Python之正则表达式
目录
单个字符匹配
多个字符匹配
案例:简单判断变量名是否符合要求
贪婪与非贪婪
单个字符匹配

语法格式:
先import re
re.match(r'正则表达式',需要匹配的表达式) # 这里成功的话会返回一个对象
re.group()
>>> import re
>>> re.match(r'破产姐妹\d','破产姐妹1')
>>> ret = re.match(r'破产姐妹\d','破产姐妹1')
>>> ret.group()
'破产姐妹1'
>>> ret = re.match(r'破产姐妹\d','破产姐妹1111')
>>> ret.group()
'破产姐妹1'
>>> ret = re.match(r'破产姐妹[12345]','破产姐妹1')
>>> ret.group()
'破产姐妹1'
>>> ret = re.match(r'破产姐妹\d','破产姐妹6')
>>> ret.group()
'破产姐妹6'
>>> re.match(r'破产姐妹\d','破产姐妹6')
>>> ret = re.match(r'破产姐妹\d','破产姐妹6')#这边应该报错的,,,但是我不知道为啥没报错???
>>> ret = re.match(r'破产姐妹[1-5]','破产姐妹1')
SyntaxError: unexpected indent
>>> ret = re.match(r'破产姐妹[1-5]','破产姐妹1')
>>> ret.group()
'破产姐妹1'
>>> ret = re.match(r'破产姐妹[1-5]','破产姐妹6')
>>> ret.group() # 这遍也应该报错的。。。
Traceback (most recent call last):
File "", line 1, in
ret.group() # 这遍也应该报错的。。。
AttributeError: 'NoneType' object has no attribute 'group'
>>> ret = re.match(r'破产姐妹[125]','破产姐妹1')
>>> ret.group()
'破产姐妹1'
>>> ret = re.match(r'破产姐妹[125]','破产姐妹4')
>>> ret.group()# 这遍应该报错。。
Traceback (most recent call last):
File "", line 1, in
ret.group()# 这遍应该报错。。
AttributeError: 'NoneType' object has no attribute 'group'
>>> ret = re.match(r'破产姐妹[13-5]','破产姐妹3')
>>> ret.group()
'破产姐妹3'
>>> ret = re.match(r'破产姐妹[13-5]','破产姐妹2')
>>> ret.group()
Traceback (most recent call last):
File "", line 1, in
ret.group()
AttributeError: 'NoneType' object has no attribute 'group'
>>>
>>>
>>>
>>>
>>> ret = re.match(r'破产姐妹[1-5abc]','破产姐妹a')
>>> ret.group()
'破产姐妹a'
>>> re.match(r'破产姐妹[1-5abc]','破产姐妹d').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'破产姐妹[1-5abc]','破产姐妹d').group()
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r'破产姐妹[1-5a-d]','破产姐妹d').group()
'破产姐妹d'
>>> re.match(r'破产姐妹[1-5a-d]','破产姐妹e').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'破产姐妹[1-5a-d]','破产姐妹e').group()
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r'破产姐妹[1-5a-dA-D]','破产姐妹A').group()
'破产姐妹A'
>>>
>>>
>>>
>>>
>>> re.match(r'破产姐妹\w','破产姐妹A').group()
'破产姐妹A'
>>> re.match(r'破产姐妹\w','破产姐妹1').group()
'破产姐妹1'
>>> re.match(r'破产姐妹\w','破产姐妹a').group()
'破产姐妹a'
>>> re.match(r'破产姐妹\w','破产姐妹_').group()
'破产姐妹_'
>>> re.match(r'破产姐妹\w','破产姐妹!').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'破产姐妹\w','破产姐妹!').group()
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r'破产姐妹\w','破产姐妹Abbb').group()
'破产姐妹A'
>>> re.match(r'破产姐妹\w','破产姐妹A').group()# 所以还是单个字符的匹配
'破产姐妹A'
>>> re.match(r'破产姐妹\w','破产姐妹呀').group() # \w是Unicode编码形式,所以包括全球所有的语言
'破产姐妹呀'
>>>
>>>
>>> re.match(r'破产姐妹\s','破产姐妹 ').group()
'破产姐妹 '
>>> re.match(r'破产姐妹\s','破产姐妹\t').group()
'破产姐妹\t' -
多个字符匹配
首先我认为,下面的这些字符都是和单个字符搭配使用的。在单个字符匹配时前面可以加其他字符串。但是多个字符匹配之前就不可以在前面加字符串了。
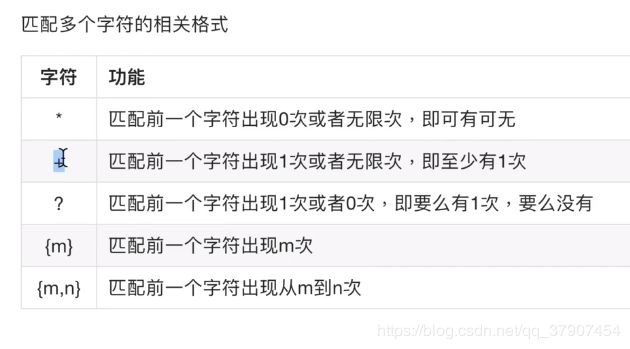
大括号{}:只有一个数字的时候,就一定要满足这个数字,而且也要满足大括号之前的要求,比如这里就是\d,数字0-9.
>>> import re
>>> re.match(r'神探夏洛克\d{1,2}','神探夏洛克1')
>>> re.match(r'神探夏洛克\d{1,2}','神探夏洛克1').group()
'神探夏洛克1'
>>> re.match(r'神探夏洛克\d{1,2}','神探夏洛克11').group()
'神探夏洛克11'
>>> re.match(r'神探夏洛克\d{1,2}','神探夏洛克a').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'神探夏洛克\d{1,2}','神探夏洛克a').group()
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r'神探夏洛克\d{1,3}','神探夏洛克123').group()
'神探夏洛克123'
>>> re.match(r'手机号\d{11}','12345678901').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'手机号\d{11}','12345678901').group()
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r'\d{11}','12345678901').group()
'12345678901'
>>> re.match(r'\d{11}','1234567890').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'\d{11}','1234567890').group()
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r'\d{11}','12345a78901').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'\d{11}','12345a78901').group()
AttributeError: 'NoneType' object has no attribute 'group' 问号?: 前一个字符要么出现一次,要么不出现。
>>> re.match(r'021-\d{8}','021-12345678').group()
'021-12345678'
>>> re.match(r'021-?\d{8}','02112345678').group()
'02112345678'
>>> re.match(r'\d{3}-\d{8}','010-12345678').group()
'010-12345678'
>>> re.match(r'\d{3,4}-\d{7,8}','0372-1234567').group()
'0372-1234567'
>>> re.match(r'\d{3,4}-?\d{7,8}','03721234567').group()
'03721234567'星号*:前一个字符出现0次或者无数(有限)次
点.:之前的任意一个字符但是不包括换行符\n,所以下面的re.S的作用就是可以显示出换行,和点.搭配使用
>>> html_content = '''abc
defg
hijk
lmn
opq'''
>>> print(html_content)
abc
defg
hijk
lmn
opq
>>> re.match(r'.*',html_content).group()
'abc'
>>> re.match(r'.*',html_content,re.S).group()
'abc\ndefg\nhijk\nlmn\nopq'加号+:前面一个字符出现1次或无限(有限)次,和星号相比不可以为空
>>> re.match(r'.*','').group()
''
>>> re.match(r'.+','11').group()
'11'
>>> re.match(r'.+','acs').group()
'acs'
>>> re.match(r'.+','').group()
Traceback (most recent call last):
File "", line 1, in
re.match(r'.+','').group()
AttributeError: 'NoneType' object has no attribute 'group' -
案例:简单判断变量名是否符合要求
Python中的变量名要求开头只能是字母和下划线,变量名中不能含有字母、数字、下划线之外的字符。
首先是第一个版本,但是这个版本中并没有判断出‘age!’,'a#ge',不是合法变量名
输入:
import re
def main():
names = ['age','_age','1age','a_age','age_1_','age!','a#123']
for name in names:
ret = re.match(r'[a-zA-Z_][a-zA-Z0-9_]*',name)
if ret:
print('变量名%s 符合要求...通过正则表达式匹配出来的变量名为:%s' % (name,ret.group()))
else:
print('变量名%s 不符合要求' % name)
if __name__ == '__main__':
main()
输出:
变量名age 符合要求...通过正则表达式匹配出来的变量名为:age
变量名_age 符合要求...通过正则表达式匹配出来的变量名为:_age
变量名1age 不符合要求
变量名a_age 符合要求...通过正则表达式匹配出来的变量名为:a_age
变量名age_1_ 符合要求...通过正则表达式匹配出来的变量名为:age_1_
变量名age! 符合要求...通过正则表达式匹配出来的变量名为:age
变量名a#123 符合要求...通过正则表达式匹配出来的变量名为:a这是因为在match中定义了开头,没有定义结尾。
就像下面的例子,虽然指定了匹配的字符数是3,小于3的会报错,但是多于3的,就会把多于的部分砍掉,相当于正则表达式只是匹配到了三个字符。
>>> re.match(r'\d{3}','12345').group()
'123'
标准的做法是给正则表达式定义上开头和结尾
输入:
import re
def main():
names = ['age','_age','1age','a_age','age_1_','age!','a#123']
for name in names:
ret = re.match(r'^[a-zA-Z_][a-zA-Z0-9_]*$',name)
if ret:
print('变量名%s 符合要求...通过正则表达式匹配出来的变量名为:%s' % (name,ret.group()))
else:
print('变量名%s 不符合要求' % name)
if __name__ == '__main__':
main()
输出:
变量名age 符合要求...通过正则表达式匹配出来的变量名为:age
变量名_age 符合要求...通过正则表达式匹配出来的变量名为:_age
变量名1age 不符合要求
变量名a_age 符合要求...通过正则表达式匹配出来的变量名为:a_age
变量名age_1_ 符合要求...通过正则表达式匹配出来的变量名为:age_1_
变量名age! 不符合要求
变量名a#123 不符合要求贪婪与非贪婪
1.什么是正则表达式的贪婪与非贪婪匹配
如:String str="abcaxc";
Patter p="ab.*c";
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab.*c)。
非贪婪匹配:就是匹配到结果就好,最少的匹配字符。如上面使用模式p匹配字符串str,结果就是匹配到:abc(ab.*?c)。
2、编程中如何区分两种模式
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
下面的都是量词:
{m,n}:m到n个
*:任意多个
+:一个到多个
?:0或一个
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复