程序员的自我修养--链接、装载与库笔记:静态链接
1. 空间与地址分配
对于链接器来说,整个链接过程中,它就是将几个输入目标文件加工后合并成一个输出文件。测试代码a.c和b.c内容如下:
// a.c
extern int shared;
int main()
{
int a = 100;
swap(&a, &shared);
}// b.c
int shared = 1;
void swap(int* a, int* b)
{
*a ^= *b ^= *a ^= *b;
}
通过执行:$ gcc -c a.c b.c ,生成a.o, b.o。
可执行文件中的代码段和数据段都是由输入的目标文件合并而来的。对于多个输入目标文件,链接器如何将它们的各个段合并到输出文件?方法如下:
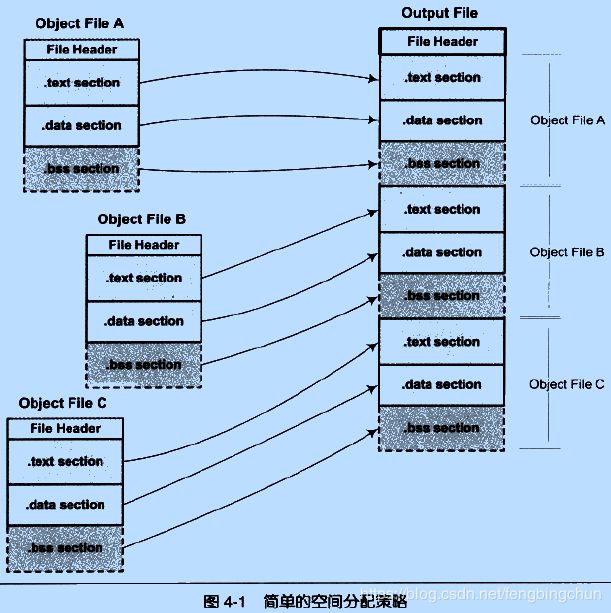
按序叠加:一个最简单的方案就是将输入的目标文件按照次序叠加起来,如下图所示:就是直接将各个目标文件依次合并。但是这样做会造成一个问题,在有很多输入文件的情况下,输出文件将会有很多零散的段。这种做法非常浪费空间,因为每个段都需要有一定的地址和空间对齐要求,比如对于x86的硬件来说,段的装载地址和空间的对齐单位是页,也就是4096字节,那么就是说如果一个段的长度只有1个字节,它也要在内存中占用4096字节。这样会造成内存空间大量的内部碎片。
相似段合并:一个更实际的方法是将相同性质的段合并到一起,比如将所有输入文件的”.text”合并到输出文件的”.text”段,接着是”.data”段、”.bass”段等,如下图所示:”.bss”段在目标文件和可执行文件中并不占用文件的空间,但是它在装载时占用地址空间。所以链接器在合并各个段的同时,也将”.bss”合并,并且分配虚拟空间。
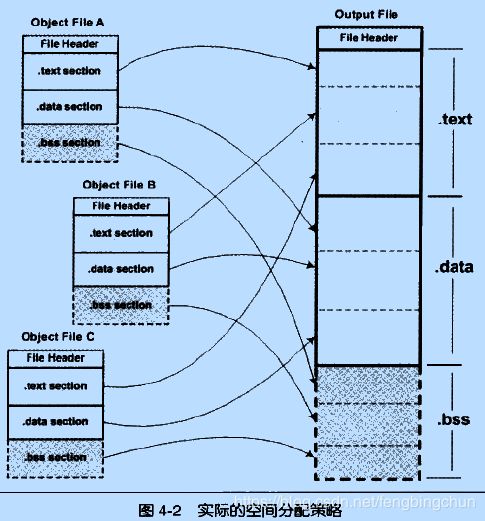
“链接器为目标文件分配地址和空间”这句话中的”地址和空间”其实有两个含义:第一个是在输出的可执行文件中的空间;第二个是在装载后的虚拟地址中的虚拟地址空间。对于有实际数据的段,比如”.text”和”.data”来说,它们在文件中和虚拟地址中都要分配空间,因为它们在这两者中都存在;而对于”.bss”这样的段来说,分配空间的意义只局限于虚拟地址空间,因为它在文件中并没有内容。
现在的链接器空间分配(只关注于虚拟地址空间的分配)的策略基本上都采用上述方法中的第二种,使用这种方法的链接器一般都采用一种叫两步链接(Two-pass Linking)的方法。也就是说整个链接过程分两步:
第一步:空间与地址分配:扫描所有的输入目标文件,并且获得它们的各个段的长度、属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局符号表。这一步中,链接器将能够获得所有输入目标文件的段长度,并且将它们合并,计算出输出文件中各个段合并后的长度与位置,并建立映射关系。
第二步:符号解析与重定位:使用上面第一步中收集到的所有信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等。
使用ld链接器将”a.o”和”b.o”链接起来:$ ld a.o b.o -e main -o ab
”-e main”表示将main函数作为程序入口,ld链接器默认的程序入口为_start。”-o ab”表示链接输出文件名为ab,默认为a.out。使用objdump来查看链接前后地址的分配情况,如下图所示:
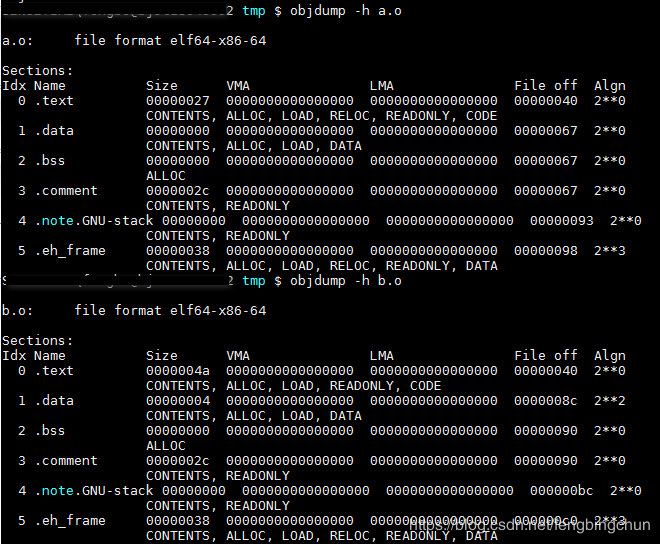
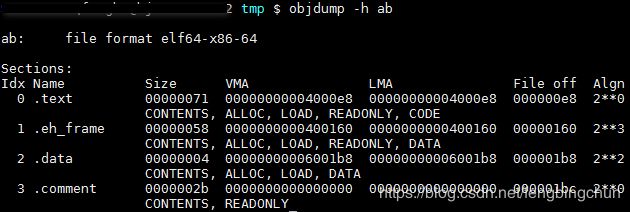
VMA表示Virtual Memory Addredd,即虚拟地址,LMA表示Load Memory Address,即加载地址,正常情况下这两个值应该是一样的,但是有些嵌入式系统中,特别是在那些程序放在ROM的系统中时,LMA和VMA是不相同的。
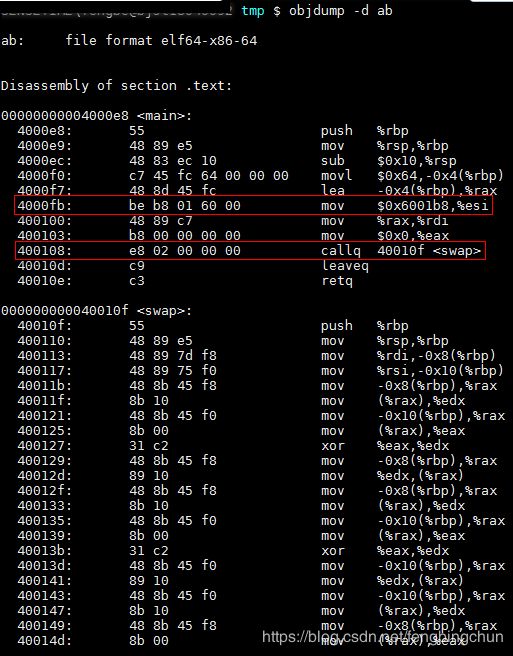
