【李宏毅机器学习笔记】 23、循环神经网络(Recurrent Neural Network,RNN)
【李宏毅机器学习笔记】1、回归问题(Regression)
【李宏毅机器学习笔记】2、error产生自哪里?
【李宏毅机器学习笔记】3、gradient descent
【李宏毅机器学习笔记】4、Classification
【李宏毅机器学习笔记】5、Logistic Regression
【李宏毅机器学习笔记】6、简短介绍Deep Learning
【李宏毅机器学习笔记】7、反向传播(Backpropagation)
【李宏毅机器学习笔记】8、Tips for Training DNN
【李宏毅机器学习笔记】9、Convolutional Neural Network(CNN)
【李宏毅机器学习笔记】10、Why deep?(待填坑)
【李宏毅机器学习笔记】11、 Semi-supervised
【李宏毅机器学习笔记】 12、Unsupervised Learning - Linear Methods
【李宏毅机器学习笔记】 13、Unsupervised Learning - Word Embedding(待填坑)
【李宏毅机器学习笔记】 14、Unsupervised Learning - Neighbor Embedding(待填坑)
【李宏毅机器学习笔记】 15、Unsupervised Learning - Auto-encoder(待填坑)
【李宏毅机器学习笔记】 16、Unsupervised Learning - Deep Generative Model(待填坑)
【李宏毅机器学习笔记】 17、迁移学习(Transfer Learning)
【李宏毅机器学习笔记】 18、支持向量机(Support Vector Machine,SVM)
【李宏毅机器学习笔记】 19、Structured Learning - Introduction(待填坑)
【李宏毅机器学习笔记】 20、Structured Learning - Linear Model(待填坑)
【李宏毅机器学习笔记】 21、Structured Learning - Structured SVM(待填坑)
【李宏毅机器学习笔记】 22、Structured Learning - Sequence Labeling(待填坑)
【李宏毅机器学习笔记】 23、循环神经网络(Recurrent Neural Network,RNN)
【李宏毅机器学习笔记】 24、集成学习(Ensemble)
------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av10590361?p=36
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
-------------------------------------------------------------------------------------------------------
Example Application

先以一个智能机器人的例子开始。
理解一段文字的一种方法是标记那些对句子有意义的单词或记号。在自然语言处理领域,这个问题被称为槽填充(Slot Filling)。
所以此时机器人要找出input句子的有用的信息(destination,time of arrival),然后输出要回答的答案。

这件事情可以先尝试用一个普通的network做一下,看看会遇到什么问题。
把词语转成vector作为input,其它步骤和普通的network一样。
但,怎么把词语转成vector呢?如下。
1-of-N encoding

这个方法很简单,将物品在对应的列上置1 。
缺点:如果出现lexicon没有记录的物品,没办法在所属的列上置1 。
所以,可以用以下方法改进。
Beyond 1-of-N encoding

