CVPR2020——3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation
3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation
- Abstract
- (一)Introduction
- (二)Related Work
- (三)Method
- 3.1. Proposal Generation
- 3.2. Proposal Consolidation
- 3.3. Object Generation
- 3.4. Training Details
- (四)Experiments
- 4.1. Comparison with State-of-the-art Methods
- 4.2. Ablation study
- (五) Conclusion
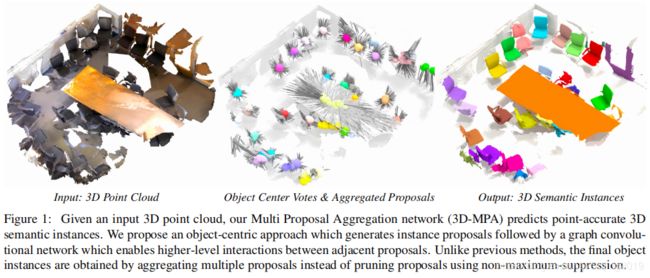
Abstract
- 提出了一种三维点云实例分割方法——3D-MPA。
- 给定一个输入点云,提出一个object-centric的方法,其中每个点都为其object center投票。
- 从预测object centers抽取object proposals。然后,从投票给同一个object center的grouped point features中学习proposal features。
- 图卷积网络引入了interproposal关系,除了提供低级的点特征外,还提供高级的特征学习。每个 proposal包括一个语义标签、一组关联点(在这些点上定义了前景-背景掩码)、一个 objectness score和aggregation features。
- 以前的工作通常对proposal执行非最大抑制(non- maximum-suppression, NMS),以获得最终的目标检测或语义实例。但是,NMS会丢弃可能正确的预测。相反,3D-MPA保持所有proposals,并基于 learned aggregation features将它们分组在一起。
- 在ScanNetV2和S3DIS数据集上, grouping proposals在3D目标检测和语义实例分割等任务上优于NMS,并优于以前的先进方法。
(一)Introduction
创新:
不再使用非最大化抑制来拒绝proposals,而是为每个proposals学习更高层次的特征,使用这些特征将proposals聚在一起,最终检测到目标。
- 思想:生成的proposals数量比3D扫描中原始输入点的数量小几个数量级,这使得分组计算非常高效。同时,每个object可以接收多个proposals,这是因为所有大小的object都以相同的方式处理,从而简化了proposals的生成,并且网络可以很容易地tolerate outlier proposals。
算法步骤:
- 使用一个sparse volumetric feature backbone中的per-point voting scheme生成object-centric proposals。
- 将proposals解释为proposal graph的节点,然后将其馈入图卷积神经网络,以实现相邻proposal特征之间的高级交互。
- 除了proposal 损失外,在proposal 之间通过proxy loss来训练网络,类似于度量学习(metric learning)中的affinity scores。由于proposals,数量相对较少,可以有效地训练网络和cluster proposals。
- 最后,每个节点会预测一个语义类,一个 object foreground mask,一个objectness score以及用于将节点分组在一起的附加特征。
贡献:
- 一种基于dense object center prediction的3D实例分割新方法,该方法利用了从sparse volumetric backbone中学习到的语义特征。
- 为了从object proposals中获取最终的object detections和语义实例,将基于共同学习的proposal features的multi proposal aggregation替换了常用的NMS,并报告了比NMS明显提高的分数。
- 使用图卷积网络,除了较低级别的点特征外,还可以显式地对相邻proposal 之间的高阶交互进行建模。
(二)Related Work
~~
(三)Method
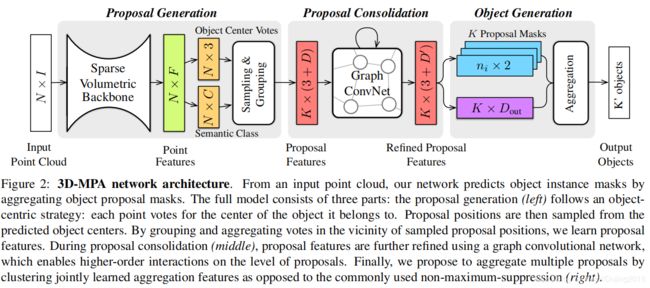
3.1. Proposal Generation
- 给定一个大小为 N × I N×I N×I的点云,由 N N N个点和 I I I维输入特征(例如位置、颜色和法线)组成。
- 网络的第一部分生成固定 K K K数量的object proposals。
- 每个proposal是由(1)位置 y i ∈ R 3 y_i∈R^3 yi∈R3,(2)proposal features vector g i ∈ R D g_i∈ R^D gi∈RD,(3)与proposal相关联的一组点集 s i s_i si等三个部分组成的元组 ( y i , g i , s i ) (y_i,g_i,s_i) (yi,gi,si).
