「Python爬虫系列讲解」八、Selenium 技术
本专栏是以杨秀璋老师爬虫著作《Python网络数据爬取及分析「从入门到精通」》为主线、个人学习理解为主要内容,以学习笔记形式编写的。
本专栏不光是自己的一个学习分享,也希望能给您普及一些关于爬虫的相关知识以及提供一些微不足道的爬虫思路。
专栏地址:Python网络数据爬取及分析「从入门到精通」
更多爬虫实例详见专栏:Python爬虫牛刀小试

前文回顾:
「Python爬虫系列讲解」一、网络数据爬取概述
「Python爬虫系列讲解」二、Python知识初学
「Python爬虫系列讲解」三、正则表达式爬虫之牛刀小试
「Python爬虫系列讲解」四、BeautifulSoup 技术
「Python爬虫系列讲解」五、用 BeautifulSoup 爬取电影信息
「Python爬虫系列讲解」六、Python 数据库知识
「Python爬虫系列讲解」七、基于数据库存储的 BeautifulSoup 招聘爬取
目录
1 初识 Selenium
1.1 安装 Selenium
1.2 安装浏览器驱动
1.3 PhantomJS
2 快速开始 Selenium 解析
3 定位元素
3.1 通过 id 属性定位元素
3.2 通过 name 属性定位元素
3.3 通过 XPath 路径定位元素
3.4 通过超链接文本定位元素
3.5 通过标签名定位元素
3.6 通过类名定位元素
3.7 通过 CSS 选择器定位元素
4 常用方法和属性
4.1 操作元素的方法
4.2 WebElement 常用属性
5 键盘和鼠标自动化操作
5.1 键盘操作
5.2 鼠标操作
6 导航控制
6.1 下拉菜单交互操作
6.2 Window 和 Frame 间对话框的移动
7 本文小结
Selenium 是一款用于测试 Web 应用程序的经典工具,它直接运行在浏览器中,仿佛真正的用户在操作浏览器一样,主要用于网站自动化测试、网站模拟登陆、自动操作键盘和鼠标、测试浏览器兼容性、测试网站功能等,同时也可以用于制作简易的网络爬虫。
本文主要介绍 Selenium Python API 技术,它以一种非常直观的方式来访问 Selenium WebDriver 的所有功能,包括定位元素、自动操作键盘鼠标、提交页面表单、抓取所需信息等。
1 初识 Selenium
Selenium 是 Thought Work 公司专门为 Web 应用程序编写的一个验收测试工具,它提供的 API 支持多种语言,包括 Python、Java、C# 等,本文主要介绍 Python 环境下的 Selenium 技术。Python 语言提供了 Selenium 扩展库,它是使用 Selenium WebDriver(网页驱动)来编写功能、验证测试的一个 API 接口。通过 Selenium Python API,用户可以以一种直观的方式来访问 Selenium WebDriver 的所有功能。Selenium Python 支持多种浏览器,诸如 Chrome、火狐、IE、360 等,也支持 PhantomJS 特殊的无界面浏览器引擎。
类似于前几期文章讲到的 BeautifulSoup 技术,Selenium 制作的爬虫也是先分析网页的 HTML 源码和 DOM 树结构,在通过其所提供的方法定位到所需信息的节点位置,并获取其文本内容。
1.1 安装 Selenium
pip install seleniumSelenium 安装成功之后,接下来需要调用浏览器进行定位或爬取信息,而使用浏览器时需要先安装浏览器驱动。下面介绍浏览器驱动的配置过程。
1.2 安装浏览器驱动
首先,下载浏览器驱动器WebDriver
chrom浏览器的驱动器下载地址:http://npm.taobao.org/mirrors/chromedriver/
firefox(火狐浏览器)的驱动器下载地址:https://github.com/mozilla/geckodriver/releases
Edge浏览器的驱动器下载地址:https://developer.microsoft.com/en-us/micrsosft-edage/tools/webdriver
Safari浏览器的驱动器下载地址:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
以谷歌浏览器为例,需要首先知道浏览器的版本号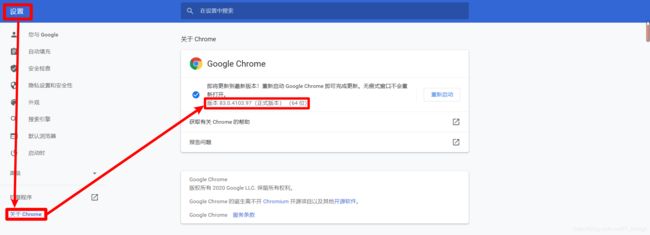
只需要前面的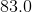 对应好就OK,大的方向对应了就行,然后找到相匹配的版本进行下载
对应好就OK,大的方向对应了就行,然后找到相匹配的版本进行下载
安装好之后,进入测试环节,下面给出加载主流浏览器驱动的核心代码:
①Firefox 浏览器
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')②Chrom 浏览器(需要指定浏览器驱动的本地目录地址)
import os
from selenium import webdriver
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
driver.get('http://www.baidu.com')③IE 浏览器
from selenium import webdriver
driver = webdriver.IE()
driver.get('http://www.baidu.com')1.3 PhantomJS
