淘宝双11大数据分析(数据准备篇)
文章目录
- 前言
- 数据内容分析
- `user_log.csv`文件内容含义
- `train.csv` 和 `test.csv` 文件内容含义
- 数据上传到Linux系统并解压
- 数据集的预处理
- 文件信息截取
- 导入数据到Hive中
- 确认 Hadoop 服务已启动
- 上传数据文件
- 在 Hive 上创建数据表
前言
阅读前,请先查看前篇:淘宝双11大数据分析(环境篇)
数据下载地址:百度云下载
另:为求方便行事,我这里的用户全是 root 用户(虽然超级不建议这麽玩)
数据内容分析
本案例采用的数据集压缩包为data_format.zip。
该数据集压缩包是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据有偏移,但是不影响实验的结果),里面包含3个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv.
user_log.csv文件内容含义
| 字段 | 含义 |
|---|---|
| user_id | 买家 id |
| item_id | 商品 id |
| cat_id | 商品类别 id |
| merchant_id | 卖家 id |
| brand_id | 品牌 id |
| month | 交易时间:月 |
| day | 交易时间:日 |
| action | 行为:取值为{0,1,2,3}。 其中0表示点击,1表示加入购物车,2表示购买,3表示关注商品 |
| age_range | 卖家年龄分段:1表示年龄小于18,2表示年龄是[18,24],3表示[25,29],4表示[30,34],5表示[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和 NULL 则表示未知 |
| gender | 性别:0表示女性,1表示男性,2和 NULL 表示未知 |
| province | 收货地址:省份 |
train.csv 和 test.csv 文件内容含义
这俩文件字段拥有相同的定义:
| 字段 | 含义 |
|---|---|
| user_id | 买家 id |
| age_range | 买家年龄分段:1表示年龄小于18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知 |
| gender | 性别:0表示女性,1表示男性,2和NULL表示未知 |
| merchant_id | 商家 id |
| label | 是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。 |
数据上传到Linux系统并解压
在 /usr 下新建一个目录taobao_data
[root@centos2020 spark-2.4.4-bin-hadoop2.7]# cd /usr/
[root@centos2020 usr]# mkdir taobao_data
使用 xftp上传压缩包到 taobao_data目录中:
[root@centos2020 taobao_data]# ls
data_format.zip
先在taobao_data创建一个 dataset 目录:
[root@centos2020 taobao_data]# ls
data_format.zip dataset
开始解压:
[root@centos2020 taobao_data]# unzip data_format.zip -d dataset
Archive: data_format.zip
inflating: dataset/test.csv
inflating: dataset/train.csv
inflating: dataset/user_log.csv
查看解压后的文件信息:
[root@centos2020 dataset]# ll
total 2790636
-rw-rw-r--. 1 root root 129452503 Mar 2 2017 test.csv
-rw-rw-r--. 1 root root 129759806 Mar 2 2017 train.csv
-rw-rw-r--. 1 root root 2598392805 Feb 23 2017 user_log.csv
查看文件的内容:
# 查看 user_log.csv 文件的前 5 条数据
[root@centos2020 dataset]# head -5 user_log.csv
user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province
328862,323294,833,2882,2661,08,29,0,0,1,内蒙古
328862,844400,1271,2882,2661,08,29,0,1,1,山西
328862,575153,1271,2882,2661,08,29,0,2,1,山西
328862,996875,1271,2882,2661,08,29,0,1,1,内蒙古
数据集的预处理
首先,在查看了前5条数据之后,发现,第一行是字段信息。
因此需要在处理数据之前,先把第一行的字段删除掉。
[root@centos2020 dataset]# sed -i '1d' user_log.csv
命令解释:
‘1d’ 表示删除第一行(如果是 '2d’ 就是删除第二行,依次类推)
查看删除后的结果(发现已经没有字段信息了):
[root@centos2020 dataset]# head -5 user_log.csv
328862,323294,833,2882,2661,08,29,0,0,1,内蒙古
328862,844400,1271,2882,2661,08,29,0,1,1,山西
328862,575153,1271,2882,2661,08,29,0,2,1,山西
328862,996875,1271,2882,2661,08,29,0,1,1,内蒙古
328862,1086186,1271,1253,1049,08,29,0,0,2,浙江
文件信息截取
截取的原因:因为数据量过大,我本机硬件的限制(怪我咯),因此需要将原数据进行截取。
原数据有100000条,现在需要截取 10000条数据。
因为可能会多次进行信息截取,因此写一个脚本predeal.sh。
[root@centos2020 taobao_data]# vim predeal.sh
脚本的内容是:
#!/bin/bash
#下面设置输入文件,把用户执行predeal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile
授权执行:
[root@centos2020 taobao_data]# chmod +x predeal.sh
[root@centos2020 taobao_data]# ll
total 598264
-rw-r--r--. 1 root root 612614352 Feb 25 22:03 data_format.zip
drwxr-xr-x. 2 root root 59 Feb 25 22:19 dataset
-rwxr-xr-x. 1 root root 602 Feb 25 23:00 predeal.sh