- Dimension for “Other” : 把没记录过的物品归到 other 类里。
- Word hashing : 用词汇的字母的n-gram来表示这个vector 。
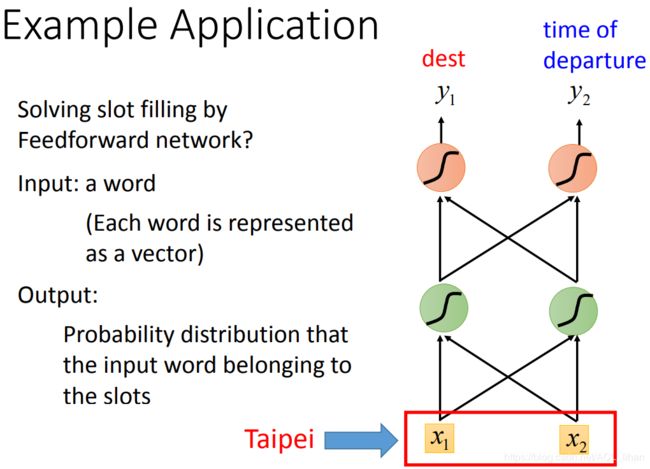
刚才讲了几种把word转成vector的方法,现在能进行输入以后,就能获得输出。
这个输出是一个分布,这个分布是输入的词汇(比如Taipei)属于哪个slot(destination,time of arrival)的几率。
这样做看起来好像很合理,但其实是有问题的,如下。
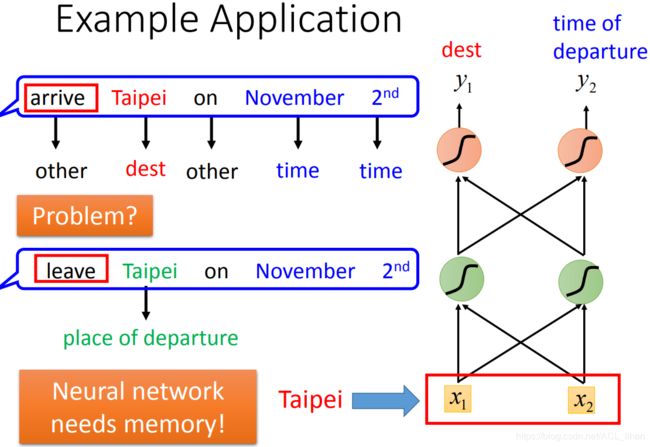
如果network的input是一样的,那output应该也是一样的,但现在面临个问题:
现在有两个句子:
- 11月2号到达台北(台北是目的地)
- 11月2号离开台北(台北是出发地)
对于刚才的network来说,input只有台北,它要么就一直认定台北是目的地,要么就一直认定台北市出发地。
所以,我们就希望这个network是有记忆力的,能记住联系台北之前的词汇,来判断台北市目的地还是出发地。
这种有记忆力的network就是循环神经网络(Recurrent Neural Network,RNN)。
Recurrent Neural Network (RNN)
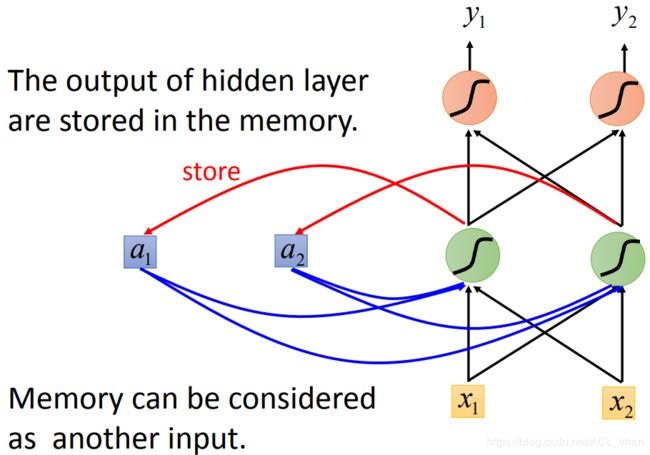
- 输入 x1,x2后,神经元的输出结果会存储到内存中
- 此时再输入 x1, x2 ,神经元不仅会此时的x1 ,x2,还会考虑之前 x1,x2的结果,综合后才得到输出。
下面以一个例子来看下。

为了计算方便,假设weight都是1,没有bias,激活函数也是线性函数。
- 先给memory那边初始值,假设都设置为0
- 现在输入[1,1]
- 绿色的神经元输出[2,2],并把[2,2]存到memory中
- 红色的神经元输出[4,4]