PhantomJS 是一个服务器端的 JavaScript API 的开源浏览器引擎(WebKit),它支持各种 Web 标准,包括 DOM 树分析、CSS 选择器、JSON 和 SVG 等。PhantomJS 常用于页面自动化、网络监测、网页截屏以及无界面测试等。
下载地址:https://phantomjs.org/download.html
建议直接下载并解压至 Scripts 目录环境下,如下图所示:

当 Selenium 安装成功且 PhantomJS 下载并配置好之后,其调用方法如下:
# 导入 Selenium.webdriver 扩产库,并提供了 webdriver 实现方法
from selenium import webdriver
# 创建 driv 实例,调用 webdriver.PhantomJS 方法配置路径
driver = webdriver.PhantomJS(executable_path="E:\software\python3.8.2\Scripts\phantomjs-2.1.1-windows\phantomjs.exe")
# 打开百度网页,webdriver 会等待网页元素加载完成之后才能把控制权交回脚本
driver.get('http://www.baidu.com')
# 获取文章标题并赋值给 data 变量输出
data = driver.title
# data 变量值为“百度一下,你就知道”
print(data)
注:webdriver 中提供的 save_screenshot() 函数可以对网页进行截图。
2 快速开始 Selenium 解析
网页通常采用文档对象模型树结构进行存储,并且这些节点都是成对出现的,如 “” 对应 “”、“
如下代码实现的功能是定位百度搜索框并进行自动搜索,可以将其作为我们快速入门的代码。

import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 该 Keys 类提供了操作键盘的快捷键,如空格键、回车键等
# 浏览驱动器路径
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 打开网页
driver.get('http://www.baidu.com')
# 使用断言(assert)判断文章标题是否包含“百度”字段。若不包括则报错,若包括则继续执行下一条语句
assert "百度" in driver.title
# 查找元素定位百度搜索输入文本框(见上图)
elem = driver.find_element_by_name("wd")
# 模拟键盘操作,输入“CSDN”字段
elem.send_keys("CSDN")
# 输入回车键进行操作
elem.send_keys(Keys.RETURN)
time.sleep(10)
# 进行截图操作
driver.save_screenshot('baidu.png')
# 关闭驱动
driver.close() # 关闭页面
# 退出驱动
driver.quit() # 退出浏览器
3 定位元素
Selenium Python 提供了一种用于定位元素(Locate Element)的策略,用户可以根据所爬取网页的 HTML 结构选择最合适的方案。当定位多个元素时,只需将方法 “element” 加 “s” ,这些元素将会以一个列表的形式返回。
| 定位单个元素的方法 | 定位多个元素的方法 | 方法的含义 |
| find_element_by_id | find_elements_by_id | 通过 id 属性定位元素 |
| find_element_by_name | find_elements_by_name | 通过 name 属性定位元素 |
| find_element_by_xpath | find_elements_by_xpath | 通过 XPath 路径定位元素 |
| find_element_by_link_text | find_elements_by_link_text | 通过显示文本定位元素 |
| find_element_by_partial_link_text | find_elements_by_partial_link_text | 通过超链接文本定位元素 |
| find_element_by_tag_name | find_elements_by_tag_name | 通过标签名定位元素 |
| find_element_by_class_name | find_elements_by_class_name | 通过类属性名定位元素 |
| find_element_by_css_selector | find_elements_by_css_selector | 通过CSS选择器定位元素 |
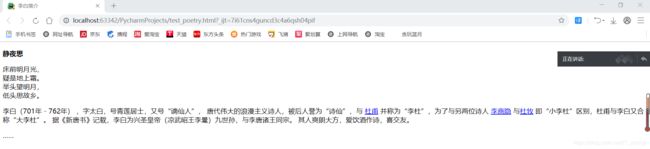
本文将结合下面的 HTML 代码分别介绍各种元素的定位方法,并以定位单位元素为主。
李白简介
静夜思
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
杜甫
并称为“李杜”,为了与另两位诗人
李商隐
与杜牧
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
……
3.1 通过 id 属性定位元素
该方法通过网页标签的 id 属性来定位元素,它将返回第一个与 id 属性值匹配的元素。如果没有元素与 id 值匹配,则返回一个 NoSuchElementException 异常。
现在假设需要通过 id 属性定位页面中的 “杜甫”、“李商隐”、“杜牧” 3 个超链接,则 HTML 核心代码如下:
李白简介
...
