Oracle GoldenGate的使用——在安装了kafka的目标端进行配置并测试实现Oracle数据同步至kafka
之前我已经安装好了目标端的Oracle GoldenGate for Big Data。可以看这篇博客:Oracle Golden Gate(OGG)学习——目标端安装Big Data
Linux系统中先进入到OGG安装的目录,使用 ggsci 打开控制程序:
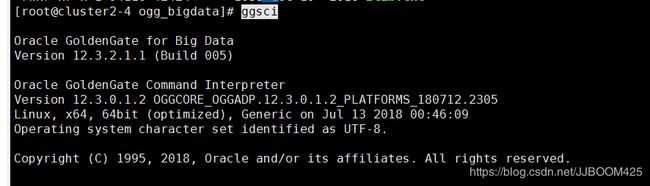
1、配置mgr进程
GGSCI > edit params mgr目标端mgr进程配置信息:
PORT 7809
DYNAMICPORTLIST 7810-7860
AUTORESTART ER *, RETRIES 3, WAITMINUTES 5
PURGEOLDEXTRACTS ./dirdat/*, USECHECKPOINTS, MINKEEPDAYS 30
lagreporthours 1
laginfominutes 30
lagcriticalminutes 60
ACCESSRULE, PROG SERVER, ALLOW; Or ACCESSRULE, PROG *, IPADDR 192.168.129.161, ALLOW;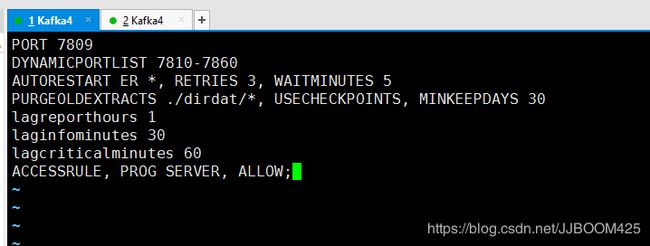
2、配置checkpoint
GGSCI > edit param ./GLOBALS
CHECKPOINTTABLE ogg_student.checkpoint
3、配置replicate进程
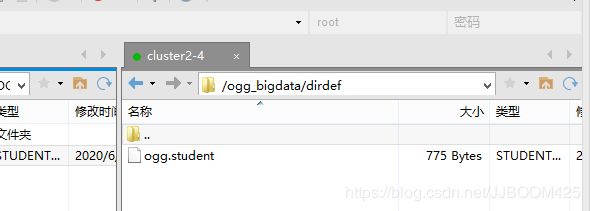
先将之前 Oracle GoldenGate的使用——在Windows源端增加配置管理、抽取、投递进程并启动测试 博客中 生成的映射文件 ogg.student 复制到我在目标端安装Oracle GoldenGate for Big Data的 /ogg_bigdata/dirdef 路径下:
GGSCI > edit param rekafka
REPLICAT rekafka
sourcedefs /ogg_bigdata/dirdef/ogg.student
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
MAP ogg.student, TARGET ogg.student;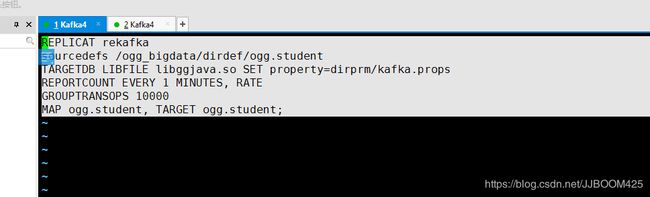
参数说明:
- REPLICATE rekafka 为rep进程名称;
- sourcedefs 为之前在源服务器上做的表映射文件;
- TARGETDB LIBFILE 为定义kafka一些适配性的库文件以及配置文件,配置文件位于OGG主目录下的dirprmfka.props;
- REPORTCOUNT即复制任务的报告生成频率;
- GROUPTRANSOPS为以事务传输时,事务合并的单位,减少IO操作;
- MAP即源端与目标端的映射关系。
其中TARGETDB LIBFILE参数中的 dirprm 路径下面并没有 kafka.props 文件,我们可以到 /ogg_bigdata/AdapterExamples/big-data/kafka 路径下找到这个文件:
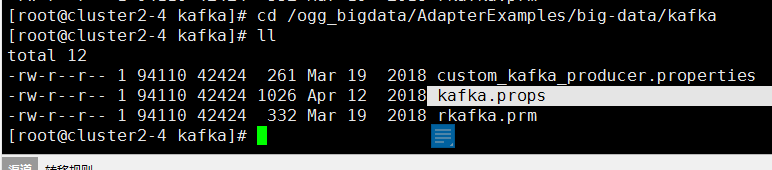
复制到dirprm路径下即可:
> cp ./kafka.props /ogg_bigdata/dirprm/
4、配置kafka.props和custom_kafka_producer.properties
A.kafka.props文件内容
gg.handlerlist=kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
gg.handler.kafkahandler.topicMappingTemplate=stu_ogg
gg.handler.kafkahandler.format=json
gg.handler.kafkahandler.mode=op