- 此时输入[1,1]
- 绿色的神经元会加上memory的值[2,2],输出[6,6],并把[6,6]存到memory中
- 红色的神经元输出[12,12]
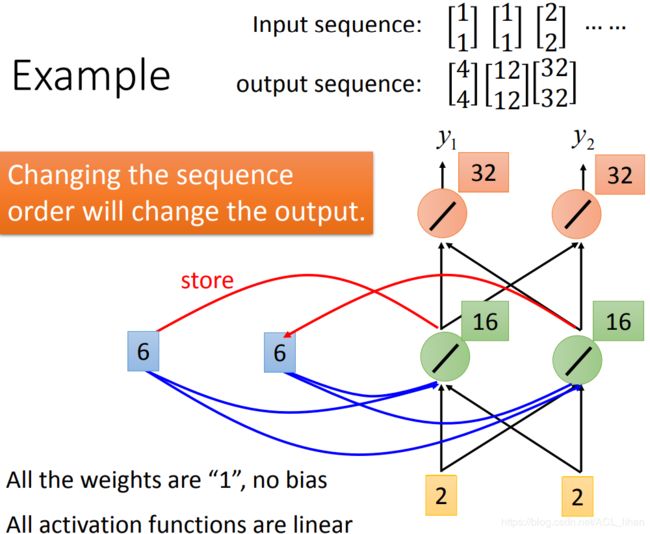
- 此时输入[2,2]
- 绿色的神经元会加上memory的值[6,6],输出[16,16,],并把[16,16]存到memory中
- 红色的神经元输出[32,32]
另外,在RNN中,input的顺序对结果是有影响的。如果第一次就输入[2,2],最后的结果是不一样的。
下面回到刚才的例子。
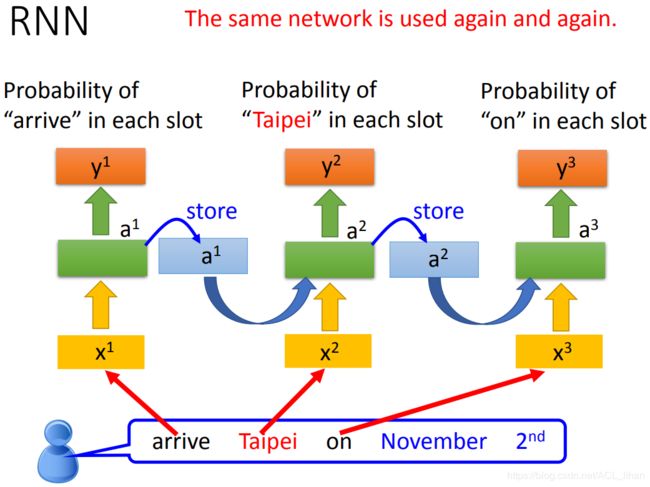
把network改为RNN。
- 输入Taipei
- 网络就会考虑上前面的词语是arrive还是leave。
- 此时就能输出Taipei是目的地还是出发地的几率。
上图不是指有三个network,而是一个network被用了3次。
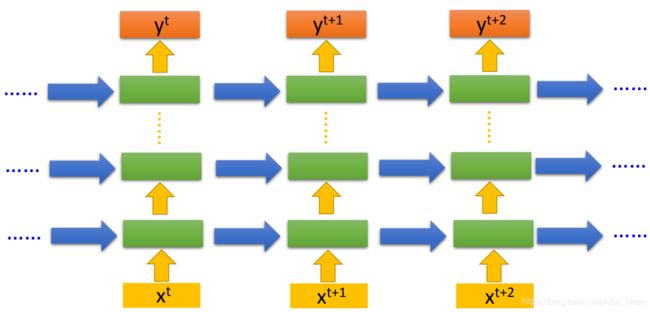
之前举的RNN的例子,都只有一层hidden layer。但其实你也可以如上图一样,DIY你的network,要加几层随便你。
Elman Network & Jordan Network

- Elman Network:(就是刚才举例的RNN)把某一个hidden layer的output存起来,在下一次使用network的时候,这个hidden layer会考虑现在的input和之前存的值,综合后再得出output。
- Jordan Network:它是把output的值存起来,下次用到再读出来。传说它的性能会好点,因为它存的是output的值,这个值和target比较有关系,所以此时我们知道存在memory的值大概会是怎样的。
Bidirectional RNN