...
如果需要获取 div 布局,则使用如下代码:
import os
from selenium import webdriver
# 浏览驱动器路径
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 打开 HTML 本地网页
driver.get('http://localhost:63342/PycharmProjects/test_poetry.html?_ijt=fu8obkjef7c2i45o7qjji407mk')
test_div = driver.find_element_by_id('nr')
print(test_div.text)
如果写成如下代码(展示核心代码),则返回第一个诗人的信息:
test_poet = driver.find_element_by_id('link')
print(test_poet.text)
如果想要通过 id 属性获取多个链接,比如 “杜甫”、“李商隐”、“杜牧” 3 个超链接,则需使用 find_elements_by_id() 函数,注意 “elements” 表示获取多个值。3 个超链接都是用同一个 id 名称 “link”,通过 find_elements_by_id() 函数定位获取之后,再调用 for 循环输出结果,如下(展示核心代码):
test_div = driver.find_elements_by_id('link')
for t in test_div:
print(t.text)
3.2 通过 name 属性定位元素
该方法通过网页标签的 name 属性来定位元素,它将返回第一个与 name 属性值匹配的元素。如果没有元素与 name 值匹配,则返回一个 NoSuchElementException 异常。
下面介绍通过 name 属性来定位页面中 “杜甫”、“李商隐”、“杜牧” 3 个超链接的方法,HTML 源码如下:
李白简介
...
...
如果需要分别捕获 “杜甫”、“李商隐”、“杜牧” 3 个超链接,则相应代码如下:
test_poet1 = driver.find_element_by_name('dufu')
test_poet2 = driver.find_element_by_name('lsy')
test_poet3 = driver.find_element_by_name('dumu')
print(test_poet1, test_poet2, test_poet3)
值得注意的是,test_poet 是获取的值,通常为 “

值得注意的还有,此时不能调用 find_elements_by_name() 函数来获取多个元素,因为 3 个人物超链接的 name 属性是不同的。
3.3 通过 XPath 路径定位元素
XPath 是用于定位 XML 文档中节点的技术,HTML/XML 都是采用网页 DOM 树状标签的结构进行编写的,所以可以通过 XPath 方法分析其节点信息。Selenium Python 也提供了类似的方法来跟踪网页中的元素。
XPath 路径定位元素方法不同于按照 id 或 name 属性的定位方法,前者更加的灵活、方便。比如,想通过 id 属性定位第三位诗人“杜牧”的超链接信息,但是 3 位诗人的 id 属性都是 link,如果没有其他属性,那将如何实现呢?此时可以借助 XPath 方法进行定位。这也体现了 XPath 方法的一个优点,即当没有一个合适的 id 或 name 属性来定位所需要查找的元素时,可以使用 XPath 去定位这个绝对元素(但不建议定位绝对元素),或者定位一个有 id 或 name 属性的相对元素位置。
XPath 方法也可以通过除了 id 和 name 属性的相对元素进行定位,其完整函数为 find_element_by_xpath() 和 find_elements_by_xpath()。
下面开始通过实例进行讲解,HTML 代码如下:
李白简介
静夜思
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
杜甫
并称为“李杜”,为了与另两位诗人
李商隐
与杜牧
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
……
上述 div 布局可以通过以下 3 中 XPath 方法定位:
# 方法一:使用绝对路径定位,从HTML代码的根节点开始定位元素,但如果HTML代码稍有改动,其结果就会被破坏
test_div1 = driver.find_element_by_xpath("/html/body/div[1]")
# 方法二:获取 HTML 代码中的第一个 div 布局元素。如果 div节点位置太深,则需寻找附近一个元素的 id 或 name 属性进行定位
test_div2 = driver.find_element_by_xpath("//div[1]")
# 方法三:定位 id 属性值为”nr“的 div 布局元素,此时可以定位介绍三位诗人的简介信息。
test_div3 = driver.find_element_by_xpath("//div[@id='nr']")
print(test_div1.text, test_div2.text, test_div3.text)

# 方法一:定位 div 节点下的一个超链接 a 元素,且 a 元素,且 a 元素 name 属性为 “dumu”
test_div1 = driver.find_element_by_xpath("//div[a/@name='dumu']")
