Win10下yolov5配置+训练自己的数据集
Win10下yolov5配置+训练自己的数据集
本人的电脑配置:
CPU:i7-8700k
GPU:GTX-1080ti
操作系统:Windows 10 专业版 64bit
CUDA:10.1
CUDNN:7.4
OenpCV:3.3
pyTorch:1.5
Python:3.7
ps:原理精讲以及配置参数、训练参数后续上传,目前可看本人录制的yolov3的视频讲解教程
https://www.bilibili.com/video/av53025521
首先我们先膜拜一下U佬在v4出了不久就更新v5
link:项目工程地址
在windows10和ubuntu下都可以进行训练,现在将如何训练自己的数据进行一个简单的说明
Step1:准备自己的数据
通常我们训练有voc格式的数据(pic.png–pic.xml),也就是有images文件夹存放我们所有训练的图片,Annotations文件夹存放我们训练图片对应的xml标注文件
PS:如何确保自己的数据和xml数据准确请参考之前的yolov3训练自己的数据集内容
通过first.py后将数据集按照(如20%验证集+80%训练集)进行分配,会在Main中生成train.txt和val.txt的文件,代码如下
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
#xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
然后运行voc_label.py,将训练集、验证集、测试集生成label标签(我们训练中用到的),同时将数据集路径导入txt文件中
voc_label.py代码如下(也可去本人资源包下载)
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2020','train'),('2020','test'),('2020','val')]
classes = ["armor","cannon","missile","tank","truck"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('Annotations/%s.xml' %(image_id))
out_file = open('labels/%s.txt' %(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
#if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('JPEGImages/%s.png\n'%(image_id))
convert_annotation(year, image_id)
list_file.close()
运行后会生成如下三个包含数据集的txt文件,训练代码就是通过txt中的路径去读取图片
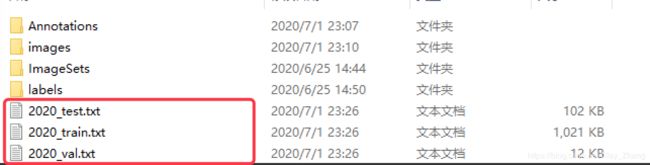
在生成的数据集路径中,显示如下(有时候会报路径错误,实在不行就全路径(粗暴))
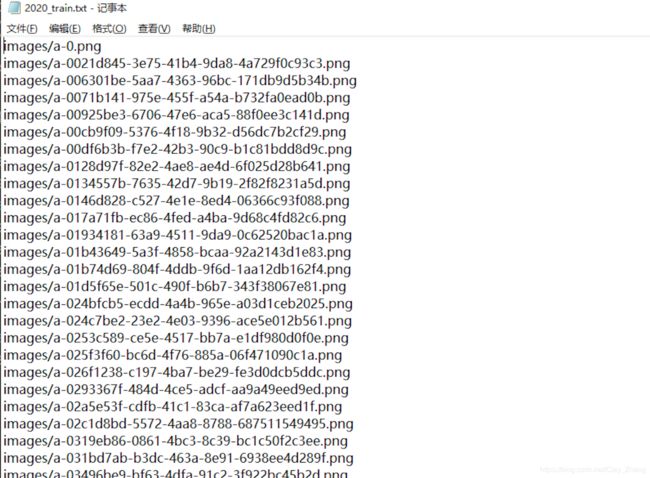
同时会在labels文件夹中生成同名的txt文件,每一个txt中包含了该图像所包含的类名,xmin,xmax,ymin,ymax,共5列的数据
Step2:修改配置文件
在准备完数据后,v5创新性的省略了.data和.names文件的配置,而是将二者合二为一到yaml中
首先是在data文件夹下新建一个数据集的yaml文件如下内容

此时data目录结构就是

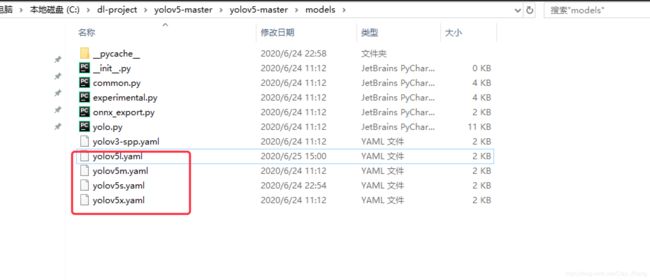
然后回到根目录,找到model文件夹,根据你训练的模型去修改配置,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大)
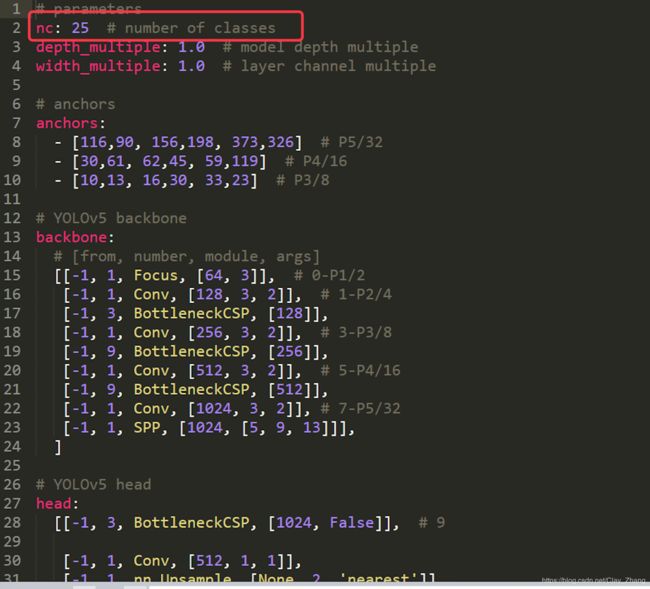
内容的话只需要修改一下类的数量即可
Step3:准备训练
首先可以在google云盘上下载一下作者提供的不同模型的预训练模型,存放到weights文件夹内
然后在train.py中修改一下训练参数,也可以直接在训练语句中重写
然后就在命令行输入训练指令吧
![]()
在这里指定你的配置文件,batchsize和输入图片的尺度、预训练模型等,然后就开始读取数据进行训练了!

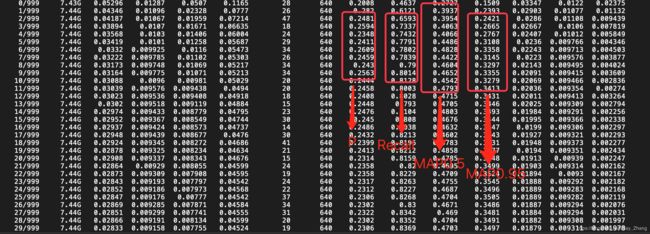
训练完成后,在result中会生成历史数据,P,R、MAP0.5和MAP0.95
后续将会上v5结构原理的讲解,尽请关注,有问题可以私信我~在过程中也陆续有问题发生,可能你们遇到的也是我遇到的,这边就没有记录了