假设一个句子的词语从前往后是![]() 、
、![]() 、
、![]() 。
。
Bidirectional RNN的做法:训练两个network,一个正向,一个逆向。把![]() 所处的两个hidden layer都接给output layer
所处的两个hidden layer都接给output layer![]() 。
。
Bidirectional RNN的好处:network产生output的时候,它考虑的范围比较广。比如输入句子中间的词语进去,之前RNN只考虑了这个词语前面句子的部分。而Bidirectional RNN是考虑了句子前面和句子后面的部分,所以它的准确率会更高。
前面讲的各种RNN是比较simple的,现在的话有些更好的结构,比如Long Short-term Memory (LSTM)。下面具体看下。
Long Short-term Memory (LSTM)
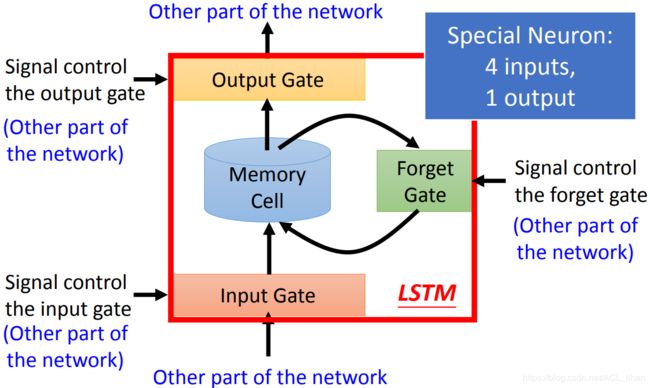
- Memory Cell:保存神经元的output
- Input Gate:决定神经元的output要不要被保存到Memory Cell(由network自己学习并决定是否打开阀门)
- Output Gate:决定神经元能不能从Memory Cell读取之前保存的东西(由network自己学习并决定是否打开阀门)
- Forget Gate:决定Memory Cell里面的东西要不要删掉(由network自己学习并自己决定是否Forget)
这里有4个input和1个output:
- input的值
- 操控Input Gate的信号
- 操控Output Gate的信号
- 操控Forget Gate的信号
- 一个output是LSTM的输出值
接下来看看LSTM在具体公式中如何体现。
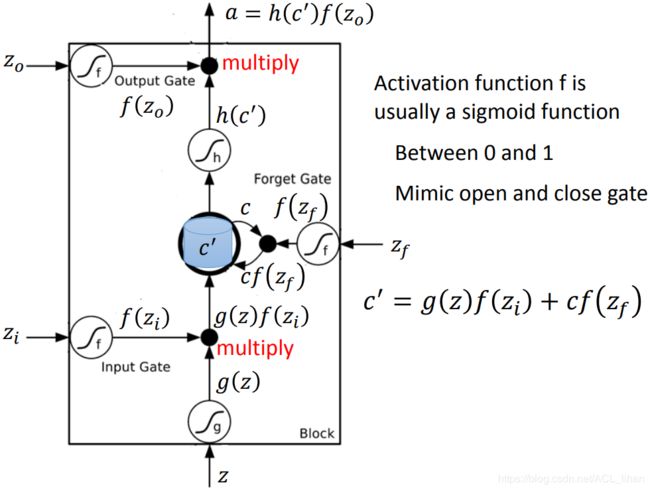
![]() 、
、![]() 、
、![]() 经过的激活函数均为Sigmoid Function。代表这个gate开启的程度。
经过的激活函数均为Sigmoid Function。代表这个gate开启的程度。
- 输入是 z,经过激活函数后变成 g(z) 。
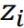 代表 是否开启 Input Gate 的信号,经过激活函数后变成
代表 是否开启 Input Gate 的信号,经过激活函数后变成 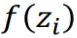 。数值为1代表完全让数据输入。
。数值为1代表完全让数据输入。 代表 是否开启 Output Gate 的信号,经过激活函数后变成
代表 是否开启 Output Gate 的信号,经过激活函数后变成  。数值为1代表完全让数据输出。
。数值为1代表完全让数据输出。 代表 是否开启 Forget Gate 的信号,经过激活函数后变成
代表 是否开启 Forget Gate 的信号,经过激活函数后变成  。数值为0代表完全忘掉数据。
。数值为0代表完全忘掉数据。
假设memory初始值是 c ,![]() 这个式子可以看出这几个信号如何操控gate:
这个式子可以看出这几个信号如何操控gate:
- 如果为1,代表输入值 g(z) 能输入进memory。
- 如果为1,代表保留memory原来的值 c ,并和输入的 g(z) 加起来,综合得到memory里新的值 c' 。