# 方法二:定位“id='nr'”的元素,再找到它的第三个超链接 a 子元素
test_div2 = driver.find_element_by_xpath("//div[@id='nr']/a[3]")
# 方法三:定位 name 属性为 “杜牧” 的第一个超链接
test_div3 = driver.find_element_by_xpath("//a[@name='dumu']")
print(test_div2.text, test_div3.text)
如果是按钮控件并且其 name 属性相同,假设 HTML 代码如下:
则定位 value 值为 “Clear” 按钮元素的方法如下:
# 定位属性 name 为 “continue” 且属性 type 为“button” 的 input 控件
clearb = driver.find_element_by_xpath("//input[@name='continue'][@type='button']")
# 定位属性“id=loginForm”的form节点下的第二个 input 子元素
clearb = driver.find_element_by_xpath("//form[@id='loginForm']/input[2]")3.4 通过超链接文本定位元素
当需要定位一个锚点标签内的链接文本(Link Text)时可以通过超链接文本定位元素的方法进行定位。该方法返回第一个匹配该链接文本值的元素。如果没有元素与该链接文本匹配,则抛出一个 NoSuchElementException 异常。
下面将介绍如何通过该方法来定位页面中“杜甫”“李商隐”“杜牧”这 3 个超链接,HTML 源码如下:
则分别获取“杜甫”、“李商隐”、“杜牧” 3 个超链接的代码如下:
# 分别定位 3 个超链接
test_poet1 = driver.find_element_by_link_text('DF')
test_poet2 = driver.find_element_by_link_text('LSY')
test_poet3 = driver.find_element_by_link_text('DM')
print(test_poet1.text, test_poet2.text, test_poet3.text)
# 定位超链接部分元素
test_poet4 = driver.find_element_by_partial_link_text('D')
print(test_poet4.text)
# 定位超链接部分元素且定位多个元素
test_poet5 = driver.find_elements_by_partial_link_text('D')
for t in test_poet5:
print(t.text)
注: find_element_by_link_text() 函数使用锚点标签的链接文本进行定位;
driver.find_elements_by_partial_link_text() 函数可以获取多个元素。
3.5 通过标签名定位元素
通过标签名(Tag Name)定位元素并将返回第一个用标签名匹配定位的元素。如果没有元素匹配,则抛出一个 NoSuchElementException 异常。
假设 HTML 源码如下:
李白简介
静夜思
床前明月光,疑是地上霜。举头望明月,低头思故乡。
定位元素 h1 和段落 p 的方法如下:
test1 = driver.find_element_by_tag_name('h1')
test2 = driver.find_element_by_tag_name('p')
print(test1.text, test2.text)
3.6 通过类名定位元素
通过类属性名(Class Attribute Name)定位元素将返回第一个用类属性名匹配定位的元素。如果没有元素匹配,则返回一个 NoSuchElementException 异常。
通过 class 属性值定位段落 p 元素的方法如下:
test1 = driver.find_element_by_class_name('content')3.7 通过 CSS 选择器定位元素
通过 CSS 选择器(CSS Selector)定位元素将返回第一个与 CSS 选择器匹配的元素。如果没有元素匹配,则返回一个 NoSuchElementException 异常。
通过 CSS 选择器定位段落 p 元素的方法如下:
test1 = driver.find_element_by_css_selector('p.content')如果存在多个相同的 class 属性值的 content 标签,则可以使用下面的方法进行定位:
test1 = driver.find_element_by_css_selector(*.content)
test2 = driver.find_element_by_css_selector(.content)通过 CSS 选择器定位元素的方法是比较难的一个方法,相比较而言,使用 id、name 和 XPath 等常用的定位元素方法更加实用。
4 常用方法和属性
4.1 操作元素的方法
定位操作完成后需要对已经定位的对象进行操作,这些操作的页面行为通常需要通过 WebElement 接口实现。
| 方法 | 含义 |
| clear() | 清除元素的内容 |
| send_keys(key) | 模拟键盘按键操作,输入关键字(key) |
| click() | 单击元素 |
| submit() | 提交表单 |
| get_attribute() | 获取属性为 name 的属性值 |
| is_displayed() | 设置该元素是否可见 |