- 为了生成proposals,,需要强大的点特征来编码语义上下文和底层场景的几何形状。
- 应用一个sparse volumetric network作为feature backbone,生成per-point features { f i ∈ R F } i = 1 N \left \{f_{i}\in R^{F}\right \}_{i=1}^{N} {fi∈RF}i=1N。
- 利用per-point semantic classification的标准交叉熵损失 L s e m . p t L_{sem.pt} Lsem.pt,使用语义标签监督feature backbone,将语义上下文编码到点特征中。
- 遵循<
>以对象为中心的方法,点投票给他们所属对象的中心。与其不同的是,只有来自objects的点才能预测中心。(这是可能的,因为论文预测语义类,在训练和测试时可以区分前景(物体)和背景(墙壁、地板等)之间的点,这会使中心预测更精确,因为来自背景点的noisy predictions被忽略了。) - 这是作为回归损失实现的,它预测点位置 x i ∈ R 3 x_i∈R^3 xi∈R3与其对应的ground truth bounding-box center c i ∗ ∈ R 3 c_i^* ∈R^3 ci∗∈R3之间的每点相对3D偏移量 △ x i ∈ R 3 \triangle x_i\in R^{3} △xi∈R3。将per-point center regression loss为:
L c e n t . p t = 1 M ∥ x i + △ x i ∥ H ⋅ 1 ( x i ) − − − − − − − − − − − − − − − − − ( 1 ) L_{cent.pt}=\frac{1}{M}\left \|x_{i} +\triangle x_{i}\right \|_{H}\cdot1(x_{i})-----------------(1) Lcent.pt=M1∥xi+△xi∥H⋅1(xi)−−−−−−−−−−−−−−−−−(1)
(I): ||·||是Huber-loss(或smooth L1-loss)
(II): (·)是一个二元函数,表示一个点 x i x_i xi是否属于一个对象。
(III): M是一个归一化因子,等于object上的总点数。
- feature backbone有两个heads(图2): 一个语义head(执行点的语义分类)和一个中心head(回归每个点的对象中心)。使用组合损失 L p o i n t L_{point} Lpoint联合监督它们,其中λ是设置为0.1的加权因子。
L p o i n t = λ ⋅ L s e m . p t + L c e n t . p t − − − − − − − − − − − − − − − − − − − − ( 2 ) L_{point}=\lambda\cdot L_{sem.pt}+L_{cent.pt}--------------------(2) Lpoint=λ⋅Lsem.pt+Lcent.pt−−−−−−−−−−−−−−−−−−−−(2)
Proposal Positions and Features.
