深度学习笔记
目录
什么是深度学习
简介
释义
深度学习典型模型
卷积神经网络模型
深度信任网络模型
堆栈自编码网络模型
深度学习框架
Tensorflow
Caffe
Microsoft Cognitive Toolkit / CNTK
火炬/ PyTorch
MXNet
深度神经网络的模块
1. 深度神经网络的基本零件
1.1 常用层:
1.2 卷积层
1.3. 池化层
1.4. 正则化层
1.5. 反卷积层
2. 深度神经网络的上下游结构
2.2. 输入模块
2.3 凸优化模块
转自:https://cloud.tencent.com/developer/ask/184862
对腾讯云社区大神问答的归纳:
什么是深度学习
简介
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
深度学习是一类模式分析方法的统称,就具体研究内容而言,主要涉及三类方法:
(1)基于 卷积运算 的神经网络系统,即卷积神经网络(CNN)。
(2)基于多层神经元的自编码神经网络,包括自编码( Auto encoder)以及近年来受到广泛关注的稀疏编码两类( Sparse Coding)。
(3)以多层自编码神经网络的方式进行预训练,进而结合鉴别信息进一步优化神经网络权值的深度置信网络(DBN)。
通过 多层处理 ,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。由此可将深度学习理解为进行 “特征学习”(feature learning)或 “表示学习”(representation learning)。
以往在机器学习用于现实任务时,描述样本的特征通常需由人类专家来设计,这成为“特征工程”(feature engineering)。众所周知,特征的好坏对泛化性能有至关重要的影响,人类专家设计出好特征也并非易事;特征学习(表征学习)则通过机器学习技术自身来产生好特征,这使机器学习向“全自动数据分析”又前进了一步。
释义
深度学习是机器学习的一种,而机器学习是实现人工智能的必经路径。深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。
从一个输入中产生一个输出所涉及的计算可以通过一个流向图(flow graph)来表示:流向图是一种能够表示计算的图,在这种图中每一个节点表示一个基本的计算以及一个计算的值,计算的结果被应用到这个节点的子节点的值。考虑这样一个计算集合,它可以被允许在每一个节点和可能的图结构中,并定义了一个函数族。输入节点没有父节点,输出节点没有子节点。
这种流向图的一个特别属性是深度(depth):从一个输入到一个输出的最长路径的长度。

深度学习典型模型
典型的深度学习模型有卷积神经网络( convolutional neural network)、DBN和堆栈自编码网络(stacked auto-encoder network)模型等,下面对这些模型进行描述。
卷积神经网络模型
在无监督预训练出现之前,训练深度神经网络通常非常困难,而其中一个特例是卷积神经网络。卷积神经网络受视觉系统的结构启发而产生。第一个卷积神经网络计算模型是在Fukushima(D的神经认知机中提出的,基于神经元之间的局部连接和分层组织图像转换,将有相同参数的神经元应用于前一层神经网络的不同位置,得到一种平移不变神经网络结构形式。后来,Le Cun等人在该思想的基础上,用误差梯度设计并训练卷积神经网络,在一些模式识别任务上得到优越的性能。至今,基于卷积神经网络的模式识别系统是最好的实现系统之一,尤其在手写体字符识别任务上表现出非凡的性能。

深度信任网络模型
DBN可以解释为贝叶斯概率生成模型,由多层随机隐变量组成,上面的两层具有无向对称连接,下面的层得到来自上一层的自顶向下的有向连接,最底层单元的状态为可见输入数据向量。DBN由若2F结构单元堆栈组成,结构单元通常为RBM(RestIlcted Boltzmann Machine,受限玻尔兹曼机)。堆栈中每个RBM单元的可视层神经元数量等于前一RBM单元的隐层神经元数量。根据深度学习机制,采用输入样例训练第一层RBM单元,并利用其输出训练第二层RBM模型,将RBM模型进行堆栈通过增加层来改善模型性能。在无监督预训练过程中,DBN编码输入到顶层RBM后,解码顶层的状态到最底层的单元,实现输入的重构。RBM作为DBN的结构单元,与每一层DBN共享参数。
堆栈自编码网络模型
堆栈自编码网络的结构与DBN类似,由若干结构单元堆栈组成,不同之处在于其结构单元为自编码模型( auto-en-coder)而不是RBM。自编码模型是一个两层的神经网络,第一层称为编码层,第二层称为解码层。
深度学习框架
深度学习是执行更高级别复杂任务的关键,成功构建和部署它们对全球数据科学家和数据工程师来说是一个巨大的挑战。今天,我们拥有无数的框架,使我们能够开发出可以提供更好抽象级别的工具,同时简化困难的编程挑战。每个框架都以不同的方式构建,以用于不同的目的。深度学习框架通过高级编程接口为深度神经网络的设计,培训和验证提供了构建模块。介绍以下这8个深度学习框架,以便您更好地了解哪个框架最适合您,或者在解决您的业务挑战时更方便。
Tensorflow

