系统学习机器学习之增强学习(三)--马尔可夫决策过程策略DP求解及参数估计
1. 值迭代和策略迭代法
上节系统学习机器学习之增强学习(二)--马尔可夫决策过程我们给出了迭代公式和优化目标,这节讨论两种求解有限状态MDP具体策略的有效算法。这里,我们只针对MDP是有限状态、有限动作的情况, 。
。
* 值迭代法
| 1、 将每一个s的V(s)初始化为0 2、 循环直到收敛 { 对于每一个状态s,对V(s)做更新
} |

值迭代策略利用了上节中公式(2)
内循环的实现有两种策略:
1、 同步迭代法
拿初始化后的第一次迭代来说吧,初始状态所有的V(s)都为0。然后对所有的s都计算新的V(s)=R(s)+0=R(s)。在计算每一个状态时,得到新的V(s)后,先存下来,不立即更新。待所有的s的新值V(s)都计算完毕后,再统一更新。
这样,第一次迭代后,V(s)=R(s)。
2、 异步迭代法
与同步迭代对应的就是异步迭代了,对每一个状态s,得到新的V(s)后,不存储,直接更新。这样,第一次迭代后,大部分V(s)>R(s)。
不管使用这两种的哪一种,最终V(s)会收敛到V*(s)。知道了V*后,我们再使用公式(3)来求出相应的最优策略![clip_image069[4]](http://img.e-com-net.com/image/info8/c894f2613f57438cae18514a187370fa.png) ,当然
,当然![clip_image069[5]](http://img.e-com-net.com/image/info8/2b7a4aac68204edfb1081ab5397ccd25.png) 可以在求V*的过程中求出。
可以在求V*的过程中求出。
* 策略迭代法
值迭代法使V值收敛到V*,而策略迭代法关注![clip_image062[4]](http://img.e-com-net.com/image/info8/5c916ead8bc146f688ad4612ec88d213.png) ,使
,使![clip_image062[5]](http://img.e-com-net.com/image/info8/6c7dc1eda3ec43acb6d6f85126630b84.png) 收敛到
收敛到![clip_image069[6]](http://img.e-com-net.com/image/info8/048d0dc3d68a4975ae94dcc403216345.png) 。
。
| 1、 将随机指定一个S到A的映射 2、 循环直到收敛 { (a) 令 (b) 对于每一个状态s,对
} |
![clip_image062[6]](http://img.e-com-net.com/image/info8/2fd0794e25154a598289cfae87615a5d.png) 。
。
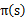 做更新
做更新
(a)步中的V可以通过之前的Bellman等式求得
![clip_image054[1]](http://img.e-com-net.com/image/info8/2ba65c5447fc4b89a6fb90e75e804eb9.jpg)
这一步会求出所有状态s的 。
。
(b)步实际上就是根据(a)步的结果挑选出当前状态s下,最优的a,然后对![clip_image080[1]](http://img.e-com-net.com/image/info8/d782017734c648e2afd5f1468b7d26f9.png) 做更新。
做更新。
对于值迭代和策略迭代很难说哪种方法好,哪种不好。对于规模比较小的MDP来说,策略一般能够更快地收敛。但是对于规模很大(状态很多)的MDP来说,值迭代比较容易(不用求线性方程组)。
2. MDP中的参数估计
在之前讨论的MDP中,我们是已知状态转移概率![clip_image004[3]](http://img.e-com-net.com/image/info8/c11db506ed2243dd829e5e4c2db4dc91.png) 和回报函数R(s)的。但在很多实际问题中,这些参数不能显式得到,我们需要从数据中估计出这些参数(通常S、A和
和回报函数R(s)的。但在很多实际问题中,这些参数不能显式得到,我们需要从数据中估计出这些参数(通常S、A和 是已知的)。
是已知的)。
假设我们已知很多条状态转移路径如下:

其中, 是i时刻,第j条转移路径对应的状态,
是i时刻,第j条转移路径对应的状态, 是
是![clip_image089[1]](http://img.e-com-net.com/image/info8/87763b0bd61e4ba9ae4ccc9b6b0f7dec.png) 状态时要执行的动作。每个转移路径中状态数是有限的,在实际操作过程中,每个转移链要么进入终结状态,要么达到规定的步数就会终结。
状态时要执行的动作。每个转移路径中状态数是有限的,在实际操作过程中,每个转移链要么进入终结状态,要么达到规定的步数就会终结。
如果我们获得了很多上面类似的转移链(相当于有了样本),那么我们就可以使用最大似然估计来估计状态转移概率。

分子是从s状态执行动作a后到达s’的次数,分母是在状态s时,执行a的次数。两者相除就是在s状态下执行a后,会转移到s’的概率。
为了避免分母为0的情况,我们需要做平滑。如果分母为0,则令 ,也就是说当样本中没有出现过在s状态下执行a的样例时,我们认为转移概率均分。
,也就是说当样本中没有出现过在s状态下执行a的样例时,我们认为转移概率均分。
上面这种估计方法是从历史数据中估计,这个公式同样适用于在线更新。比如我们新得到了一些转移路径,那么对上面的公式进行分子分母的修正(加上新得到的count)即可。修正过后,转移概率有所改变,按照改变后的概率,可能出现更多的新的转移路径,这样![clip_image004[4]](http://img.e-com-net.com/image/info8/e74c57f4c554402799a7bf1f2922eb0a.png) 会越来越准。
会越来越准。
同样,如果回报函数未知,那么我们认为R(s)为在s状态下已经观测到的回报均值。
当转移概率和回报函数估计出之后,我们可以使用值迭代或者策略迭代来解决MDP问题。比如,我们将参数估计和值迭代结合起来(在不知道状态转移概率情况下)的流程如下:
| 1、 随机初始化 2、 循环直到收敛 { (a) 在样本上统计 (b) 使用估计到的参数来更新V(使用上节的值迭代方法) (c) 根据更新的V来重新得出 } |
![clip_image038[9]](http://img.e-com-net.com/image/info8/88f65bde17d540739b6cef8e4f3e18d8.png)
![clip_image038[10]](http://img.e-com-net.com/image/info8/724d0d6b28994a369a27911cb6a3d615.png) 中每个状态转移次数,用来更新
中每个状态转移次数,用来更新![clip_image004[5]](http://img.e-com-net.com/image/info8/9feceda970e842bdbb5b74af8c111250.png) 和R
和R![clip_image038[11]](http://img.e-com-net.com/image/info8/2be628ca86334cffa8d23fa0b60f4a1d.png)
在(b)步中我们要做值更新,也是一个循环迭代的过程,在上节中,我们通过将V初始化为0,然后进行迭代来求解V。嵌套到上面的过程后,如果每次初始化V为0,然后迭代更新,就会很慢。一个加快速度的方法是每次将V初始化为上一次大循环中得到的V。也就是说V的初值衔接了上次的结果。
3.连续状态的MDP
之前我们的状态都是离散的,如果状态是连续的,下面将用一个例子来予以说明,这个例子就是inverted pendulum问题,也就是一个铁轨小车上有一个长杆,要用计算机来让它保持平衡(其实就是我们平时玩杆子,放在手上让它一直保持竖直状态),这个问题需要的状态有:都是real的值
x(在铁轨上的位置)
theta(杆的角度)
x’(铁轨上的速度)
thata'(角速度)
/////////////////离散化///////////////////////////
也就是把连续的值分成多个区间,这是很自然的一个想法,比如一个二维的连续区间可以分成如下的离散值:

但是这样做的效果并不好,因为用一个离散的去表示连续空间毕竟是有限的离散值。
离散值不好的另一个原因是因为curse of dimension(维度灾难),因为连续值离散值后会有多个离散值,这样如果维度很大就会造成有非常多状态
从而使需要更多计算,这是随着dimension以指数增长的
//////////////////////simulator方法///////////////////////////////
也就是说假设我们有一个simulator,输入一个状态s和一个操作a可以输出下一个状态,并且下一个状态是服从MDP中的概率Psa的分布,即:

这样我们就把状态变成连续的了,但是如何得到这样一个simulator呢?
①:根据客观事实
比如说上面的inverted pendulum问题,action就是作用在小车上的水平力,根据物理上的知识,完全可以解出这个加速度对状态的影响
也就是算出该力对于小车的水平加速度和杆的角加速度,再去一个比较小的时间间隔,就可以得到S(t+1)了
②:学习一个simulator
这个部分,首先你可以自己尝试控制小车,得到一系列的数据,假设力是线性的或者非线性的,将S(t+1)看作关于S(t)和a(t)的一个函数
得到这些数据之后,你可以通过一个supervised learning来得到这个函数,其实就是得到了simulator了。
比如我们假设这是一个线性的函数:
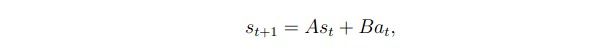
在inverted pendulum问题中,A就是一个4*4的矩阵,B就是一个4维向量,再加上一点噪音,就变成了:其中噪音服从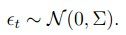

我们的任务就是要学习到A和B
(这里只是假设线性的,更具体的,如果我们假设是非线性的,比如说加一个feature是速度和角速度的乘积,或者平方,或者其他,上式还可以写作:)
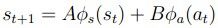
这样就是非线性的了,我们的任务就是得到A和B,用一个supervised learning分别拟合每个参数就可以了
4.连续状态中得Value(Q)函数
这里介绍了一个fitted value(Q) iteration的算法
在之前我们的value iteration算法中,我们有:
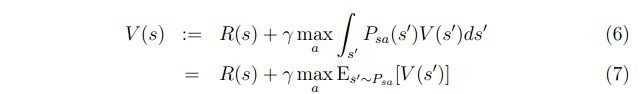
这里使用了期望的定义而转化。fitted value(Q) iteration算法的主要思想就是用一个参数去逼近右边的这个式子
也就是说:令
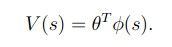
其中 是一些基于s的参数,我们需要去得到系数
是一些基于s的参数,我们需要去得到系数 的值,先给出算法步骤再一步步解释吧:
的值,先给出算法步骤再一步步解释吧:

算法步骤其实很简单,最主要的其实就是他的思想:
在对于action的那个循环里,我们尝试得到这个action所对应的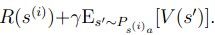 ,记作q(a)
,记作q(a)
这里的q(a)都是对应第i个样例的情况
然后i=1……m的那个循环是得到是最优的action对应的Value值,记作y(i),然后用y(i)拿去做supervised learning,大概就是这样一个思路
至于reward函数就比较简单了,比如说在inverted pendulum问题中,杆子比较直立就是给高reward,这个可以很直观地从状态得到衡量奖励的方法
在有了之上的东西之后,我们就可以去算我们的policy了: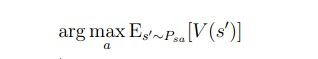
5.确定性的模型
上面讲的连续状态的算法其实是针对一个非确定性的模型,即一个动作可能到达多个状态,有P在影响到达哪个状态
如果在一个确定性模型中,其实是一个简化的问题,得到的样例简化了,计算也简化了
也就是说一个对于一个状态和一个动作,只能到达另一个状态,而不是多个,特例就不细讲了
6.控制MDP算法
前面重点讲的都是每个状态有个明确的奖励,并且没有时间的限制。但是在这里开始,我们的策略是有时间限制的,因此,我们的奖励最大值的计算,在到达时间T的时候就已经终结了。
开始讲了如何求解含有T时间的策略方程。知道V*(T)是容易的,然后通过逆推的动态规划函数就可以解出。但是,有时间的策略方程,因为是有关于st和s(t+1)之间关系的,因此,也需要进行线性拟合,这个在之前已经讲过,这里不再赘述。有s(t+1)=As(t)+Balpha(t)。但是,这里的逆推在一些特殊情况下将会有非常高的效率。
1.reward函数的选取,假设可以表示为Rt+1(st,at)=-st'utst-at'vtat的形式等等,那么最终,可以迅速通过公式得到时间t状态下应该对应的策略。
实际上,就是假设:
,其中噪声项服从高斯分布,不是很重要。
但同时假设了边界时间,二次奖励函数。
7.动态规划
上一篇我们已经说到了,增强学习的目的就是求解马尔可夫决策过程(MDP)的最优策略,使其在任意初始状态下,都能获得最大的Vπ值。(本文不考虑非马尔可夫环境和不完全可观测马尔可夫决策过程(POMDP)中的增强学习)。
那么如何求解最优策略呢?基本的解法有三种:
动态规划法(dynamic programming methods)
蒙特卡罗方法(Monte Carlo methods)
时间差分法(temporal difference)。
动态规划法是其中最基本的算法,也是理解后续算法的基础,因此本文先介绍动态规划法求解MDP。本文假设拥有MDP模型M=(S, A, Psa, R)的完整知识。
1. 贝尔曼方程(Bellman Equation)
上一篇我们得到了Vπ和Qπ的表达式,并且写成了如下的形式

在动态规划中,上面两个式子称为贝尔曼方程,它表明了当前状态的值函数与下个状态的值函数的关系。
优化目标π*可以表示为:![]()
分别记最优策略π*对应的状态值函数和行为值函数为V*(s)和Q*(s, a),由它们的定义容易知道,V*(s)和Q*(s, a)存在如下关系:![]()
状态值函数和行为值函数分别满足如下贝尔曼最优性方程(Bellman optimality equation):


有了贝尔曼方程和贝尔曼最优性方程后,我们就可以用动态规划来求解MDP了。
2. 策略估计(Policy Evaluation)
首先,对于任意的策略π,我们如何计算其状态值函数Vπ(s)?这个问题被称作策略估计,
前面讲到对于确定性策略,值函数![]()
现在扩展到更一般的情况,如果在某策略π下,π(s)对应的动作a有多种可能,每种可能记为π(a|s),则状态值函数定义如下:
![]()
一般采用迭代的方法更新状态值函数,首先将所有Vπ(s)的初值赋为0(其他状态也可以赋为任意值,不过吸收态必须赋0值),然后采用如下式子更新所有状态s的值函数(第k+1次迭代):
![]()
对于Vπ(s),有两种更新方法,
第一种:将第k次迭代的各状态值函数[Vk(s1),Vk(s2),Vk(s3)..]保存在一个数组中,第k+1次的Vπ(s)采用第k次的Vπ(s')来计算,并将结果保存在第二个数组中。
第二种:即仅用一个数组保存各状态值函数,每当得到一个新值,就将旧的值覆盖,形如[Vk+1(s1),Vk+1(s2),Vk(s3)..],第k+1次迭代的Vπ(s)可能用到第k+1次迭代得到的Vπ(s')。
通常情况下,我们采用第二种方法更新数据,因为它及时利用了新值,能更快的收敛。整个策略估计算法如下图所示:

3. 策略改进(Policy Improvement)
上一节中进行策略估计的目的,是为了寻找更好的策略,这个过程叫做策略改进(Policy Improvement)。
假设我们有一个策略π,并且确定了它的所有状态的值函数Vπ(s)。对于某状态s,有动作a0=π(s)。 那么如果我们在状态s下不采用动作a0,而采用其他动作a≠π(s)是否会更好呢?要判断好坏就需要我们计算行为值函数Qπ(s,a),公式我们前面已经说过:
![]()
评判标准是:Qπ(s,a)是否大于Vπ(s)。如果Qπ(s,a)> Vπ(s),那么至少说明新策略【仅在状态s下采用动作a,其他状态下遵循策略π】比旧策略【所有状态下都遵循策略π】整体上要更好。
策略改进定理(policy improvement theorem):π和π'是两个确定的策略,如果对所有状态s∈S有Qπ(s,π'(s))≥Vπ(s),那么策略π'必然比策略π更好,或者至少一样好。其中的不等式等价于Vπ'(s)≥Vπ(s)。
有了在某状态s上改进策略的方法和策略改进定理,我们可以遍历所有状态和所有可能的动作a,并采用贪心策略来获得新策略π'。即对所有的s∈S, 采用下式更新策略:

这种采用关于值函数的贪心策略获得新策略,改进旧策略的过程,称为策略改进(Policy Improvement)
最后大家可能会疑惑,贪心策略能否收敛到最优策略,这里我们假设策略改进过程已经收敛,即对所有的s,Vπ'(s)等于Vπ(s)。那么根据上面的策略更新的式子,可以知道对于所有的s∈S下式成立:

可是这个式子正好就是我们在1中所说的Bellman optimality equation,所以π和π'都必然是最优策略!神奇吧!
4. 策略迭代(Policy Iteration)
策略迭代算法就是上面两节内容的组合。假设我们有一个策略π,那么我们可以用policy evaluation获得它的值函数Vπ(s),然后根据policy improvement得到更好的策略π',接着再计算Vπ'(s),再获得更好的策略π'',整个过程顺序进行如下图所示:
![]()
完整的算法如下图所示:

5. 值迭代(Value Iteration)
从上面我们可以看到,策略迭代算法包含了一个策略估计的过程,而策略估计则需要扫描(sweep)所有的状态若干次,其中巨大的计算量直接影响了策略迭代算法的效率。我们必须要获得精确的Vπ值吗?事实上不必,有几种方法可以在保证算法收敛的情况下,缩短策略估计的过程。
值迭代(Value Iteration)就是其中非常重要的一种。它的每次迭代只扫描(sweep)了每个状态一次。值迭代的每次迭代对所有的s∈S按照下列公式更新:

即在值迭代的第k+1次迭代时,直接将能获得的最大的Vπ(s)值赋给Vk+1。值迭代算法直接用可能转到的下一步s'的V(s')来更新当前的V(s),算法甚至都不需要存储策略π。而实际上这种更新方式同时却改变了策略πk和V(s)的估值Vk(s)。 直到算法结束后,我们再通过V值来获得最优的π。
此外,值迭代还可以理解成是采用迭代的方式逼近1中所示的贝尔曼最优方程。
值迭代完整的算法如图所示:

由上面的算法可知,值迭代的最后一步,我们才根据V*(s),获得最优策略π*。
一般来说值迭代和策略迭代都需要经过无数轮迭代才能精确的收敛到V*和π*, 而实践中,我们往往设定一个阈值来作为中止条件,即当Vπ(s)值改变很小时,我们就近似的认为获得了最优策略。在折扣回报的有限MDP(discounted finite MDPs)中,进过有限次迭代,两种算法都能收敛到最优策略π*。
至此我们了解了马尔可夫决策过程的动态规划解法,动态规划的优点在于它有很好的数学上的解释,但是动态要求一个完全已知的环境模型,这在现实中是很难做到的。另外,当状态数量较大的时候,动态规划法的效率也将是一个问题。下一篇介绍蒙特卡罗方法,它的优点在于不需要完整的环境模型。
PS: 如果什么没讲清楚的地方,欢迎提出,我会补充说明...
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction , 1998
[2] 徐昕,增强学习及其在移动机器人导航与控制中的应用研究[D],2002