链接前后的程序中所使用的地址已经是程序在进程中的虚拟地址,即我们关心上面各个段中的VMA和Size,而忽略文件偏移(File off)。我们可以看到,在链接之前,目标文件中的所有段的VMA都是0,因为虚拟空间还没有被分配,所以他们默认都为0.等到链接之后,可执行文件”ab”中的各个段都被分配到了相应的虚拟地址。这里的输出程序”ab”中,”.text”段被分配到了地址0x00000000004000e8,大小为0x00000071字节;”.data”段从地址0x 00000000006001b8开始,大小为0x00000004字节。可以看到,”a.o”和”b.o”的代码段被先后叠加起来,合并成”ab”的一个”.text”段,加起来的长度为0x00000071。所以”ab”的代码段里面肯定包含了main函数和swap函数的指令代码。
符号地址的确定:在第一步的扫描和空间分配阶段,链接器按照前面介绍的空间分配方法进行分配,这时候输入文件中的各个段在链接后的虚拟地址就已经确定了,比如”.text”段起始地址为0x00000000004000e8,”.data”段的起始地址为0x 00000000006001b8。当前面一步完成之后,链接器开始计算各个符号的虚拟地址。因为各个符号在段内的相对位置是固定的,所以这时候其实”main”、”shared”和”swap”的地址也已经是确定的了,只不过链接器须要给每个符号加上一个偏移量,使它们能够调整到正确的虚拟地址。比如我们假设”a.o”中的”main”函数相对于”a.o”的”.text”段偏移是X,但是经过链接合并以后,”a.o”的”.text”段位于虚拟地址0x00000000004000e8,那么”main”的地址应该是0x00000000004000e8+X。从前面”objdump”的输出看到,”main”位于”a.o”的”.text”段的最开始,也就是偏移为0,所以”main”这个符号在最终的输出文件中的地址应该是0x00000000004000e8+0,即0x00000000004000e8。我们也可以通过完全一样的计算方法得知所有符号的地址,在这个例子里面,只有三个全局符号,所以链接器在更新全局符号表的符号地址以后,各个符号的最终地址如下图所示:

2. 符号解析与重定位
重定位:在完成空间和地址的分配步骤以后,链接器就进入了符号解析与重定位的步骤。使用objdump的”-d”参数查看”a.o”的代码段反汇编结果如下图所示:在程序的代码里面使用的都是虚拟地址,在这里也可以看到”main”的起始地址为0x0000000000000000,这是因为在未进行前面提到过的空间分配之前,目标文件代码段中的起始地址以0x0000000000000000开始,等到空间分配完成以后,各个函数才会确定自己在虚拟地址空间中的位置。从反汇编结果中,可以看到”a.o”共定义了一个函数main。这个函数占用0x26个字节,共11条指令;最左边那列是每条指令的偏移量,每一行代表一条指令(有些指令的长度很长)。图中红框标出了两个引用”shared”和”swap”的位置,对于”shared”的引用是一条”mov”指定。另外一个是偏移为0x20的指令的一条调用指令,它其实就表示对swap函数的调用。
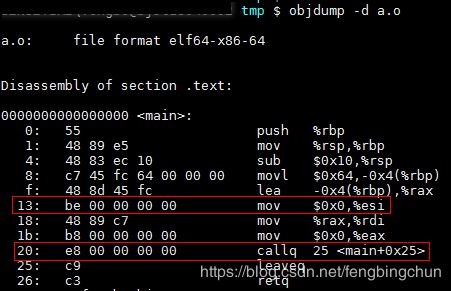
链接器在完成地址和空间分配之后就已经可以确定所有符号的虚拟地址了,那么链接器就可以根据符号的地址对每个需要重定位的指令进行地位修正。用objdump来反汇编输出程序”ab”的代码段,可以看到main函数的两个重定位入口都已经被修正到正确的位置,如下图所示:经过修正以后,”shared”和“swap”的地址分别为0x6001b8和0x40010f。
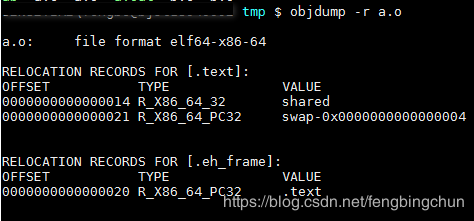
重定位表:专门用来保存与重定位相关的信息,它在ELF文件中往往是一个或多个段。对于可重定位的ELF文件来说,它必须包含有重定位表,用来描述如何修改相应的段里的内容。对于每个要被重定位的ELF段都有一个对应的重定位表,而一个重定位表往往就是ELF文件中的一个段,所以其实重定位表也可以叫重定位段。可以使用objdump来查看文件的重定位表,如下图所示:”objdump -r a.o”命令可以用来查看”a.o”里面要重定位的地方,即”a.o”所有引用到外部符号的地址。每个要被重定位的地方叫一个重定位入口(Relocation Entry),可以看到”a.o”里面有两个重定位入口。重定位入口的偏移(Offset)表示该入口在要被重定位的段中的位置,”RELOCATION RECORDS FOR [.text]”表示这个重定位是代码段的重定位表,所以偏移表示代码段中需要被调整的位置。对照前面的反汇编结果可以知道,这里的0x14和0x21分别就是代码段中的”mov”指令和”callq”指令的地址部分。
对于64位的重定位表是一个Elf64_Rel结构的数组,每个数组元素对应一个重定位入口。Elf64_Rel的定义如下:
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
} Elf64_Rel;Elf64_Rel结构说明如下:

符号解析:如果直接使用ld来链接”a.o”,而不将”b.o”作为输入,链接器就会发现shared和swap两个符号没有被定义,没有办法完成链接工作,如下图所示:就是链接时符号未定义。导致这个问题的原因很多,最常见的一般都是链接时缺少了某个库,或者输入目标文件路径不正确或符号的声明与定义不一样。

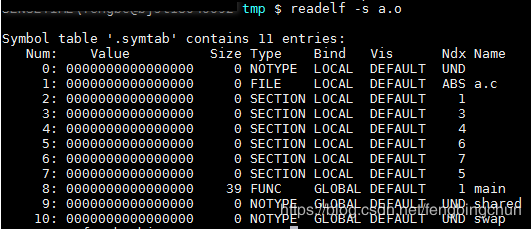
其实重定位过程也伴随着符号的解析过程,每个目标文件都可能定义一些符号,也可能引用到定义在其它目标文件的符号。重定位的过程中,每个重定位的入口都是对一个符号的引用,那么当链接器须要对某个符号的引用进行重定位时,它就要确定这个符号的目标地址。这时候链接器就会去查找由所有输入目标文件的符号表组成的全局符号表,找到相应的符号后进行重定位。比如查看”a.o”的符号表,如下图所示”GLOBAL”类型的符号,除了”main”函数是定义在代码段之外,其它两个”shared”和”swap”都是”UND”,即”undefined”未定义类型,这种未定义的符号都是因为该目标文件中有关于它们的重定位项。所以在链接器扫描完所有的输入目标文件之后,所有这些未定义的符号都应该能够在全局符号表中找到,否则链接器就报符号未定义错误。
指令修正方式:不同的处理器指令对于地址的格式和方式都不一样。寻址方式有如下区别:近址寻址或远址寻址;绝对寻址或相对寻址;寻址长度为8位、16位、32位或64位。绝对寻址修正和相对寻址修正的区别就是绝对寻址修正后的地址为该符号的实际地址;相对寻址修正后的地址为符号距离被修正位置的地址差。
3. COMMON块:现在的编译器和链接器都支持一种叫COMMON块(Common Block)的机制。现代的链接机制在处理弱符号的时候,采用的就是与COMMON块一样的机制,当不同的目标文件需要的COMMON块空间大小不一致时,以最大的那块为准。COMMON类型的链接规则是针对符号都是弱符号的情况,如果其中有一个符号为强符号,那么最终输出结果中的符号所占空间与强符号相同。值的注意的是,如果链接过程中有弱符号大小大于强符号,那么ld链接器会报警告。未初始化的全局变量就是典型的弱符号。GCC的”-fno-common”也允许我们把所有未初始化的全局变量不以COMMON块的形式处理,或者使用”__attribute__”扩展,即int global __attribute__((nocommon)); 一旦一个未初始化的全局变量不是以COMMON块的形式存在,那么它就相当于一个强符号,如果其它目标文件中还有同一个变量的强符号定义,链接时就会发生符号重复定义错误。
4. C++相关问题
C++的一些语言特性使之必须由编译器和链接器共同支持才能完成工作。最主要的有两个方面,一个是C++的重复代码消除,还有一个就是全局构造与析构。另外由于C++语言的各种特性,比如虚函数、函数重载、继承、异常等,使得它背后的数据结构异常复杂,这些数据结构往往在不同的编译器和链接器之间相互不能通用,使得C++程序的二进制兼容性成了一个很大的问题。
重复代码消除:C++编译器在很多时候会产生重复的代码,比如模板(Templates)、外部内联函数(Extern Inline Function)和虚函数表(Virtual Function Table)都有可能在不同的编译单元里生成相同的代码。如模板,从本质上来讲很像宏,当模板在一个编译单元里被实例化时,它并不知道自己是否在别的编译单元也被实例化了。所以当一个模板在多个编译单元同时实例化成相同的类型的时候,必然会生成重复的代码。当然,最简单的方案就是不管这些,将这些重复的代码都保留下来,不过这样做的主要问题有以下几个方面:空间浪费、地址容易出错、指令运行效率较低。
