CNN(Convolutional Neural Networks)学习总结
刚开始学习cnn,把前段时间看cnn相关的内容,今天稍微的总结下。在文章中差漏的地方,还望见谅。权当做交流。
文章开头先推荐一个网址:
https://github.com/BVLC/caffe/wiki/Model-Zoo
罗列了主流会议,近年来cnn上的相关进展和各种model,感兴趣的可以拿来阅读一番。
**
Cnn几篇重要的论文
**
Lenet-5 :Yann LeCun等在1998年发布的论文”Gradient-based learning applied to document recognition(Yan)” 不过当时并没有流行开来。
Alexnet:真正将cnn流行开来的是,Alex Krizhevsky等人在2012年发布的论文:Imagenet classification with deep convolutional neural networks. 在imagenet比赛上,将Top5错误率由26%大幅降低至15%。
VGG:基于alexnet,牛津大学 visual geometry group(VGG)Karen Simonyan 和Andrew Zisserman 于14年撰写的论文” Very Deep Convolutional Networks for Large-Scale Image Recognition”,主要探讨了深度对于网络的重要性;并建立了一个19层的深度网络获得了很好的结果;在ILSVRC上定位第一,分类第二。
GoogLeNet:Christian Szegedy等人针对ImageNet2014的比赛,撰写了” Going deeper with convolutions”,该论文中的方法是2014年比赛的第一名,包括task1分类任务和task2检测任务。
此外最近还有以下几篇论文,都从不同角度对cnn进行了探索。
Inception V2: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V3: Rethinking the Inception Architecture for Computer Vision
Residual Network: Deep Residual Learning for Image Recognition
**
Cnn基本结构[1]:
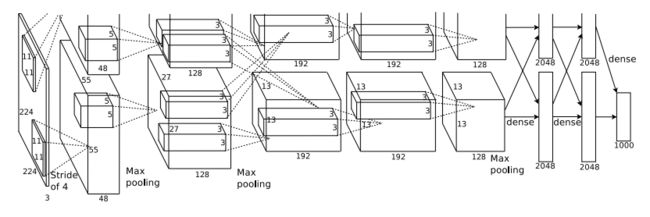
图中是alexnet的基本框架,网上也有很多介绍,在此只谈谈自己的理解:
和传统的神经网络相比,cnn的隐藏层一般有三类:卷积层,池化层,全连接层。
**
卷积层:
**
输入:上一个相邻层的输出。对于图片而言,就是一个个像素值,可以看做一维(其实也是二维只不过用一维表示)或者二维的向量。
卷积操作:
先上图有个直观的印象:
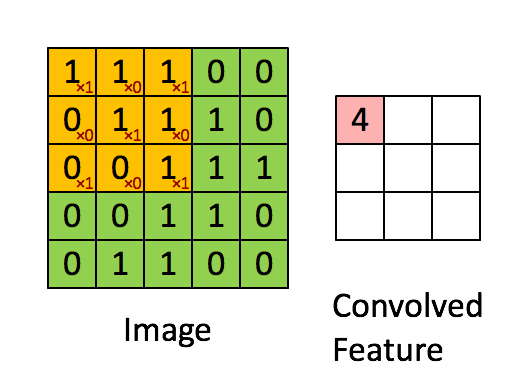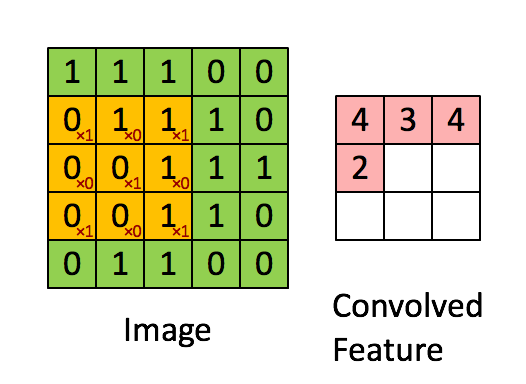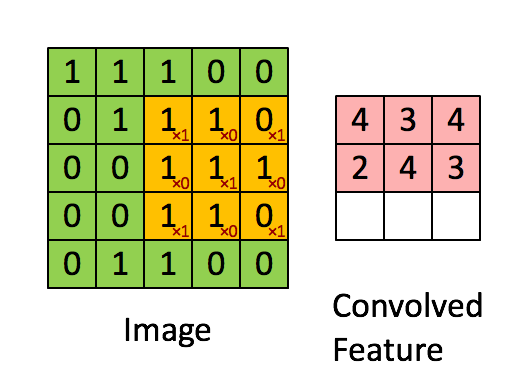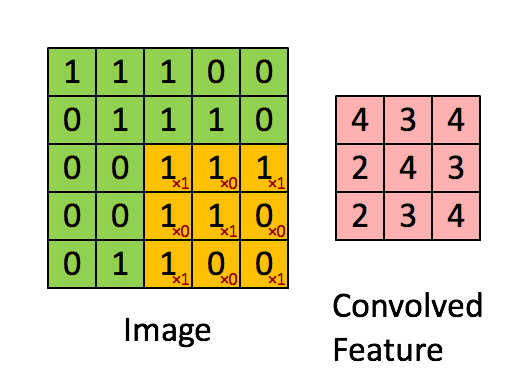
其实,就是通过对每一个输入(一个二维向量(其实是实际操作是一维)),固定size的区域,进行乘以权值加偏移量线性求和,类似于线性回归。
y=wx+b
输出:
然后相当于用这样一个size按一定stride遍历一遍这个输入的每一维数值,分别做线性求和操作得到一个值,最后合起来得到输出,即一个二维的向量(其实用一维表示)。
此外更细节的你需要了解一些额外名词:
Filter:就是图1或图2中固定size的区域,实际上就是一个固定大小的权值向量。训练也是要学习这个权值向量。一个filter,学习到的便是一个feature。可以用多个filter,来学习多个feature。
权值共享:因为对于每个filter,遍历每个输入向量的每一维时,相乘的都是同样一个固定大小的权值向量。因此权值共享。为了减少参数,不然要学习的参数会很庞大。
Size: filter的大小
Stride:每次filter计算后,位移的长度,影响取样的数量;
对于每次移动后,移动到边界的处理:[2]
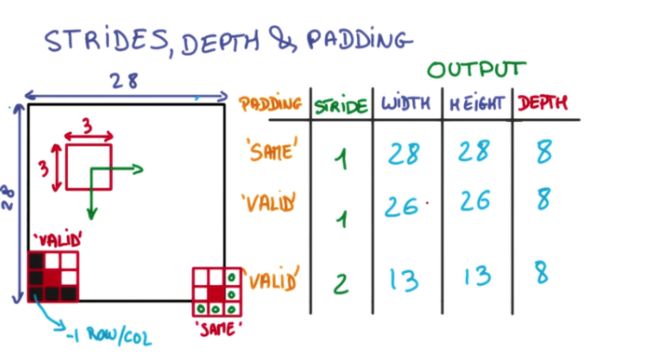
• 用一个3x3的网格在一个28x28的图像上做切片并移动
• 移动到边缘上的时候,如果不超出边缘,3x3的中心就到不了边界
• 因此得到的内容就会缺乏边界的一圈像素点,只能得到26x26的结果
• 而可以越过边界的情况下,就可以让3x3的中心到达边界的像素点
• 超出部分的矩阵补零就行
激活函数:采用ReLu,为什么不用其他的如sigmod等,是因为Relu学习效率更高,详见alexnet论文。
**
池化层(pooling层)
**
目的:是为了减少参数,加速运算。
输入:上一层(一般是卷积层)的输出,即一个二维向量。
池化操作:
先看一下两种不同的pooling,直观理解:
max-pooling:
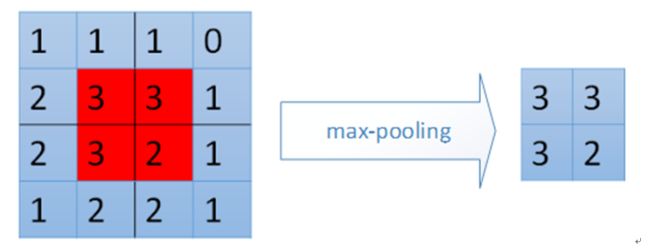
mean-pooling:

即对输入固定区域的最大值(max-pooling)或者平均值(mean-pooling)作为输出。来减少参数,复杂度,提高效率。
其实就是聚类,然后把相似的整合,来减小规模,只不过对于输入而言(一般是图片)由于相近位置像素大小都是相近的,因此已经聚类好了,不需要其他聚类操作。而对于相邻位置没有太大关系的输入而言,可以相对其进行聚类,聚为同一类的再进行池化操作。
**
全连接层:
**
和一般的神经网络一样的操作,此处不做过多称述。
**
Dropout层
**
在输出层前,一般还有一个dropout层:简单讲就是将前一层的输出,以一定概率人为的设置成0,这样的话,使得整个网络更加的复杂,不容易产生过拟合。
**
输出层:
**
不同的任务有不同的函数处理。对于一般的分类任务,都是softmax层(不清楚softmax的可以移步到博主另一篇介绍softmax的)
**
学习算法:
**
和BP一样,就是梯度下降算法。
但是对于损失函数,一般实现上,都不采用方差损失函数,而是采用交叉熵的形式。原因是因为,方差形式的损失函数在初期学习效率太低,导致w和b更新过慢,而交叉熵在误差较大时更新较快。详见[3 ]
这样一个基本的cnn框架就搭好了。不过需要注意的是:目前cnn是主要针对结构化,规则的数据比如图片等进行操作,而对于非规则数据,还需一定的变化。博主准备在后续的文章,进行介绍。
参考:
[1] Imagenet classification with deep convolutional neural networks
[2] http://www.cnblogs.com/hellocwh/p/5564568.html
[3] http://blog.csdn.net/u012162613/article/details/44239919]