可以说是最好的深度学习框架之一,现在已被大规模的几家巨头采用,如空中客车,Twitter,IBM等,这主要归功于其高度灵活的系统架构。
最着名的TensorFlow用例必须是谷歌翻译,加上自然语言处理,文本分类/摘要,语音/图像/手写识别,预测和标记等功能。
TensorFlow可在桌面和移动设备上使用,并且还支持Python,C ++和R等语言,以创建深度学习模型以及包装器库。
TensorFlow附带2个广泛使用的工具 -
- TensorBoard用于网络建模和性能的有效数据可视化
- TensorFlow用于快速部署新算法/实验,同时保留相同的服务器架构和API。它还提供与其他TensorFlow模型的集成,这与传统实践不同,可以扩展为其他模型和数据类型。
如果您在深度学习方面碰巧迈出了第一步,那么您应该选择TensorFlow,这是基于Python的,由Google支持,并附带文档和演练来指导您。
Caffe

Caffe是一个深度学习框架,支持C,C ++,Python,MATLAB等接口以及命令行界面。众所周知,它的速度和可转换性及其在卷积神经网络(CNN)建模中的适用性。使用Caffe的C ++库(附带Python接口)的最大好处是从深度网络存储库“Caffe Model Zoo”访问可用网络,这些网络已经过预先培训,可以立即使用。无论是建模CNN还是解决图像处理问题,这都必须成为首选图书馆。
Caffe最大的USP就是速度。它可以使用单个Nvidia K40 GPU每天处理超过六千万张图像。这是用于推理的1 ms /图像和用于学习的4 ms /图像,更新的库版本仍然更快。
Caffe是一种流行的视觉识别深度学习网络。但是,Caffe不支持像TensorFlow或CNTK中那样的细粒度网络层。鉴于该体系结构,对循环网络和语言建模的总体支持非常差,并且建立复杂的层类型必须以低级语言完成。
Microsoft Cognitive Toolkit / CNTK

Microsoft Cognitive Toolkit(以前称为CNTK)是一种开源深度学习框架,用于训练深度学习模型,因其易于培训和跨服务器的流行模型类型而闻名。它执行有效的卷积神经网络和基于图像,语音和文本的数据培训。与Caffe类似,它受Python,C ++和命令行界面等接口的支持。
鉴于其资源的连贯使用,可以使用工具包轻松完成强化学习模型或生成对抗网络(GAN)。众所周知,与在Theano或TensorFlow等工具包上运行时,在多台机器上运行时,可提供更高的性能和可扩展性。
与Caffe相比,在发明新的复杂层类型时,由于构建块的精细粒度,用户不需要以低级语言实现它们。Microsoft Cognitive Toolkit支持RNN和CNN类型的神经模型,因此能够处理图像,手写和语音识别问题。目前,由于缺乏对ARM架构的支持,移动设备的功能相当有限。
火炬/ PyTorch

Torch是一种科学计算框架,可为机器学习算法提供广泛支持。它是一个基于Lua的深度学习框架,广泛应用于Facebook,Twitter和Google等行业巨头。它采用CUDA和C / C ++库进行处理,基本上是为了扩展建筑模型的生产和整体灵活性。
毕竟,PyTorch已经在深度学习框架社区中获得了很高的采用率,并且被认为是TensorFlow的竞争对手。PyTorch基本上是Torch深度学习框架的一个端口,用于构建深度神经网络和执行高度复杂的张量计算。
与Torch相反,PyTorch在Python上运行,这意味着任何对Python有基本了解的人都可以开始构建他们自己的深度学习模型。
鉴于PyTorch框架的架构风格,与Torch相比,整个深度建模过程更简单,更透明。
MXNet

MXNet(发音为mix-net)专为高效率,高生产率和灵活性而设计,是一个深度学习框架,由Python,R,C ++和Julia支持。
MXNet的优点在于它为用户提供了使用各种编程语言(Python,C ++,R,Julia和Scala等)编写代码的能力。这意味着您可以使用您喜欢的任何语言训练您的深度学习模型,而无需从头学习新东西。使用C ++和CUDA编写的后端,MXNet能够扩展和使用无数的GPU,这使得它对企业来说是不可或缺的。例如 - 亚马逊使用MXNet作为深度学习的参考库。
MXNet支持长短期内存(LTSM)网络以及RNN和CNN。这种深度学习框架以其在成像,手写/语音识别,预测以及NLP方面的能力而闻名。
此外还有Chainer 、Keras 、Deeplearning4j等其他架构。
深度神经网络的模块
我们可以简单的将深度神经网络的模块,分成以下的三个部分,即深度神经网络上游的基于生成器的 输入模块,深度神经网络本身,以及深度神经网络下游基于批量梯度下降算法的 凸优化模块:
- 批量输入模块
- 各种深度学习零件搭建的深度神经网络
- 凸优化模块
其中,搭建深度神经网络的零件又可以分成以下类别:
各种深度学习零件搭建的深度神经网络
- 常用层
- Dense
- Activation
- Dropout
- Flatten
- 卷积层
- Conv2D
- Cropping2D
- ZeroPadding2D
- 池化层
- MaxPooling2D
- AveragePooling2D
- GlobalAveragePooling2D
- 正则化层
- BatchNormalization
- 反卷积层(Keras中在卷积层部分)
- UpSampling2D
需要强调一下,这些层与之前一样,都 同时包括了正向传播、反向传播两条通路。我们这里只介绍比较好理解的正向传播过程,基于其导数的反向过程同样也是存在的,其代码已经包括在 Tensorflow 的框架中对应的模块里,可以直接使用。当然还有更多的零件,具体可以去keras 文档中参阅。接下来的部分,我们将首先介绍这些深度神经网络的零件,然后再分别介绍上游的批量输入模块,以及下游的凸优化模块。
1. 深度神经网络的基本零件
1.1 常用层:
1.1.1. Dense
Dense 层,就是我们上一篇文章里提到的 Linear 层,即 y=wx+b ,计算乘法以及加法。
1.1.2. Activation
Activation 层在我们上一篇文章中,同样出现过,即 Tanh层以及Sigmoid层,他们都是 Activation 层的一种。当然 Activation 不止有这两种形式,比如有:
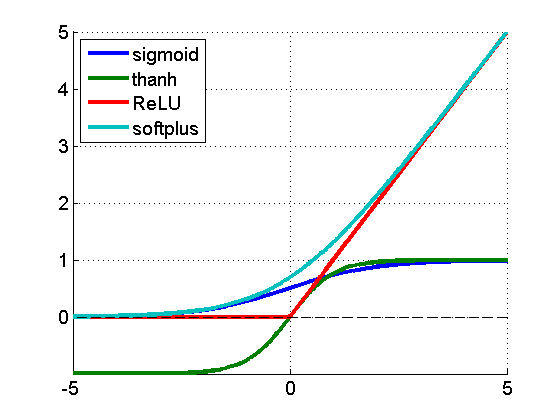
图片来源 激活函数与caffe及参数
这其中 relu 层可能是深度学习时代最重要的一种激发函数,在2011年首次被提出。由公式可见,relu 相比早期的 tanh 与 sigmoid函数, relu 有两个重要的特点,其一是在较小处都是0(sigmoid,relu)或者-5(tanh),但是较大值relu函数没有取值上限。其次是relu层在0除不可导,是一个非线性的函数:
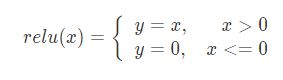
即 y=x*(x>0)
对其求导,其结果是:
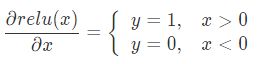
1.1.3. Dropout
Dropout 层,指的是在训练过程中,每次更新参数时将会随机断开一定百分比(rate)的输入神经元,这种方式可以用于防止过拟合。

图片来源Dropout: A Simple Way to Prevent Neural Networks from Overfitting
1.1.4. Flatten
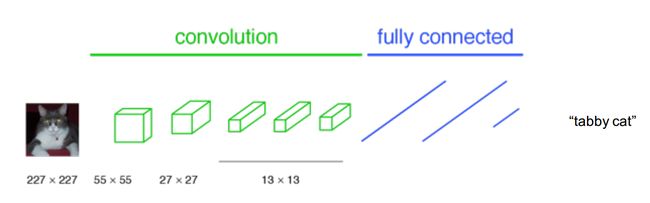
Flatten 层,指的是将高维的张量(Tensor, 如二维的矩阵、三维的3D矩阵等)变成一个一维张量(向量)。Flatten 层通常位于连接深度神经网络的 卷积层部分 以及 全连接层部分。
1.2 卷积层
提到卷积层,就必须讲一下卷积神经网络。我们在第一讲的最后部分提高深度学习模型预测的准确性部分,提了一句 “使用更复杂的深度学习网络,在图片中挖出数以百万计的特征”。这种“更复杂的神经网络”,指的就是卷积神经网络。卷积神经网络相比之前基于 Dense 层建立的神经网络,有所区别之处在于,卷积神经网络可以使用更少的参数,对局部特征有更好的理解。
1.2.1. Conv2D
我们这里以2D 的卷积神经网络为例,来逐一介绍卷积神经网络中的重要函数。比如我们使用一个形状如下的卷积核:
|
|
|
|
|---|---|---|
| 1 |
0 |
1 |
| 0 |
1 |
0 |
| 1 |
0 |
1 |
扫描这样一个二维矩阵,比如一张图片:
|
|
|
|
|
|
|---|---|---|---|---|
| 1 |
1 |
1 |
0 |
0 |
| 0 |
1 |
1 |
1 |
0 |
| 0 |
0 |
1 |
1 |
1 |
| 0 |
0 |
1 |
1 |
0 |
| 0 |
1 |
1 |
0 |
0 |
其过程与结果会是这样:

图片来源kdnuggets
当然,这里很重要的一点,就是正如我们上一讲提到的, Linear 函数的 w, b两个参数都是变量,会在不断的训练中,不断学习更新。卷积神经网络中,卷积核其实也是一个变量。这里的
|
|
|
|
|---|---|---|
| 1 |
0 |
1 |
| 0 |
1 |
0 |
| 1 |
0 |
1 |
可能只是初始值,也可能是某一次迭代时选用的值。随着模型的不断训练,将会不断的更新成其他值,结果也将会是一个不规则的形状。具体的更新方式,同上一讲提到的 Linear 等函数模块相同,卷积层也有反向传播函数,基于反向函数计算梯度,即可用来更新现有的卷积层的值,具体方法可参考CNN的反向传导练习。举一个经过多次学习得到的卷积神经网络的卷积核为例:
| AlexNet |
第一层卷积层的96个、大小为 11x11 的卷积核结果矩阵。 |
|---|---|
|
|
|


图片来源Alexnet 2012年文章
清楚了其原理,卷积神经网络还需要再理解几个输入参数:
Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', ...)
其中:
filters指的是输出的卷积层的层数。如上面的动图,只输出了一个卷积层,filters = 1,而实际运用过程中,一次会输出很多卷积层。kernel_size指的是卷积层的大小,是一个 二维数组,分别代表卷积层有几行、几列。strides指的是卷积核在输入层扫描时,在 x,y 两个方向,每间隔多长扫执行一次扫描。padding这里指的是是否扫描边缘。如果是valid,则仅仅扫描已知的矩阵,即忽略边缘。而如果是same,则将根据情况在边缘补上0,并且扫描边缘,使得输出的大小等于 input_size / strides。
1.2.2. Cropping2D
这里 Cropping2D 就比较好理解了,就是特地选取输入图像的某一个固定的小部分。比如车载摄像头检测路面的马路线时,摄像头上半部分拍到的天空就可以被 Cropping2D函数直接切掉忽略不计。