步骤:
- 在每个点(属于一个对象)为一个中心投票后,得到一个在对象中心上的分布(图3,第三列.)。
- 从这个分布中,随机抽取 K K K个样本作为proposal位置 { y i = x i + △ x i ∈ R 3 } i = 1 K \left \{y_i=x_i+\triangle x_{i}\in R^{3}\right \}_{i=1}^{K} {yi=xi+△xi∈R3}i=1K(图3,第四列.)。(随机抽样比中使用的最远点抽样(FPS)工作得更好,因为FPS更倾向于远离真实目标中心的离群点。)
- 定义关联点集 s i s_i si,即在sampled proposal position y i y_i yi的半径 r r r内投票支持centers 的那些点。
- proposal features { g i ∈ R D } i = 1 N \left \{g_{i}\in R^{D}\right \}_{i=1}^{N} {gi∈RD}i=1N是通过将PointNet应用于关联点 s i s_i si的点特征来学习的。
- 这对应于<
>中描述的分组和归一化技术。在此阶段,论文有K个proposals,这些proposals由位于object centers附近的3D位置 y i y_i yi组成,proposal features { g i ∈ R D } \left \{g_{i}\in R^{D}\right \} {gi∈RD}描述了局部几何形状和the nearest objects的语义,以及与每个 proposal相关的一组点 s i s_i si。
3.2. Proposal Consolidation
proposal features 对与其关联对象的局部信息进行编码。在proposal consolidation期间,proposal通过显式建模相邻proposal之间的高级交互来了解其全局邻域。为此,在proposal上定义了图卷积网络(GCN)。
最初的point-feature backbone在点级别运行,而GCN在proposal级别运行。
- 图卷积网络由 l l l个堆叠的图卷积层组成。
- 尽管3D-MPA也可以在不进行GCN细化的情况下工作(即 l l l= 0),但在 l = 10 l = 10 l=10的情况下(第4节),观察到了最佳结果。
- 在proposal consolidation期间,GCN会根据初始proposal features { g i ∈ R D ′ } i = 1 K \left \{g_{i}\in R^{D'}\right \}_{i=1}^{K} {gi∈RD′}i=1K学习refined proposal features { h i ∈ R D } i = 1 K \left \{h_{i}\in R^{D}\right \}_{i=1}^{K} {hi∈RD}i=1K。
具体而言,图的节点由具有相关 proposal features g i g_i gi的proposal positions y i y_i yi定义。如果两个3Dproposal位置 y { i , j } y\left \{i,j\right \} y{i,j}之间的欧式距离 d d d小于2 m,则两个节点之间存在一条边。采用DGCNN 的卷积运算符将两个相邻proposal之间的边缘特征定义为:
e i , j = h θ ( [ y i , g i ] , [ y j , g j ] − [ y i , g i ] ) − − − − − − − − − − ( 3 ) e_{i,j}=h_{\theta}\left (\left [ y_{i},g_{i}\right ] ,\left [ y_{j},g_{j}\right ]-\left [ y_{i},g_{i}\right ] \right )----------(3) ei,j=hθ([yi,gi],[yj,gj]−[yi,gi])−−−−−−−−−−(3)
- h θ h_{\theta} hθ是具有可学习参数θ的非线性函数
- [·,·]表示串联
3.3. Object Generation
- 在这个阶段,有K个 proposals ( y i , g i , s i ) i = 1 K (y_i,g_i,s_i)_{i=1}^{K} (yi,gi,si)i=1K,其中位置 y i y_i yi, refined features h i h_i hi和点集 s i s_i si。目的是从这些proposals中获得最终的语义实例(或object detections)。
- 为此,为每一个proposals预测一个语义类,一个聚合特征向量,一个目标得分和一个二进制前景背景掩码。
- 具体地说, proposal features h i h_i hi输入到具有输出大小 ( 128 , 128 , D o u t ) (128,128,D_{out}) (128,128,Dout)的MLP中,,其中 D o u t = S + E + 2 D_{out}=S+E+2 Dout=S+E+2, S S S semantic classes、 E E E维aggregation feature和2D(正、负)objectness score。
objectness score将proposal分为正面或负面的例子。它通过交叉熵损失 L o b j L_{obj} Lobj进行监督。
- ground truth中心(<0.3 m)附近的proposals被分类为positive.。
- 如果它们与任何ground truth中心相距很远(> 0.6 m),或者如果它们与两个ground truth中心相距相等,则它们被归类为负值,因为ground truth object 是模棱两可的。当 d 1 d_1 d1> 0.6· d 2 d_2 d2时就是这种情况,其中 d i d_i di是第 i i i接近的ground truth中心的距离。
Positive proposals被进一步监督以预测语义类、聚合特征和二进制掩码。Negative的被忽略。使用交叉熵损失 L s e m L_{sem} Lsem来预测 the closest ground truth object的语义标签。
Aggregation Features.
