Java 中的集合框架
一、什么是集合?
什么是集合(Collection)呢?集合就是由若干个确定的元素所构成的整体,它是一个容器。集合是 Java 中最最重要的一部分,使用频率非常高。
在前面我们其实已经接触过 Java 中的容器了,比如 StringBuffer、数组。
那为什么会出现集合类呢?
我们知道,面向对象的语言对事物的体现都是以对象的形式来呈现的。虽然数组也可以存储对象,但是数组的长度是固定的,并且只能按索引顺序存取,所以,数组不一定能满足我们的需求,更加无法适应变化的需求。
所以为了方便存储对象、对多个对象进行操作,就出现了集合类。集合类的特点就是:提供一种存储空间可变的存储模型,存储的数据容量可以发生改变。
二、集合框架的层次结构
集合容器因为内部的数据结构不同,也就有了不同的具体容器;然后经过不断地向上抽取,就形成了集合框架(collection framework)。
在向上抽取的过程中,因为数据的结构不同,所以就出现了两个不同的顶层接口:Collection 接口和 Map 接口。
Java 中的集合框架的所有类和接口都包含在 java.util 包中。
1、Collection 接口
在 Collection 的接口的分支下,Java 又通过 Set、 List 和 Queue 接口进行扩展,然后在这三个分支中还有大量的其他类。
注意一个区别:
Collection是个java.util下的接口,它是各种集合框架中的一个父接口;Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
下面看看集合框架中基于 Collection 接口的结构层次:
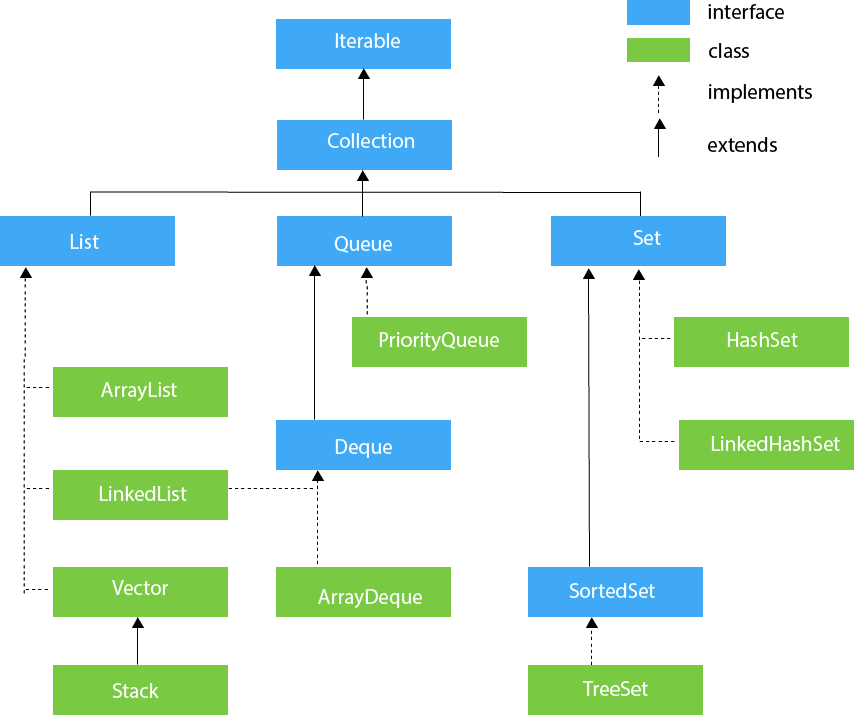
在 Collection 接口中声明了许多方法,具体方法及作用可以在 Collection 接口中查看。
上图中,我们发现 Collection 接口的上方还有一个 Iterable 接口,Iterable 接口是 java 集合框架的顶级接口,它的作用就是提供了统一的语法进行集合对象(Collection)遍历操作。
2、Map 接口
Map 接口提供了一种映射关系,所有的元素都是以键值对的方式存储的,所以能够根据 key 快速查找 value,key 是映射关系的索引,value 是 key 所指向的对象。
Map 接口中,它有两个接口用于实现 :Map 和 SortedMap 接口,以及三个类: HashMap、 LinkedHashMap 和 TreeMap。Java 中 Map 分支下的层次结构如下:
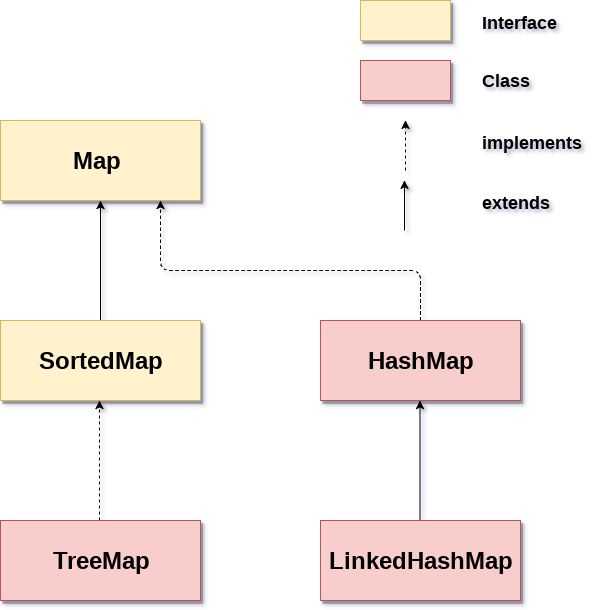
Collection 接口和 Map 接口之间并不是完全独立的,也有一些联系,用来创建一个其他的数据结构,稍后会讲到。
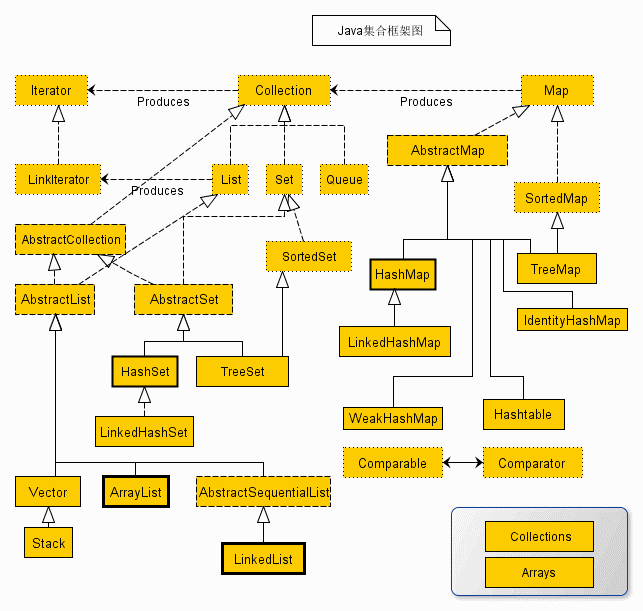
下面我们来具体看看集合框架中的一些常见的类。
三、List
List 接口是 Collection 接口的子接口。
1、ArrayList
ArrayList 是 Java 中我们最常使用的 List 接口的实现类,是基于 Array 的数据结构。
我们都知道数组的限制是它有一个固定的长度,所以如果数组已满,就不能再添加任何元素。而 ArrayList 是 List 接口的可调整大小的数组实现,可以在添加和删除元素后动态增长和缩小长度,所以,我们也不用在声明的时候指定大小。ArrayList 使用起来比 Array 更加方便。
1)创建 ArrayList
ArrayList<String> arrList=new ArrayList<String>();
ArrayList<Integer> list = new ArrayList<Integer>();
2)添加元素
ArrayList<String> fruits = new ArrayList<String>();
fruits.add("Apple"); // 添加元素
fruits.add("Banana");
fruits.add(1,"Strawberry"); // 在指定位置添加
System.out.println(Arrays.toString(fruits.toArray())); // [Apple, Strawberry, Banana]
3)获取长度
System.out.println(fruits.size()); // 获取长度 3
4)获取元素
System.out.println(fruits.get(1)); // 获取元素
5)删除元素
ArrayList<String> fruits = new ArrayList<String>();
fruits.add("Apple"); // 添加元素
fruits.add("Banana");
fruits.add(1, "Strawberry"); // 在指定位置添加
fruits.remove("Apple"); // 删除元素
fruits.remove(1); // 在指定位置删除
System.out.println(Arrays.toString(fruits.toArray())); // [Strawberry]
6)遍历
ArrayList<String> fruits = new ArrayList<String>();
fruits.add("Apple"); // 添加元素
fruits.add("Banana");
fruits.add(1, "Strawberry"); // 在指定位置添加
for (int i = 0; i < fruits.size(); i++) {