| is_enabled() | 判断元素是否被使用 |
| is_selected() | 判断元素是否被选中 |
下面举一个自动登录百度首页的示例,利用该示例来讲解常见操作元素的方法。

通过上图所示方法可以看到百度首页“登录”按钮对应的 HTML 源码。
首先用浏览器驱动打开目标网页
# 浏览驱动器路径
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 打开网页
driver.get('https://www.baidu.com/?tn=78040160_5_pg&ch=8')通过 name 值为 “ tj_login ” 锁定并单击 “登录” 按钮,跳转至登录页面
login = driver.find_element_by_name("tj_login")
login.click()通过 id 值查找 “用户名登录” 并单击它。
denglu = driver.find_element_by_id('TANGRAM__PSP_11__footerULoginBtn')
根据上图,用同样的方法定位输入框并清除默认数据后输入账户密码,单击登录。
name = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__userName"]')
name.send_keys("这里填账户")
pwd = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__password"]')
pwd.send_keys("这里填密码")
denglu = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__submit"]')
denglu.click()下面给出完整代码参考:
import time
import os
from selenium import webdriver
# 浏览驱动器路径
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 打开网页
driver.get('https://www.baidu.com/?tn=78040160_5_pg&ch=8')
# 登录按钮
login = driver.find_element_by_xpath('//*[@id="u1"]/a[2]')
print(login.text)
login.click()
time.sleep(3)
# 切换账号密码登录
dl = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__footerULoginBtn"]')
dl.click()
time.sleep(3)
# 填入账号密码
name = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__userName"]')
name.send_keys("这里填账户")
time.sleep(1)
pwd = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__password"]')
pwd.send_keys("这里填密码")
time.sleep(1)
# 点击登录按钮
denglu = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__submit"]')
denglu.click()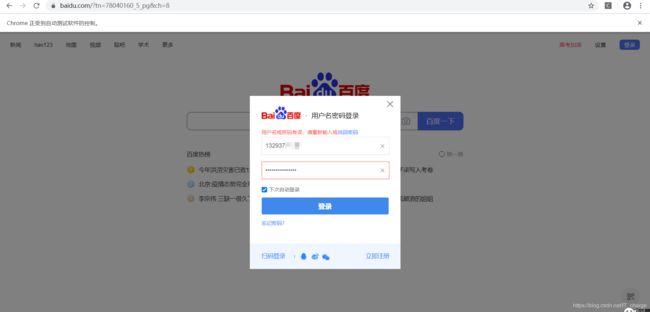
注:每步加载需要时间,故设置适当的 sleep 值使得程序顺利执行、不易报错。
4.2 WebElement 常用属性
通过 WebElement 接口可以获取常用的值。
| 方法 | 含义 |
| size | 获取元素的尺寸 |
| text | 获取元素的文本 |
| location | 获取元素的坐标,先找到要获取的元素,再调用该方法 |
| page_source | 返回页面源码 |
| title | 返回页面标题 |
| current_url | 获取当前页面的 URL |
| tag_name | 返回元素的标签名称 |
5 键盘和鼠标自动化操作
Selenium 技术还可以实现自动操作键盘鼠标的功能,所以它更多地用用于自动化测试领域,通过自藕丁操作网页、反馈响应的结果来检测网站的健壮性和安全性。
5.1 键盘操作
| 方法 | 含义 |
| send_keys(Key,ENTER) | 按回车键,最常用按键操作 |
| send_keys(Key,TAB) | 按 Tab 键 |
| send_keys(Key,SPACE) | 按空格键 |
| send_keys(Key,ESCAPE) | 按 Esc 键 |
| send_keys(Key,BACK_SPACE) | 按 Backspace 键 |
| send_keys(Key,SHIFT) | 按 Shift 键 |
| send_keys(Key,CONTROL) | 按 Ctrl 键 |
| send_keys(Key,CONTROL,'a') | 按 Ctrl + A 快捷键全选 |
| send_keys(Key,CONTROL,'c') | 按 Ctrl + C 快捷键复制 |
| send_keys(Key,CONTROL,'x') | 按 Ctrl + X 快捷键剪切 |
| send_keys(Key,CONTROL,'v') | 按 Ctrl + V 快捷键粘贴 |
5.2 鼠标操作
| 方法 | 含义 |
