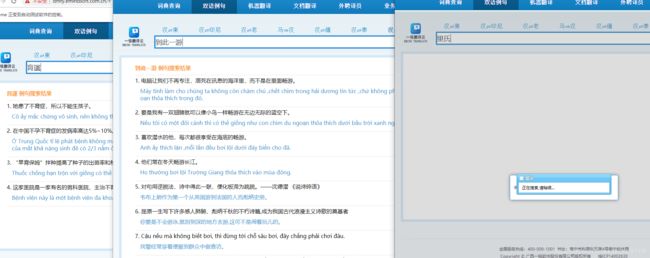
基于selenium的网络语料获取
基于selenium的网络语料获取
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法执行javaScript代码的问题。
优点就是可以帮我们避开一系列复杂的通信流程,例如在我们之前学习的requests模块,那么requests模块在模拟请求的时候是不是需要把素有的通信流程都分析完成后才能通过请求,然后返回响应。假如目标站点有一系列复杂的通信流程,例如的登录时的滑动验证等…那么你使用requests模块的时候是不是就特别麻烦了。不过你也不需要担心,因为网站的反爬策略越高,那么用户的体验效果就越差,所以网站都需要在用户的淫威之下降低安全策略。
本文首先对特定的语料网址编写了基于selenium的网络爬虫实现代码如下:(在此之前你需要下载相应的包和chromedriver.exe驱动)
# encoding=utf-8
from selenium import webdriver
import time
import os
def s(int):
time.sleep(int)
if __name__ == '__main__':
f = open("zh.txt", "r", encoding="utf8")
#查询的文件位置
# fR = open('e:\\text\\a.txt','r',encoding = 'utf-8')
# 模拟浏览器,使用谷歌浏览器,将chromedriver.exe复制到谷歌浏览器的文件夹内
chromedriver = "C:\\Users\\shenzhou\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe"
# 设置浏览器
os.environ["webdriver.chrome.driver"] = chromedriver
chrome_opt = webdriver.ChromeOptions()
browser = webdriver.Chrome(chromedriver)
browser.get(u'http://dmfy.emindsoft.com.cn/')
browser.find_element_by_xpath('//*[@id ="tabexamp"]').click()
browser.switch_to.frame("mainFrame")
s(2)
test=browser.find_element_by_xpath("//*[@id ='searchBar']/tbody/tr/td[2]/font[7]").click()
# browser.execute_script("arguments[0].click();", test)
print(test)
# browser.switch_to.frame("mainFrame")
wen=open("zhvi.txt","a",encoding="utf8")
line=f.readline()
# for word in fR.readlines():
while line:
word = line.lstrip("").rstrip("")
print(len(word))
browser.find_element_by_xpath("//*[@id='keyword']").clear()
browser.find_element_by_xpath("//*[@id='keyword']").send_keys(word)
test=browser.find_element_by_xpath('//*[@id ="btnSearch"]')
browser.execute_script("arguments[0].click();", test)
s(2)
try:
neirongs = browser.find_element_by_xpath('//*[@id="container"]').text
neirongs=neirongs.split("\n")
for k, line in enumerate(neirongs):
if k==0:
continue
wen.write(line+"\n")
wen.flush()
except:
s(2)
continue
finally:
line=f.readline()
# break
f.close()
wen.close()
然后发现速度太慢了。。。。
然后基于此实现了生产者消费者模型。
```javascript
import threading;
import queue;
queue = queue.Queue();
from selenium import webdriver
import time
import os
def s(int):
time.sleep(int)
def isConnected():
import requests
try:
requests.get("http://www.baidu.com",timeout=2)
except:
return False
return True
import linecache
mutex = threading.Lock()
# lock=threading.Lock() #申请一把锁
filename = "zh.txt"
total_line = len(open(filename, 'r', encoding="utf8").readlines())
line_num = 29489
#生产者线程 当队列中产品数量小于100时就每隔1秒向队列放5个产品
class producer(threading.Thread):
def run(self):
global queue;
global line_num
global total_line
while line_num < total_line:
if queue.qsize() < 150:
line = linecache.getline(filename, line_num)
word = line.strip()
queue.put(word)
line_num += 1
# print(line_num,word)
else:
print(line_num)
s(3)
#消费者线程 当队列中产品数量大于50时就每隔1秒从队列中消费20个产品
class consumer(threading.Thread):
def run(self):
global queue;
chromedriver = "C:\\Users\\shenzhou\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe"
# 设置浏览器
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
browser.get(u'http://dmfy.emindsoft.com.cn/')
browser.find_element_by_xpath('//*[@id ="tabexamp"]').click()
browser.switch_to.frame("mainFrame")
s(1)
browser.find_element_by_xpath("//*[@id ='searchBar']/tbody/tr/td[2]/font[7]").click()
# if line_num%100000==0:
# mu="xin"+str(line_num)+".txt"
# wen=open(mu,"a",encoding="utf8")
while line_num < total_line:
if queue.qsize() >60 and isConnected:
# lock.acquire()
for i in range(30):
word=queue.get()
