基于人工分析的HTTP-POST请求报文特征获取一般方法
基于人工分析的HTTP-POST请求报文特征获取一般方法
(以百度贴吧客户端发帖行为分析为例)
本文由CSDN-蚍蜉撼青松 【主页:http://blog.csdn.net/howeverpf】原创,转载请注明出处!
现有的HTTP-POST请求报文信息还原工具都是基于特征(包括网络应用的行为识别特征与信息提取特征)的,而特征的获取往往依赖于人工分析。在分析的过程中往往需要用到一些能帮助完成网络数据采集和分析功能的工具。根据网络环境的不同,可能用到的几款工具包括:
- Tcpdump(Unix/Linux平台上最常用的网络数据包捕获工具)
- Aircrack(WiFi环境下最常用的无线数据包嗅探解密工具)
- Wireshark(Windows平台上最好用的网络数据包嗅探与分析工具)
下面以分析百度贴吧客户端的发帖为例,说明这种基于人工分析获取HTTP-POST请求报文特征的一般流程:
首先,分析者需要构造测试帖子并提交给服务器。为了后续流程分析方便,一般要求测试帖子的标题和内容都尽量有规律,易识别。本文在Linux吧构造了一条标题为“新人报道”,内容为“fresh man, coming!”的帖子,如图1。
图1 使用百度贴吧客户端在Linux吧发帖
分析者在向服务器提交测试数据的同时,根据网络环境的不同选用合适的数据包捕获工具(WireShark / TcpDump / Aircrack)采集客户端发送的数据包,并以pcap文件等通用格式保存下来。
分析者使用网络协议分析工具(WireShark等)在捕获的数据包里搜索自己构造的测试数据。如果搜索失败,分析者需要使用一些编码工具对测试数据进行常见的编码处理(如URL编码、Base64编码、QP编码、Unicode编码、MD5散列、SHA1散列),并重新搜索经各种编码变形后的测试数据,直到搜索成功。
分析者根据所找到的数据包的四元组信息(即源IP地址、目的IP地址、源TCP端口号、目的TCP端口号),使用网络协议分析工具(WireShark等)重组该数据包所在的TCP流。前文所构造的测试数据,其所在的TCP流重组结果如图2所示,

图2 百度贴吧客户端发帖产生的HTTP-POST请求报文
分析者提取出请求行的请求方法“POST”、URI的路径部分“/c/c/thread/add”,以及Host头域的值“c.tieba.baidu.com”,猜测将这三者联合在一起,应该可以通过这三个特征唯一的确定一个百度贴吧客户端的发帖行为。初步得出结论,可能这就是所要找的行为识别特征。
分析者提取出Content-Type头域的值,确认消息实体采用的是application/ x-www-form-urlencoded格式,并在请求实体中找到经URL编码后的发帖标题“%E6%96%B0%E4%BA%BA%E6%8A%A5%E9%81%93”和帖子内容“fresh+ man%2C+coming%21”。分析者通过观察发帖标题、帖子内容前后的数据,根据经验进行取舍,初步得出发帖标题的信息提取前缀为“title=”,帖子内容的信息提取前缀为“content=”,二者的信息提取后缀均为“&”。这些前后缀可能就是所要找的信息提取特征。
分析者继续分析这个请求报文的头部和消息实体,根据经验从中找出其他可能有用的信息,并初步得出这些信息相应的提取特征。对于前文所举例子来说,这些可能有用的信息以及它们可能的信息提取特征如表1所示。
表1 百度贴吧客户端发帖请求报文中可能有效的信息及其提取特征
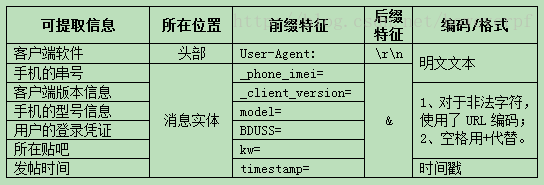
分析者构造其他发帖行为的测试数据,根据前面初步得出的行为识别特征和内容提取特征看是否发生漏检。即,没有识别出所有发帖行为,或没能提取出所有测试数据中的有效信息。如果发生,则需要根据漏检的测试数据对前面得出的特征进行修改,直到没有漏检为止。
分析者构造一些非发帖行为的测试数据,根据前面得出的行为识别特征和内容提取特征看是否发生误检。即,将非发帖行为识别为发帖行为,或将测试数据中的无效信息当成有效信息提取出来。如果发生,则需要根据误检的测试数据对前面得出的特征进行修改,直到没有误检为止。
至此,一次完整的人工分析过程介绍完毕。
需要补充说明的是,前文所举的例子中,要提取的有效信息刚好都是明文文本,且都有前后缀。但在实际的情况往往会更复杂,例如:
- 有些有效信息没有统一的前缀特征,这时可以尝试根据一些有特殊标志的位置(如请求头起始位置,请求实体起始位置,multipart/form-data格式的子段数据起始位置),计算有效信息相对这些位置的偏移量。如果能找到不同测试数据中有效信息相对某位置固定的偏移量,则这个偏移量就可以取代提取前缀,作为信息提取特征的一部分。
- 有些有效信息没有统一的后缀特征,这时可以尝试在有效信息的上下文中寻找是否存在关于信息长度的说明(如,chunked编码后的部分实体);还可以尝试计算不同测试数据中有效信息是否存在固定的长度(如,口令的散列值、经纬度信息、时间戳),如果可以找到这些关于有效信息长度的确定值或计算方法,则其长度就可以取代提取后缀,作为信息提取特征的一部分。
- 有些有效信息所在的请求实体使用了XML、JSON等比较复杂的格式,其提取特征不能简单地依赖前后缀、偏移量、信息长度等,而是要基于这些格式本身做解析。
- 有些有效信息是人眼不可识别的二进制流,而非可读明文文本。不过,这种情况多见于HTTP响应报文中,在HTTP-POST请求报文中比较少见。
By The Way
本文只为技术分享,作者本人一向认为,技术本身是没有好坏的,关键在于人心!
:)希望看到本文的读者也能认同我这个观点~
------本文由CSDN-蚍蜉撼青松【主页:http://blog.csdn.net/howeverpf】原创,转载请注明出处!------