System.out.println(fruits.get(i));
}
for (String fruit : fruits) {
System.out.println(fruit);
}
7)返回元素的索引
ArrayList<String> fruits = new ArrayList<String>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add(2, "Apple");
System.out.println(fruits.indexOf("Apple")); // 获取索引: 0
System.out.println(fruits.lastIndexOf("Apple")); // 获取索引: 2
System.out.println(fruits.lastIndexOf("pear")); // 获取索引: -1
8)检查某个元素是否存在 ArrayList 中
ArrayList<String> fruits = new ArrayList<String>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add(2, "Apple");
System.out.println(fruits.contains("Apple")); // true
System.out.println(fruits.contains("pear")); // false
ArrayList<String> newFruits = new ArrayList<String>();
fruits.add("Apple");
fruits.add("Banana");
System.out.println(fruits.containsAll(newFruits)); // true
9)一次性删除所有元素
fruits.clear();
10)排序
Collections.sort(fruits); // 升序
Collections.reverse(fruits); // 降序
如果需要对对象进行排序,需要使用 Comparator 的 compare 方法进行排序。
Student 类:
import java.util.Comparator;
public class Student {
public static Comparator<Student> StuNameComparator = new Comparator<Student>() {
public int compare(Student s1, Student s2) {
String StudentName1 = s1.getStudentName().toUpperCase();
String StudentName2 = s2.getStudentName().toUpperCase();
// ascending order
return StudentName1.compareTo(StudentName2);
// descending order
//return StudentName2.compareTo(StudentName1);
}
};
/*Comparator for sorting the list by roll no*/
public static Comparator<Student> StuRollNo = new Comparator<Student>() {
public int compare(Student s1, Student s2) {
int rollNo1 = s1.getRollNo();
int rollNo2 = s2.getRollNo();
/*For ascending order*/
return rollNo1 - rollNo2;
}
};
private String studentName;
private int rollNo;
private int studentAge;
public Student(int rollNo, String studentName, int studentAge) {
this.rollNo = rollNo;
this.studentName = studentName;
this.studentAge = studentAge;
}
@Override
public String toString() {
return "[ rollNo=" + rollNo + ", name=" + studentName + ", age=" + studentAge + "]";
}
public String getStudentName() {
return studentName;
}
public int getRollNo() {
return rollNo;
}
}
Main 方法:
import java.util.ArrayList;
import java.util.Collections;
public class Main {
public static void main(String[] args) {
ArrayList<Student> studentArrayList = new ArrayList<Student>();
studentArrayList.add(new Student(101, "Zues", 26));
studentArrayList.add(new Student(505, "Abey", 24));
studentArrayList.add(new Student(809, "Vignesh", 32));
/*Sorting based on Student Name*/
System.out.println("Student Name Sorting:");
studentArrayList.sort(Student.StuNameComparator);
// 或者下面这样写
//Collections.sort(studentArrayList, Student.StuNameComparator);
for (Student str : studentArrayList) {
System.out.println(str);
}
/* Sorting on RollNo property*/
System.out.println("RollNum Sorting:");
studentArrayList.sort(Student.StuRollNo);
for (Student str : studentArrayList) {
System.out.println(str);
}
}
}
11)更新列表元素
public class Main {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(1);
arrayList.add(2);
System.out.println("ArrayList before update: " + arrayList);
// Updating 1st element
arrayList.set(0, 11);
arrayList.set(1, 22);
System.out.println("ArrayList after Update: " + arrayList);
}
}
12)连接组合
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(1);
arrayList.add(2);
ArrayList<Integer> arrayList1 = new ArrayList<Integer>();
arrayList1.add(3);
arrayList1.addAll(arrayList); // [3, 1, 2]
13)拷贝
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(1);
arrayList.add(2);
ArrayList<Integer> arrayList1 = (ArrayList<Integer>) arrayList.clone();
arrayList1.add(3);
System.out.println(arrayList1); // [1, 2, 3]
14)判空
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(1);
ArrayList<Integer> arrayList1 = new ArrayList<Integer>();
System.out.println(arrayList.isEmpty()); // false
System.out.println(arrayList1.isEmpty()); // true
15)将 ArrayList 转换为字符串数组
ArrayList<String> fruits = new ArrayList<String>();
fruits.add("Apple"); // 添加元素
fruits.add("Banana");
System.out.println(Arrays.toString(fruits.toArray())); // [Strawberry]
16)将数组转换为 ArrayList
String cityNames[] = {"Agra", "Mysore", "Chandigarh", "Bhopal"};
ArrayList<String> cityList = new ArrayList<String>(Arrays.asList(cityNames));
或者:
String[] cityNames = {"Agra", "Mysore", "Chandigarh", "Bhopal"};
ArrayList<String> arrayList = new ArrayList<String>();
Collections.addAll(arrayList, cityNames);
Collections.addAll() 方法性能更好。
2、LinkedList
与 Java 中的数组类似,LinkedList (链表)是线性数据结构。但是,LinkedList 元素不存储在像数组这样的连续位置中,它们使用指针相互链接。
LinkedList 中的每个元素称为节点。LinkedList 的每个节点包含两个部分:
- 元素的内容
- 指向链表中的下一节点的指针(地址/引用)
如下图:
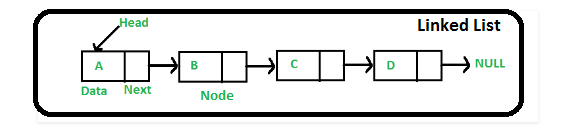
注意:
LinkedList的头仅包含List的第一个元素的地址;LinkedList的最后一个元素在节点的指针部分包含null,因为它是List的结尾,因此它不指向任何内容;- 上图所示的图表示单链表。
LinkedList的另一种复杂类型变体称为双向链表,双向链表的节点包含三部分:- 指向链表的前一节点的指针;
- 元素的内容;
- 指向链表的下一个节点的指针。
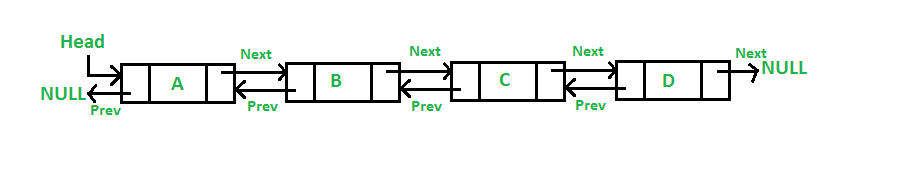
为什么会出现 LinkedList 这样的一个数据结构呢?也就是为什么需要链表呢?
