1.DataFrame使用unionAll算子
java.util.concurrent.ExecutionException: org.apache.spark.sql.AnalysisException: Union can only be performed on tables with the same number of columns, but the left table has 44 columns and the right has 45;
问题描述:unionAll需要两个DataFrame拥有一样的列,如果连接两个表,则需要两个表字段数量一致。如果不一致,则可以采取一些处理方法:加载的时候加载的字段一致。该算子本人经常使用,但是还是踩了坑:如下,我需要将一个天表数据按照一个小时为粒度取出,分开进行hiveSql运算,合并接着运算,最终得到一个DF,但是由于经过hiveContext.sql之后的字段有了改变,所以,这个坑还是无意外的踩了。

解决方法:可以对每个小时的数据进行取出,得到df1(原始数据集),进行hiveContext.sql操作,得到df2,此时df1与df2字段个数不同,将df2存进DataFrame数组dfs,然后依次将24小时存进数组dfs。此时dfs一共拥有24个df2字段数一直的DataFrame。
此时,可遍历依次将dfs[index]的数据集unionAll操作,sql操作,得到新的DataFrame。
此方法可以解决大的DataFrame计算完,无法进行存储的缺陷。(为什么这么说,如果一次性加载一天的数据,数据量大概为3000W条,字段数为12个,通过计算,主要是hiveContext.sql计算,得到480W数据量,此时DataFrame好像只有count操作能够执行,其它的都执行不了。也不能进行forEachPartition操作,这是因为JVM内存限制,可能跟设置无关,因为我需要将计算结果入库,所以必须要实现DataFrame进行forEachPartition)。代码做了一点优化,将每小时的数据合并成每六小时。
为什么一定要这么实现dataFrame入库(mysql)?
本人尝试:①使用原生的dataframe.jdbc,结果:入库慢,一般地10万数据,几十个字段,使用forEachPartition批量入,大概10s,使用官方jdbc需要3~4min。最重要的是也无法对我实际中产生的数据入库。(一条都没入库,处于计算完待入库,转换过程中歇菜~)
②原来的入库方式是dataFrame.toJavaRdd().forEachPartition(),对小数据量能入,对计算量大数据量大的不能入,观察sparkUI发现,卡在.toJavaRdd算子上,所以想改造dataFrame直接入库,dataFrame.forEachPartition形式。实现scala.Function1类即可。结果:与DataFrame.toJavaRdd一样入不了库,通过查看源码发现,基本所有的dataFrame算子都会转换成rdd的形式,此例子的也是。
③为什么dataFrame可以count却不能进行其他算子操作,想去模仿count的实现(scala实现),发现是空指针。。
④大的dataFrame转换成小的dataFrame,尝试dataFrame.randomSplit操作,将分割成若干个小df,结果表明,任何想要操作大dataFrame的行为都是不可行的!
⑤所以,只能将小的dataFrame计算完,与其他小的dataFrame.unionAll的方式,进行处理。我们此处是数据量经过处理一定会变小,1+1<2的形式,经过实践,此方法可行,就是时间很慢,计算需要7s,计算完到入库完,需要7~8min.
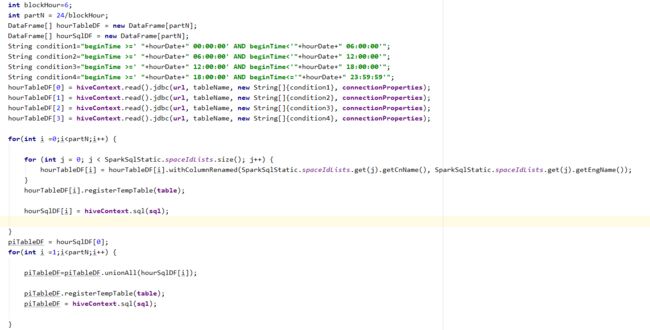
原因:DataFrame不是不能够对大数据量的数据表进行操作,而是需要提高加载并行度,将数据分布到各个执行器上,hiveContext.read().jdbc算是转换算子,会惰性执行,可以将加载后的数据进行缓存提高速度。
2.说到forEachPartition入库操作,就得顺带一提序列化陷阱。
使用forEachPartition对每个分区的数据进行存储操作,传入forEachPartition匿名类的所有参数对象都必须序列化,dataSource是一定传不了的,还想着少建立与数据库连接,此时为空指针,需要在匿名类内创建。还有日志也是打印不了的,可以传递些字符串或者自定义序列化过的bean等。
3.提高Spark并行度
①设置参数:
spark.default.parallelism=60 (应该为总executor-cores的2~3倍,官方推荐)
spark.sql.shuffle.partitions = 60
只有在shuffle操作之后生效;
②如果数据在HDFS上,增大block;
③如果数据是在关系数据库上,增加加载并行度,应该是有四种方式增大并行度;
④RDD.repartition,给RDD重新设置partition的数量;
⑤reduceByKey的算子指定partition的数量;
val rdd2 = rdd1.reduceByKey(_+_,10)
⑥val rdd3 = rdd1.join(rdd2) rdd3里面partiiton的数量是由父RDD中最多的partition数量来决定,因此使用join算子的时候,增加父RDD中partition的数量。
参考博客:https://www.cnblogs.com/haozhengfei/p/e19171de913caf91228d9b432d0eeefb.html
4.hdfs错误
Caused by: java.io.IOException: Filesystem closed
原因:多个datanode在getFileSystem过程中,由于Configuration一样,会得到同一个FileSystem。如果有一个datanode在使用完关闭连接,其它的datanode在访问就会出现上述异常
解决办法:
在hdfs core-site.xml里把fs.hdfs.impl.disable.cache设置为true
5.dataFrame.write().mode("overwrite").text(hdfspath);
org.apache.spark.sql.AnalysisException: Text data source supports only a single column, and you have 6 columns.;
dataFrame只能保存一列数据,如果仍需要保存多列数据,则将多列数据合并成一列,再保存;
或者转换为RDD再保存:
dataFrame.toJavaRDD().saveAsTextFile(hdfsPath);
6.DataFrame超过200列(>200columns)无法缓存,超过8117列无法计算。
来源:https://issues.apache.org/jira/browse/SPARK-16664