# print('消费者线程{0}消费中。。。{1}'.format(self.name,word));
# print('消费者线程{0}消费中。。。{1}'.format(self.name, word));
browser.find_element_by_xpath("//*[@id='keyword']").clear()
browser.find_element_by_xpath("//*[@id='keyword']").send_keys(word)
test = browser.find_element_by_xpath('//*[@id ="btnSearch"]')
browser.execute_script("arguments[0].click();", test)
try:
neirongs = browser.find_element_by_xpath('//*[@id="container"]').text
if len(neirongs)==0:
continue
neirongs = neirongs.split("\n")[1::]
print(word, len(neirongs), line_num)
lin="\n".join(neirongs)
wen = open("./yuliao/xin000001.txt", "a", encoding="utf8")
wen.write(lin)
wen.flush()
except:
s(1)
wen.close()
continue
# lock.release()
else:
print('消费者线程{0}等待中。。。'.format(self.name));
s(3);
# wen.close()
#启动生产者线程
p1 = producer();
p1.start();
p2 = producer();
p2.start();
#启动消费者线程
c1 = consumer();
c1.start();
c2 = consumer();
c2.start();
# #
c3 = consumer();
c3.start();
# wen.close()
然后又发现一个问题。写文件写不进去了,多个线程同时对文件这个资源进行占有。。死锁。然后对齐进行了加锁操作。
import threading;
import queue;
queue = queue.Queue();
from selenium import webdriver
import time
import os
def s(int):
time.sleep(int)
def isConnected():
import requests
try:
requests.get("http://www.baidu.com",timeout=2)
except:
return False
return True
import linecache
mutex = threading.Lock()
# lock=threading.Lock() #申请一把锁
filename = "zh.txt"
total_line = len(open(filename, 'r', encoding="utf8").readlines())
line_num = 29489
#生产者线程 当队列中产品数量小于100时就每隔1秒向队列放5个产品
class producer(threading.Thread):
def run(self):
global queue;
global line_num
global total_line
while line_num < total_line:
if queue.qsize() < 150:
line = linecache.getline(filename, line_num)
word = line.strip()
queue.put(word)
line_num += 1
# print(line_num,word)
else:
print(line_num)
s(3)
#消费者线程 当队列中产品数量大于50时就每隔1秒从队列中消费20个产品
class consumer(threading.Thread):
def run(self):
global queue;
chromedriver = "C:\\Users\\shenzhou\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe"
# 设置浏览器
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
browser.get(u'http://dmfy.emindsoft.com.cn/')
browser.find_element_by_xpath('//*[@id ="tabexamp"]').click()
browser.switch_to.frame("mainFrame")
s(1)
browser.find_element_by_xpath("//*[@id ='searchBar']/tbody/tr/td[2]/font[7]").click()
# if line_num%100000==0:
# mu="xin"+str(line_num)+".txt"
# wen=open(mu,"a",encoding="utf8")
while line_num < total_line:
if queue.qsize() >60 and isConnected:
# lock.acquire()
for i in range(30):
word=queue.get()
# print('消费者线程{0}消费中。。。{1}'.format(self.name,word));
# print('消费者线程{0}消费中。。。{1}'.format(self.name, word));
browser.find_element_by_xpath("//*[@id='keyword']").clear()
browser.find_element_by_xpath("//*[@id='keyword']").send_keys(word)
test = browser.find_element_by_xpath('//*[@id ="btnSearch"]')
browser.execute_script("arguments[0].click();", test)
try:
neirongs = browser.find_element_by_xpath('//*[@id="container"]').text
if len(neirongs)==0:
continue
neirongs = neirongs.split("\n")[1::]
print(word, len(neirongs), line_num)
lin="\n".join(neirongs)
mutex.acquire(3)
wen = open("./yuliao/xin000001.txt", "a", encoding="utf8")
wen.write(lin)
wen.flush()
mutex.release()
except:
s(1)
wen.close()
continue
# lock.release()
else:
print('消费者线程{0}等待中。。。'.format(self.name));
s(3);
# wen.close()
#启动生产者线程
p1 = producer();
p1.start();
p2 = producer();
p2.start();
#启动消费者线程
c1 = consumer();
c1.start();
c2 = consumer();
c2.start();
# #
c3 = consumer();
c3.start();
# wen.close()
涉及到的词典如下:
爬取语料格式如下:

爬取界面显示: