【翻译】Deep Learning-Based Video Coding: A Review and A Case Study
【翻译】Deep Learning-Based Video Coding: A Review and A Case Study
【下载】
论文发布地址:https://arxiv.org/abs/1904.12462
PDF下载地址:https://arxiv.org/pdf/1904.12462.pdf
DLVC源码地址:https://github.com/fvc2018/dlvc
【翻译】
\quad 在过去的十年里,深度学习技术在许多领域,尤其是在计算机视觉和图像处理领域,取得了巨大的成功。然而,基于深度学习的视频编码技术仍处于起步阶段。本文回顾了自2015年以来,图像/视频编码领域中应用深度学习的代表性研究成果。我们将相关工作分为两类:一类是基于深度网络(深度方案)构建的新编码方案,另一类是和传统编码方案或传统编码工具一起使用的基于深度网络的编码工具(深度工具)。对于深度编码方案,像素概率建模和自动编码器两种方法,分别可以看作预测编码方案和变换编码方案。对于深度工具,已经提出了几种使用深度学习的技术来执行帧内预测、帧间预测、跨通道预测、概率分布预测、变换、后循环或环内滤波、下采样和上采样以及编码优化。根据最新的报道,深度编码方案在图像编码方面的压缩效率已经达到了与目前最先进的传统方案,如用于图像编码的高效视频编码方案(HEVC),相当甚至更高的水平。然而,深度编码方案还没有达到目前HEVC视频编码的高度,深度工具在压缩效率与编码/解码复杂度之间的权衡、感知自然度或语义质量的优化、特性与通用性、多个深度工具的联合设计等诸多方面还有待探索。为了推动基于深度学习的视频编码的研究,本文以我们开发的原型视频编解码器,即深度学习视频编码(DLVC)为例进行了研究。DLVC中有两个基于卷积神经网络(CNN)的深度工具:基于CNN的环路滤波器(CNN-ILF)和基于CNN的块自适应分辨率编码。这两种工具都有助于显著提高压缩效率。使用这两种深度编码工具和其他非深度编码工具,在随机访问和低延迟配置下,DLVC比HEVC平均节省39.6%和33.0%的比特。DLVC的源代码已经发布,以供进一步研究。
A. 图像、视频编码
\quad 图像/视频编码通常是指将图像/视频压缩成二进制码(即比特位)以方便存储和传输的计算技术。压缩技术根据是否能保证图像/视频从比特位的完美重建,被分为无损编码和有损编码。对于自然图像/视频,无损编码的压缩效率通常低于要求,因此大部分工作都致力于有损编码。有损图像/视频编码解决方案从两个方面评估:第一是压缩效率,通常以比特数(编码速率)来衡量,越少越好。第二是产生的损失,通常用重构图像/视频与原始图像/视频相比的质量来衡量,质量越高越好。
\quad 图像/视频编码是计算机图像处理、计算机视觉和视觉通信的基础和实现技术。图像/视频编码的研究和发展最早可以追溯到20世纪60年代,远远早于现代成像、图像处理和视觉通信系统的出现。例如,图像编码研讨会,一个专门讨论图像/视频编码发展的著名国际论坛,始于1969年。从那时起,学术界和工业界都在这一领域做出了众多努力。
\quad 由于互操作性的要求,在过去的三十年中,已经制定了一系列关于图像/视频编码的标准。在国际标准化组织中,ISO/IEC有两个专家组,即为图像/视频编码技术标准化的联合照片专家组(JPEG)和移动图像专家组(MPEG),而ITU-T有自己的视频编码专家组(VCEG)。这些组织已经发布了几个著名的、被广泛采用的标准,如JPEG[121]、JPEG 2000[103]、H.262 (MPEG-2 Part 2)[115]、H.264 (MPEG-4 Part 10 or AVC) [128]、 H.265 (MPEG-H Part 2 or HEVC)[108]等。
\quad 随着视频技术的进步,特别是超高清视频的普及,迫切需要进一步提高压缩效率,在有限的存储空间和有限的传输带宽下适应超高清视频。因此,在HEVC之后,MPEG和VCEG组成了联合视频专家团队(JVET)探索先进的视频编码技术,该团队开发了用于研究的联合勘探模型(JEM)。此外,自2018年以来,JVET团队一直致力于一种新的视频编码标准作为HEVC的继承者,即通用视频编码(VVC)。预计VVC可以在保持相同质量的同时,节省约50%的比特,从而提高压缩效率,尤其是和HEVC在超高清视频方面相比。尽管如此,值得注意的是,VVC的改进很可能是以乘性编码/解码复杂度为代价的。
B.应用深度学习的图像、视频编码
\quad 过去的十年见证了深度学习的出现和蓬勃发展,人们越来越多地采用这类技术,以期达到人工智能的最终目标[59]。深度学习属于机器学习技术,其计算模型有其特殊性,称为深度人工神经网络或简称深度网络,深度网络由多个(通常超过三个)处理层组成,每一层又由多个简单但非线性的基本计算单元组成。人们认为这种深度网络的优势之一是能够处理多层抽象的数据,并将数据转换成不同的表示形式。注意,这些表示不是人工设计的;相反,包括处理层在内的深层网络是使用一般的机器学习过程从大量数据中学习的。深度学习消除了手工表示法的必要性,因此被认为对处理原生非结构化数据(如声音和视觉信号)特别有用,而处理此类数据一直是人工智能领域的一个长期难题。
\quad 在图像/视频处理领域,使用卷积神经网络(CNN)的深度学习彻底改变了计算机视觉和图像处理的模式。2012年,Krizhevsky等人[57]设计了一个8层CNN,与之前的方法相比,改方法以极低的错误率赢得了图像分类的挑战。2014年,Girshick等人[33]提出的CNN特征区域显著提高了目标检测的性能。同样在2014年,Dong等人提出了一种针对单图像超分辨率(SR)的3层CNN,该方法在重建质量和计算速度上都优于之前的方法。2017年,Zhang等人[142]提出了一种深度CNN的图像去噪方法,并证明了一个CNN模型可以处理多个不同的图像恢复任务,包括去噪、单图像超分辨率和压缩伪影的减少,而长期以来,这些任务都是被单独研究的。
\quad 看到这些成功的案例,专家们不禁要问,深度学习是否对图像/视频编码也有帮助。历史上,人工神经网络在图像/视频编码领域并不陌生。从20世纪80年代至90年代,人们就对基于神经网络的图像编码[28]、[48]进行了大量的研究,但当时的网络较浅,压缩效率不高。得益于丰富的数据,越来越强大的计算平台和先进算法的发展,我们现在训练能非常深网络,甚至可以超过1000层[40]。因此,我们可以重新考虑利用深度学习进行图像/视频编码的探索,事实上,自2015年以来,这个研究领域就开始了积极的发展。目前,研究已经显示出良好的结果,证实了基于深度学习的图像/视频编码的可行性。尽管如此,这项技术还远远不够成熟,需要更多的研究和开发工作。
\quad 本文旨在对基于深度学习的图像/视频编码的最新研究成果进行全面的综述(截止到2018年底),并以我们开发的原型视频编解码器——深度学习视频编码(DLVC)为例,让感兴趣的读者了解目前的现状。读者也可以参考[84]最近发表的关于同一主题的评论文章。
\quad 本文的其余部分组织如下。第二章和第三章回顾了使用深度学习进行图像/视频编码的相关工作。相关著作分为两类,分别在两部分中进行综述。第一类是深度方案,即主要建立在深度网络上的新的编码方案;第二类是深度工具,即嵌入到传统非深度编码方案中的基于深度网络的编码工具;深度工具可以替代传统方案中的对应工具,也可以新加入到方案中。第四章介绍了我们开发的DLVC,给出了所有的设计细节和实验结果。第五章总结了我们对未来研究中一些有待解决的问题的看法,并对本文进行了总结。表一列出了本文使用的缩写。
C.绪论
\quad 在本文中,我们考虑了自然图像/视频的编码方法,即日常相机或手机拍摄的人类所看到的图像/视频。虽然这些方法通常是通用的,但它们是专门为自然图像/视频设计的,对于其他类型(例如生物医学、遥感)可能不太适用。
\quad 目前,几乎所有的自然图像/视频都是数字格式的。灰度数字图像可以用 x ∈ D m × n x∈ \Bbb D^{m×n} x∈Dm×n 表示,其中m和n为图像的行数(高)和列数(宽), D \Bbb D D 是单张图像(所有)元素(像素)的定义域。例如, D = { 0 , 1 , . . . , 255 } \Bbb D = \{0,1,...,255\} D={0,1,...,255}是一种常见的设置,其中, ∣ D ∣ = 256 = 2 8 |\Bbb D| = 256 = 2^8 ∣D∣=256=28,从而像素值可以用8位整数表示;因此,一个未压缩的灰度数字图像有8比特每像素(bpp),压缩后的位肯定更少。
\quad 彩色图像通常被分解成多个通道来记录颜色信息。例如,使用RGB颜色空间,一个彩色图像可以表示为 x ∈ D m × n × 3 x ∈ \Bbb D^{m×n×3} x∈Dm×n×3,其中3表示三个通道——红、绿、蓝。由于人类的视觉对亮度比色度更敏感,因此YCbCr(YUV)颜色空间比RGB采用得更多,并且通常对U和V通道进行下采样以实现压缩。例如,在所谓的YUV420彩色格式中,彩色图像可以用 X = { x Y ∈ D m × n , x U ∈ D m 2 × n 2 , x V ∈ D m 2 × n 2 } X = \{ x_Y ∈ \Bbb D^{m×n}, x_U ∈ \Bbb D^{\frac m2×\frac n2}, x_V ∈ \Bbb D^{\frac m2×\frac n2} \} X={xY∈Dm×n,xU∈D2m×2n,xV∈D2m×2n}表示。
\quad 彩色视频由多个彩色图像组成,称为帧,以记录不同时间戳的场景。例如,在YUV420彩色格式中,一个彩色视频可以被表示为 V = { X 0 , X 1 , . . . , X T − 1 } V = \{ X_0,X_1,...,X_{T-1} \} V={X0,X1,...,XT−1},其中,T是帧数, X i = { x Y ( i ) ∈ D m × n , x U ( i ) ∈ D m 2 × n 2 , x V ( i ) ∈ D m 2 × n 2 } X_i = \{ x^{(i)}_Y ∈ \Bbb D^{m×n},x^{(i)}_U ∈ \Bbb D^{\frac m2×\frac n2},x^{(i)}_V ∈ \Bbb D^{\frac m2×\frac n2} \} Xi={xY(i)∈Dm×n,xU(i)∈D2m×2n,xV(i)∈D2m×2n}。如果 m=1080,n=1920, ∣ D ∣ = 2 10 |\Bbb D| = 2^{10} ∣D∣=210,一个视频为50帧每秒(fps),那么未压缩的视频数据率为 1080 × 1920 × ( 10 + 10 4 + 10 4 ) × 50 = 1 , 555 , 200 , 000 1080×1920×(10+\frac {10}4 +\frac {10}4) ×50=1,555,200,000 1080×1920×(10+410+410)×50=1,555,200,000 比特每秒(bps),大约1.555Gbps。显然,在这段视频可以有效地在当前有线和无线网络中传输之前,它应该先以成百上千的比例被压缩。
\quad 现有的无损编码方法对自然图像的压缩比约为1.5:3,明显低于要求。因此,引入有损编码来压缩更多的数据,但代价是产生损耗。损失可以通过原始图像和重建图像之间的差异来测量,例如对灰度图像使用均方误差(MSE): M S E = ∣ ∣ x − x r e c ∣ ∣ 2 m × n ( 1 ) MSE = \frac {||x-x_{rec}||^2}{m×n}\qquad(1) MSE=m×n∣∣x−xrec∣∣2(1)因此,与原始图像相比,重建图像的质量可以用峰值信噪比(PSNR)来衡量: P S N R = 10 × l o g 10 ( m a x ( D ) ) 2 M S E ( 2 ) \rm PSNR = 10×log_{10}\frac {(max(\Bbb D))^2}{MSE}\qquad(2) PSNR=10×log10MSE(max(D))2(2)其中 m a x ( D ) max (\Bbb D) max(D)为 D \Bbb D D中的最大值,8位灰度图像中为255。对于彩色图像/视频,Y、U、V的PSNR值通常分开计算。对于视频,不同帧的PSNR值通常分开计算然后求平均。还有其他可以替代PSNR的质量指标,如结构相似度(SSIM)和多尺度SSIM (MS-SSIM) [126]。
\quad 为了比较不同的无损编码方案,只要比较压缩比或产生的速率(bpp、bps等)就足够了。为了比较不同的有损编码方案,有必要同时考虑速率和质量。例如,一种常用的方法是计算几个不同质量水平的相对比率,然后求平均比率;平均相对比率被称为Bjontegaard’s delta-rate (BD-rate) [13]。评估图像/视频编码方案还有其他重要方面,包括编码/解码复杂性、可伸缩性、鲁棒性等。
\quad 在本节中,我们将回顾一些典型的主要建立在深度网络上的编码方案。一般来说,深度图像编码有两种方法,像素概率建模和自动编码器。在一些深度方案中,这两种方法被结合起来使用。另外,我们讨论了深度视频编码方案和专用编码方案,其中专用编码方案进一步分为感知编码和语义编码。
A. 像素概率建模
\quad 根据香农信息论[102],最优的无损编码方法可以达到最小编码速率—— l o g 2 p ( x ) log_2p(x) log2p(x),其中 p(x) 是符号 x 的概率。为了达到这个目标,人们提出了大量的无损编码方法,其中,算术编码被认为是最优的编码方法之一[129]。事实上,对于给定的概率 p(x),算术编码就是要确保编码率要尽可能接近 l o g 2 p ( x ) log_2p(x) log2p(x) 直到舍入误差。因此,剩下的问题是求出概率,而这对于自然图像/视频来说是非常困难的,因为它的维度很高。
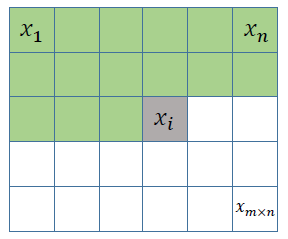
图1. 一种典型的预测编码方案,其中像素按光栅扫描顺序逐点编码/解码。对于像素 x i x_i xi(标记为灰色),所有之前的像素(标记为绿色),即 x i x_i xi的上面和 x i x_i xi同一行的左边,都可以作为条件来预测 x i x_i xi的像素值。绿色区域也被称为 x i x_i xi的上下文。为了简化,可以选择绿色区域的子集做为上下文。
\quad 一种估计 p(x) 的方法是(这里的 x 是图像):将图像分解为 m × n m×n m×n 个像素并逐个估计这些像素的概率(如按光栅扫描顺序)。这是一种典型的预测编码策略。注意 p ( x ) = p ( x 1 ) p ( x 2 ∣ x 1 ) ⋅ ⋅ ⋅ p ( x i ∣ x 1 , . . . , x i − 1 ) ⋅ ⋅ ⋅ p ( x m × n ∣ x 1 , . . . , x m × n − 1 ) ( 3 ) p(x) = p(x_1)p(x_2|x_1)···p(x_i|x_1,...,x_{i-1})···p(x_{m×n}|x_1,...,x_{m×n-1})\qquad(3) p(x)=p(x1)p(x2∣x1)⋅⋅⋅p(xi∣x1,...,xi−1)⋅⋅⋅p(xm×n∣x1,...,xm×n−1)(3)如图1所示。这里 x i x_i xi的条件也被成为 x i x_i xi的上下文。当图像很大时,条件概率会变得难以估计。一种简化的方法是缩小上下文的范围,如 p ( x ) = p ( x 1 ) p ( x 2 ∣ x 1 ) ⋅ ⋅ ⋅ p ( x i ∣ x i − k , . . . , x i − 1 ) ⋅ ⋅ ⋅ p ( x m × n ∣ x m × n − k , . . . , x m × n − 1 ) ( 4 ) p(x) = p(x_1)p(x_2|x_1)···p(x_i|x_{i-k},...,x_{i-1})···p(x_{m×n}|x_{m×n-k},...,x_{m×n-1})\qquad(4) p(x)=p(x1)p(x2∣x1)⋅⋅⋅p(xi∣xi−k,...,xi−1)⋅⋅⋅p(xm×n∣xm×n−k,...,xm×n−1)(4)其中,k是一个预先选择的常数。
\quad 众所周知,深度学习善于解决回归和分类问题。因此,提出了给出上下文 x 1 , . . . , x i − 1 x_1,...,x_{i-1} x1,...,xi−1,通过训练深度网络估计概率 p ( x i ∣ x 1 , . . . , x i − 1 ) p(x_i|x_1,...,x_{i-1}) p(xi∣x1,...,xi−1) 的方法。这种策略早在2000年就被提出用于其他类型的高维数据[12],但直到最近才被应用于图像/视频。例如,在[58]中,考虑了二值图像的概率估计,即 x i ∈ { − 1 , + 1 } x_i∈\{-1,+1\} xi∈{−1,+1},在这里为每一个像素预测一个单一概率值 p ( x i = + 1 ∣ x 1 , . . . , x i − 1 ) p(x_i=+1|x_1,...,x_{i-1}) p(xi=+1∣x1,...,xi−1)就足够了。文中提出了一种基于神经网络的自回归分布估计器(NADE),该自回归分布估计器使用一个具有一个隐层的前馈网络对每个像素点进行参数共享。参数共享还有助于加快每个像素的计算速度。在[37]中也有类似的工作,前馈网络也有跳过隐含层的连接,并且参数也是共享的。[58]和[37]都对二值化MNIST数据集进行了实验。Uria等[116]将NADE扩展为实值NADE (RNADE),其中概率 p ( x i ∣ x 1 , . . . , x i − 1 ) p(x_i|x_1,...,x_{i-1}) p(xi∣x1,...,xi−1)是由一个混合高斯模型生成的,前馈网络需要输出一组高斯混合模型的参数,而不是NADE中的单一值。他们的前馈网络有一个隐藏层并设置了参数共享,但隐藏层为避免过拟合而设置了尺度缩放,并使用整流线性单元(ReLU)[90]代替了sigmoid。他们还考虑了拉普拉斯混合而非高斯混合。在8×8的自然图像块上进行实验,将像素值加入噪声并转换为真实值。在[117]中,通过使用像素的不同顺序以及在网络中使用更多的隐藏层对NADE和RNADE进行了改进。在[120]中,使用深度GMM对高斯混合模型(GMM)进行增强来改进RNADE。
\quad 设计先进的网络是改进像素概率建模的一个重要课题。[109]中提出了基于多维长短时记忆(LSTM)的网络,并将其与条件高斯尺度(GMM的一种推广)融合,用于概率建模。LSTM是一种递归神经网络,具有良好的序列数据建模能力。LSTM的空间变体被用于图像。后来在[118]中,研究了几种不同的网络,包括被称为PixelRNN和PixelCNN的RNNs和CNNs。PixelRNN提出两种LSTM变体,称为行LSTM和对角BiLSTM,后者是专门为图像设计的。PixelRNN整合了剩余连接[40]来帮助训练多达12层的深层网络。PixelCNN为了适应上下文(见图1)的形状,提出了masked卷积。PixelCNN也有15层。与之前的工作相比,PixelRNN和PixelCNN更专注于自然图像:它们将图像看作离散值(如0,1,…,255)来预测离散值上的多项分布;它们处理彩色图像(在RGB颜色空间中);提出了多尺度PixelRNN;它们在CIFAR-10和ImageNet数据集上运行良好。大量的研究采用了PixelRNN和PixelCNN的方法。在[119]中,门控PixelCNN被提出来对PixelCNN进行改进,其性能与PixelRNN相当,但复杂度大大降低。在[99]中,PixelCNN++在PixelCNN的基础上提出了以下改进:使用离散的逻辑混合似然来代替256路多项分布;下采样用于捕获多分辨率的结构;为了加快培训速度,引入了额外的short-cut连接;采用dropout进行正则化;将RGB合并为一个像素。[18]提出了PixelSNAIL,通过自注意力将任意卷积结合起来。
\quad 上述工作大多直接对像素概率进行建模。此外,像素概率可以建模为一个有条件的显式或潜式表示。也就是说,我们可以估算 p ( x ∣ h ) = ∏ i = 1 m × n p ( x i ∣ x 1 , . . . , x i − 1 , h ) ( 5 ) p(x|h) = \prod_{i=1}^{m×n}p(x_i|x_1,...,x_{i-1},h)\qquad(5) p(x∣h)=i=1∏m×np(xi∣x1,...,xi−1,h)(5)其中h是附加条件。注意 p ( x ) = p ( h ) p ( x ∣ h ) p(x) = p(h)p(x|h) p(x)=p(h)p(x∣h),这意味着建模分为无条件建模和条件建模。例如,在[119]中,附加条件可以是由另一个深层网络派生的图像类或高级图像表示。[56]考虑了含有潜在变量的PixelCNN,这些潜在变量来源于原始图像:它们可以是原始彩色图像的量化灰度版本,也可以是一个多分辨率的图像金字塔。
\quad 在实际的图像编码方案中,[64]中采用了具有裁剪卷积的网络来预测二进制数据的概率,通过网络处理将大小为m×n的8位灰度图像转换为大小为m×n×8的二进制立方体。网络和PixelCNN相似,但它是三维的。据说裁剪后的基于卷积网络的算术编码(TCAE)比之前的非深度无损编码方案更好,例如TIFF, GIF, PNG, JPEG-LS和JPEG 2000-LS;在Kodak图像集上,TCAE达到了2.00的压缩比。不同的是,在[4中,CNN是在小波变换域而不是像素域使用的,即CNN从相邻子带的系数中预测小波细节系数。
\quad 对于视频编码,在[52]中,将PixelCNN推广到视频像素网络(VPN)中进行视频像素概率建模。VPN由CNN编码器(针对前一帧来预测当前帧)和PixelCNN解码器(用于当前帧内的预测)组成。CNN编码器在所有层都保持输入帧的空间分辨率,以最大限度地提高表示能力。采用空洞卷积来扩大接收域,更好地捕捉全局运动。随着时间的推移,CNN编码器的输出与卷积LSTM相结合,也保留了分辨率。PixelCNN解码器使用masked卷积,并采用离散像素值上的多项分布。VPN在Moving MNIST和Robotic Pushing数据集上作了验证。
\quad 另外,Schiopu等[101]研究了一种无损图像编码方案,使用CNN而非其分布来预测像素值。真实像素值减去预测值得到残差,然后对残差进行编码。此外,他们还考虑了CNN预测器和一些非CNN预测器之间的自适应选择。
B. 自动编码器
\quad 自动编码器起源于Hinton和Salakhutdinov的著名工作[42],它训练一个由编码部分和解码部分组成的降维网络。编码部分将输入的高维信号转换为低维表示,解码部分将高维信号从低维表示中恢复(不是完全恢复)。自动编码器实现了表示的自动学习,减少了对手工设计特性的需求,被认为是深度学习最重要的优势之一。
\quad 采用自动编码器网络进行有损图像编码似乎非常简单:编码器和解码器都经过了训练,我们只需要对学习得到的表示进行编码。然而,传统的自动编码器没有针对压缩进行优化,直接使用经过训练的自动编码器效率不高[127]。当我们考虑压缩需求时,会遇到以下几个挑战:第一,低维表示需要先量化再编码,但是量化步骤是不可微分的,这使训练网络比较困难。第二,有损编码是为了获得速率和质量之间的更好地权衡,因此训练网络时应考虑速率,但速率不易计算或估计。第三,一个实际的图像编码方案需要考虑可变速率、可伸缩性、编码/解码速度、互操作性等。为了应对这些挑战,近年来人们进行了大量的研究。
\quad 基于自编码器的图像编码方案的概念图如图2所示,这是一种典型的转换编码策略。原始图像 x x x 转换为 y = g a ( x ) y = g_a(x) y=ga(x), y y y 被量化然后被编码。解码后的 y ^ \hat y y^ 反变换为 x = g s ( y ^ ) x = g_s(\hat y) x=gs(y^)。考虑到速率和质量之间的权衡,我们可以训练网络来最小化联合率失真代价 D + λ R D+\lambda R D+λR,其中 D D D 由 x x x 和 x ^ \hat x x^ 的差值来计算或估计(注意差值的计算或估计可以在感知空间中进行), R R R 由量化码计算或估计, λ \lambda λ 是拉格朗日乘子。现有的研究或多或少都遵循这一方案,但其网络结构和损失函数各不相同。
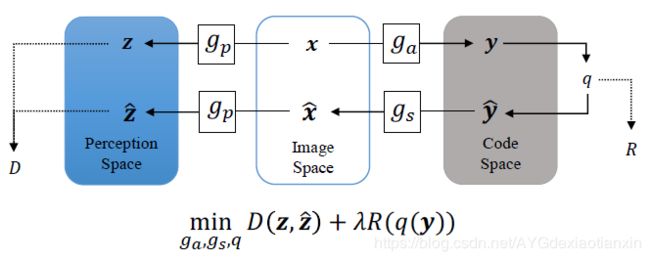
图2. 典型的转换编码方案的说明。通过分析函数 g a g_a ga 对原始图像 x x x 进行变换,得到编码 y y y,将编码 y y y 量化(用 q q q 表示)并压缩为比特。用比特数来测量编码率 ( R ) (R) (R),然后用合成函数 g s g_s gs 对量化后的码 y ^ \hat y y^ 进行反变换,得到重构后的图像 x ^ \hat x x^。 x x x 和 x ^ \hat x x^ 通过相同的感知函数 g p g_p gp进一步变换,分别得到 z z z 和 z ^ \hat z z^。 z z z 和 z ^ \hat z z^ 之差用于测量失真(D)。
\quad 在网络结构上,RNNs和CNNs是应用最广泛的两类网络。最具代表性的工作有:
\quad ·Toderici等人[111]提出了一种可变速率图像压缩的通用框架。他们使用二进制量化来生成编码,不考虑训练的速率,即损耗只是端到端失真,用MSE来测量。他们的框架确实提供了一个可伸缩的编码功能,据说其中具有卷积和反卷积层的RNN(特别是LSTM)表现良好。他们提供了一个32×32缩略图的大尺度数据集的结果。后来,Toderici等人[112]提出了一个改进的版本,他们使用像PixelRNN[118]这样的神经网络来压缩二进制代码;他们还引入了一种新的门控递归单元(GRU),其灵感来自于残差网络(ResNet)[40]。使用MS-SSIM作为质量度量,在Kodak图像集上报告的结果比JPEG更好。Johnston等人[51]通过在RNN中引入隐藏状态启动,使用ssim加权损失函数,并支持空间自适应比特率,进一步改进了基于RNN的方法。在使用MS-SSIM的柯达图像集上,取得了比BPG更好的效果。Covell等人[22]通过训练容忍停止码的RNNs来实现空间自适应比特率。
\quad ·Balle等人[9]提出了一个针对率失真优化的图像压缩通用框架。他们使用多元量化来生成整数编码,并考虑训练时的速率,即损失函数是联合率失真代价,其中失真可以是MSE,也可以是其他形式。为了估计这个速率,他们在训练中加入随机噪声来代替量化,并使用有噪声“代码”的微分熵代替速率。网络结构方面,他们使用了由线性映射(矩阵乘法)和非线性参数归一化组成的广义分裂归一化(GDN)变换;在[8]中验证了所提出的图像编码GDN网络的有效性。后来,Balle等人[10]提出了改进的版本,他们使用3个卷积层,每一层都由下采样和GDN操作来实现变换;因此,使用3层反GDN+上采样+卷积来实现逆变换。此外,他们还设计了一种算术编码方法来压缩整数编码。在使用MSE作为质量度量的柯达图像集上,他们报告了比JPEG和jpeg2000更好的结果。此外,受变分自动编码器的启发,Balle等人[11]通过将将超先验尺度融入到自动编码器中改进了他们的方案。他们使用另一种变换 h a h_a ha 来将 y y y 转换为 w = h a ( y ) w=h_a(y) w=ha(y),对 w w w(作为边信息传输)进行量化和编码,并使用另一个逆变换 h s h_s hs 将解码后的 w ^ \hat w w^ 转化为量化后的 y ^ \hat y y^ 的估计标准差,这个估计标准差稍后会用于 y ^ \hat y y^ 的算术编码。在柯达图像集上,使用PSNR作为质量度量,他们的方法只比BPG略差。