一个比较有效的做法就是将每个模板的实例代码都单独地存放在一个段里,每个段只包含一个模板实例。这样链接器在最终链接的时候可以区分这些相同的模板实例段,然后将它们合并入最后的代码段。这种做法被主流的编译器所采用,GNU GCC编译器和VISUAL C++编译器都采用了类似的方法。GCC把这种类似的需要在最终链接时合并的段叫”Link Once”,它的做法是将这种类型的段命名为”.gnu.linkonce.name”,其中”name”是该模板函数实例的修饰后名称。VISUAL C++编译器做法稍有不同,它把这种类型的段叫做”COMDAT”,这种”COMDAT”段的属性字段(PE文件的段表结构里面的IMAGE_SECTION_HEADER的Characteristics成员)都有IMAGE_SCN_LNK_COMDAT这个标记,在链接器看到这个标记后,它就认为该段是COMDAT类型的,在链接时会将重复的段丢弃。
这种重复代码消除对于模板来说是这样的,对于外部内联函数和虚函数表的做法也类似。比如对于一个有虚函数的类来说,有一个与之相对应的虚函数表(Virtual Function Table,一般简称vtbl),编译器会在用到该类的多个编译单元生成虚函数表,造成代码重复;外部内联函数、默认构造函数、默认拷贝构造函数和赋值操作符也有类似的问题。它们的解决方式基本跟模板的重复代码消除类似。
这种方法虽然能够基本上解决代码重复的问题,但还是存在一些问题。比如相同名称的段可能拥有不同的内容,这可能由于不同的编译单元使用了不同的编译器版本或者编译优化选项,导致同一个函数编译出来的实际代码有所不同。那么这种情况下链接器可能会做出一个选择,那就是随意选择其中任何一个副本作为链接的输入,然后同时提供一个警告信息。
函数级别链接:由于现在的程序和库通常来讲都非常庞大,一个目标文件可能包含成千上百个函数或变量。当我们需要用到某个目标文件中的任意一个函数或变量时,就需要把它整个地链接起来,也就是说那些没有用到的函数也被一起链接了起来。这样的后果是链接输出文件会变得很大,所有用到的没用到的变量和函数都一起塞到了输出文件中。
VISUAL C++编译器提供了一个编译选项叫函数级别链接(Functional-Level Linking, /Gy),这个选项的作用就是让所有的函数都向前面模板函数一样,单独保存到一个段里面。当链接器需要用到某个函数时,它就将它合并到输出文件中,对于那些没有用的函数则将它们抛弃。这种做法可以很大程度上减少输出文件的长度,减少空间浪费。但是这个优化选项会减慢编译和链接过程,因为链接器需要计算各个函数之间的依赖关系,并且所有函数都保存到独立的段中,目标函数的段的数量大大增加,重定位过程也会因为段的数目的增加而变得复杂,目标文件随着段数目的增加也会变得相对较大。
GCC编译器也提供了类似的机制,它有两个选择分别是”-ffunction-sections”和”-fdata-sections”,这两个选项的作用就是将每个函数或变量分别保持到独立的段中。
全局构造与析构:一般的一个C/C++程序时从main开始执行的,随着main函数的结束而结束。然而,其实在main函数被调用之前,为了程序能够顺利执行,要先初始化进程执行环境,比如堆分配初始化(malloc, free)、线程子系统等。C++的全局对象构造函数也是在这一时期被执行的,C++的全局对象的构造函数在main之前被执行,C++全局对象的析构函数在main之后被执行。
Linux系统下一般程序的入口是”_start”,这个函数是Linux系统库(Glibc)的一部分。当我们的程序与Glibc库链接在一起形成最终可执行文件以后,这个函数就是程序的初始化部分的入口,程序初始化部分完成一系列初始化过程之后,会调用main函数来执行程序的主体。在main函数执行完成以后,返回到初始化部分,它进行一些清理工作,然后结束进程。
ELF文件还定义了两种特殊的段:
(1). .init:该段里面保存的是可执行指令,它构成了进程的初始化代码。因此,当一个程序开始运行时,在main函数被调用之前,Glibc的初始化部分安排执行这个段的中的代码。
(2). .fini:该段保存着进程终止代码指令。因此,当一个程序的main函数正常退出时,Glibc会安排执行这个段中的代码。
这两个段.init和.fini的存在有着特别的目的,如果一个函数放到.init段,在main函数执行前系统就会执行它。同理,假如一个函数放到.fini段,在main函数返回后该函数就会被执行。利用这两个特性,C++的全局构造和析构函数就由此实现。