图片来源Udacity自动驾驶课程
1.2.3. ZeroPadding2D
在1.2.1部分提到输入参数时,提到 padding参数如果是same,扫描图像边缘时会补上0,确保输出数量等于 input / strides。这里 ZeroPadding2D 的作用,就是在图像外层边缘补上几层0。如下图,就是对原本 32x32x3 的图片进行 ZeroPadding2D(padding=(2, 2)) 操作后的结果:
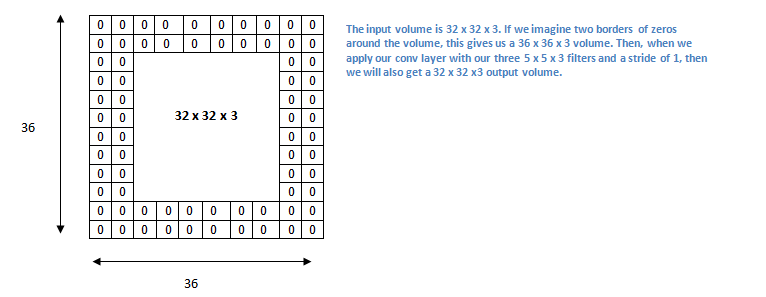
图片来源Adit Deshpande博客
1.3. 池化层
1.3.1. MaxPooling2D
可能大家在上一部分会意识到一点,就是通过与一个相同的、大小为11x11的卷积核做卷积操作,每次移动步长为1,则相邻的结果会非常接近,正是由于结果接近,有很多信息是冗余的。
因此,MaxPooling 就是一种减少模型冗余程度的方法。以 2x 2 MaxPooling 为例。图中如果是一个 4x4 的输入矩阵,则这个 4x4 的矩阵,会被分割成由两行、两列组成的 2x2 子矩阵,然后每个 2x2 子矩阵取一个最大值作为代表,由此得到一个两行、两列的结果:

图片来源 斯坦福CS231课程
1.3.2. AveragePooling2D
AveragePooling 与 MaxPooling 类似,不同的是一个取最大值,一个是平均值。如果上图的 MaxPooling 换成 AveragePooling2D,结果会是:
|
|
|
|---|---|
| 3.25 |
5.25 |
| 2 |
2 |
1.3.3. GlobalAveragePooling2D
GlobalAveragePooling,其实指的是,之前举例 MaxPooling 提到的 2x2 Pooling,对子矩阵分别平均,变成了对整个input 矩阵求平均值。
这个理念其实和池化层关系并不十分紧密,因为他扔掉的信息有点过多了,通常只会出现在卷积神经网络的最后一层,通常是作为早期深度神经网络 Flatten 层 + Dense 层结构的替代品:

前面提到过 Flatten 层通常位于连接深度神经网络的 卷积层部分 以及 全连接层部分,但是这个连接有一个大问题,就是如果是一个 1k x 1k 的全连接层,一下就多出来了百万参数,而这些参数实际用处相比卷积层并不高。造成的结果就是,早期的深度神经网络占据内存的大小,反而要高于后期表现更好的神经网络:
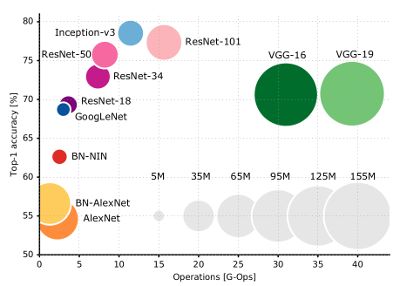
图片来源Training ENet on ImageNet
更重要的是,全连接层由于参数偏多,更容易造成 过拟合——前文提到的 Dropout 层就是为了避免过拟合的一种策略,进而由于过拟合,妨碍整个网络的泛化能力。于是就有了用更多的卷积层提取特征,然后不去 Flatten 这些 k x k 大小卷积层,直接把这些 k x k 大小卷积层变成一个值,作为特征,连接分类标签。
1.4. 正则化层
除了之前提到的 Dropout 策略,以及用 GlobalAveragePooling取代全连接层的策略,还有一种方法可以降低网络的过拟合,就是正则化,这里着重介绍下 BatchNormalization。
1.4.1. BatchNormalization
BatchNormalization 确实适合降低过拟合,但他提出的本意,是为了加速神经网络训练的收敛速度。比如我们进行最优值搜索时,我们不清楚最优值位于哪里,可能是上千、上万,也可能是个负数。这种不确定性,会造成搜索时间的浪费。
BatchNormalization就是一种将需要进行最优值搜索数据,转换成标准正态分布,这样optimizer就可以加速优化:
输入:一批input 数据: B
期望输出: β,γ
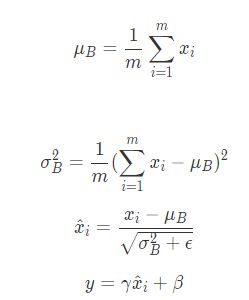
具体如何实现正向传播和反向传播,可以看这里。
1.5. 反卷积层
最后再谈一谈和图像分割相关的反卷积层。
之前在 1.2 介绍了卷积层,在 1.3 介绍了池化层。相信读者大概有了一种感觉,就是卷积、池化其实都是在对一片区域计算平均值、最大值,进而忽略这部分信息。换言之,卷积+池化,就是对输入图片打马赛克。
但是马赛克是否有用?我们知道老司机可以做到“图中有码,心中无码”,就是说,图片即便是打了马赛克、忽略了细节,我们仍然可以大概猜出图片的内容。这个过程,就有点反卷积的意思了。
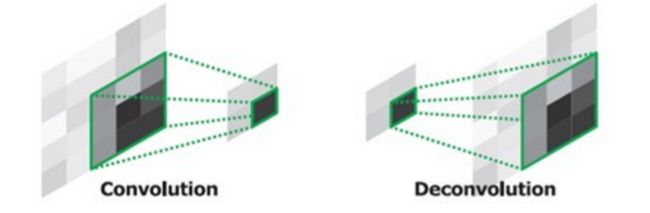
利用反卷积层,可以基于 卷积层+全连接层结构,构建新的、用于图像分割的神经网络 结构。这种结构不限制输入图片的大小,
| 卷积+全连接层结构 |
全卷积层结构 |
|---|---|
|
|
|