- 蓝色格子代表memory里的值。
 代表input
代表input- 当
 时代表,input能被写进memory
时代表,input能被写进memory - 当
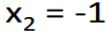 时代表,清空memory
时代表,清空memory - 当
 时代表,memory的值能被输出
时代表,memory的值能被输出 - 红色格子代表输出的值。
知道这些规则,就可以知道上图的LSTM的运行的大概过程。其中的每一个更具体的过程如下:

以[3,1,0]为输入。
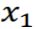 代表input值。input值为3,乘上weight值1,所以实际的input值为1 。
代表input值。input值为3,乘上weight值1,所以实际的input值为1 。- 接下来看Input Gate那边,
 对应的weight是100。如果的值为1,此时bias为-10,此时通过sigmoid后,Input Gate就会打开;如果的值为0,此时bias为-10,通过sigmoid后,Input Gate就会关闭。
对应的weight是100。如果的值为1,此时bias为-10,此时通过sigmoid后,Input Gate就会打开;如果的值为0,此时bias为-10,通过sigmoid后,Input Gate就会关闭。 - 接下来看Forget Gate那边,对应的weight是100。如果的值为-1,此时bias为10,此时通过sigmoid后,Forget Gate就会关闭(即清空memory);如果的值为0,此时bias为10,通过sigmoid后,Forget Gate就会打开(即保留memory)。
- 接下来看Output Gate那边,
 对应的weight是100。如果的值为1,此时bias为-10,此时通过sigmoid后,Output Gate就会打开;如果的值为0,此时bias为-10,通过sigmoid后,Output Gate就会关闭。
对应的weight是100。如果的值为1,此时bias为-10,此时通过sigmoid后,Output Gate就会打开;如果的值为0,此时bias为-10,通过sigmoid后,Output Gate就会关闭。
普通的network和LSTM的对比
- 左边就是普通的network,有两个神经元,每个神经元有两个input。
- 右边则是2个LSTM的单元。
其实它们是差不多的,整个LSTM可以看做一个神经元,只是它的需要的input是左边神经元的4倍。
所以,在同样神经元的状况下,使用LSTM的参数会是原来的4倍。
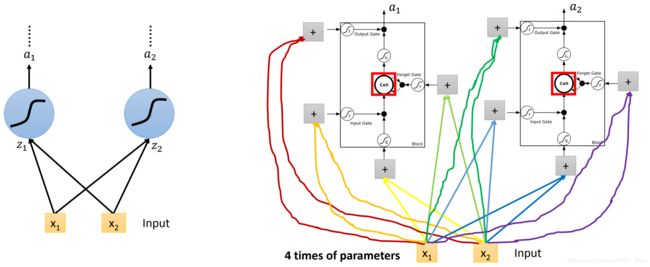
LSTM的过程也可以写成以下这样:
如上图,把LSTM排成一排,c 这个vector就是指这一整排LSTM的memory cell 的值,每个memory cell 里的值代表 c 的一个维度。
- 在时间点 t 输入一个

