CVPR2019 Feature Selective Anchor-Free Module for Single-Shot Object Detection 论文笔记

论文地址 https://arxiv.org/abs/1903.00621
参考Github https://github.com/xuannianz/FSAF
https://github.com/hdjang/Feature-Selective-Anchor-Free-Module-for-Single-Shot-Object-Detection
Overview
- Background
- Image Pyramid 图像金字塔
- Anchor Box
- Pyramidal Feature Hierarchy 特征金字塔
- Feature Pyramid Network 特征金字塔网络
- Feature Pyramid和Anchor Box
- Motivation
- Feature Selective Anchor-Free (FSAF) Module
- General Concept
- Network Architecture
- Ground-Truth and Loss
- Definitions
- Calassification Output
- Box Regression Output
- Online Feature Selection
- Joint Inference and Training
- Takeaway
Background
Object Detection = Classification + Localization,目标检测包含分类和定位两个子任务,但是实际应用中物体尺度变化问题一直是个难解决的问题,比如图中远处的人和近处的马的目标尺寸差别就比较大。目前为止主要是从网络结构设计、损失函数、训练方式等方面去缓解尺度带来的烦恼,特别是小物体检测,至今没有一个好的解决方案。
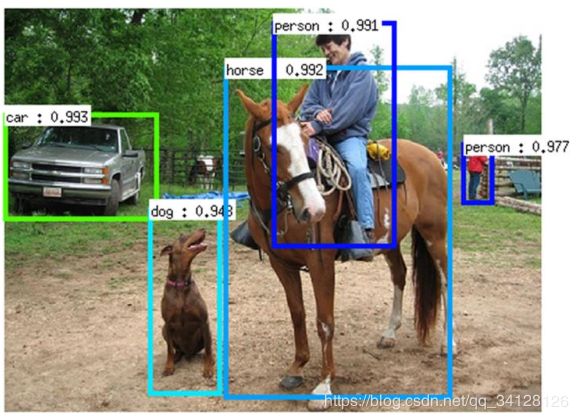
通常的one-stage算法是直接进行多分类,比如背景、前景1和前景2的三分类任务,这中思路会带来“样本极不均衡”问题,毕竟大部分的box都是背景类别。two-stage的算法采用了另外一种思路,它在第一阶段做二分类任务,将“样本极不均衡”问题转换成了“样本较不均衡”问题,第二阶段的前景多分类由于样本均衡,所以任务就变得很简单了,存在的缺点就是算法太耗时。
为了解决one-stage算法面临的“样本极不均衡”问题,在Retinanet论文中,作者提出了focal loss,从损失函数的角度解决该问题。具体来说,作者基于先验知识,proposal的预测置信度越高,说明该proposal对应的gnd box属于简单样本,那么在每一次参数更新的时候,让网络尽量从hard gnd box中学习,从而可以过滤掉背景中的很多简单box,缓解了样本不均衡问题。
Image Pyramid 图像金字塔
简单直接的办法,构建图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的优点在于带来很好的检测精度,缺点在于增加了时间成本;这种处理的方法就是“Multi-Scale Testing”。

输入图片的尺寸对检测模型的性能影响相当明显,事实上,多尺度是提升精度最明显的技巧之一。在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性,仅在测试阶段引入多尺度,也可享受大尺寸和多尺寸带来的增益。

Multi-Scale Training/Testing最早见于*(K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.)*,训练时,预先定义几个固定的尺度,每个epoch随机选择一个尺度进行训练。测试时,生成几个不同尺度的feature map,对每个Region Proposal,在不同的feature map上也有不同的尺度,我们选择最接近某一固定尺寸(即检测头部的输入尺寸)的Region Proposal作为后续的输入。在(Object Detection Networks on Convolutional Feature Maps)中,选择单一尺度的方式被Maxout(element-wise max,逐元素取最大)取代:随机选两个相邻尺度,经过Pooling后使用Maxout进行合并。
Anchor Box

为了解决滑动窗口存在一个窗口只能检测一个目标和无法解决多尺度的问题,在Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks提出采用Anchor Box;采用不同大小和长宽比的Anchor Box密铺整张图片,然后选择IoU(或者其他调整的标准)高的框作为输出;这样就提供了对尺度变化的一种解决方案。
Pyramidal Feature Hierarchy 特征金字塔

浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以利用最后一个卷积层上的feature map来进行预测。这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类。这种方法的优点是速度快、需要内存少。它的缺点是我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。因此有了Pyramidal Feature Hierarchy 特征金字塔所示的架构,它的设计思想就是同时利用低层特征和高层特征,分别在不同的层同时进行预测,这是因为我的一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。它的优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。它的缺点是获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。
SSD将每次卷积得到的特征图(feature map)都进行检测,而我们知道CNN深层网络一般都会经过每层的卷积(pad=0)和池化(stride>=2)将feature map变得越来越小,这样就可以用小的特征图来检测大的目标,大的特征图来检测小的目标。因为特征图越小相当于将图像压缩的越严重,那么图中本来的小物体就会变得特别小导致无法被识别(这也是YOLO无法识别小目标的原因),而在大的特征图用大目标一般很大,而先验框(prior box后面会介绍)大小固定,无法完全包含大的目标,因此无法识别,但是小的目标正相反,恰恰可以被很好识别。
SSD在不同大小的feature map上分别进行预测,具有了多尺度预测的能力,但是特征与特征之间没有融合。
Feature Pyramid Network 特征金字塔网络

一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
首先在输入的图像上进行深度卷积,然后对Layer2上面的特征进行降维操作(即添加一层1x1的卷积层),对Layer4上面的特征就行上采样操作,使得它们具有相应的尺寸,然后对处理后的Layer2和处理后的Layer4执行加法操作(对应元素相加),将获得的结果输入到Layer5中去。其背后的思路是为了获得一个强语义信息,这样可以提高检测性能。并且使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,这样我们就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。
- Setp1 选择一张需要处理的图片,然后对该图片进行预处理操作;
- Setp2 将处理过的图片送入预训练的特征网络中(如ResNet等),即构建所谓的bottom-up网络;
- Setp3 构建对应的top-down网络(即对层4进行上采样操作,先用1x1的卷积对层2进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作;
- Setp4 在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归
- Setp5 将上一步获得的候选ROI分别输入到4、5、6层上面分别进行ROI Pool操作(固定为7x7的特征);
- Setp6 在上一步的基础上面连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层。

FPN能够很好地处理小目标的主要原因是: - FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息);
- 对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息)。
Feature Pyramid和Anchor Box
在single-stage模型中,会定义一系列稠密的均匀分布的anchor,这些anchor会根据其不同的尺寸大小和不同的feature map联系起来。在带有FPN的backbone中,高层的feature map分辨率高,得到的anchor数量多尺寸小,浅层的feature map分辨率低,得到的anchor数量少尺寸大,anchor的生成是根据feature map不同而定义的。底层的特征包含更多的细节,适合用来检测小目标;顶层的特征包含更多的语义信息,适合用来检测大目标。
- Smaller anchor associated with lower pyramid levels
- Larger anchor associated with higher pyramid levels

在anchor match ground truth阶段,ground truth与anchor匹配,确定ground truth归属于哪些anchor,这个过程隐式的决定了ground truth会由哪层feature map负责预测。不管是生成anchor还是ground truth match 过程,都是由size这个变量决定,一般会设定先验的规则来选择最好的feature map,但存在的问题是,仅仅利用size来决定哪些feature map来检测物体是一种暴力的做法。
Motivation

Problem: Feature selection by anchor boxes may not be optimal
采用特征金字塔处理方式的两点局限性:
- herisitc-guided feature selection 启发式的特征选择
- overlap-based anchor sampling overlap-based的anchor 采样训练时,实例通过IoU与最接近的anchor box进行匹配,同时,一个anchor box通过人为预先定义的尺寸被安排到特征层的feature map上。因此,挑选的特征完全基于临时启发所得。比如,一个50x50大小的小车与60x60的小车可能被归为不同的特征层中,而40x40与50x50的通过人为定义会归为同一个层次中。换言之,anchor机制一定程度上受到潜在的启发因素影响。因此,用大量这样挑选的特征训练实例可能并不是最优的。所以基于anchor的特征选取机制是人工设计的。
Feature Selective Anchor-Free (FSAF) Module
FSAF模型主要是让实例选择最合适的特征层次进而来优化网络,因此,在该模型中不应该存在anchor限制特征的选择;以无anchor机制的方法对分类及回归参数进行学习。每个instance自动的选择最合适的feature,在这个模块中,anchor box的大小不再决定选择哪些feature进行预测,也就是说anchor (instance) size成为了一个无关的变量,这也就是anchor-free的由来。因此,feature 选择的依据有原来的instance size变成了instance content,实现了模型自动化学习选择feature。
General Concept

FSAF在特征金字塔的每一层构建一个无anchor的分支,并独立于基于anchor的分支。无anchor分支也包含分类与回归两个子网络。一个实例可以被放到任意层的无anchor分支上。训练时,在feature selection进行特征选择,采用基于实例的内容而不是实例框的大小动态的为每个实例选择最适合的特征层次。选择后的特征用于检测相应的实例。inference时,FASA可以单独预测结果或者结合anchor-based分支。FSAF与backbone无关,同时可以应用在具有特征金字塔的单阶段检测中。此外,anchor-free分支与在线特征选择可以多种多样。

FSAF以RetinaNet为主要结构,添加一个FSAF分支和原来的classification subnet、regression subnet并行,可以不改变原有结构的基础上实现完全的end-to-end training,特别是,FSAF可以独立工作,也可以增加到原有anchor-based brach的模型,比如FSAF可以集成到其他single-stage模型中,比如SSD、DSSD等。
Network Architecture

FSAF采用RetinaNet作为骨干网络,RetinaNet由一个backbone网络及两个任务明确的自网络组成。特征金字塔基于backbone进行构建,P3~P7,金字塔的每一层用于检测物体的不同尺寸。在每层Pl的后面添加分类及回归子网络,二者都为全卷积网络。分类网络预测每个位置的A个anchor及K个类别的分数值,回归分支预测每个anchor框距离最近实列的偏差值。RetinaNet网络Anchor-based部分分别在Class subnet和Box subnet 包含4个WH256的卷积网络,然后WHKA和WH4A作为输出。
FSAF在卷积层最后分别增加了WHK和WH4卷积层(相对于anchor-based branch减少了A倍的输出,这里的A就是Anchor的数量),作为anchor-free branch的输出;因此anchor-free的计算量非常小。在RetinaNet的输出端,FSAF在每层引入了额外的两层卷积层,分别用于基于anchor-free分支的分类及回归。一个3x3XK的卷积层添加到分类分支的输出,后接sigmoid函数,与基于anchor分支的部分相互平行,其预测目标物在每个位置上K个类别的概率值。相似的,3x3x4的卷积层添加到回归分支的输出,与anchor-based分支的部分相呼应,其后接ReLU函数。其作用是以anchor-free的方式预测框的偏移量。anchor-based与anchor-free共享每层特征以多任务的方式进行运作。
Ground-Truth and Loss
Definitions