我们知道数组是一个线性数据结构,数组是有一些限制的,如下:
-
数组的大小是固定的。因此我们在创建一个数组时,很难预先预测元素的数量,如果声明的内存空间大小不足,那么我们就不能增加数组的大小;但是如果我们声明一个大型数组,并且不需要存储那么多的元素时,又会浪费空间(
ArrayList已经解决了这个问题); -
数组元素需要连续的存储单元来存储它们的值,也就是说数组(和
ArrayList) 总是将元素加入数组中的第一个非空位置,由于这个特点,就导致了下面的第三个问题; -
在数组中插入一个元素是性能上昂贵的,因为我们必须移动几个元素来为新元素腾出空间。比如:假设我们有一个具有以下元素的数组:
10,12,15,20,4,5,100,现在如果我们想要在值为12的元素之后插入新元素99, 那么我们必须将12之后的所有元素移到右边,为新元素腾出空间。类似地,从数组中删除元素也是性能上昂贵的操作,因为删除元素之后的所有元素都必须向左移位。
LinkedList 就是为了解决上面的问题而出现的。链表是这样来处理的:
- 链表允许动态内存分配,这意味着内存的分配在运行时由编译器完成,在链表声明中我们不需要声明列表的大小;
- 链表元素不需要连续的存储单元,因为列表中的节点(元素)使用包含列表的下一个节点(元素)的地址相互链接;
- 在链表中插入和删除操作的性能并不昂贵,因为从链表中添加和删除元素不需要元素移位,只需要更改前一个节点和下一个节点的指针。
下面介绍下 LinkedList 类的方法。
1)创建
LinkedList<String> list = new LinkedList<String>();
2)添加
LinkedList<String> list = new LinkedList<String>();
list.add("hello");
list.add(0, "I love");
list.addFirst("world");
list.addLast("bye");
3)将指定集合的所有元素添加到列表中:addAll
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>();
ArrayList<String> arrayList= new ArrayList<String>();
arrayList.add("String1");
arrayList.add("String2");
list.addAll(arrayList);
System.out.println(list); // [String1, String2]
}
}
如果指定的集合为 null,则抛出 NullPointerException。
4)获取元素
Object get(int index):从列表中返回指定索引的项;Object getFirst():从列表中取出第一个项;Object getLast():从列表中取出最后一项;int size():返回列表元素的数量。
5)索引
int indexOf(Object item):返回指定项的索引;int lastIndexOf(Object item):返回指定元素最后一次出现的索引;
6)删除元素
Object poll():返回并删除列表的第一项;Object pollFirst():与poll()方法相同,删除列表中的第一项;Object pollLast():返回并删除列表的最后一个元素;Object remove():删除列表的第一个元素;Object remove(int index):从列表中删除指定索引处的元素;Object remove(Object obj):从列表中删除指定的对象;Object removeFirst():从列表中删除第一个项目;Object removeLast():删除列表的最后一项;Object removeFirstOccurrence(Object item):删除第一次出现的指定项;Object removeLastOccurrence(Object item):删除最后一次出现的指定项;- 删除列表中的所有元素:
void clear()。
7)返回列表的副本:Object clone()
8)用赋值更新指定索引的项:Object set(int index, Object item)
9)遍历
for循环- 高级
For循环 - 迭代器
while循环
只介绍迭代器循环:
import java.util.Iterator;
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
/*LinkedList declaration*/
LinkedList<String> linkedList = new LinkedList<String>();
linkedList.add("Apple");
linkedList.add("Orange");
linkedList.add("Mango");
/*for loop*/
System.out.println("**For loop**");
for (int num = 0; num < linkedList.size(); num++) {
System.out.println(linkedList.get(num));
}
/*Advanced for loop*/
System.out.println("**Advanced For loop**");
for (String str : linkedList) {
System.out.println(str);
}
/*Using Iterator*/
System.out.println("**Iterator**");
Iterator i = linkedList.iterator();
// Iterator i = linkedList.descendingIterator(); // 反序遍历
while (i.hasNext()) {
System.out.println(i.next());
}
/* Using While Loop*/
System.out.println("**While Loop**");
int num = 0;
while (linkedList.size() > num) {
System.out.println(linkedList.get(num));
num++;
}
}
}
10)获取子列表
LinkedList类的 subList(int startIndex, int endIndex) 方法可以获取 LinkedList 的子列表。它返回指定索引 startIndex(包括)和 endIndex(不包括)之间的 List。
注意:对子列表所做的任何更改都将反映在原始列表中。
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
// Create a LinkedList
LinkedList<String> linkedList = new LinkedList<String>();
// Add elements to LinkedList
linkedList.add("Item1");
linkedList.add("Item2");
linkedList.add("Item3");
linkedList.add("Item4");
linkedList.add("Item5");
linkedList.add("Item6");
linkedList.add("Item7");
// Displaying LinkedList elements
System.out.println("LinkedList elements:");
Iterator it = linkedList.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// Obtaining Sublist from the LinkedList
List sublist = linkedList.subList(2, 5);
// Displaying SubList elements
System.out.println("\nSub List elements:");
Iterator item = ((List) sublist).iterator();
while (item.hasNext()) {
System.out.println(item.next());
}
sublist.remove("Item4");
System.out.println("\nLinkedList elements After remove:");
Iterator it2 = linkedList.iterator();
while (it2.hasNext()) {