\quad 除了[9],还有很多工作都专注于解决不可微量化和/或速率估计问题。Theis等人[110]采用了一种非常简单的量化方法:在前向通道中像往常一样进行量化,而在后向通道中则将梯度直接通过量化层。令人惊讶的是,这种变通工作得很好。此外,它们用一个可微的上界来代替速率。Dumas等人[29]考虑了一种随机赢者通吃的机制,其中y中绝对值最大的项保持不变,其他项设置为0;然后对项进行均匀的量化和压缩。Agustsson等人[2 提出了一种软到硬的矢量量化方案,他们在训练过程中使用了软量化(即为具有不同成员值的多个代码分配一个表示),而不是硬量化(即仅为一个代码分配一个表示),并采用退火过程,让软量化逐渐接近硬量化。注意,他们的方案利用了矢量量化,而其他方案通常采用标量量化。Li等[65]提出了一种用于速率估计的重要映射,它将重要映射量化为掩码,掩码决定在每个位置保留多少比特位,因此重要映射的总和可以用来粗略估计编码速率。
\quad 除了[111],一些研究还考虑了对不同速率进行较少或不进行训练的可变速率的功能。在[110]中,引入了尺度参数,使用预训练的自动编码器对不同的速率进行微调。在[30]中,提出了一种独特的学习变换,对不同速率使用可变的量化步长。在[15]中,对所有尺度进行多尺度分解变换训练和优化;提供了速率分配算法,以确定针对目标速率或目标质量因子的每个图像块的最优尺度。此外,[146]提出了和[111]不同的可伸缩编码。在[146]中,将图像分解为多个位平面,并对其进行并行变换和量化;为了减少不同位平面之间的相关性,提出了双向装配门控单元。
\quad 一些研究考虑了先进的网络结构和不同的损失函数。Theis等人[110]采用了亚像素结构提高计算效率。Rippel和Bourdev等人[97]提出了提出了一个金字塔分解,其后伴随着轻量级、实时运行的跨尺度对齐网络。除了重构损失,他们还使用了鉴频器损失。Snell等人[104]使用MS-SSIM代替MSE或平均绝对误差(MAE)作为训练自动编码器的损失函数,他们发现MS-SSIM能更好地校准感知质量。Zhou等人[149]对编码器/解码器使用更深的网络,并在解码端使用单独的网络做后处理。他们还用拉普拉斯模型代替了[11]中的高斯模型。
\quad 如前所述,像素概率建模表示预测编码,自动编码器表示变换编码。这两种策略可以结合使用以获得更高的压缩效率。Mentzer等人[87]提出了一种实用的无损图像编码方案,该方案在多个层次上使用自动编码器来学习像素概率建模的条件。Mentzer等人[86]将像素概率建模(一种3D PixelCNN)集成到自动编码器中来估计编码速率,并对PixelCNN和自动编码器进行联合训练。Baig等人[6]将部分上下文图像修复引入可变速率压缩框架,也就是通过一个块的上下文来预测块,假设这些块按光栅扫描顺序逐个进行编码/解码(类似于图1所示,但处于块级别)。将预测信号加入到网络输出信号中获得 x ^ \hat x x^,即变换编码网络处理预测残差。Minnen等人[89]还考虑了块之间的速率分配。类似但是方法不同,Minnen等人[88]通过增加超前上下文改进[11],即他们不仅使用 w ^ \hat w w^,还使用上下文来预测 y ^ \hat y y^ 的每一项。他们的方法使用PSNR作为质量度量,柯达图像集上表现优于BPG,这也代表了到2018年底的技术水平。Lee等人[60]将上下文自适应熵模型引入了超前 w ^ \hat w w^。
\quad 此外,Cheng等人[21] 将主成分分析应用于学习表示,实际上是做了二次变换。
C.视频编码
\quad 自2017年以来,已有一些关于深度视频编码方案的研究报道。与图像编码相比,视频编码需要有效的方法来消除图像间的冗余。因此,帧间预测是这些研究中的一个重要问题。运动估计和补偿技术被广泛采用,但直到最近才被训练好的深度网络实现。
\quad Chen等人[17]似乎首先报告了使用训练好的深度网络作为自动编码器的视频编码方案。具体来说,他们将视频帧分成32×32块,每一块他们从两种模式中选择一种:帧内编码或帧间编码。如果使用帧内编码,有一个自动编码器来压缩块。如果使用帧间编码,则使用传统方法进行运动估计和补偿,并将残差输入到另一个自动编码器。对于这两种自动编码器,编码表示直接由霍夫曼方法做量化和编码。这个方案相当粗糙,无法与H.264竞争。
\quad Wu等人[131]提出了一种基于图像插值的视频编码方案,其中关键帧(I帧)首先由[112]中的深度图像编码方案压缩,其余帧(B帧)再按层次顺序压缩。对于每一个B帧,使用前后的两个压缩帧(I帧或之前压缩过的B帧)“内插”当前帧:使用运动信息对两个压缩帧进行变形(即运动补偿),然后将变形后的两个帧作为边信息发送给处理当前帧的可变速率图像编码方案。据报道,该方案的性能可与H.264相媲美。
\quad Chen等人[20]提出了另一种视频编码方案,即所谓的PixelMotionCNN。在他们的方案中,帧是按时间顺序压缩的,每一帧都被划分为按光栅扫描顺序压缩的块。在压缩一个帧之前,前两个压缩帧用于“推断”当前帧。当对一个块进行压缩时,将推断得到的帧连同块的上下文发送到PixelMotionCNN,生成当前块的预测信号,然后采用[112]中的可变速率图像编码方案对预测残差进行压缩。该方案的性能也可与H.264相媲美。
\quad Lu等人[80]提出了一种真正的端到端深度视频编码方案,可以看作是传统视频编码方案的“深化”版本。在他们的方案中,每个要压缩的帧都使用一个光流估计模块来获得帧与先前压缩帧之间的运动信息。运动补偿也由一个训练好的网络来执行,以产生当前帧的预测信号。对于预测残差和运动信息,分别使用两个自动编码器进行压缩。整个网络采用单一损耗函数联合优化,即联合率失真代价。据报道,该方案比H.264实现了更好的压缩效率,甚至在使用MS-SSIM进行评估时优于HEVC (x265编码器)。
\quad Rippel等[98]提出了迄今为止最成熟的深度视频编码方案,该方案继承并扩展了传统视频编码方案的深化版本。该方案具有以下特点:(1)只有一个自动编码器同时压缩运动信息和预测残差;(2)从前一帧中学习并递归更新的状态;(3)多帧多光流运动补偿;(4)速率控制算法。在使用MS-SSIM进行评估时,该方案的性能优于HEVC参考软件(HM)。
\quad 到2018年底,我们没有看到任何关于深度视频编码方案在使用PSNR评估时能够超越HM,这似乎是一个艰巨的任务。
D.专用编码
\quad 关于深度方案的研究大多涉及到图像/视频的信号保真度 编码,即在给定速率下最小化原图像/视频与重建图像/视频之间的失真,其中的失真可以定义为MSE或其他不同形式。然而,如果我们不关心保真度,我们可能会关心重构图像/视频的感知自然性,或者重构图像/视频在语义分析任务中的效用。后两种质量度量被称为感知自然度 和语义质量。已经有一些研究针对这些质量指标定制了图像/视频编码方案。
\quad 1)感知自然度: 自生成对抗网络(GAN)[34]兴起以来,深度网络被认为能够产生感知自然的图像。利用解码器端的这一能力,可以提高解码图像的感知质量。与普通GANs中的生成器不同,解码器还应确保解码后的图像与原始图像相似,这就产生了受控生成的问题,编码器实际上在编码位中提供控制信号。
\quad 受变分自动编码器(VAE)[55]的启发,Gregor等人[36]提出了一种深度递归注意写入(DRAW)的图像生成方法,利用RNNs作为编码器和解码器对传统的VAE进行了扩展。将编码器RNN展开会产生一系列潜在的表示。随后,Gregor等人在[35]中引入了卷积绘图,并观察到它能够将图像转化为一系列越来越详细的表示,从全局概念方面到低层细节。随后,Gregor等人[35]引入了卷积DRAW,并观察到它能够将图像转化为一系列越来越详细的表示,从全局概念方面到低层细节。因此,他们提出了一种概念压缩方案,其优点之一是可以在极低的比特率下实现可信的重建图像。