| click() | 单击一次 |
| context_click(elem) | 右击元素 elem,比如在弹出的快捷菜单中选择“另存为”等命令 |
| double_click(elem) | 双击元素 elem |
| drag_and_drop(source,target) | 鼠标拖动操作,在源元素 source 位置处按下鼠标左键并移动至目标元素 target,然后释放 |
| send_keys(Keys, BACK_SPACE) | 按 Backspace 键 |
| move_to_element(elem) | 将光标移动到元素 elem 上 |
| click_and_hold(elem) | 按下鼠标左键并悬停在元素 elem 上 |
| perform() | 执行 ActionChains 类中的存储操作,弹出对话框 |
6 导航控制
下面介绍 Selenium 的导航控制操作,包括页面交互、表单操作和对话框间的移动等内容。
6.1 下拉菜单交互操作
前面讲述的百度搜索案例就是一个页面交互的过程,包括:
- 调用 driver.find_element_by_xpath() 函数定位元素
- 调用 send_keys(key) 输入关键词或键盘按键,如输入 Keys.RETURN 回车键。
- 调用 click() 函数单击,执行另存为图片的操作等。
这里将补充页面交互切换下拉菜单的实例。定位 "name" 下拉菜单标签后,调用 SELECT 类选中选项,同时 select_by_visible_text() 用于显示选中的菜单,也可以提交 Form 表单,具体代码如下:
from selenium.webdriver.support.ui import Select
name = driver.find_element_by_name("name")
select = Select(name)
select.select_by_index(index)
select.select_by_visible_text("text")
select.select_by_value(value)如果想取消已选中的选项,则可以使用如下代码:
from selenium.webdriver.support.ui import Select
name = driver.find_element_by_name("name")
select = Select(name)
all_selected_options = select.all_selected_options如果想获取所有的可用选项,则可嗲用 select.options。当填写完表单后,可以通过 submit() 函数提交,或者找到提交按钮后调用 “ driver.find_element_by_id("submit").click*() ” 提交。
6.2 Window 和 Frame 间对话框的移动
网站通常都是由多个窗口组成的,称为多帧 Web 应用。webdriver 提供 switch_to_window() 方法来支持命名窗口间的移动切换,如下:
driver.switch_to_window("windowName")现在 driver 的所有操作都将针对特定的窗口,因此可以通过定位其 HTML 源码中的超链接,或者给 switch_to_window() 方法传递一个 “窗口句柄” 来实现。常用方法是,循环遍历所有的窗口,获取指定的句柄进行定位操作,核心代码如下:
for handle in driver.window_handles:
driver.switch_to_window(handle)在帧与帧(Iframe)之间切换使用 “ driver.switch_to_frame("frameName") ” 函数。对于弹出式对话框,Selenium webdriver 提供了内建支持,switch_to_alert() 函数将返回当前打开的 alert 对象,通过该对象可以进行确认同意或反对操作,也可以读取它的内容,代码如下:
alert = driver.switch_to_alert()下面是捕获弹出式对话框内容的核心代码:
# 获取当前窗口句柄
now_handle = driver.current_window_handle
print(now_handle)
# 获取所有窗口句柄
all_handles = driver.window_handles
for handle in all_handles:
if handle != now_handle:
# 输出待选择的窗口句柄
print(handle)
driver.switch_to_window(handle)
time.sleep(1)
# 具体操作
elem_bt = driver.find_element_by_xpath("...")
driver.close() # 关闭当前窗口
# 输出主窗口句柄
print(now_handle)
driver.switch_to_window(now_handle) # 返回主窗口7 本文小结
Selenium 库分析和定位节点的方法与 BeautifulSoup 库类似,他们都能够利用类似于 XPath 技术的方法来定位标签,都拥有丰富的操作函数来爬取数据。但不同之处在于,Selenium 能方便地操控键盘、鼠标,以及切换对话框、提交表单等。对于目标网页需要验证登录后才能爬取,所爬取的数据位于弹出对话框中或所爬取的数据通过超链接跳转到了新的窗口等情况,Selenium 技术的优势就体现出来了,它可以通过控制鼠标模拟登录或提交表单来爬取数据,但其缺点是爬取效率较低。
欢迎留言,一起学习交流~
感谢阅读