现有方法不足:
- 先前方法依赖于非最大抑制(NMS)获得最终objects.。
- NMS反复选择具有最高客观评分的proposals,并删除所有与某个IoU重叠的proposals。
- 但是,这对objectness scores的质量很敏感,可能丢弃正确的预测。
改进:
- 3D-MPA不会拒绝可能有用的信息,而是结合了多个proposals。为此,3D-MPA学习每个proposals的aggregation features ,然后使用DBScan 对其进行聚类。
- 所有aggregation features最终在同一个簇中的proposals被聚合在一起,产生最终的目标检测。
- final object的点是combined proposals的前景masks上的联合。
- 由于与全点云( N ≈ 1 0 6 N≈10^6 N≈106)相比,proposals数量相对较少(K≈500),因此这一步非常快(∼8ms)。这与聚集全点云相比是一个显著的优势,后者的速度可能非常慢。
研究两种类型的aggregation features:
- Geometric features: { ε i ∈ R E = 4 } i = 1 K \left \{\varepsilon _{i}\in R^{E=4} \right \}_{i=1}^{K} {εi∈RE=4}i=1K 由refined 3D object center prediction ∆ y i ∆y_i ∆yi和一维目标半径估计 r i r_i ri组成。损失定义为:
L a g g = ∥ y i + △ y i − c i ∗ ∥ H + ∥ r i − r i ∗ ∥ H − − − − − − − − − − − − ( 4 ) L_{agg}=\left \|y_{i} +\triangle y_{i}-c_{i}^{\ast}\right \|_{H}+\left \|r_{i} -r_{i}^{\ast}\right \|_{H}------------(4) Lagg=∥yi+△yi−ci∗∥H+∥ri−ri∗∥H−−−−−−−−−−−−(4)
c ∗ c^* c∗是nearest ground truth object center, r i ∗ r_{i}^{\ast} ri∗是the nearest ground truth object边界球的半径。
- Embedding features: { ε i ∈ R E } i = 1 K \left \{\varepsilon _{i}\in R^{E} \right \}_{i=1}^{K} {εi∈RE}i=1K由判别损失函数《Semantic Instance Segmentation with a Discriminative Loss Function》进行监督,损失由三部分组成:
L v a r . = 1 C ∑ c = 1 C 1 N c ∑ i = 1 N c [ ∥ μ C − ϵ i ∥ − δ v ] + 2 − − − − − − − − − − − − − − − ( 5 ) L_{var.}=\frac{1}{C}\sum_{c=1}^{C}\frac{1}{N_{c}}\sum_{i=1}^{N_{c}}\left [ \left \| \mu_{C}-\epsilon _{i}\right \|-\delta _{v}\right ]_{+}^{2}---------------(5) Lvar.=C1c=1∑CNc1i=1∑Nc[∥μC−ϵi∥−δv]+2−−−−−−−−−−−−−−−(5)
L d i s t . = 1 C ( C − 1 ) ∑ C A = 1 C ∑ C B = 1 C [ 2 δ d − ∥ μ C A − μ C B ∥ ] + 2 . . . . . . . . C A ≠ C B − − − − − − − − − − ( 6 ) L_{dist.}=\frac{1}{C(C-1)}\sum_{C_{A}=1}^{C}\sum_{C_{B}=1}^{C}\left [2\delta _{d}- \left \| \mu_{C_{A}}-\mu_{C_{B}}\right \|\right ]_{+}^{2} ........ C_{A}\neq C_{B}----------(6) Ldist.=C(C−1)1CA=1∑CCB=1∑C[2δd−∥μCA−μCB∥]+2........CA=CB−−−−−−−−−−(6)
L r e g . = 1 C ∑ C = 1 C ∥ μ C ∥ − − − − − − − − − − − − ( 7 ) L_{reg.}=\frac{1}{C}\sum_{C=1}^{C}\left \|\mu _{C} \right \|------------(7) Lreg.=C1C=1∑C∥μC∥−−−−−−−−−−−−(7)
在实验中,设置 γ = 0.001 γ=0.001 γ=0.001和 δ v = δ d = 0.1 δ_v=δ_d=0.1 δv=δd=0.1。
- C C C是ground truth objects 的总数
- N C N_C NC是属于一个object的proposals 数
- L v a r . L_{var.} Lvar.将属于同一实例的特征拉到它们的平均值
- L d i s t . L_{dist.} Ldist.将具有不同实例标签的聚类分开
- L r e g . L_{reg.} Lreg.是一个正则化的术语, pulling the means towards the origin。
- 几何特征优于嵌入特征。
Mask Prediction.