C++与ABI:如果要使两个编译器编译出来的目标文件能够相互链接,那么这两个目标文件必须满足下面这些条件:采用同样的目标文件格式、拥有同样的符号修饰标准、变量的内存分布方式相同、函数的调用方式相同,等等。其中我们把符号修饰标准、变量内存布局、函数调用方式等这些跟可执行代码二进制兼容性相关的内容称为ABI(Application Binary Interface)。API往往是指源代码级别的接口;而ABI是指二进制层面的接口。影响ABI的因素非常多,硬件、编程语言、编译器、链接器、操作系统等都会影响ABI。对于C语言的目标代码来说,以下几个方面会决定目标文件之间是否二进制兼容:
(1). 内置类型(如int、float、char等)的大小和在存储器中的放置方式(大端、小端、对齐方式等)。
(2). 组合类型(如struct、union、数组等)的存储方式和内存分布。
(3). 外部符号(external-linkage)与用户定义的符号之间的命名方式和解析方式,如函数名func在C语言的目标文件中是否被解析成外部符号_func。
(4). 函数调用方式,比如参数入栈顺序、返回值如何保持等。
(5). 堆栈的分布方式,比如参数和局部变量在堆栈里的位置,参数传递方法等。
(6). 寄存器使用约定,函数调用时哪些寄存器可以修改,哪些需要保存,等等。
这只是一部分因素。到了C++的时代,语言层面对ABI的影响又增加了很多额外的内容,正是这些内容使C++要做到二进制兼容比C来得更为不易:
(7). 继承类体系的内存分布,如基类,虚基类在继承类中的位置等。
(8). 指向成员函数的指针(pointer-to-member)的内存分别,如何通过指向成员函数的指针来调用成员函数,如何传递this指针。
(9). 如何调用虚函数,vtable的内容和分布形式,vtable指针在object中的位置等。
(10). template如何实例化。
(11). 外部符号的修饰。
(12). 全局对象的构造和析构。
(13). 异常的产生和捕获机制。
(14). 标准库的细节问题,RTTI如何实现等。
(15). 内嵌函数访问细节。
C++一直为人诟病的一大原因是它的二进制兼容性不好,或者说比起C语言来更为不易。不仅不同的编译器编译的二进制代码之间无法相互兼容,有时候连同一个编译器的不同版本之间兼容性也不好。
5. 静态库链接:
在一般的情况下,一种语言的开发环境往往会附带有语言库(Language Library)。这些库就是对操作系统的API(Application Programming Interface, 应用程序编程接口)的包装,比如C语言版”Hello World”程序,它使用C语言标准库的”printf”函数来输出一个字符串,”printf”函数对字符串进行一些必要的处理后,最后会调用操作系统提供的API。各个操作系统下,往终端输出字符串的API都不一样,在Linux下,它是一个”write”的系统调用,而在Windows下它是”WriteConsole”系统API。
其实一个静态库可以简单地看成一组目标文件的集合,即很多目标文件经过压缩打包后形成的一个文件。比如我们在Linux中最常用的C语言静态库libc位于/usr/lib/x86_64-linux-gnu/libc.a,它属于glibc项目的一部分;像Windows这样的平台上,最常使用的C语言库是由集成开发环境所附带的运行库,这些库一般由编译器厂商提供,比如Visual C++附带了多个版本的C/C++运行库。
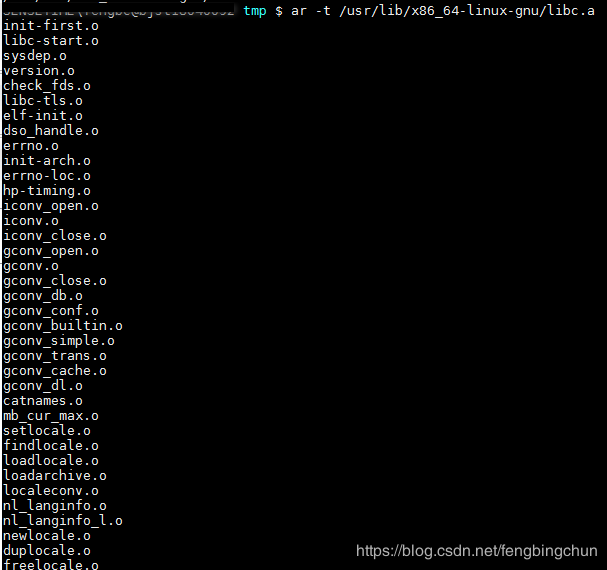
在一个C语言的运行库中,包含了很多跟系统功能相关的代码,比如输入输出、文件操作、时间日期、内存管理等。glibc本身是用C语言开发的,它由成百上千个C语言源代码文件组成,也就是说,编译完成以后有相同数量的目标文件,比如输入输出有printf.o,scanf.o;文件操作有fread.o, fwrite.o;时间日期有date.o, time.o;内存管理有malloc.o等。把这些零散的目标文件直接提供给库的使用者,很大程度上会造成文件传输、管理和组织方面的不便,于是通常人们使用”ar”压缩程序将这些目标文件压缩到一起,并且对其进行编号和索引,以便于查找和检索,就形成了libc.a这个静态库文件。我们也可以使用”ar”工具来查看这个文件包含了哪些目标文件,如下图所示,仅显示一小部分:
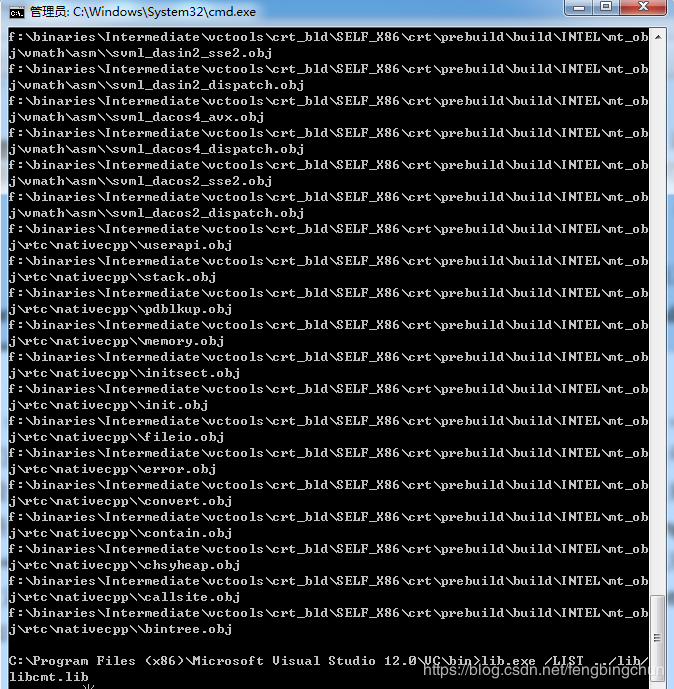
Visual C++也提供了与Linux下的ar类似的工具,叫lib.exe,这个程序可以用来创建、提取、列举.lib文件中的内容。使用”lib.exe /LIST ../libcmt.lib”就可以列举出libcmt.lib中所有的目标文件,如下图所示:
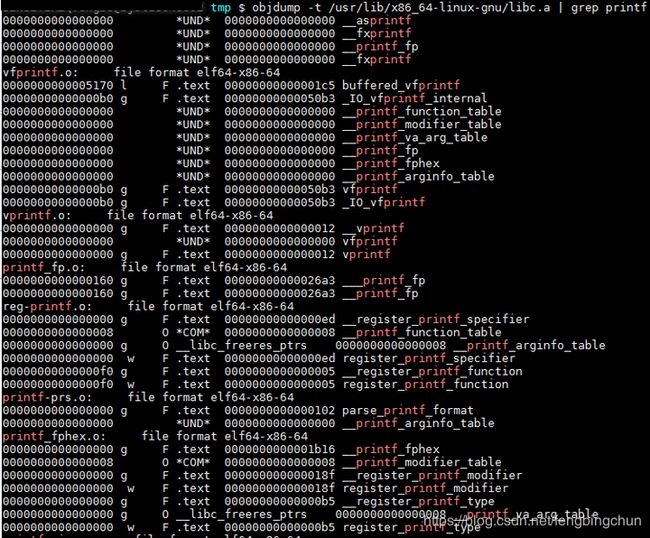
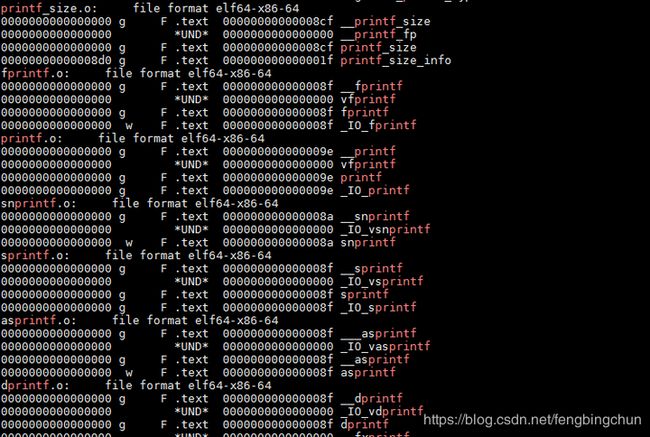
libc.a里面包含了很多个目标文件,我们如何在这么多目标文件中找到”printf”函数所在的目标文件呢?是使用”objdump”或”readelf”加上文本查找工具如”grep”,执行结果如下图所示:可以看到”printf”函数被定义在了”printf.o”这个目标文件中。通过命令“$ar -x /usr/lib/x86_64-linux-gnu/libc.a”,会将libc.a中的所有目标文件”解压”至当前目录,也可以找到”printf.o”。
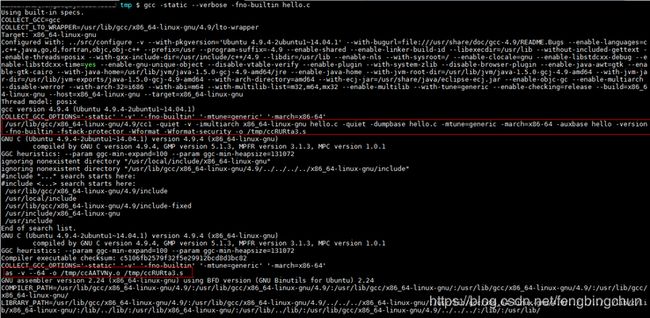
可以通过GCC的”--verbose”参数将整个编译链接过程的中间步骤打印出来,默认情况下,GCC会自作聪明地将”Hello World”程序中只使用了一个字符串参数的”printf”替换成”puts”函数,以提高运行速度,要使用”-fno-builtin”参数关闭这个内置函数优化选项,执行结果如下图所示:关键的三个步骤在图中已经用红线框起来了,第一步是调用cc1程序,这个程序实际上就是GCC的C语言编译器,它将”hello.c”编译成一个临时的汇编文件”/tmp/ccRURta3.s”;然后调用as程序,as程序是GNU的汇编器,它将”/tmp/ccRURta3.s”汇编成临时目标文件”/tmp/ccAATVNy.o”,这个”/tmp/ccAATVNy.o”实际上就是”hello.o”;接着最关键的步骤是最后一步,GCC调用collect2程序来完成最后的链接。实际上collect2可以看做是ld链接器的一个包装,它会调用ld链接器来完成对目标文件的链接,然后再对链接结果进行一些处理,主要是收集所有与程序初始化相关的信息并且构造初始化的结构。可以看到最后一步中,有几个库和目标文件被链接入了最终可执行文件。

为什么静态运行库里面一个目标文件只包含一个函数:比如libc.a里面pritnf.o只有printf()函数。链接器在链接静态库的时候是以目标文件为单位的。比如我们引用了静态库中的printf()函数,那么链接器就会把库中包含printf()函数的那个目标文件链接进来,如果很多函数都放在一个目标文件中,很可能很多没用的函数都被一起链接进了输出结果中。由于运行库有成百上千个函数,数量非常庞大,每个函数独立地放在一个目标文件中可以尽量减少空间的浪费,那么没有被用到的目标文件(函数)就不要链接到最终的输出文件中。
6. 链接过程控制
绝大部分情况下,我们使用链接器提供的默认链接规则对目标文件进行链接。这在一般情况下是没有问题的,但对于一些特殊要求的程序,比如操作系统内核、BIOS(Basic Input Output Syste)或一些在没有操作系统的情况下运行的程序(如引导程序Boot Loader或者嵌入式系统的程序,或者有一些脱离操作系统的硬盘分区软件PQMagic等),以及另外的一些需要特殊的链接过程的程序,如一些内核驱动程序等,它们往往受限于一些特殊的条件,如需要指定输出文件的各个段虚拟地址、段的名称、段存放的顺序等,因为这些特殊的环境,特别是某些硬件条件的限制,往往对程序的各个段的地址有着特殊的要求。
由于整个链接过程有很多内容需要确定:使用哪些目标文件?使用哪些库文件?是否在最终可执行文件中保留调试信息、输出文件格式(可执行文件还是动态链接库)?还要考虑是否要导出某些符号以供调试器或程序本身或其它程序使用等。
操作系统内核:从本质上来讲,它本身也是一个程序。比如Windows的内核ntoskrnl.exe就是一个我们平常看到的PE文件,它的位置位于C:\Windows\System32\ntoskrnl.exe。很多人误以为Windows操作系统的内核很庞大,由很多文件组成。这是一个误解,其实真正的Windows内核就是这个文件。
链接控制脚本:链接器一般都提供多种控制整个链接过程的方法,以用来产生用户所需要的文件。一般链接器有如下三种方法:
(1). 使用命令行来给链接器指定参数,如前面所使用的ld的-o, -e参数就属于这类。
(2). 将链接指令存放在目标文件里面,编译器经常会通过这种方法向链接器传递指令。方法也比较常见,比如VISUAL C++编译器会把链接参数放在PE目标文件的.drectve段以用来传递参数。