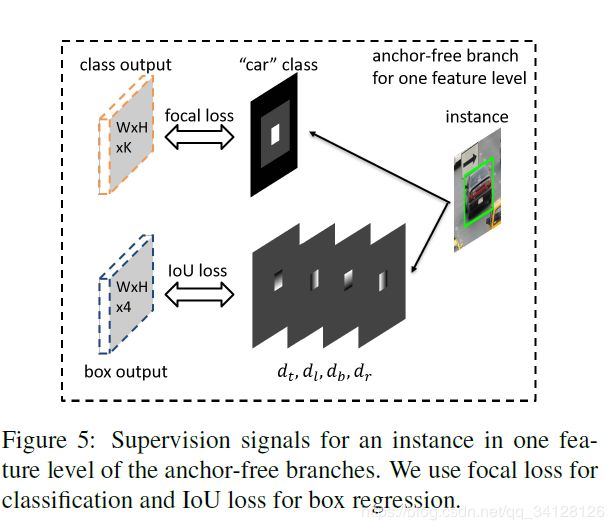
Calassification Output
ground-truth针对分类的输出为K个maps,每个map对应一个类别。实例通过三种方式影响第K个ground truth map,首先,有效区域ble是正样本区域,通过在“car”这个类别的Map对应区域覆盖一个白色区域,代表该实例的存在。而忽略区域(bli-ble),即灰色区域,该区域内的像素在进行网络的反向传播时不参与贡献。最后,ignore 区域的相邻层的区域(bi-1i,bi+1i)特征也是被看作是忽略的,如果同一层中有两个实例发生了重叠,则以小区域的优先级较高。而ground truth map剩下的区域为负样本,用0填充。应用了Focal loss,a=0.25,r=2.0 anchor free分支的总损失是图像中所有非忽略区域的focal loss的和,同时通过有效区域内的像素个数来进行正则化处理。
Box Regression Output
回归输出的ground truth是与类别无关的4个offset maps,实例只作用于offeset maps上的有效区域ble。


而且,因为ground truth box只影响了 ble 区域,所以这里的(i, j)是该区域内的所有像素。可以看出,回归分支的groundtruth offset map中的有效区域尺寸和分类分支中的白色区域相同。回归分支作者采用了IoU损失函数。
Online Feature Selection
在anchor-based算法中,通常是基于目标的尺寸分配到指定的特征层,而FSAF模块是基于目标的内容选择最优特征层。**记目标I分配到第L个特征层的分类损失和定位损失分别如下

那么,最优特征层的定义如下,实例通过特征金字塔的每一层。然后,基于计算所有anchor-free分支的和,最好的层的定义是所有的损失最小,则用该层特征学习实例。
![]()
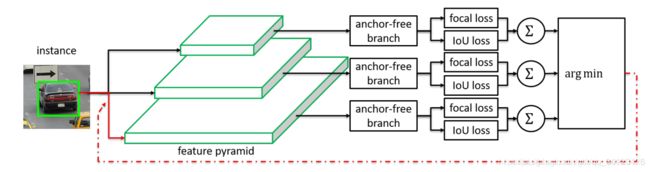
对于每一个“Instance”,FPN的每一层各自计算这一层的loss,从这些loss种选择最小的那个,从而决定对于这个“Instance”应该选择哪一层。这是在训练的时候,其实就是决定某个Instance 用哪个路线去回传,只训练这层FPN The intuition is that the selected feature is currently the best to model the instance. Its loss forms a lower bound in the feature space.
在运行inference 的时候是没有这样的选择机制的,因为“对于每一个instance而言,一定存在一个最合适的层,所以对于每一层,我们都去选,最后一起用阈值过滤以及nms就能够一定程度上得到最好的结果” 也就是只要保证了,最合适的在里面,那么一定能够得到最合适的!!!
测试阶段 anchor-free 以及anchor-based 这两路的结果都会被拿出来,一起最后删选。
为什么称作为Online呢,因为在每一次参数更新的时候,需要将所有的目标分配到最优的特征层。也就是说,每一个特征层的参数,只学习对应的groundtruth目标。
Joint Inference and Training
在训练的时候,只需要综合考虑anchor-based和anchor-free分支的损失,联合优化这两个分支的参数。关于这两部分的损失,作者取了权重系数0.5。
Takeaway
采用Anchor free来实现基于语义信息来选取特征。