- 分别乘上4个matrix,把转换成四个vector,分别是
 (操控forget gate的)、
(操控forget gate的)、 (操控input gate的)、
(操控input gate的)、 (LSTM的input)、
(LSTM的input)、 (操控output gate的)。其中,z的第一维就是第一个LSTM的输入,第二维就是第二个LSTM的输入。、、 同理。
(操控output gate的)。其中,z的第一维就是第一个LSTM的输入,第二维就是第二个LSTM的输入。、、 同理。

此时,一个LSTM的运算过程就可以用上图左边的样子来描述。
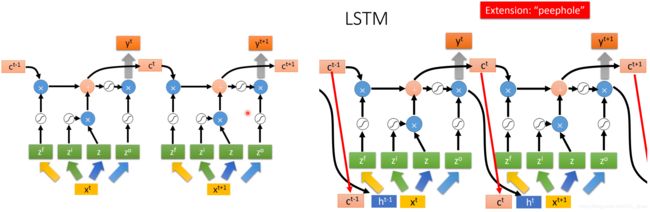
进一步,把多个LSTM连起来,就形成上图左边的样子。
但这还只是一个简化版的LSTM 。
LSTM的最终形态如上图右边的样子。它在input ![]() 的时候,会考虑之前的memory cell的值
的时候,会考虑之前的memory cell的值![]() (peephole),还会考虑之前的output的值
(peephole),还会考虑之前的output的值![]() ,考虑这三个vector,再做transform去操控LSTM 。
,考虑这三个vector,再做transform去操控LSTM 。

所以,叠多几个LSTM之后,整个network就变得很吓人。
不过不用慌,Keras已经帮我们搞定这些东西了 ,到时敲上图几个命令就完事了。
训练
经过上面的介绍,已经知道RNN的大概样子了,接下来就要看下它是如何训练的。
想要训练模型就要:
- 定一个loss function
- 更新参数使loss function最低。
先看第一点。
Learning Target

在这里,:
- 如果输入Taipei(Taipei是属于destination这个slot)。(这边输入的顺序和句子的顺序是一样的)
- 输入后,得到network的输出。这个输出是一个vector,这个vector的长度和slot的数目是一样的。如果network觉得Taipei是属于dest这个slot,则在dest这一维就会为1。
- 得到output后,再和target算cross entropy 。
这样就得到一个loss function。
接下来要更新参数,使loss最小化。
Learning
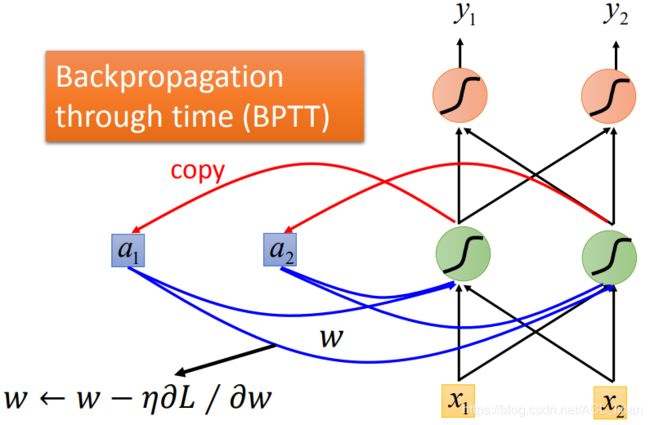
这边还是使用gradient descent来更新参数。
之前为了让gradient descent更有效率的进行,有使用了反向传播(Backpropagation) 。
不过这里需要考虑一个句子的顺序,所以需要改用Backpropagation的进阶版,Backpropagation through time (BPTT)。
RNN不好train