(3). 使用链接控制脚本,也是最为灵活、最为强大的链接控制方法。
由于各个链接器平台的链接控制过程各不相同。ld链接器的链接脚本功能非常强大。VISUAL C++也允许使用脚本来控制整个链接过程,VISUAL C++把这种控制脚本叫做模块定义文件(Module-Definition File),它们的扩展名一般为.def。
ld在用户没有指定链接脚本的时候会使用默认链接脚本。我们可以使用”$ ld -verboase”命令来查看ld默认的链接脚本。默认的ld链接脚本存放在/usr/lib/ldscripts/下,不同的机器平台、输出文件格式都有相应的链接脚本,如下图所示:ld会根据命令行要求使用相应的链接脚本文件来控制链接过程。当然,为了更加精确地控制链接过程,我们可以自己写一个脚本,然后指定该脚本为链接控制脚本,比如可以使用-T参数,如link.script已存在,执行命令”$ ld -T link.script”。

最”小”的程序:为了演示链接的控制过程,我们接着要做一个最小的程序:这个程序的功能是在终端上输出”Hello world!”。这个”小程序”能够脱离C语言运行库,使用nomain作为整个程序的入口,将”小程序”的所有段都合并到一个叫”tinytext”的段,这个段是我们任意命名的,是由链接脚本控制链接过程生成的。
TinyHelloWorld.c源代码如下:
char* str = "Hello world!\n";
void print()
{
asm("movl $13, %%edx \n\t"
"movl %0, %%ecx \n\t"
"movl $0, %%ebx \n\t"
"movl $4, %%eax \n\t"
"int $0x80 \n\t"
::"r"(str):"edx", "ecx", "ebx");
}
void exit()
{
asm("movl $42, %ebx \n\t"
"movl $1, %eax \n\t"
"int $0x80 \n\t");
}
void nomain()
{
print();
exit();
}依次执行命令及结果如下:

从源代码可以看到,程序入口为nomain()函数,然后该函数调用print()函数,打印”Hello World”,接着调用exit()函数,结束进程。这里的print函数使用了Linux的WRITE系统调用,exit()函数使用了EXIT系统调用。这里我们使用了GCC内嵌汇编。
GCC和ld的参数意义如下:
(1). -fno-builtin:GCC编译器提供了很多内置函数(Built-in Function),它会把一些常用的C库函数替换成编译器的内置函数,以达到优化的功能。比如GCC会将只有字符串参数的printf函数替换成puts,以节省格式解析的时间。exit()函数也是GCC的内置参数之一,所以要使用-fno-builtin参数来关闭GCC内置函数功能。
(2). -static:这个参数表示ld将使用静态链接的方式来链接程序,而不是使用默认的动态链接的方式。
(3). -e nomain:表示该程序的入口函数为nomain,这个参数就是将ELF文件头的e_entry成员赋值成nomain函数的地址。
(4). -o TinyHelloWorld:表示指定输出可执行文件名为TinyHelloWorld。
使用ld链接脚本:如果把整个链接过程比作一台计算机,那么ld链接器就是计算机的CPU,所有的目标文件、库文件就是输入,链接结果输出的可执行文件就是输出,而链接控制脚本正是这台计算机的”程序”,它控制CPU的运行,以”程序”要求的方式将输入加工成所需要的输出结果。链接控制脚本”程序”使用一种特殊的语言写成,即ld的链接脚本语言。
无论是输出文件还是输入文件,它们的主要的数据就是文件中的各种段,我们把输入文件中的段称为输入段(Input Sections),输出文件中的段称为输出段(Output Sections)。简单来讲,控制链接过程无非是控制输入段如何变成输出段,比如哪些输入段合并一个输出段,哪些输入段要丢弃;指定输出段的命名、装载地址、属性,等等。TinyHelloWorld的链接脚本TinyHelloWorld.lds(一般链接脚本名都以lds作为扩展名ld script)的内容如下:
ENTRY(nomain)
SECTIONS
{
. = 0X08048000 + SIZEOF_HEADERS;