- 每个积极的proposals预测一个class-agnostic二值分割掩码在与该proposal相关的点 s i s_i si上,其中每个proposal i i i的点数是 ∣ s i ∣ = n i |s_i| = n_i ∣si∣=ni。
- 之前的方法通过分割2D regions of interest (RoI) (MaskRCNN)或3D bounding boxes(3D- bonet)来获得masks。
- 由于3D-MPA采用object-centric的方法,掩码分割可以直接在与proposal相关的点 s i s_i si上执行。
- 特别地,对于每个proposal,3D-MPA选择在proposal位置 y i y_i yi的距离 r r r内投票支持中心的点的per-point features f i f_i fi。
- 形式上,所选per-point features 集定义为 M f = { f i ∣ ∣ ∣ k ( x i + ∆ x i ) − y i ∣ ∣ 2 < r } M_f=\left \{ f_i| ||k(x_i+∆_{xi})−y_i||_2< r\right \} Mf={fi∣∣∣k(xi+∆xi)−yi∣∣2<r},且r = 0.3m。
- 所选特征 M f M_f Mf被传递到PointNet进行二值分割,3D-MPA在每个per-point特征上应用一个共享的MLP,在所有特征通道上计算最大池,并将结果连接到每个特征,然后将其通过另一个具有特征大小(256、128、64、32、2)的MLP。
- 与最接近的ground truth对象实例标签具有相同ground truth实例标签的点被监督为前景,而其他所有点都是背景。
- 掩码损失 L m a s k L_{mask} Lmask实现为FocalLoss,而不是交叉熵丢失,以应对foreground-background class imbalance。
3.4. Training Details
采用多任务损失 L = L p o i n t + L o b j . + 0.1 ⋅ L s e m . + L m a s k + L a g g . L=L_{point}+L_{obj.}+0.1 \cdot L_{sem.}+L_{mask}+L_{agg.} L=Lpoint+Lobj.+0.1⋅Lsem.+Lmask+Lagg.端到端训练模型。批大小为4,初始学习率为0.1,每 2 ⋅ 1 0 4 2·10^4 2⋅104次迭代减少一半,总共训练 15 ⋅ 1 0 4 15·10^4 15⋅104次迭代。模型是在TensorFlow中实现的,运行在Nvidia TitanXp GPU (12GB)上。
Input and data augmentation.