\quad 人们已经认识到,感知觉自然度可以通过GAN[14]中的鉴别器来进行评价。目前有许多研究致力于利用鉴别器损耗单独或联合MSE损耗或其他损耗对感知质量进行深度编码。例如,Santurkar等人[100]提出了图像和视频的生成压缩方案。对于图像,他们首先训练一个标准GAN,然后使用生成器作为解码器,修复它,然后训练编码器,以最小化MSE和特征损失的总和。对于视频,它们重用经过图像训练的编码器和解码器,只传输少量帧,并通过插值恢复解码器端的其他帧。他们的方案能够达到很高的压缩比。Kim等人[54]构建了一个新的视频压缩方案,其中几个关键帧按一般方式压缩(H.264格式),而其他帧则被高度压缩。实际上,从下采样的非关键帧中提取边缘并进行传输。在解码器端,首先重构关键帧,然后对关键帧进行相似的边缘提取。以边为条件的重构关键帧对条件GAN进行训练。然后利用条件GAN生成非关键帧。同样,他们的方案在非常低的比特率下表现良好。
\quad 2)语义编码: 在语义信息保留或关注语义质量的深层编码方案方面,已经有了一些研究。
\quad Agustsson等人提出了一种针对极低比特率的基于GAN的图像压缩方案。该方案结合了自动编码器和GAN,将解码器和生成器合二为一。此外,语义标签映射可以用作编码器的附加输入,也可以用作鉴别器的条件。据报道,该方法重构出的图像具有较高的语义质量,即在相同的速度下,这些图像的语义分割比BPG压缩图像的语义分割更准确。
\quad Luo等人[81]提出了深度语义图像压缩(DeepSIC),将语义信息(如类)合并到编码位中。DeepSIC有两个版本,都基于自动编码器。在一个版本中,语义信息从表示 y y y 中提取出来,并编码到位中。在另一个版本中,语义信息不进行编码,而是在解码器端从量化的表示 y ^ \hat y y^ 中提取出来。Torfason等人[113]研究了从量化表示而不是重构图像执行语义分析任务(分类和语义分割)。也就是说,解码过程被省略了。结果表明,表示的分类精度和分割精度与图像非常接近,但计算复杂度明显降低。Zhang等[143]研究了一种用于同时压缩和检索的深度图像编码方案。他们的动机是编码位不仅可以用来重建图像,而且可以在不解码的情况下检索相似的图像。他们使用一个自动编码器将图像压缩成比特,并使用一个修改过的分类网络来提取二进制特征。然后将这两部分结合起来,对图像检索的特征提取网络进行微调。结果表明,在相同的速率下,重构图像优于JPEG压缩图像,并且由于进行了微调,提高了检索精度。
\quad Akbari等人设计了一个可伸缩的图像编码方案,其中编码位由三层组成。第一层是无损编码的语义分割图。第二层是原始图像的降采样版本,也是无损编码的。在前两层中,训练网络对原始图像进行预测,用BPG对预测残差进行编码作为第三层。据报道,当使用PSNR和MS-SSIM进行评估时,该方案在柯达图像集上的表现优于BPG。
\quad Chen和He[19]考虑使用语义质量度量代替PSNR或感知质量来对面部图像进行深度编码。为此,它们的损失函数有三个部分:MAE、鉴别器损失和语义损失,语义损失是指通过学习变换将原始图像和重建图像投影到一个紧凑的欧几里得空间中,并计算它们之间的欧几里得距离。在相同的速率下,通过人脸验证精度的评估,其方案的性能非常好。
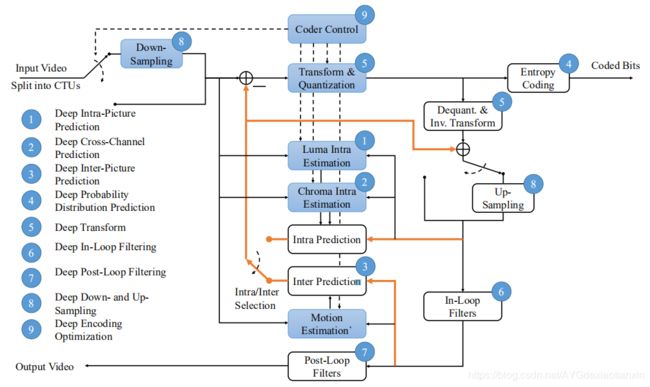
图3. 介绍了一种传统的混合视频编码方案以及该方案中深度工具的位置。注意,黄色的线表示预测流,蓝色的方框表示仅在编码器端使用的工具。
\quad 在这一节中,我们将回顾一些具有代表性的在传统编码框架中,或和传统编码工具一起,使用训练好的深度网络作为工具的研究工作。传统的视频编码方案一般采用预测编码和变换编码相结合的混合编码策略。如图3所示,一段输入视频序列被分为若干图片,图片可以分为若干块(在HEVC[108]中,最大的块被称为CTU, CTU可以被划分为更小的CUs),块可以被划分为通道(即Y,U,V)。图片、块、通道按照预定义的顺序压缩,先压缩的可以预测后压缩的,分别被称为帧内预测(块间),跨通道预测(通道间),和帧间预测(图像间)。然后对预测残数进行转换和量化,并对其进行熵编码以获得最终的比特。一些辅助信息,如块划分和预测模式,也被熵编码到位中(图中没有显示)。熵编码采用概率分布预测方法。由于量化步骤会丢失信息并可能产生伪影,因此提出了滤波的方法来增强重建的视频,滤波可以在循环内(预测下一幅图像之前)或在循环外(输出之前)执行。另外,为了减少数据量,图像/块/通道可以在压缩前先向下采样,压缩后再向上采样。最后,编码器需要控制不同的模块,并将它们组合起来,以实现编码速度、质量和计算速度之间的权衡。编码优化是实际编码系统中的一个重要课题。
\quad 经过训练的深度网络几乎可以充当图3中所示的所有模块,其中我们为深度工具指出了不同的位置。在接下来的文章中,我们将根据深度工具在整个方案中的使用情况,对其相关工作进行回顾。
A.帧间图像预测
\quad 帧内图像预测,或简称帧内预测,是一种预测同一幅图片中不同块之间的信息的工具。H.264中通过几种预定义的预测模式提出了帧内预测,例如DC预测和沿不同方向的外推[128]。编码器可以对每个块选择一个预测模式,并将选择的信号发送给解码器。为了确定模式,一般方法是比较不同模式的编码率和失真,选择率失真代价最小的模式。HEVC中提出了更多的预测模式[108]。
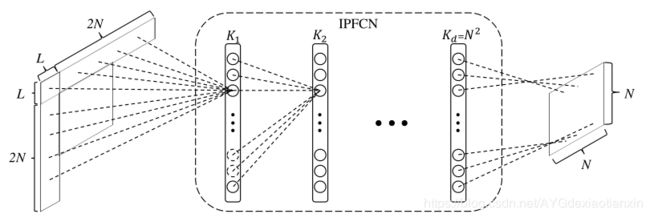
图4. 用于帧内预测的全连接网络
\quad Li等人[63]提出了一个用于帧内预测的全连接网络,如图4所示,对当前 N × N N×N N×N 块,他们使用上边的L行和左边的L列,总共 4 N L + L 2 4NL+L^2 4NL+L2 个像素作为上下文。他们使用 New York City Library 图像集生成训练数据,其中原始图像按不同的量化参数(QPs)进行压缩。当训练网络时,他们研究了两种策略:第一种是用全部训练数据训练一个简单的模型,第二种是通过考虑HEVC预测模式,将训练数据分为两组,分别训练两个模型。两种模型的方法在压缩时效果更好。他们将训练后的网络与HEVC模式整合为新的预测模式,比HM节省大约3%的BD率。
\quad Pfaff等人[94]也采用全连接网络用于帧内预测,但是提出训练多个网络作为不同的预测模式。另外,他们提出训练单独的网络,网络的输入是块的上下文,但输出是不同模式的预测可能性。此外,他们建议对每个基于网络的预测模式使用不同的变换。他们报告的性能非常好:与HM的改进版本(使用高级块分区)相比,大约降低了6%的BD率。
\quad Hu等人[44]设计了一个用于帧内预测的渐进式空间RNN。与之前的工作不同,他们提出利用RNN的顺序建模能力,逐步生成从上下文到块的预测。另外,他们建议使用绝对变换差的和(SATD)作为损失函数并任务SATD与率失真代价具有更好的相关性。
\quad Cui等人[23]考虑了一个用于帧内预测,或更具体地说,用于帧内预测细化的CNN。他们使用HEVC预测模式生成预测,然后使用训练好的CNN细化预测。注意CNN不只使用HEVC预测,还使用上下文做它的输入。这个方法似乎只有些许效果。
B.帧间图像预测
\quad 帧间图像预测,或简称帧内预测,是一种对视频帧间进行预测的工具,目的是消除时间冗余。帧间预测是视频编码的核心,它主要决定视频编码方案的压缩效率。在传统视频编码框架中,帧间预测主要由块间运动估计(ME)和运动补偿(MC)实现。给定一个参考帧和一个待编码的块,ME是在参考帧中找到内容与待编码块中最相似的位置,MC是在找到的位置检索内容,从而预测块。为了提高块级ME和MC,人们提出了许多技术,如使用多参考帧、双向间预测(即联合使用两个参考帧)、分数像素ME和MC等。
\quad 受多参考帧启发,Lin等人[71]通过外推多参考帧提出了一种新帧间预测机制。具体来说,他们采用了GANs的拉普拉斯金字塔从之前已压缩的四帧推断一帧。这个推断得到的帧作为另一个参考帧。他们报告比HM节省大约2%的BD率。
\quad 受双向帧间预测启发,Zhao等人[148]提出了一种增强预测质量的方法。以前的双向预测只是简单地计算两个预测块的线性组合。他们建议使用训练好的CNN将两个预测块以非线性和数据驱动的方式结合起来。
\quad 受到分数像素ME和MC的启发,人们对分数像素插值问题进行了大量研究,分数像素插值的目的是在参考帧的分数位置生成虚拟像素,因为两个帧之间的运动没有对齐到整数像素。这里的主要困难是如何准备训练数据,因为分数像素是虚构的。Yan等人[137]提出使用CNN做半像素插值,他们提出了一种模糊高分辨率图像的方法,然后从模糊图像中提取像素:奇数位置为整数像素,偶数位置为半像素。这个方法在[76]中被继承,作者分析了不同模糊度的影响。Zhang等人[141]提出了另一种方法,将分数插值问题表示为一个分辨率增强问题。因此,他们通过下采样高分辨率图像来获取训练数据。Yan等人[136]考虑了一种不同的方法,将分数像素MC作为帧间图像回归问题。他们使用视频序列来检测训练数据,依靠分数像素ME对齐不同帧,然后将参考帧当作整数像素,将当前帧当作分数像素。Yan等人[135]进一步发现了分数插值问题的一个关键特征,即其可逆性:如果分数像素可以从整数像素插值而来,你们整数像素一个也可以从分数像素插值而来。基于其可逆性,他们提出了一种无监督训练CNN进行半像素插值的方法。
\quad 除了改进帧间预测方法,还有一种将帧内和帧间结合起来的方法。具体来说,预测信号的生成不仅基于参考帧,还基于当前帧的上下文。例如,Huo等人[45]提出使用训练好的CNN细化帧间预测信号。他们发现使用待预测块的上下文可以提高预测质量。类似地,Wang等人[124]也通过CNN喜欢帧间预测信号,其中,CNN的输入包含帧间预测信号,当前块的上下文和帧间预测快的上下文。
C.跨通道预测
\quad 跨通道预测是为了预测不同的两个通道。在YUV格式中,亮度通道(Y)通常在色度通道(U和V)前被编码。因此,可以通过Y预测U,也可以通过Y和U预测V。一种传统的跨通道预测方法被称为线性模型(LM)。LM的核心思想是可以用一个线性函数从亮度预测色度,但不传递色度函数的系数;相反,它们是通过执行线性回归从上下文估计的。线性假设似乎过于简单了。
\quad Baig和Torresani[7]研究了图像压缩的着色。着色是为了从亮度中预测色度,这是一个不适定问题因为一个亮度值可以对应多个色度值。因此,他们提出了一个树形结构的CNN,给定一个灰度图像作为输入,它能够产生多个预测(称为多个假设)。当用于压缩时,经过训练的CNN应用于编码器端,产生最佳预测信号的分支被编码为边信息供解码器使用。他们在不改变亮度编码的情况下,将该方法集成到JPEG中,实验结果表明,该方法在色度编码方面优于JPEG。
\quad Li等人[67]提出了一种和LM类似地跨通道预测方法。他们设计了一个由全连接部分和卷积部分组成的混合神经网络。前者用于处理上下文,包括三个通道,后者用于处理当前块的亮度通道。将两个特征融合在一起得到最终的预测结果。该方法提供超过2%的帧速率进行色度编码,优于LM。
D.概率分布预测
\quad 如前所述,准确的概率估计是熵编码的关键问题,因此,已经开展了许多利用深度学习进行概率分布预测以提高熵编码效率的研究工作,这些工作处理信息的不同部分。例如,每个块的帧内预测模式都需要被传送到解码端,Song等人[106]设计了一种基于上下文的的CNN来预测帧内预测模式的概率分布。类似地,Pfaff等人[94]也基于上下文预测帧内预测模式的概率分布,但是使用的是全连接网络。考虑到如果编码/解码框架允许多种变换,并且每个块可以分配一个变换模式,Puri等人[96]提出了使用CNN预测变换模式的概率分布,该概率分布基于量化的变换系数。在最近的一项研究中,Ma等人[82]考虑了量化变换系数的熵编码,特别是直流系数。他们设计了一个CNN,从块的上下文和块的交流系数来预测一个块的直流系数的概率分布。
E.变换
\quad 变换是混合视频编码框架中的一个重要工具,它将信号(通常是残差)转换为系数,然后进行量化和编码。一开始,视频编码框架采用的是离散余弦变换(DCT),后来被H.264中的整数余弦变换(ICT)所替换。HEVC同样使用ICT,但还另外对4×4亮度块使用整数正弦变换。自适应多重变换和二次变换也被研究。但是,所有这些变换都非常简单。
\quad 受自动编码器的启发,Liu等人[73]提出了一种基于CNN的图像编码方法用于实现DCT样变换。这种变换由一个CNN和一个全连接层组成,其中CNN对输入块进行预处理,全连接层完成变换。在他们的视线中,全连接层由DCT的变换矩阵初始化,然后与CNN一起训练。他们使用联合率失真代价训练网络,其中速率由量化系数的 l 1 − n o r m l_1-norm l1−norm 估计。他们还研究了非对称自动编码,即编码部分和译码部分不对称,这与传统的自动编码器不同。他们的实验结果显示,训练好的变换比固定DCT效果好,非对称自动编码器可以更有效地实现压缩效率和编解码时间的权衡。
F.后置或环内滤波
\quad 目前广泛使用的图像和视频编码方案大多是有损编码方案,即因为压缩而导致的重建图像/视频与原始图像/视频不完全一致。损失通常是量化过程造成的,如图3所示。当量化步长过大,损失就会大,这会导致重建图像/视频中出现可见伪影,如遮挡、模糊、振铃、色差、闪烁等。滤波是减少这些伪影的工具,为了提升重建图像/视频的矢量,从而间接提升压缩效率。对于图像,滤波也被认为后处理,因为它不直接改变编码过程。对于视频,根据滤波后的帧是否作为后续帧的参考帧,滤波被分为环内和环外。HEVC中有两种环内滤波,被称为去块滤波(DF)[91]和样本自适应偏移(SAO)[31]。
\quad 在基于深度学习的图像/视频编码的相关工作中,后或环内滤波占据了大部分:
\quad •图像编码的早期研究关注后置滤波,尤其是JPEG。例如,Dong等人[26]提出了一个4层CNN用于减少压缩伪影,称为ARCNN。当质量因子(QF)在10到40之间时,ARCNN在5个经典测试图像上的PSNR比JPEG提高了1dB以上。Cavigelli等人[16]使用更深的CNN(12层)和分级跳过连接,测试更高的QF(从40到76)。Wang等人[125]利用JPEG压缩的先验知识,即对8×8块的DCT系数进行量化,提出了一种基于双域(像素域和变换域)的方法。与ARCNN相比,它们实现了更高的质量和更短的计算时间。[38]中也研究了双域变换过程。Guo和Chao[39]提出了一个一对多的网络,通过联合感知损失、自然损失和JPEG损失进行训练。[32]中提出了另一个有关损失函数的工作,建议使用类似GAN中的鉴别器损失。Ororbia等人[92]提出了一个使用训练好的RNN进行迭代后滤波的方法。最近,一些研究将JPEG后滤波当作图像恢复任务,例如去噪或超分辨率,并针对一系列图像恢复任务提出了不同的网络[78]、[140]、[142]、[144]。
\quad •后来,越来越多的研究针对视频编码中的环外滤波,尤其是HEVC。Dai等人[24]提出了用于帧内后滤波的4层CNN,其中,CNN具有可变的滤波大小和残差连接,被称为VRCNN。Wang等人[122]对环外滤波使用10层CNN,他们训练一个CNN滤波一张图像并单独对视频帧使用训练好的CNN。Yang等人[138]提出分别对I帧和P帧训练不同的CNN模型,并验证其有效性。Jin等人[50]建议用鉴别器损失代替MSE损失。Li等人[62]提出给解码器传递一些边信息,以便从一组先前训练过的模型中为每一帧选择一个模型。另外,Yang等人[139]提出在后滤波过程中使用帧间图像的相关性,将相邻帧作为CNN的输入来增强帧。Wang等人[123]也考虑帧间图像相关性,但是使用多尺度卷积LSTM。前述工作只将解码帧当作CNN的输入,He等人[41]提出将块分区信息和解码帧一起当作CNN的输入,Kang等人[53]也将块分区信息作为CNN的输入并设计了一种多尺度网络,Ma等人[83]将帧内预测信号和解码残差信号输入CNN,Song等人[107]将QP加解码帧输入CNN(他们还对网络参数进行量化,以确保不同计算平台之间的一致性)。[114]中提出了一种不同的方法,该方法不直接增强解码帧,相反,他们提出在编码端计算压缩残差(即原始视频减去解码视频,来区别预测残差),并训练一个自动编码器来编码压缩残差并将其发送到解码端。据报道,他们的方法在特定领域的视频序列上表现良好,如视频游戏流服务。
\quad •将基于CNN的滤波器集成到编码循环中更具挑战性,因为被被的帧将作为参考帧,这将影响其他编码工具。Park和Kim[93]训练了一个3层CNN作为HEVC的环内滤波器。他们对两个QP范围分别训练了两个模型:20-29和30-39,并根据其QP为每个帧使用一个模型。DF后使用CNN,关闭SAO。他们还设计了两种情况来应用基于CNN的过滤器:在一种情况下,滤波器应用于基于图片顺序计数(POC)的指定帧;在另一种情况下,对每一帧都测试滤波器,如果它能提升质量就使用它,在这种情况下,每一帧都向解码器发送一个二进制标志。Meng等人[85]在HEVC中使用LSTM作为环内滤波器,应用在DF后,SAO前。网络以分块信息为输入对帧进行解码,并结合MS-SSIM损失和MAE损失进行训练。Zhang等人[145]提出了一种残差高速CNN(RHCNN)用于HEVC的环内滤波。基于RHCNN的滤波器用于SAO后。他们分别对I、P、B帧训练不同的RHCNN。他们还将QPs分为几个范围并对每一个范围单独训练一个模型。Dai等人[25]提出了一个被称为 VRCNN-ext 的深度CNN,用于HEVC的环内滤波。他们对I帧和P/B帧设计了不同的策略:对I帧使用基于CNN的滤波器代替DF和SAO,但对于P/B帧,在DF之后和SAO之前,基于CNN的滤波器和CTU级、CU级的控制一起应用。在CTU级,每个CTU标记一个二进制标志用于控制基于CNN的滤波器的开关;如果标记关闭,那么在CU级,使用一个二进制分类器来决定是否对每个CU打开基于CNN的滤波器。Jia等人[46]也考虑了一个用于HEVC的深度CNN。该滤波器被用于SAO之后,由帧级别和CTU级别的标志控制。如果帧级别的标志位是“关闭”,那么相关的CTU级别的标志位就被忽略。另外,他们训练多个CNN模型,并训练了一个内容分析网络,为每个CTU决定一个模型,从而节省选择CNN模型的时间。
G.下采样和上采样
\quad 视频技术的一个发展趋势是在不同维度提高分辨率,例如空间分辨率(即像素数),时间分辨率(即帧率)和像素值分辨率(即位深度)。分辨率的提高导致了数据量的成倍增长,给视频传输系统带来了了巨大的挑战。当传输带宽受限时(例如使用2G或3G移动网络),通常的做法是在编码前降低视频分辨率,解码后提高视频分辨率。这就是所谓的基于下采样和上采样的编码策略。下采样和上采样可以在空间域、时间域、像素值域或这些域的组合中执行。传统下采样和上采样滤波器通常是人工设计的。最近,有人提出训练深度网络作为高效视频编码的上下采样滤波器。相关研究分为两类。
\quad 第一类是只将训练深度网络为上采样过滤器,而仍然使用手工下采样过滤器。这受到了超分辨率启发,例如[27]。以[1]为例,提出了一种空间与像素值下采样相结合的方法,其中空间下采样采用手工制作的低通滤波器,像素值下采样采用按位右移的方法。在编码器端,使用支持向量机来决定是否对每一帧进行下采样。在解码器端,训练好的CNN将解码后的视频上采样到原始分辨率。Li等人[69]只考虑了同样由手工滤波器进行的空间下采样,并训练CNN进行上采样。但与[1]不同的是,他们提出了块自适应分辨率编码(BARC)框架。具体来说,对于帧内的每个块,他们考虑两种编码模式:下采样再编码和直接编码。编码器可以为每个块选择一种模式,并将选择的模式发送给解码器。此外,在下采样编码模式中,他们进一步设计了两种子模式:使用手工制作的简单滤波器进行上采样,使用训练好的CNN进行上采样。子模式也被发送到解码器。Li等人[69]只研究了I帧的BARC。随后,Lin等人[72]将BARC框架扩展到P帧和B帧,构建了完整的基于BARC的视频编码方案。前面的工作是在像素域进行下采样,Liu等[77]提出在残差域进行下采样,即对帧间预测残差进行下采样,然后利用训练好的CNN对残差进行上采样,同时考虑预测信号。他们也遵循BARC框架。
\quad 第二类不仅训练上采样,而且训练下采样过滤器,以提供更大的灵活性。以[47]为例,研究了具有两个CNN的压缩框架。第一个CNN下采样一个图像,下采样后的图像被现有的图像编码器(如JPEG和BPG)压缩,然后解码,第二个CNN上采样解码后的图像。该框架的一个缺点是不能进行端到端的训练,因为图像编码器/解码器是不可微的。为了解决这个问题,Jiang等人[47]决定对两个CNN进行交替优化。与之不同的是,Zhao等人[147]使用一个实际上是CNN的虚拟编解码器来近似地实现编码器/解码器的功能,从而替代编码器/解码器;在上采样CNN之前插入一个CNN进行后处理;他们的方案完全是卷积的并且可以进行端到端的训练。Li等[68]在训练过程中简单地去掉编码器/解码器,只保留两个CNN;考虑到下采样后的图像会被压缩,他们提出了一种新的正则化损失方法进行训练,这要求下采样图像与理想的低通和抽取图像(手工制作的滤波器近似)相差不大。实验结果表明,对于图像编码,使用这种正则化损失训练联合上下采样CNNs是有效的。
H.编码优化
\quad 前述深度工具是为了提高压缩效率而提出的,尤其是为了在相同的PSNR下降低比特率。还有一些针对不同方面的深度工具。在本小节中,我们将回顾几个用于三个不同目标的深度工具:快速编码、码率控制和感兴趣区域(ROI)编码。由于这些工具只在编码器端使用,所以我们称它们为编码优化工具。
\quad 1)快速编码: 在最新的视频编码标准H.264和HEVC中,解码器在计算上很简单,但编码器要复杂得多。这是因为越来越多的编码模式被引入到视频编码标准中,每个块可以被分配一个不同的模式。每个块的模式被发送给解码器,因此解码器只需要计算给定的模式。但为了找到每个块的模式,编码器通常需要比较多个可选模式,并选择最优模式,其中最优性表现在率失真上。因此,如果编码器执行穷举搜索,则压缩效率最高,但计算复杂度也可能很高。任何实际的编码器将采用启发式算法,以寻找更好的模式,此时机器学习特别是深度学习可以提供帮助。
\quad Liu等[79]提出了一种用于HEVC帧内编码的硬件设计,采用经过训练的CNN来帮助确定CU分区模式。具体来说,在HEVC帧内编码中,CTU被递归地分割成CUs,形成一个四叉树结构。他们训练的CNN会根据CU里面的内容和指定的QP来决定是否拆分32×32/16×16/8×8 CU。实际上,这是一个二元决策问题。Xu等[134]还考虑了HEVC帧间编码,提出了提前终止的分级CNN和提前终止的分级LSTM,分别用于I帧和P/B帧来帮助确定CU划分模式。Jin等人[49]也考虑了CU分区模式的决策,但是将其引入VVC而不是HEVC,因为在VVC中,一个四叉树-二叉树(QTBT)结构是为CU分区而设计的,这比HEVC要复杂得多。他们训练一个CNN对32×32的 CU进行了5路分类,不同的分类表示不同的树深度。XU等人[133]研究了H.264转码到HEVC的CU分区模式决策他们设计了一种分层LSTM网络通过从H.264的编码位中提取的特征来预测CU划分模式。
\quad Song等人[105]研究了一种用于HEVC帧内编码器的基于CNN的快速帧内预测模式判定方法。他们训练CNN,根据内容和指定的QP为每个8×8/4×4块推导出最可能的模式列表,然后通过正常的率失真优化过程从列表中选择一个模式。
\quad 2)码率控制: 给定有限的传输带宽,视频编码器试图产生不溢出带宽的比特。这就是所谓的码率控制要求。
\quad 一种传统的码率控制工具是根据 R-λ 模型为不同的块分配比特[61]。在这个模型中,每个块有两个待定参数 α α α 和 β β β。以前,参数是由经验公式估计的。在[66]中,Li等人提出训练一个CNN来预测每个CTU的参数。实验结果表明,该方法具有较高的压缩效率和较低的码率控制误差。
\quad Hu等人[43]尝试利用增强学习方法来控制帧内速率。他们将速率控制问题与强化学习问题进行类比:块的纹理复杂度和位平衡被视为环境状态,量化参数被视为代理需要采取的行动,块的负失真被视为即时的奖励。他们训练一个神经网络作为代理。
\quad 3)ROI编码: ROI是指图像中感兴趣的区域。图像压缩需要ROI的内容具有高质量,不具有ROI的内容可以具有低质量。许多图像编码方案,例如JPEG和JPEG 2000,都支持ROI编码。如何识别ROI是一个研究问题,这个问题通过深度学习的方法得到了解决。Prakash等人[95]提出了一个基于深度学习的方法,生成一个多尺度ROI(MS-ROI)来引导后续的JPEG编码。他们对一张图像使用训练好的图像分类网络,挑选出网络预测的前五类,并识别出与这些类相对应的区域。因此,他们的MS-ROI映射显示了与语义分析相关的显著性区域。
\quad 现在来分析我们开发的DLVC,一个原型视频编解码器。事实上,DLVC是为了响应视频压缩联合的需求而作为一个提案开发的,它的能力超过了HEVC。DLVC源码已发布供后续研究使用。DLVC在JEM软件基础上制作,相比JEM有很多改进,尤其是两个深度编码工具:基于CNN的环内滤波器(CNN-ILF)和基于CNN的块自适应超分辨率编码(CNN-BARC),这两种工具都基于训练好的CNN模型。DLVC方案如图5所示。在这一节中,我们将重点介绍两个深度工具。更多有关DLVC的技术细节可在技术报告[132]中查阅。

图5. DLVC方案说明。蓝色方块代表提出的的CNN-ILF。绿色方块对应的是CNN-BARC。
A.基于CNN的环内滤波器
\quad 如III-F节所述,已经有大量的研究使用训练好的CNN模型进行环后滤波或环内滤波。CNN-ILF代表了我们在这方面的努力。
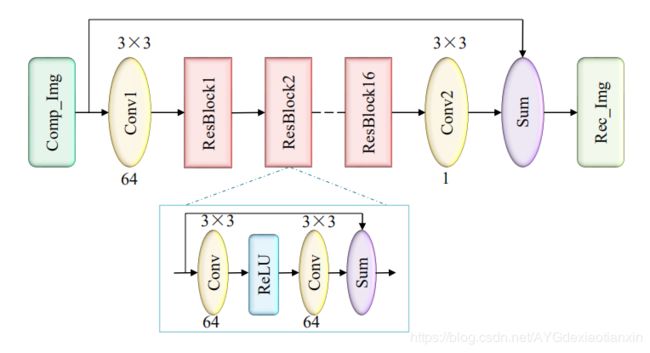
图6. CNN-ILF的网络结构。每个卷积(Conv)层上面和下面的数字分别表示卷积核的大小(如3×3)和输出通道的数量(如64)。
\quad 我们提出的CNN-ILF网络结构如图6所示。受到SR网络[70]的启发,我们设计了一个深度CNN,由16个残差块(ResBlocks)和2个卷积层组成,共34层。每个ResBlock由2个卷积层组成,层之间由ReLU映射和一个跳跃连接分隔。整个网络具有从输入到输出的全局跳跃连接。这些跳跃连接是训练高效网络和加速训练收敛的关键。
\quad 为了训练网络,我们使用了一组自然图像,并在不同的QPs下用DLVC 帧内编码(关闭所有的环内滤波器)对每个图像进行压缩。对于每个QP,我们训练一个单独的模型。我们只使用亮度分量进行训练,但训练后的模型在压缩时用于亮度和色度通道。我们将图像分成70×70个子图像,并对这些子图像进行洗牌,以准备训练数据。损失函数为MSE,即网络输出图像与原始未压缩图像之间的误差。使用随机梯度下降算法训练网络直到收敛。
\quad 我们将训练好的模型应用到DLVC中。在去块滤波后和样本自适应偏移前应用CNN-ILF。不同的QP对应不同的模型,根据框架的QP为每一帧选择一个模型。每个CTU都有两个二进制标志,分别控制着亮度和色度的CNN-ILF的开关。这些标志在编码器端决定并传送到解码器。
B.基于CNN的块自适应分辨率编码
\quad CNN-BARC是一个基于下采样和上采样的编码工具,它使用训练好的CNN模型作为下采样和上采样滤波器。在DLVC中,CNN-BARC仅用于帧内编码。下采样编码或直接编码模式由每个CTU决定,下采样编码模式有两种子模式:使用CNNs做下采样和上采样,使用简单的插值滤波器做下采样和上采样。所有的模式和子模式由编码器决定并向解码器发出信号。

图7. 提出的CNN-BARC的网络结构,包括(a)用于下采样的CNN-DS和(b)用于上采样的CNN-US。注意(a)中的第一个卷积层的步长为2,实现2倍下采样。
\quad 下采样和上采样的网络如图7所示。具体来说,下采样CNN (CNNDS)有10个卷积层,其中第一层的步长为2,实现2倍下采样。CNN-DS也包含了残差学习,但在这里原始图像是双三次下采样后的图像,作为跳跃连接使用。上采样CNN (CNN- us)类似于[70]中的SR网络,它有16个ResBlock、3个卷积层、1个反卷积层和一个全局跳跃连接。
\quad CNN-DS和CNN-US的训练分为四个步骤。首先,我们去除CNN-DS中的卷积层,使其成为简单的双三次下采样,并训练CNN-US最小化端到端MSE(即原始图像与下采样-上采样图像之间的误差)。第二,我们将层重新添加回CNN-DS,修正CNN-US的参数,并对CNN-DS进行训练以最小化端到端MSE。第三,我们同时对CNN-DS和CNN-US的参数进行微调,使用两个损失的组合:一个是端到端MSE,另一个是下采样MSE(即双三次下采样图像与网络下采样图像之间的误差),后者作为正则化项。第四,我们修正了CNN-DS的参数,并在不同的QPs下通过DLVC帧内编码(关闭所有的环内滤波器)对下采样的图像进行压缩。对于每个QP,我们训练一个单独的CNN-US模型。
\quad 在DLVC编码器中有两个关于CNN-BARC的模式选择步骤。第一个决定下采样和上采样(子)模式,第二个决定是否执行下采样。我们比较不同模式的率失真代价来做出决策。率是编码比特数,失真是原始CTUs和重建CTUs之间的MSE。为了公平比较,我们通常在原始分辨率下计算失真。最后一点,也是非常重要的一点,在帧内压缩后,我们再次对下行采样编码的CTUs进行上行采样。关于CNN-BARC的更多细节可以在[68]、[69]中找到。
C.压缩性能
\quad 我们测试了DLVC在JVET推荐的10个视频序列上的压缩性能。这些序列按照空间分辨率分为A类和B类:5个序列具有超高清(3840×2160)分辨率,5个序列具有高清(1920×1080)分辨率。测试了不同的编码配置,包括全帧内(AI)、低延迟(LD)和随机存取(RA)。我们将DLVC与HEVC参考软件 HM 16.16 [ 4 ] ^{[4]} [4]及其变体JEM 7.0 [ 5 ] ^{[5]} [5]进行比较,并使用BD-rate[13]测量相对压缩效率。
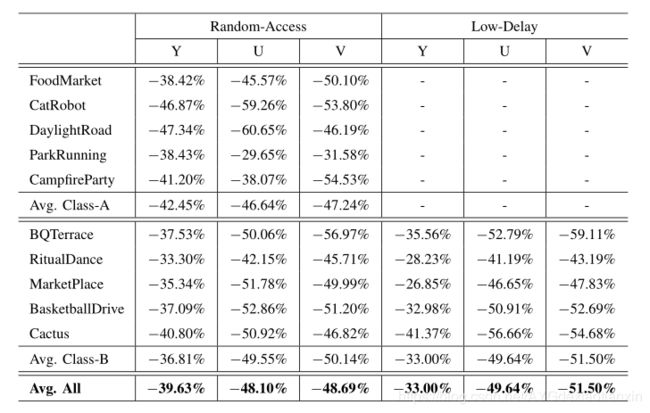
\quad 表II展示了DLVC和HEVC相比的BD-rate结果。显然,DLVC显著提高了压缩效率。考虑Y通道,在RA和LD配置下,相比HEVC,DLVC平均降低了39.6%和33.0%的BD率。结果显示当时用DLVC代替HEVC时,在不降低重建质量的前提下,可以获得超过30%的比特节省。
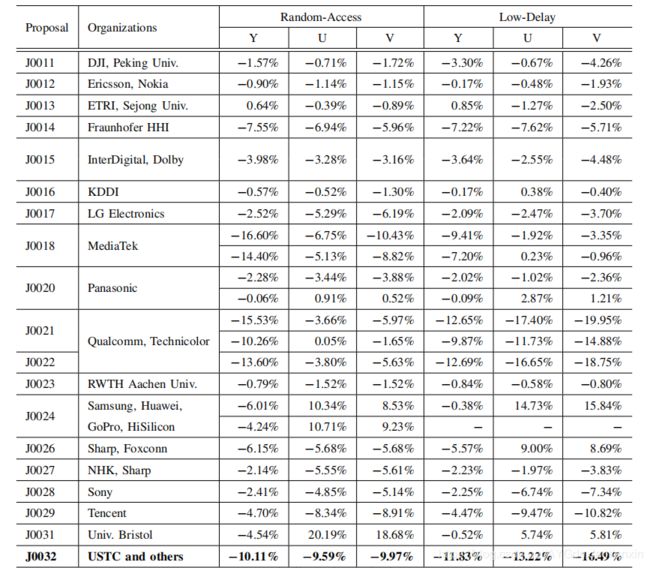
\quad 表III展示了DLVC和JEM相比的BD率结果。比较而言,我们亦包括其他建议的BD率结果,以回应联合征求建议书的要求。考虑Y通道,在RA和LD配置下,DLVC比JEM平均降低了10.1%和11.8%的BD率。从BD率的角度看,DLVC是最好的提案。
http://phenix.it-sudparis.eu/jvet/doc_end_user/current_meeting.php?id_meeting=174&search_id_group=1&search_sub_group=1
\quad 表IV验证了提出的CNN-ILF的有效性。具体来说,我们将HM的一个变体添加到QTBT结构中作为anchor,它的性能优于普通HM。我们将CNN-ILF集成到anchor中,并打开/关闭CNN-ILF进行比较。如图所示,CNN-ILF显著降低了BD率:在RA、LD、AI配置下,Y通道平均降低5.5%、5.2%、6.4%。

\quad 表V验证了提出的CNN-BARC的有效性。我们使用HM的另一种变体作为anchor添加到四叉树-二叉树-三叉树(QTBTTT)结构中,该结构的性能进一步优于HM + QTBT。我们将CNN-BARC整合到anchor中,并打开/关闭CNN-BARC进行比较。如图所示,CNN-BARC在AI配置下实现了显著的BD率降低:Y通道平均降低5.4%。RA和LD配置下的BD率节省不那么显著,因为CNN-BARC仅适用于帧内。
A.开放问题
\quad • 深度方案或深度工具。 我们是雄心勃勃地期待深度方案成为视频编码的未来,还是满足于传统非深度方案中的深度工具?换句话说,深度方案可以完全代替非深度方案吗?现在答案或许是否定的,因为在视频编码领域,深度方案一般不会优于非深度方案。但是随着研究的深入,答案或许通过两种方式变为肯定:第一,深度方案可能会被大大改进并明显击败非深度方案;第二,传统编码方案(如HEVC)中的编码工具可能全部被相应的深度工具所替代,从而产生比以前更好的“深化的”编码方案。根据我们的主观感受,第二种方法可能更实际。我们是雄心勃勃地期待深度方案成为视频编码的未来,还是满足于传统非深度方案中的深度工具?换句话说,深度方案可以完全代替非深度方案吗?现在答案或许是否定的,因为在视频编码领域,深度方案一般不会优于非深度方案。但是随着研究的深入,答案或许通过两种方式变为肯定:第一,深度方案可能会被大大改进并明显击败非深度方案;第二,传统编码方案(如HEVC)中的编码工具可能全部被相应的深度工具所替代,从而产生比以前更好的“深化的”编码方案。根据我们的主观感受,第二种方法可能更实际。
\quad •压缩效率与计算复杂度之比。 将现有的深度工具与传统的非深度方案进行比较,不难发现前者的计算复杂度要远远高于后者。高复杂度实是深度学习的一个普遍问题,也是在计算资源有限的情况下(如移动电话)阻碍深度网络应用的一个关键问题。这个普遍的问题现在在两个方面得到解决:首先,开发新颖、高效、紧凑的,可以保持高性能(即视频编码的压缩效率),但需要更少的计算的深层网络;第二,提倡采用专门为深度网络设计的硬件。
\quad •感知自然度或语义质量的优化。 为自然视频设计的编码方案通常是为人类观看服务的,如电视、电影、微视频。在这些方案中,基于人的感知来评价重建视频的质量是很自然的。然而,在传统的非深度编码方案中,采用最多的质量度量仍然是PSNR,这与人类的感知能力不相符。对于深度方案或深度工具,已经做了一些工作来优化它们的感知自然性,例如使用鉴别器损失。此外,还有一些用于自动语义分析的编码方案,如监视视频编码。对于这些方案,质量度量应该是语义质量[74],这在很大程度上还没有得到探索。特别需要注意的是,我们发现信号保真度、感知自然度和语义质量之间存在权衡[75],这意味着优化目标应该与实际需求保持一致。
\quad •特性和普遍性。 一个极端,一个编码方案能简单地最适合任何类型的视频吗?根据机器学习文献[130]中提出的无免费午餐定理,答案是否定的,该定理也适用于压缩。另一个极端是,我们可以为每个视频设置一个特殊的编码方案吗?这样的编码“策略”是没用的,更不用提实际的困难,因为它只是为每个视频分配一个标识符。介于这两个极端之间的是实用而有用的编码方案。也就是说,编码方案应该具有一定的特殊性和通用性。对于深度方案和深度工具,意味着需要仔细选择训练数据来反映感兴趣的数据域。期待这方面的研究。
\quad •多个深度工具的联合设计。 目前,大多数深度工具都是单独设计的,但是一旦联合应用,它们可能就不能很好地协作,甚至可能相互冲突。其根本原因是多种编码工具确实是相互依赖的。例如,不同的预测工具产生不同的预测,导致残差信号的变化,因此处理残差信号的变换工具的性能也不同。理想情况下,应该以联合方式设计多个深度工具。然而,这可能很困难,因为工具之间的依赖关系很复杂。
B.未来的工作
\quad 在可以预见的未来,对视频编码技术的需求还在不断增长。在娱乐方面,虚拟现实和增强现实应用程序需要处理新数据的技术,如深度地图、点云、3D表面等等。对于监控来说,智能分析的需求推动了视频分辨率的提升。为了科学观测,越来越多的观测仪器直接与录像机相连,产生大量的视频数据。所有这些需求推动了视频编码的发展,以实现更高的压缩效率、更低的计算复杂度和更智能地集成到视频分析系统中。我们相信基于深度学习的视频编码技术对于这些具有挑战性的目标是有前途的。特别是,我们期待一个基于深度网络的整体框架,集成图像/视频采集、编码、处理、分析和理解,真正模仿人类视觉系统。
\quad 本研究由国家自然科学基金61772483资助。作者要感谢以下同事和合作者: Jizheng Xu, Bin Li, Zhibo Chen, Li Li, Fangdong Chen, Yuanying Dai, Changsheng Gao, Lei Guo, Shuai Huo, Ye Li, Kang Liu, Changyue Ma, Haichuan Ma, Rui Song, Yefei Wang, Ning Yan, Kun Yang, Qingyu Zhang, Zhenxin Zhang, and Haitao Yang.