虽然上面有了loss function,也有了做gradient的方法。但是RNN没那么容易train。
上图绿线就是实际train RNN的loss值,可以看到很不稳定。
这是因为RNN 的error surface是很崎岖的,如下。
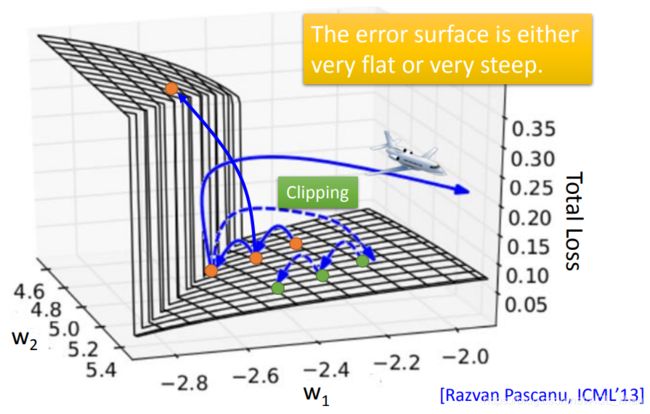
如上图,可以看到,RNN 的error surface是很崎岖的。
在平坦的surface上,由于gradient比较小,所以用比较大的learning rate。但是一旦突然遇到一个悬崖,此时gradient突然变大,而learning rate还没来得及变小,此时参数就会直接跑飞了。就像前面图的绿线,最后直接往上顶上去了。
为什么RNN 的error surface会这么崎岖?

以上图的network为例子。上面一排network是代表不同时间点使用的,不是指有这么多个network。
这个network很简单。
- 只有一个神经元。这个神经元的output也会作为下一次神经元的input,加上下一时间点的input,一起被输入到下一时间点的神经元中。
- 所有weight都是1 。
现在input是[1,……,0],除了第一个是1,其他都是0 。
那么时间点为1000的output就是![]() 。
。
在这整个过程中,神经元的那个weight被使用了999次。所以,w的变化有两种影响:
- 要么就是1变成1.01,造成gradient的巨大变化
- 要么就是0.99变成0,但是gradient约等于没变化
由于这里有两种变化情况,所以不能很死板地说,用大的learning rate或者小的learning rate就是好的。
所以RNN不好train的原因是:它有时间顺序,同样的weight在不同的时间点会被反复使用多次。
解决方法
LSTM

使用LSTM可以解决gradient vanishing的问题(即error surface平坦那部分的问题),原因:
- 原始的RNN中,后一个时间点输入到memory cell的值会直接覆盖前一个时间点memory cell的值,这相当于把前一时间点的w对memory cell的影响给消除掉了,所以会容易产生gradient vanishing的问题。
- 而LSTM中,如果forget gate打开(即保留memory cell的值),memory cell值会是上一个时间点的memory cell的值加上现在 input的值。所以原来的 w 对 memory cell 造成的影响还保留着,没有被直接消除掉。所以训练的时候,可以给一个bias,使得forget gate在大多数时候都被开启。
另外,如果使用LSTM发生过拟合(由于LSTM有3个gate,参数比较多)。可以改用一个比LSTM简单的版本 ,Gated Recurrent Unit (GRU),它只有2个gate(它把input gate和forget gate联动起来):
- 当input gate被打开,forget gate就会被自动关闭(即清除原来memory cell的值)。
Other

上图是更多改进RNN的方法。也是能解决gradient vanishing的问题。具体可以看上图所示的论文了解。
More Applications
因为本文主要讲的是RNN原理相关的内容。而下面的内容偏向于RNN的应用,所以下面的内容都是粗略讲而已。
Many to one

RNN也可以做到,输入是vector sequence,而输出只有一个vector。如上图,是一个情感分析的例子。
输入一个句子到RNN中,最后输出这个句子包含的情感。
Many to Many (Output is shorter)
语音辨识

输入是一个sequence(比较长),输出也是一个sequence(比较短)。以语音辨识为例子:
- 输入是一连串语音,每一小段时间的语音就是一个vector(图中的蓝色柱子)。
- 每一小段语音的vector通过RNN后会得到各自的意思,即“好好好棒棒棒棒棒”。
- 使用Trimming操作去除掉重复的东西,最后输出这段语音的意思,即“好棒”。
但是这样做还是有问题,如果经过Trimming操作会去除重复的东西,那如果实际结果是“好棒棒”的话,就会出错。要知道“好棒”和“好棒棒”(yygq)是完全相反的两种意思。
怎么办呢?用Connectionist Temporal Classification (CTC)。
Connectionist Temporal Classification (CTC)