- 网络在三维网格表面采样N个点的3 m×3 m点云块上进行训练。
- 在测试期间,在全场景上进行评估。
- 输入特征是分配给每个点的三维位置、颜色和法线。
- 数据增加是通过均匀[−180◦,180◦]围绕垂直轴和均匀[−10,10]围绕其他轴随机旋转场景。
- 场景在两个水平方向上随机翻转,并通过Uniform [0.9,1.1]随机缩放。
(四)Experiments
4.1. Comparison with State-of-the-art Methods
Datasets:
- ScanNetV2
- S3DIS
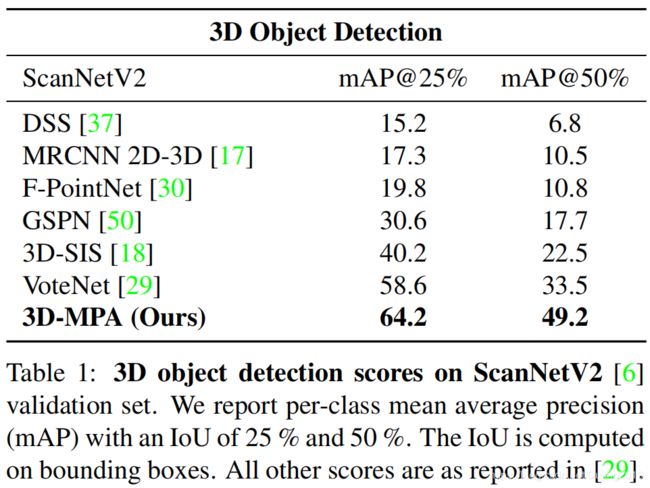
Object detection scores:
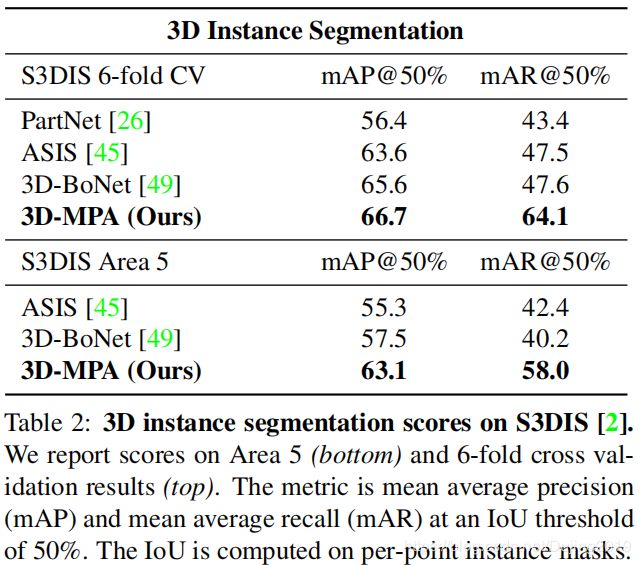
Instance segmentation scores :
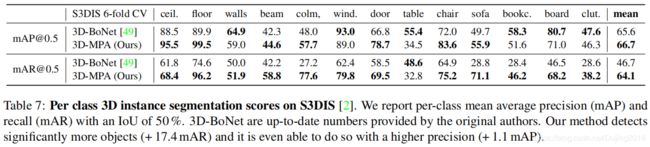
S3DIS:
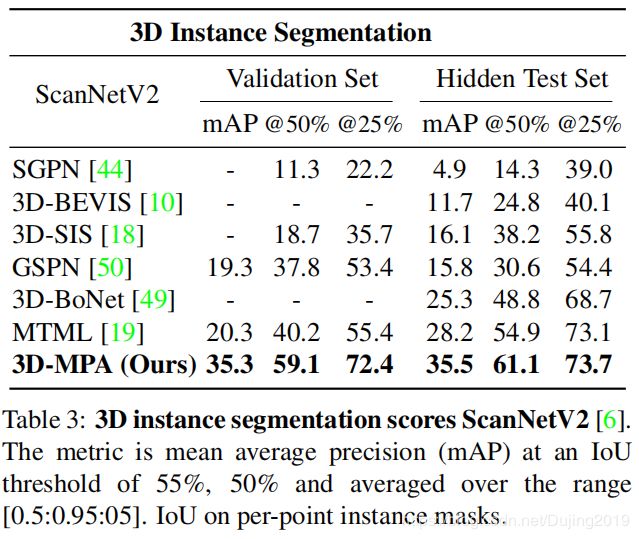
ScanNetV2:
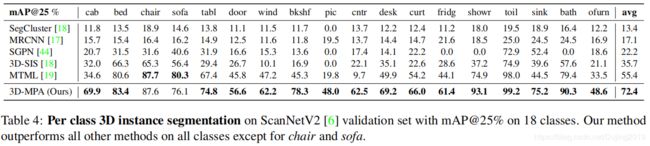
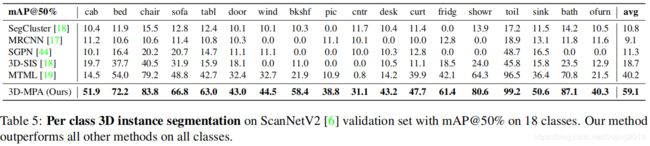
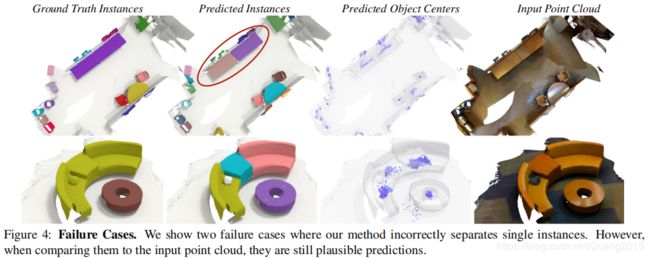
4.2. Ablation study
Effect of grouping compared to NMS.