gg.classpath=dirprm/:/opt/cloudera/parcels/KAFKA-4.1.0-1.4.1.0.p0.4/lib/kafka/libs/*:/ogg_bigdata/:/ogg_bigdata/lib/*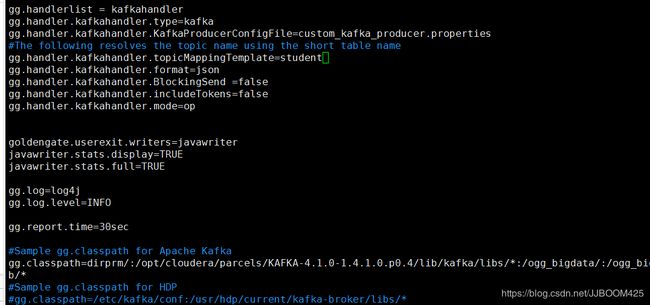
参数说明:
- gg.handlerlist :handler类型。
- gg.handler.kafkahandler.KafkaProducerConfigFile :kafka相关配置文件。
- gg.handler.kafkahandler.topicMappingTemplate :kafka的topic名称,无需手动创建。
- gg.handler.kafkahandler.SchemaTopicName :主题名称将在其中传递架构数据。如果未设置此属性,则不会传播架构。模式将仅针对Avro格式化程序传播。
- gg.handler.kafkahandler.format :传输文件的格式,支持json,xml,avro等。
- gg.handler.kafkahandler.mode :OGG for Big Data中传输模式,即op为一次SQL传输一次,tx为一次事务传输一次。
- gg.classpath :配置kafka和ogg的libs位置,用来读取相关的jar包。
注意:
a、gg.classpath配置kafka和ogg的libs位置,不然启动的时候读取不到相关jar包,会报错。
b、网上参考说需要其中四个jar包:kafka-clients-2.2.1-kafka-4.1.0.jar , lz4-1.5.0.jar , slf4j-api-1.7.25.jar , snappy-java-1.1.7.2jar。可以将这几个jar包复制到某一路径下,然后classpath指向这个路径即可。
c、我将gg.handler.kafkahandler.SchemaTopicName参数删了,因为使用的是json格式,不是Avro。
B.custom_kafka_producer.properties文件内容
bootstrap.servers=cluster2-4:9092
acks=1
compression.type=gzip
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
batch.size=102400
linger.ms=10000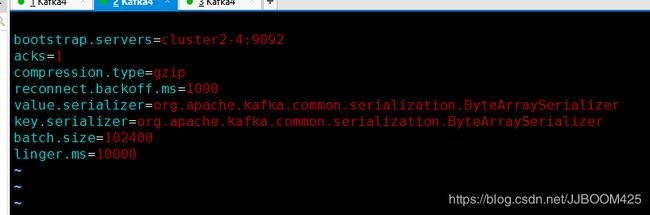
参数说明:
- bootstrap.servers :kafkabroker的地址
- compression.type :压缩类型
- reconnect.backoff.ms :重连延时
详细参考此文档:
docs.oracle.com/goldengate
5、添加trail文件到replicate进程
add replicat rekafka exttrail /ogg_bigdata/dirdat/to,checkpointtable ogg_student.checkpoint
6、启动进程
A.源端启动所有部署的进程,使用以下指令在源端的ggsci中启动进程
start mgr
start extkafka
start pukafka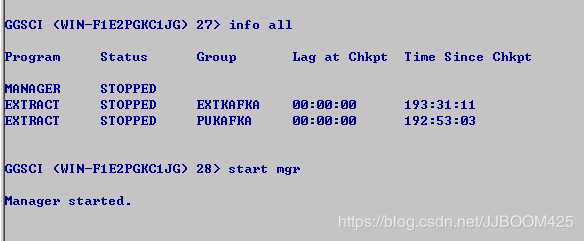
这里之前我启动extkafka时被拒绝了: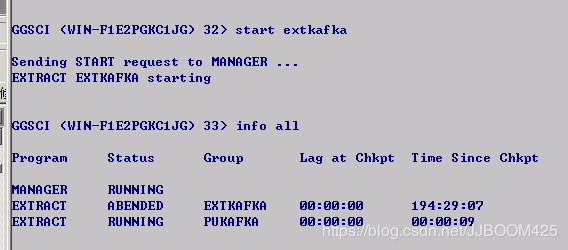
后面查看了安装ogg目录下的ggserr.log日志文件,发现报了这个错误:
The trail 'C:/OGG/dirdat/to' is not assigned to extract 'EXTKAFKA'. Assign the trail to the extract with the command "ADD EXTTRAIL/RMTTRAIL C:/OGG/dirdat/to, EXTRACT EXTKAFKA".