[root@centos2020 taobao_data]# ./predeal.sh ./dataset/user_log.csv ./dataset/small_user_log.csv
# 确认是否截取数据成功
[root@centos2020 taobao_data]# cd dataset/
[root@centos2020 dataset]# head -5 small_user_log.csv
328862,406349,1280,2700,5476,11,11,0,0,1,四川
328862,406349,1280,2700,5476,11,11,0,7,1,重庆市
328862,807126,1181,1963,6109,11,11,0,1,0,上海市
328862,406349,1280,2700,5476,11,11,2,6,0,台湾
328862,406349,1280,2700,5476,11,11,0,6,2,甘肃
导入数据到Hive中
将 small_user_log.csv 文件中的数据导入到 Hive 数据仓库中。
这个过程分成2步:
- 把目标文件上传到 HDFS 中。
- 在 Hive 中建立 2 个外部表以完成数据的导入。
确认 Hadoop 服务已启动
[root@centos2020 dataset]# jps
11408 Master
12321 Jps
7876 NameNode
8183 ResourceManager
7930 DataNode
8477 NodeManager
11550 Worker
看到 NameNode,NodeManager,DataNode 等服务已经启动。
上传数据文件
首先在 HDFS 上创建目录 /taobao_data/dataset/user_log
在 Hadoop 安装目录下使用以下命令:
[root@centos2020 hadoop-2.7.7]# ./bin/hdfs dfs -mkdir -p /taobao_data/dataset/user_log
接着使用命令上传文件到 HDFS:将Linux中的small_user_log.csv 文件上传到HDFS 文件目录/taobao_data/dataset/user_log 中。
[root@centos2020 hadoop-2.7.7]# ./bin/hdfs dfs -put /usr/taobao_data/dataset/small_user_log.csv /taobao_data/dataset/user_log
确认上传成功:
可以选择使用命令或使用图形化界面。
使用命令查看 HDFS 上的 small_user_log.csv 文件的前10行记录:
[root@centos2020 hadoop-2.7.7]# ./bin/hdfs dfs -cat /taobao_data/dataset/user_log/small_user_log.csv | head -10
328862,406349,1280,2700,5476,11,11,0,0,1,四川
328862,406349,1280,2700,5476,11,11,0,7,1,重庆市
328862,807126,1181,1963,6109,11,11,0,1,0,上海市
328862,406349,1280,2700,5476,11,11,2,6,0,台湾
328862,406349,1280,2700,5476,11,11,0,6,2,甘肃
328862,406349,1280,2700,5476,11,11,0,4,1,甘肃
328862,406349,1280,2700,5476,11,11,0,5,0,浙江
328862,406349,1280,2700,5476,11,11,0,3,2,澳门
328862,406349,1280,2700,5476,11,11,0,7,1,台湾
234512,399860,962,305,6300,11,11,0,4,1,安徽
cat: Unable to write to output stream.
使用图形化界面:访问 50070 端口。
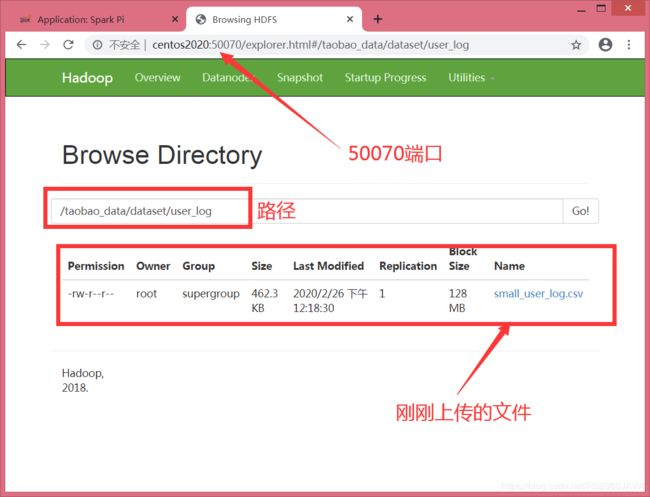
在 Hive 上创建数据表
首先启动 mysql 数据库,因为 Hive 的元数据配置到了 mysql 上。
然后得确认 Hadoop 服务已经启动(使用 jps 命令查看服务即可)。
[root@centos2020 hadoop-2.7.7]# service mysql start
Redirecting to /bin/systemctl start mysql.service
启动 Hive :
[root@centos2020 apache-hive-2.3.6-bin]# ./bin/hive
在 Hive 中创建数据库 dbtaobao:
hive> create database dbtaobao;
OK
Time taken: 13.067 seconds
hive> use dbtaobao;
OK
Time taken: 0.051 seconds
在 dbtaobao 中创建一个外部表 user_log:
该表字段包含:user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province。
建表语句是:
create external table dbtaobao.user_log
(
user_id INT,
item_id INT,
cat_id INT,
merchant_id INT,
brand_id INT,
month STRING,
day STRING,
action INT,
age_range INT,
gender INT,
province STRING
) comment 'this is action what create dbtaobao.user_log' row format delimited fields terminated by ',' stored as textfile location '/taobao_data/dataset/user_log';
建表之后,查看表中的前10条内容:
hive> select * from user_log limit 10;
OK
328862 406349 1280 2700 5476 11 11 0 0 1 四川
328862 406349 1280 2700 5476 11 11 0 7 1 重庆市
328862 807126 1181 1963 6109 11 11 0 1 0 上海市
328862 406349 1280 2700 5476 11 11 2 6 0 台湾
328862 406349 1280 2700 5476 11 11 0 6 2 甘肃
328862 406349 1280 2700 5476 11 11 0 4 1 甘肃
328862 406349 1280 2700 5476 11 11 0 5 0 浙江
328862 406349 1280 2700 5476 11 11 0 3 2 澳门
328862 406349 1280 2700 5476 11 11 0 7 1 台湾
234512 399860 962 305 6300 11 11 0 4 1 安徽
Time taken: 3.761 seconds, Fetched: 10 row(s)
如此,数据就准备好了。