- 证明多个proposal分组比非最大抑制(NMS)更好。
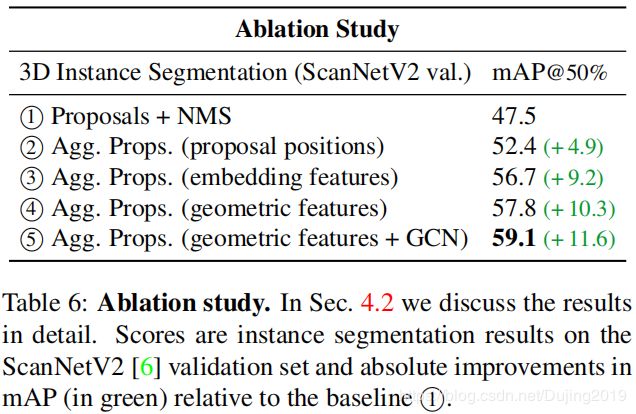
- 通过比较模型的两个基准变体来通过实验证明这一点:在实验1中(表6),采用传统的方法来预测许多proposal,并应用NMS来获得最终的预测。该模型对应于图2所示的模型,没有 proposal consolidation,但aggregation 被NMS取代。 NMS选择最可靠的预测,并抑制IoU大于指定阈值(在本例中为25%)的所有其他预测。
- 对于实验2,通过对proposals位置 y i y_i yi进行聚类来对proposals进行简单的分组。最终object instance masks作为一个聚类中所有 proposal masks的并集获得。通过使用 aggregation替换NMS,我们观察到+4.9 mAP的显着增加。
How important are good aggregation features?
- 在实验2中,根据proposals的位置对proposals进行分组。这些仍然是相对简单的特征。
- 在实验3和4中,分别根据学习到的嵌入特征和学习到的几何特征对建议进行分组。与实验2相比,有显著改善。
- 几何特征的表现优于嵌入特征(+1.1 mAP)。一种可能的解释是,几何特征有明确的含义,因此比实验3 中使用的5维嵌入空间更容易训练。
- 总之,aggregation feature的quality有很大的影响。
Does the graph convolutional network help?
- 在proposals之上定义的graph convolutional network (GCN)允许proposals之间的高阶交互。实验5 对应于图2所示的模型,GCN为10层。实验4 不同于实验5 ,因为它不包括合并proposals的GCN。
- 通过合并GCN并使用多proposals aggregation,替换NMS,在相同的网络架构上得到了+11.6 mAP改进。
(五) Conclusion
- 在本文中,引入了一种新的三维语义实例分割方法——3D-MAP。
- 核心思想是将自顶向下和自底向上的目标检测策略的优点结合起来。
- 首先使用基于sparse volumetric backbone的以 object-centric的投票方案生成许多proposals。每个对象可能会收到多个proposals,这使得我们的方法在object proposals阶段对潜在的异常值具有鲁棒性。
- 首先通过一个图形卷积网络来设置proposals之间的higher-order feature interactions。然后根据图关系结果和proposals特征相似度对proposals进行聚合,只获得了少量的proposals,这样的聚类在计算上是轻量的。
- 图卷积有助于获得高评估分数,
- 论文最大的改进是multi proposal aggregation strategy。