tinytext : { *(.text) *(.data) *(.rodata) }
/DISCARD/ : { *(.comment) }
}
这是一个非常简单的链接脚本,第一行的ENTRY(nomain)指定了程序的入口为nomain()函数;后面的SECTIONS命令一般是链接脚本的主体,这个命令指定了各种输入段到输出段的变换,SECTIONS后面紧跟着的一对大括号里面包含了SECTIONS变换规则,其中有三条语句,每条语句一行。第一条是赋值语句,后面两条是段转换规则,它们的含义分别如下:
(1). . = 0x08048000 + SIZEOF_HEADERS:第一条赋值语句的意思是将当前虚拟地址设置成0x08048000 + SIZEOF_HEADERS,SIZEOF_HEADERS为输出文件的文件头大小。”.”表示当前虚拟地址,因为这条语句后面紧跟着输出段”tinytext”,所以”tinytext”段的起始虚拟地址即为0x08048000 + SIZEOF_HEADERS。它将当前虚拟地址设置成一个比较巧妙的值,以便于装载时页映射更为方便。
(2). tinytext: { *(.text) *(.data) *(.rodata) }:第二条是个段转换规则,它的意思即为所有输入文件中的名字为”.text”, “.data”或”.rodata”的段依次合并到输出文件的”tinytext”。
(3). /DISCARD/ : { *(.comment) }:第三条规则为:将所有输入文件中的名字为”.comment”的段丢弃,不保存到输出文件中。
通过上述两条转换规则,我们就达到了TinyHelloWorld程序的第三个要求:最终输出的可执行文件只有一个叫做”tinytext”的段。通过以下命令编译并且启用该链接控制脚本,结果如下图所示:
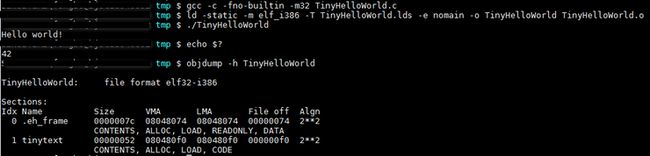
执行这个程序能够在终端上正确显示”Hello world!”。如果使用objdump查看TinyHelloWorld的段,我们达到了目的,有一个段”tinytext”。你可以通过ld的-s参数禁止链接器产生符号表,或者使用strip命令去除程序中的符号表。
ld链接脚本语法简介:ld链接器的链接脚本语法继承与AT&T链接器命令语言的语法,风格有点像C语言。链接脚本由一系列语句组成,语句分两种,一种是命令语句,另外一种是赋值语句。如ENTRY(nomain)就是命令语句,而. = 0x08048000 + SIZEOF_HEADERS则是一个赋值语句。之所以说链接脚本语法像C语言,主要有如下几点相似之处:
(1). 语句之间使用分号”;”作为分隔符:原则上讲语句之间都要以”;”作为分隔符,但是对于命令语句来说也可以使用换行来结束该语句,对于赋值语句来说必须以”;”结束。
(2). 表达式与运算符:脚本语言的语句中可以使用C语言类似的表达式和运算操作符,比如+, -, *, /, +=, -=, *=等,甚至包括&, |, >>, <<等这些位操作符。
(3). 注释和字符引用:使用/* */作为注释。脚本文件中使用到的文件名、格式名或段名等凡是包含”;”或其它的分隔符的,都要使用双引号将该名字全称引用起来,如果文件名包含引号,则很不幸,无法处理。
命令语句一般的格式是由一个关键字和紧跟其后的参数所组成。
7. BFD库
BFD库(Binary File Descriptor library)是一个GNU项目,它的目标就是希望通过一种统一的接口来处理不同的目标文件格式。BFD这个项目本身是binutils项目的一个子项目。BFD把目标文件抽象成一个统一的模型,比如在这个抽象的目标文件模型中,最开始有一个描述整个目标文件总体信息的”文件头”,就跟我们实际的ELF文件一样,文件头后面是一系列的段,每个段都有名字、属性和段的内容,同时还抽象了符号表、重定位表、字符串表等类似的概念,使得BFD库的程序只要通过操作这个抽象的目标文件模型就可以实现操作所有BFD支持的目标文件格式。
现在GCC、链接器ld、调试器GDB及binutils的其它工具都通过BFD库来处理目标文件,而不是直接操作目标文件。这样做最大的好处是将编译器和链接器本身同具体的目标文件格式隔离开来,一旦我们需要支持一种新的目标文件格式,只需要在BFD库里面添加一种格式就可以了,而不需要修改编译器和链接器。
GitHub: https://github.com/fengbingchun/Messy_Test