图片来源:Fully Convolutional Networks for Semantic Segmentation
1.5.1. UpSampling2D
上图在最后阶段使用了 Upsampling 模块,这个同样在 Tensorflow 的 keras 模块可以找到。用法和 MaxPooling2D 基本相反,比如:
UpSampling2D(size=(2, 2))
就相当于将输入图片的长宽各拉伸一倍,整个图片被放大了。
当然,Upsampling 实际上未必在网络的最后才使用,我们后面文章提到的 unet 网络结构,每一次进行卷积操作缩小图片大小,后期都会使用 Upsampling 函数增大图片。
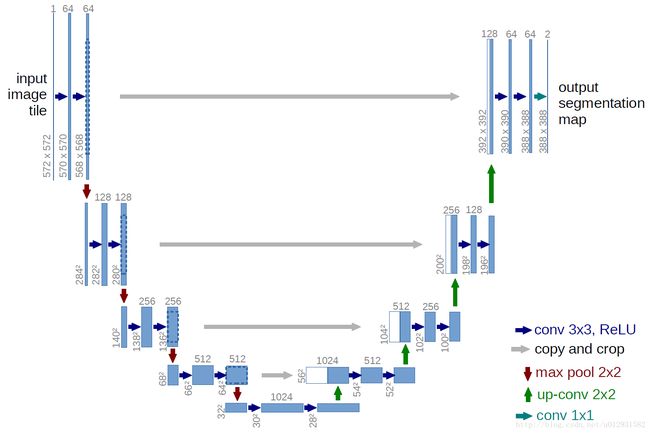
图片来源 U-Net: Convolutional Networks for Biomedical Image Segmentation
2. 深度神经网络的上下游结构
介绍完深度神经网络的基本结构以后,读者可能已经意识到了,1.3.3 部分提到的深度神经网络的参数大小动辄几十M、上百M,如何合理训练这些参数是个大问题。这就需要在这个网络的上下游,合理处理这个问题。
海量参数背后的意义是,深度神经网络可以获取海量的特征。第一讲中提到过,深度学习是脱胎于传统机器学习的,两者之间的区别,就是深度学习可以在图像处理中,自动进行特征工程,如我们第一讲所言:
想让计算机帮忙挖掘、标注这些更多的特征,这就离不开 更优化的模型 了。事实上,这几年深度学习领域的新进展,就是以这个想法为基础产生的。我们可以使用更复杂的深度学习网络,在图片中挖出数以百万计的特征。
这时候,问题也就来了。机器学习过程中,是需要一个输入文件的。这个输入文件的行、列,分别指代样本名称以及特征名称。如果是进行百万张图片的分类,每个图片都有数以百万计的特征,我们将拿到一个 百万样本 x 百万特征 的巨型矩阵。传统的机器学习方法拿到这个矩阵时,受限于计算机内存大小的限制,通常是无从下手的。也就是说,传统机器学习方法,除了在多数情况下不会自动产生这么多的特征以外,模型的训练也会是一个大问题。
深度学习算法为了实现对这一量级数据的计算,做了以下算法以及工程方面的创新:
- 将全部所有数据按照样本拆分成若干批次,每个批次大小通常在十几个到100多个样本之间。(详见下文 输入模块)
- 将产生的批次逐一参与训练,更新参数。(详见下文 凸优化模块)
- 使用 GPU 等计算卡代替 CPU,加速并行计算速度。
这就有点《愚公移山》的意思了。我们可以把训练深度神经网络的训练任务,想象成是搬走一座大山。成语故事中,愚公的办法是既然没有办法直接把山搬走,那就子子孙孙,每人每天搬几筐土走,山就会越来越矮,总有一天可以搬完——这种任务分解方式就如同深度学习算法的分批训练方式。同时,随着科技进步,可能搬着搬着就用翻斗车甚至是高达来代替背筐,就相当于是用 GPU 等高并行计算卡代替了 CPU。
于是,我们这里将主要提到的上游输入模块,以及下游凸优化模块,实际上就是在说如何使用愚公移山的策略,用 少量多次 的方法,去“搬”深度神经网络背后大规模计算量这座大山。
2.2. 输入模块
这一部分实际是在说,当我们有成千上万的图片,存在硬盘中时,如何实现一个函数,每调用一次,就会读取指定张数的图片(以n=32为例),将其转化成矩阵,返回输出。
有 Python 基础的人可能意识到了,这里可能是使用了 Python 的 生成器 特性。其具体作用如廖雪峰博客所言:
创建一个包含100万个元素的 list,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果 list 元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
其关键的写法,是把传统函数的 return 换成 yield:
def generator(samples, batch_size=32):
num_samples = len(samples)
while 1:
sklearn.utils.shuffle(samples)
for offset in range(0, num_samples, batch_size):
batch_samples = samples.iloc[offset:offset+batch_size]
images = []
angles = []
for idx in range(batch_samples.shape[0]):
name = './data/'+batch_samples.iloc[idx]['center']
center_image = cv2.cvtColor( cv2.imread(name), cv2.COLOR_BGR2RGB )
center_angle = float(batch_samples.iloc[idx]['dir'])
images.append(center_image)
angles.append(center_angle)
# trim image to only see section with road
X_train = np.array(images)
y_train = np.array(angles)
yield sklearn.utils.shuffle(X_train, y_train)然后调用时,使用
next(generator)即可一次返回 32 张图像以及对应的标注信息。
当然,keras 同样提供了这一模块,ImageDataGenerator,并且还是加强版,可以对图片进行 增强处理(data argument)(如旋转、反转、白化、截取等)。图片的增强处理在样本数量不多时增加样本量——因为如果图中是一只猫,旋转、反转、颜色调整之后,这张图片可能会不太相同,但它仍然是一只猫:
datagen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
vertical_flip=False)
# compute quantities required for featurewise normalization
datagen.fit(X_train)
2.3 凸优化模块
这一部分谈的是,如何使用基于批量梯度下降算法的凸优化模块,优化模型参数。
前面提到,深度学习的“梯度下降”计算,可以理解成搬走一座大山,而“批量梯度下降”,则是一群人拿着土筐,一点一点把山上的土给搬下山。那么这一点具体应该如何实现呢?其实在第二讲,我们就实现了一个随机批量梯度下降(Stochastic gradient descent, SGD),这里再回顾一下:
def sgd_update(trainables, learning_rate=1e-2):
for t in trainables:
t.value = t.value - learning_rate * t.gradients[t]
#训练神经网络的过程
for i in range(epochs):
loss = 0
for j in range(steps_per_epoch):
# 输入模块,将全部所有数据按照样本拆分成若干批次
X_batch, y_batch = resample(X_, y_, n_samples=batch_size)
# 各种深度学习零件搭建的深度神经网络
forward_and_backward(graph)
# 凸优化模块
sgd_update(trainables, 0.1)
当然,SGD 其实并不是一个很好的方法,有很多改进版本,可以用下面这张gif图概况:

Keras 里,可以直接使用 SGD, Adagrad, Adadelta, RMSProp 以及 Adam 等模块。其实在优化过程中,直接使用 Adam 默认参数,基本就可以得到最优的结果:
from keras.optimizers import Adam
adam = Adam()
model.compile(loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy']).....