [Other: 7.3 ms]:其他事项共耗时,其他事项包括选择CSet,处理已用对象,引用入ReferenceQueues,大对象的注册、声明,释放CSet中的region到free list
- [Eden: 4588.0M(4588.0M)->0.0B(4596.0M) Survivors: 12.0M->8192.0K Heap: 7347.2M(8192.0M)→2758.0M(8192.0M)]:年轻代被清空,大小调整到4596M
八、G1常见问题
-
G1中频繁的大对象分配会导致性能问题,应尽可能避免大对象的产生,可以指定-XX:G1HeapRegionSize。
-
在Evacuation的时候没有足够的to-space来存放晋升的对象;并发处理过程完成之前空间耗尽。这两种情况会导致Full gc,G1中发生Full gc时使用的是Serial GC,简直是灾难级别,但是在JDK11后已经优化成了Parallel并发gc。
九、G1常用配置
| 配置项 | 作用 | 建议值 |
|---|---|---|
| -XX:+UseG1GC | 使用G1来垃圾回收 | |
| -XX:MaxGCPauseMillis | 最大STW时间 | 默认值200ms |
| -XX:+ParallelRefProcEnabled | 使用多线程进行引用处理 | 强烈建议打开 |
| -XX:G1NewSizePercent | 年轻代大小最小百分比,如果太小会造成过多young GC,太大的话young GC时间过长 | 默认5,建议20,可根据具体业务场景调整 |
| -XX:G1MaxNewSizePercent | 年轻代大小最大百分比 | 默认60,建议75,可根据具体业务场景调整 |
| -XX:+UnlockExperimentalVMOptions | 解锁实验标记,打开后上面两项才会生效 | |
| -XX:+PrintClassHistogram | gc日志参数,打印类信息 | |
| XX:+PrintTenuringDistribution | gc日志参数,打印对象年龄 | |
| -XX:+PrintGCApplicationStoppedTime | 打印应用STW时间,不仅是包括gc,还有jvm的一些操作 | |
| -XX:+PrintGCTimeStamps | gc日志参数,打印gc具体发生时间 | |
| -XX:+PrintAdaptiveSizePolicy | gc日志参数,打印自适应调整策略、gc原因 | |
| -XX:+PrintReferenceGC | gc日志参数,打印引用处理细节 | |
| -XX:-UseBiasedLocking | 关闭偏向锁,偏向锁是synchronized优化,使用会增加stw时间 | 对时间敏感的服务建议关闭偏向锁 |