这里简单看下过程 。
这个方法会输出一个 ![]() 代表 “null” 的意思。
代表 “null” 的意思。
如上图,如果input一串语音,它的output是{ 好,![]() ,
,![]() ,棒,
,棒,![]() ,
,![]() ,
,![]() ,
,![]() },把其中的
},把其中的 ![]() 拿掉就变成“好棒”。
拿掉就变成“好棒”。
如上图,如果input一串语音,它的output是{ 好,![]() ,
,![]() ,棒,
,棒,![]() ,棒,
,棒,![]() ,
,![]() },把其中的
},把其中的 ![]() 拿掉就变成“好棒棒”。
拿掉就变成“好棒棒”。
因为老师这块没细讲,本人水平有限,不想说错误导人,所以更多具体过程建议参考论文。
Sequence to sequence learning
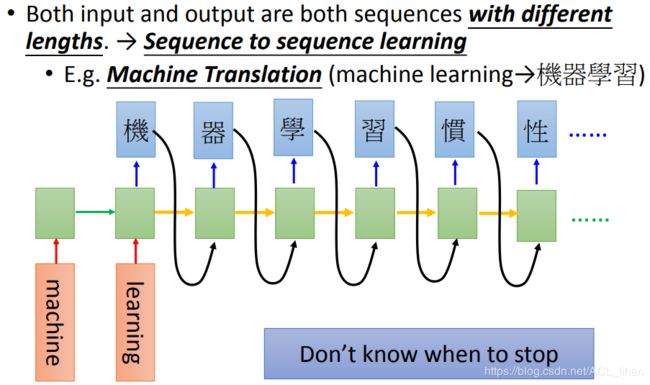
现在的情况是:输入的sequence和输出的sequence的长短不确定。
上图是做翻译的例子。输入machine learning,输出机器学习。
但是有一个问题,输出正确结果后它不会停下来。怎么做呢?

给它加一个“===”的符号,代表任务结束。

上图是Google的一片论文,它实现了输入声音讯号(比如英语),不经过语音辨识,然后直接输出翻译后的句子(比如翻译成中文)。具体看图中的论文地址。
Beyond Sequence
Syntactic parsing
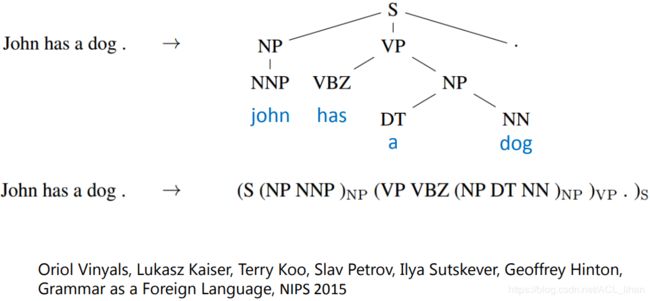
Sequence-to-Sequence的技术还可以用于生成 Syntactic parsing tree 。
它可以做到让机器看一段句子,然后机器就会输出这个句子的语法的结构树。
具体可以看上图中的论文。
Sequence-to-sequence Auto-encoder - Text

使用bag-of-word方法把一段文字转成word vector的话,是没有考虑顺序的。
上图两个单词相同但不同意思句子,在bag-of-word看来就是一样的。
Sequence-to-sequence Auto-encoder - Text就能在考虑顺序的情况下,把一段文字转成word vector。
接下去挺多在NLP的应用,而我对NLP了解不多,视频里也没细讲。所以为了防止误导人,下面内容建议直接看视频吧,等以后我把NLP熟悉一下,再回来填坑。。。