System.out.println(it2.next());
}
}
}
11)isEmpty() 方法用于检查列表是否为空
12)将 LinkedList 转换为 ArrayList
LinkedList<String> linkedList = new LinkedList<String>();
linkedList.add("Harry");
linkedList.add("Jack");
List<String> list = new ArrayList<String>(linkedList);
13)将 LinkedList 转换为数组
LinkedList<String> linkedList = new LinkedList<String>();
linkedList.add("Harry");
linkedList.add("Jack");
String[] array = linkedList.toArray(new String[linkedList.size()]);
3、ArrayList 和 LinkedList 的区别
总结一下二者的区别:
操作方面,ArrayList 搜索操作非常快,而 LinkedList 元素删除更快,插入性能也是 LinkedList 较好,原因在前面已经解释过了。
而在内存开销上面,ArrayList 维护索引和元素数据,而 LinkedList 维护元素数据和相邻节点的两个指针,因此 LinkedList 中的内存消耗比较高。
所以,在开发过程中,我们需要根据具体的需求来选择哪种集合。
3、Vector
Vector (向量)实现 List 接口。与 ArrayList 一样,它也维护插入顺序,但是两者还是有很大的区别的。
Vector 和 ArrayList 的区别:
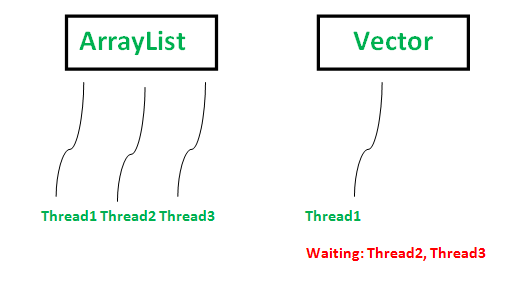
- 同步性(
Synchronization)Vector是同步的,这意味着一次只有一个线程可以访问代码,而不是ArrayList同步的,这意味着多个线程可以同时在ArrayList上工作;- 例如,如果一个线程正在执行添加操作,这个时候可能有另一个线程在多线程环境中执行删除操作。如果多线程同时访问
ArrayList,可能就会发生一个线程的值覆盖另一个线程添加的值,在某些时候会导致一些错误; vector大部分方法都使用了synchronized修饰符,所以它是线程安全的集合类。- 如下图所示:
- 性能(
Performance)ArrayList更快,因为它是非同步的,而向量操作因为是同步的(线程安全的) ,所以性能更慢;- 如果一个线程处理一个向量,那么它就获得了一个向量的锁,这迫使任何其他想要处理它的线程必须等待,直到锁被释放。
- 数据增长(
Data Growth)ArrayList和Vector都会动态地增长和缩小以保持存储空间的最佳使用 —— 但是它们的调整方式是不同的;- 如果元素的数量超过了当前数组的容量,
ArrayList的增量为当前数组大小的50%,而矢量的增量为100%。
- 遍历
Vector可以使用枚举和迭代器(Enumeration and Iterator)遍历Vector元素,而ArrayList不可以使用枚举遍历。
在开发中,我们可以根据具体的需求和 ArrayList 与 Vector 的区别来决定选取哪种集合。
常用的 Vector 类方法有:
void addElement(Object element):在Vector的末尾插入元素;int capacity():此方法返回向量的当前容量;int size():返回向量的当前大小;void setSize(int size):使用指定的大小更改现有大小;boolean contains(Object element):此方法检查Vector中是否存在指定的元素;boolean containsAll(Collection c):如果Vector中存在集合c的所有元素,则返回true;Object elementAt(int index):返回Vector中指定位置的元素;Object firstElement():用于获取向量的第一个元素;Object lastElement():返回数组的最后一个元素;Object get(int index):返回指定索引处的元素;boolean isEmpty():如果Vector没有任何元素,则此方法返回true;boolean remove(Object element):从向量中移除指定的元素;boolean removeAll(Collection c):从向量中删除所有存在于Collection c中的元素;void setElementAt(Object element, int index):使用给定元素更新指定索引的元素;subList(int fromIndex, int toIndex):获取元素的子列表;- 使用
Enumeration迭代Vector; - 使用
Iterator遍历Vector; - 使用
ListIterator在前进和后退方向上遍历Vector
import java.util.Enumeration;
import java.util.Iterator;
import java.util.ListIterator;
import java.util.Vector;
public class Main {
public static void main(String[] args) {
Vector<String> vector = new Vector<String>();
vector.add("Mango");
vector.add("Orange");
vector.add("Apple");
// 使用 Enumeration 迭代 Vector
Enumeration en = vector.elements();
System.out.println("Vector elements are(Enumeration): ");
while (en.hasMoreElements()) {
System.out.println(en.nextElement());
}
// 使用 Iterator 遍历 Vector
Iterator it = vector.iterator();
System.out.println("\nVector elements are(Iterator):");
while (it.hasNext()) {
System.out.println(it.next());
}
ListIterator litr = vector.listIterator();
System.out.println("\nTraversing in Forward Direction:");
while (litr.hasNext()) {
System.out.println(litr.next());
}
System.out.println("\nTraversing in Backward Direction:");
while (litr.hasPrevious()) {
System.out.println(litr.previous());
}
}
}
打印结果:
Vector elements are(Enumeration):
Mango
Orange
Apple
Vector elements are(Iterator):
Mango
Orange
Apple
Traversing in Forward Direction:
Mango
Orange
Apple
Traversing in Backward Direction:
Apple
Orange
Mango
- 将
Vector转换为List; - 将
Vector转换为ArrayList; - 将
Vector转换为字符串数组。
import java.util.*;
public class Main {
public static void main(String[] args) {
Vector<String> vector = new Vector<String>();
vector.add("Mango");
vector.add("Orange");
vector.add("Apple");
System.out.println("Vector Elements :");
for (String str : vector) {
System.out.println(str);
}
List<String> list = Collections.list(vector.elements());
ArrayList<String> arrayList = new ArrayList<String>(vector);