解决办法:
将之前我添加trail文件的定义与extract进程绑定时的指令 :add exttrail C:\OGG\dirdat\to,extract extkafka 中的 \ 改为 / 即可。
然后启动成功:
B.目标端启动部署的进程,使用以下指令字啊目标端的ggsci中启动进程
start mgr
start rekafka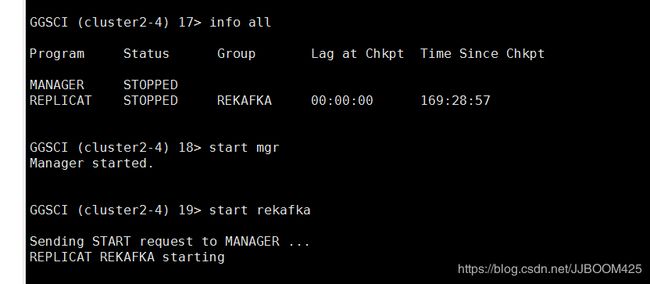
若有问题(窗口闪退,报错启动失败),可以查看系统日志:
1. windows下:
ogg目录下的ggserr.log日志文件,也可以在ggsci下使用下列命令查看:
view report extkafka --这个取决于你的名称是什么,比如是extkafka
2. linux下:
与windows相同,但是对于kafka报错可以去 ./dirrpt/XXXXX_info_log4j.log中查看。
启动成功则使用info all查看,进程全部正在运行:
7、数据测试
连接Oracle,可以插入或者修改数据,但是注意一定记得commit提交,才可以提交并监测到数据变化。可以发现源端和目标端的dirdat文件夹下生成了to000000的文件。
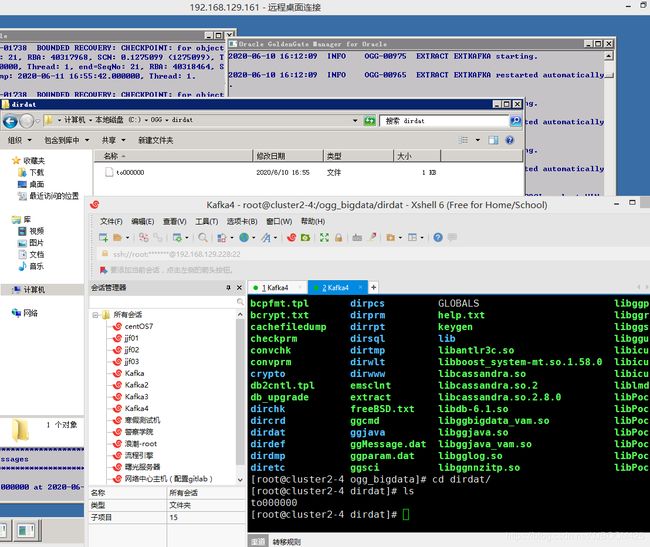
这里要注意,前面的服务器名要跟之前配置文件里写的一样,用localhost则会报错:
> kafka-console-consumer --bootstrap-server localhost:9092 --topic student --from-beginning会报错:
........
20/06/11 23:26:41 WARN clients.NetworkClient: [Consumer clientId=consumer-1, groupId=console-consumer-28300] Connection to node -1 (localhost/127.0.0.1:9092) could not be established. Broker may not be available.
........
解决办法——启动正确的消费者指令:
kafka-console-consumer --bootstrap-server cluster2-4:9092 --topic student --from-beginning
kafka接受到数据则测试成功。