Res2Net------论文理解
1. 设计网络的动机
目前现有的特征提取方法大多都是用分层方式表示多尺度特征。分层方式即要么对每一层使用多个尺度的卷积核进行提特征(如SPPNet),要么就是对每一层提取特征进行融合(如FPN)。
本文提出的Res2Net在原有的残差单元结构中又增加了小的残差块,增加了每一层的感受野大小。Res2Net也可以嵌入到不同的特征提取网络中,如ResNet, ResNeXt, DLA等等。
2. Res2Net
2.1 Res2Net网络模型

上图左边是最基本的卷积模块。右图是针对中间的3x3卷积进行的改进。
首先对经过1x1输出后的特征图按通道数均分为s(图中s=4)块,每一部分是xi,i ∈ {1,2,...,s}。
每一个xi都会具有相应的3x3卷积,由Ki()表示。我们用yi表示Ki()的输出。
特征子集xi与Ki-1()的输出相加,然后送入Ki()。为了在增加s的同时减少参数,我们省略了x1的3×3卷积,这样也可以看做是对特征的重复利用。

(*代表卷积操作)
y1 = x1;
y2 = x2*(3x3)= K2;
y3 =(x3 + x2*(3x3))*(3x3) = (K2 + x3)*(3x3)= K3 ;
y4 =(x4 +(x3 + x2*(3x3))*(3x3))*(3x3) = (K3 + x4)*(3x3)= K4
如此一来,我们将得到不同数量以及不同感受野大小的输出。 比如y2得到3x3的感受野,那么y3就得到5x5的感受野,y4同样会得到更大尺寸如7x7的感受野。
最后将这四个输出进行融合并经过一个1x1的卷积。这种先拆分后融合的策略能够使卷积可以更高效的处理特征。
在本文中,我们将s设置为比例尺寸的控制参数,也就是可以将输入通道数平均等分为多个特征通道。s越大表明多尺度能力越强,此外一些额外的计算开销也可以忽略。
2.2 与其他网络做融合
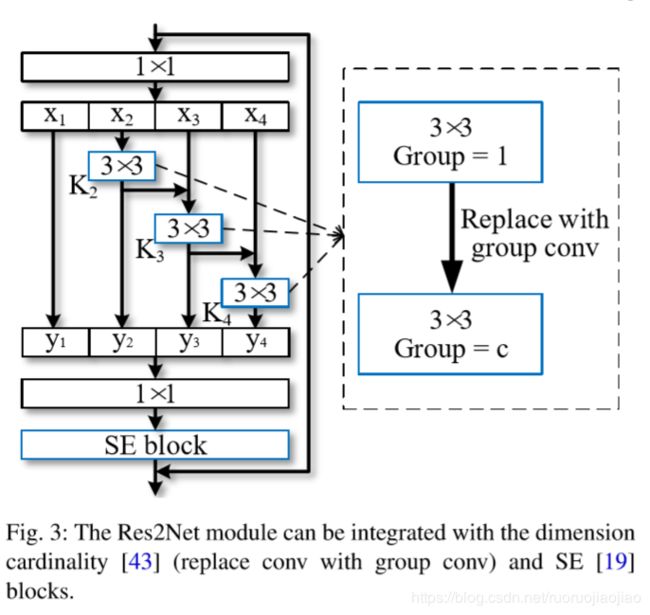
目前已经有大量的神经网络提出并且被应用,比如ResNeXt和SENet。上图中将这两个网络运用到Res2Net中。
首先是ResNeXt中的维度基数(Dimension cardinality),主要是利用分组卷积,将输出的通道维数平均分为c组,分别进行卷积,最后通过concat进行连接,使输入维度和输出维度相同。
(
若输入和输出维度都为256,用3x3的卷积核进行卷积,参数量为3x3x256x256.
但若使用分组卷积,比如将通道数分为8组,每组通道数即为32,则参数量为3x3x32x32x8.远远小于上个参数量。
最初是在AlexNet中用到,为了使用多个GPU进行训练过。Alex认为group conv的方式能够增加 filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
)
本文是对每个块下的3x3卷积进行分组,每一组的通道数变为channel/c。
然后,在最后的1x1卷积后加上SENet,其主要通过建模通道数之间的相互依赖性自适应地校准每个通道的特征响应,即为每一个通道分配权值,该权值代表每个通道的影响力。