System.out.println("\nList Elements :");
for (String str2 : list) {
System.out.println(str2);
}
System.out.println("\nArrayList Elements :");
for (String str2 : arrayList) {
System.out.println(str2);
}
String[] array = vector.toArray(new String[vector.size()]);
System.out.println("\nString Array Elements :");
for (String s : array) {
System.out.println(s);
}
}
}
4、Stack
在 Java 中 Stack 类表示后进先出(Last in First out, LIFO)的对象堆栈。
就像洗碗一样,最后洗好的碗叠在最上面,而下次拿的时候是最先拿到最后叠上去的碗,即已放置在最底部位置的碗在堆栈中保留的时间最长。像一些编辑器的撤销功能,棋牌程序的悔牌、悔棋功能,就可以选择 Stack。
Stack 类支持一个缺省构造函数堆栈 ,用于创建一个空堆栈。
下面的程序展示了 Stack 类提供的一些基本操作:
import java.util.Stack;
public class Main {
// Pushing element on the top of the stack
static void stack_push(Stack<Integer> stack) {
for (int i = 0; i < 5; i++) {
stack.push(i);
}
}
// Popping element from the top of the stack
static void stack_pop(Stack<Integer> stack) {
System.out.println("Pop :");
for (int i = 0; i < 5; i++) {
Integer y = (Integer) stack.pop();
System.out.println(y);
}
}
// Displaying element on the top of the stack
static void stack_peek(Stack<Integer> stack) {
Integer element = (Integer) stack.peek();
System.out.println("Element on stack top : " + element);
}
// Searching element in the stack
static void stack_search(Stack<Integer> stack, int element) {
Integer pos = (Integer) stack.search(element);
if (pos == -1)
System.out.println("Element not found");
else
System.out.println("Element is found at position " + pos);
}
public static void main(String[] args) {
Stack<Integer> stack = new Stack<Integer>();
stack_push(stack);
stack_pop(stack);
System.out.println(stack.empty());
stack_push(stack);
stack_peek(stack);
stack_search(stack, 2);
stack_search(stack, 6);
}
}
打印结果为:
Pop :
4
3
2
1
0
true
Element on stack top : 4
Element is found at position 3
Element not found
解释一下上面的代码:
Object push(Object element):将一个元素推送到堆栈顶部;Object pop(): 移除并返回堆栈的顶部元素。 注意,当调用堆栈为空时,如果我们调用pop (),就会引发EmptyStackException异常;Object peek():返回堆栈顶部的元素,但不删除它;boolean empty():如果堆栈顶部没有任何内容,则返回true, 否则,返回falseint search(Object element): 它确定堆栈中是否存在某对象。 如果找到该元素,则返回该元素在堆栈中的索引,否则,它返回-1。
四、Queue
Queue (队列)接口与 List、Set 同一级别,都是继承了 Collection 接口。
队列是一种数据结构。它有两个基本操作:在队列尾部加入一个元素和从队列头部移除一个元素(注意不要弄混队列的头部和尾部),即数据是先进先出(FIFO:first in first out)。
在集合框架的结构图中,我们可以看出,LinkedList 实现了 Deque 接口。但是 Queue 接口窄化了对 LinkedList 的方法的访问权限,即在方法中的参数类型如果是 Queue 时,就只能访问 Queue 接口所定义的方法 了,而不能直接访问 LinkedList 的非 Queue 的方法。
Queue 接口支持集合接口的所有方法,包括插入、删除等。
在并发队列上,JDK 提供了两套实现:
- 一个是以
ConcurrentLinkedQueue为代表的高性能非阻塞队列; - 一个是以
BlockingQueue接口为代表的阻塞队列,无论哪种都继承自Queue。
1、阻塞队列与非阻塞队列
阻塞队列
阻塞调用是指调用结果返回之前,当前线程会被挂起,函数只有在得到结果之后才会返回。
从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。同样,往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程使队列重新变得空闲起来,如从队列中移除一个或者多个元素,或者完全清空队列。
非阻塞队列
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
阻塞与同步
这里需要注意,看了上面的解释之后,你可能会把阻塞调用和同步调用等同起来,实际上它们是不同的。对于同 步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已,当前线程还会继续处理各种各样的消息。
而在阻塞状态下, 如果没有数据的情况下调用该函数,则当前线程就会被挂起,直到有数据为止。
2、Queue 中的方法
add():此方法用于在队列尾部添加元素;peek():用于查看队列头部,而不用移除它;如果队列为空,则返回Null;element():此方法类似于peek(); 当队列为空时,它抛出NoSuchElementException;remove():此方法删除并返回队列的头部;当队列为空时,它抛出NoSuchElementException;poll():此方法删除并返回队列的前端;如果队列为空,则返回null;size():此方法返回队列中元素的编号。
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
Queue<Integer> q = new LinkedList<>();
// Adds elements {0, 1, 2, 3, 4} to queue
for (int i = 0; i < 5; i++) {
q.add(i);
}
// Display contents of the queue.
System.out.println("Elements of queue-" + q);
// To remove the head of queue.
int removedele = q.remove();
System.out.println("removed element-" + removedele);
System.out.println(q);
// To view the head of queue
int head = q.peek();
System.out.println("head of queue-" + head);
// Rest all methods of collection interface,
// Like size and contains can be used with this
// implementation.
int size = q.size();
System.out.println("Size of queue-" + size);
}
}
输出结果为:
Elements of queue-[0, 1, 2, 3, 4]
removed element-0
[1, 2, 3, 4]
head of queue-1
Size of queue-4
五、Set
Set 也是 Collection 的子接口,它的特点是:无序,不允许包含重复元素,重复元素会覆盖掉。当不考虑顺序,且没有重复元素时,Set 集合和 List 集合可以互相替换的。
注意:元素虽然无放入顺序,但是元素在 Set 中的位置是有该元素的 HashCode 决定的,其位置其实是固定的,加入 Set 的 Object 必须定义 equals() 方法 ,另外 List 支持 for 循环、下标和迭代器来遍历,但是 Set 只能用迭代器和 foreach 循环方法来遍历,因为它无序,无法用下标来取得想要的值。
所以,与 List 相比,Set 的检索元素效率低下,删除和插入效率高,插入和删除时不会引起元素位置改变。而 List 查找元素效率高,插入和删除元素效率低,因为会引起其他元素位置改变。
基于 Set 接口类有三个:HashSet、LinkedHashSet、TreeSet。
基本上,Set 的方法和 List 都是一致的,这里就不再赘述。
1、HashSet
使用 HashSet 有几点需要注意:
- 不维护任何顺序,元素将以随机顺序返回;
- 不允许重复;如果在
HashSet中添加重复元素,则旧值将被覆盖; - 允许空值
null,但是如果插入多个空值,它仍然只返回一个空值; - 它是非同步的。
import java.util.HashSet;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
HashSet<String> hset = new HashSet<String>();
hset.add("Apple");
hset.add("Mango");
hset.add("Strawberry");
//Addition of duplicate elements
hset.add("Apple");
hset.add("Mango");
//Addition of null values
hset.add(null);
hset.add(null);
//Displaying HashSet elements
System.out.println(hset);
System.out.println("\n--foreach--");
for (String value : hset) {
System.out.println(value);
}
System.out.println("\n--iterator--");
Iterator s = hset.iterator();
while (s.hasNext()) {
System.out.println(s.next());
}
}
}
输出结果为:
[null, Apple, Strawberry, Mango]
--foreach--
null
Apple
Strawberry
Mango
--iterator--
null
Apple
Strawberry
Mango
那 HashSet 如何保证唯一性呢?我们看看 HashSet 的源码中的一部分:
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing HashMap instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
// ...
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
可以看出 HashSet 是基于 HashMap 来实现的,而 PRESENT 则是一个虚假的值。
当向 HashSet 中添加元素时,将元素作为 map 的 key,而 value 则是用一个虚假的值 PRESENT。由于 HashMap 中的 Key 是唯一的,而 HashSet 中的元素是作为 Key 储存在 HashMap 中的,这样就保证了 HashSet元素中没有重复的值。
那如何能够确保
HashMap中Key的唯一性呢?HashMap中有hashCode()和equals()两个方法,用来保证唯一性。
2、TreeSet
TreeSet 类似于 HashSet,不同之处在于它按自然顺序对元素进行升序排序,而 HashSet 不维护任何顺序。
注意:TreeSet 不允许 null 元素。
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
TreeSet<String> treeSet = new TreeSet<String>();
// Adding elements to TreeSet可以看到 TreeSet 已经按隐式升序排序了。
3、LinkedHashSet
LinkedHashSet 也是 Set 接口的一个实现,它的特点是:维护插入顺序,元素按照添加到 Set 中的顺序进行排序。LinkedHashSet 支持 null。
import java.util.LinkedHashSet;
public class Main {
public static void main(String[] args) {
LinkedHashSet<String> lhset = new LinkedHashSet<String>();
// Adding elements to the LinkedHashSet
lhset.add("Z");
lhset.add("PQ");
lhset.add("KK");
lhset.add("Z");
lhset.add(null);
System.out.println(lhset); // [Z, PQ, KK, null]
// LinkedHashSet of Integer Type
LinkedHashSet<Integer> lhset2 = new LinkedHashSet<Integer>();
// Adding elements
lhset2.add(99);
lhset2.add(7);
lhset2.add(0);
System.out.println(lhset2); // [99, 7, 0]
}
}
可以看到,两种类型的 LinkedHashSet 都保留了插入顺序。
4、小结
所以,三者都保证了元素的唯一性,怎么选择呢?
如果无排序要求可以选用 HashSet;
如果想取出元素的顺序和放入元素的顺序相同,那么可以选用 LinkedHashSet ;
如果想插入、删除立即排序或者按照一定规则排序可以选用 TreeSet。
六、HashMap
HashMap 是一个基于 Map 的集合类,用于存储键值对。
1、Map 接口的特点
Map 接口中的每个成员方法由一个关键字(key)和一个值(value)构成。
Map 接口并不直接继承于 Collection 接口,因为它包装的是一组成对的 “键—值” 对象的集合,而且在 Map 接口的集合中也不能有重复的 key 出现,因为每个键只能与一个成员元素相对应。
Map 接口的特点有:
Map接口提供了一种映射关系,其中的元素是以键值对(key-value)的形式存储的,能够实现根据key快速查找value;Map中的键值对以Entry类型的对象实例形式存在;key值不可重复,value值可以;- 每个键最多只能映射到一个值;
Map接口提供了分别返回key值集合,value值集合以及Entry(键值对)集合的方法;Map同样也支持泛型,形式如:Map;
HashMap
HashMap 不是有序集合,这意味着它不会按照插入的顺序返回键和值,也不会对存储的键和值进行排序。它是一个线程不安全的集合对象。
HashMap 的键和值都允许有 null 值存在。
2、HashMap 中的方法
-
void clear():它从指定的Map中删除所有键和值对。 -
Object clone():它返回映射所有映射的副本,用于将它们克隆到另一个映射中。 -
boolean containsKey(Object key):它是一个布尔函数,根据是否在映射中找到指定的键返回true或false; -
boolean containsValue(Object Value):与containsKey()方法类似,但它查找的是指定的值而不是key; -
Value get(Object key):返回指定键的值; -
boolean isEmpty():检查映射是否为空; -
Set keySet():返回从映射中获取的键的Set; -
Value put(Key k, Value v):将键值映射插入到映射中; -
int size():返回映射的大小(键值映射)的数量; -
Set values():返回映射的值集合; -
Value remove(Object key):删除指定键的键值对; -
void putAll(Map m):将映射的所有元素复制到另一个指定的映射; -
遍历
for循环while循环 + 迭代器
import java.util.HashMap; import java.util.Iterator; import java.util.Map; public class Main { public static void main(String[] args) { HashMap<Integer, String> hmap = new HashMap<Integer, String>(); // Adding elements to HashMap hmap.put(11, "AB"); hmap.put(2, "CD"); // FOR LOOP System.out.println("For Loop:"); for (Map.Entry me : hmap.entrySet()) { System.out.println("Key: " + me.getKey() + " & Value: " + me.getValue()); } // WHILE LOOP & ITERATOR System.out.println("While Loop:"); Iterator iterator = hmap.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry me2 = (Map.Entry) iterator.next(); System.out.println("Key: " + me2.getKey() + " & Value: " + me2.getValue()); } } }
七、TreeMap
TreeMap 存储是会进行默认排序的,会根据 key 来排序。
1、TreeMap 的排序
默认情况下,TreeMap元素按键的升序排序。我们可以以相反的顺序迭代 TreeMap,以按键的降序显示元素。
import java.util.*;
public class Main {
public static void main(String[] args) {
Map<String, String> treemap = new TreeMap<String, String>(Collections.reverseOrder());
treemap.put("Key1", "Jack");
treemap.put("Key2", "Rick");
treemap.put("Key3", "Kate");
treemap.put("Key4", "Tom");
treemap.put("Key5", "Steve");
Set set = treemap.entrySet();
Iterator i = set.iterator();
while (i.hasNext()) {
Map.Entry me = (Map.Entry) i.next();
System.out.print(me.getKey() + ": ");
System.out.println(me.getValue());
}
}
}
2、按照值来排序
但是如果想根据它的值进行排序,那就需要使用比较器(Comparator)来实现了。
import java.util.*;
public class Main {
public static void main(String[] args) {
TreeMap<String, String> treeMap = new TreeMap<String, String>();
treeMap.put("Key1", "Steve");
treeMap.put("Key2", "Rick");
treeMap.put("Key3", "Kate");
treeMap.put("Key4", "Tom");
treeMap.put("Key5", "Jack");
Map sortedMap = sortByValues(treeMap);
// Get a set of the entries on the sorted map
Set set = sortedMap.entrySet();
// Get an iterator
Iterator i = set.iterator();
// Display elements
while (i.hasNext()) {
Map.Entry me = (Map.Entry) i.next();
System.out.print(me.getKey() + ": ");
System.out.println(me.getValue());
}
}
public static <K, V extends Comparable<V>> Map<K, V> sortByValues(final Map<K, V> map) {
Comparator<K> valueComparator = new Comparator<K>() {
public int compare(K k1, K k2) {
int compare =
map.get(k1).compareTo(map.get(k2));
if (compare == 0)
return 1;
else
return compare;
}
};
Map<K, V> sortedByValues = new TreeMap<K, V>(valueComparator);
sortedByValues.putAll(map);
return sortedByValues;
}
}
输出结果为:
Key5: Jack
Key3: Kate
Key2: Rick
Key1: Steve
Key4: Tom
3、获取子映射
从 TreeMap 获取子映射,需要用到 subMap 方法:
import java.util.*;
public class Main {
public static void main(String[] args) {
TreeMap<String, String> treeMap = new TreeMap<String, String>();
// Put elements to the map
treeMap.put("Key1", "Jack");
treeMap.put("Key2", "Rick");
treeMap.put("Key3", "Kate");
treeMap.put("Key4", "Tom");
treeMap.put("Key5", "Steve");
treeMap.put("Key6", "Ram");
// Displaying TreeMap elements
System.out.println("TreeMap Contains : " + treeMap);
SortedMap<String, String> sortedMap = treeMap.subMap("Key2", "Key5");
System.out.println("SortedMap Contains : " + sortedMap);
// Removing an element from Sub Map
sortedMap.remove("Key4");
System.out.println("TreeMap Contains : " + treeMap);
}
}
输出结果为:
TreeMap Contains : {Key1=Jack, Key2=Rick, Key3=Kate, Key4=Tom, Key5=Steve, Key6=Ram}
SortedMap Contains : {Key2=Rick, Key3=Kate, Key4=Tom}
TreeMap Contains : {Key1=Jack, Key2=Rick, Key3=Kate, Key5=Steve, Key6=Ram}
可以看到,子映射会影响到源映射。
八、LinkedHashMap
LinkedHashMap 的不同之处在于维护了元素的插入顺序。
import java.util.*;
public class Main {
public static void main(String[] args) {
LinkedHashMap<Integer, String> lhmap = new LinkedHashMap<Integer, String>();
lhmap.put(22, "Abey");
lhmap.put(33, "Dawn");
lhmap.put(1, "Sherry");
lhmap.put(2, "Karon");
lhmap.put(100, "Jim");
Set set = lhmap.entrySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Map.Entry me = (Map.Entry) iterator.next();
System.out.print("Key is: " + me.getKey() + "& Value is: " + me.getValue() + "\n");
}
}
}
输出结果为:
Key is: 22& Value is: Abey
Key is: 33& Value is: Dawn
Key is: 1& Value is: Sherry
Key is: 2& Value is: Karon
Key is: 100& Value is: Jim
可以看到,值的返回顺序与插入的顺序相同。
九、总结
关于 Java 集合框架中的实现类,还有很多 Api,本文没有详尽地列出。具体的方法的使用可以查看官方文档或者源码。