python爬虫从0到1遇到问题及解决方向
一.环境介绍
1.由于使用惯了Eclipse,我直接在里面装了个pydev,当初装的时候遇到些版本兼容问题,请大家装的时候一定要根据自己python版本来装,我的是python2.7.X,注意在线安装有个小坑,如下图:
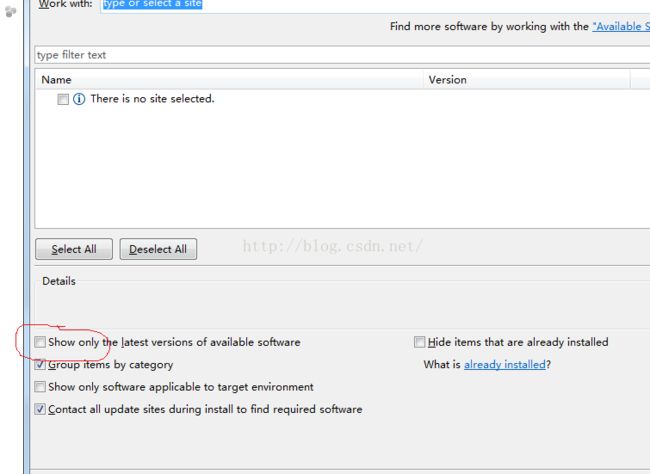
这是自动屏蔽旧版本,如果不注意会装错至最新,除了以上装法,还有就是自己下载,解压到Eclipse安装
文件的plugins文件下。
二.python扩展工具包的使用和爬虫整体思路

1.网页下载器
可以用py自带的urllib2,直接import使用即可,本文使用扩展的respects来充当下载器(因为功能比较强大,还有其他一些功能,如post),下载方式比较简单,可以用pip命令(本人的不知道怎么用不了,出现奇怪异常)不过可能会撞墙,推荐http://www.lfd.uci.edu/~gohlke/pythonlibs/找到相应的包,把后缀改为ZIP解压到py的Lib中即可。
2.网页解析器
主要用2种,都是扩展的(py不自带),beautifulsoup4和xpath,个人感觉后一种好用一点,后面会具体介绍。
3.URL管理器
这个是自己用2个Set实现的,一个存放即将使用的URL,一个存放使用过的URL(不然可能在一个网页循环爬取)。
三.实战爬取起点高质量小说
1.爬取前的准备
由于我爬取的是起点的玄幻小说为主,所以我的起始URL为:
http://book.qidian.com/info/1004608738
然后观察每个小说的URL 发现都是http://book.qidian.com/info/数字 格式,所以在每个页面URL可以正则匹配,看是否符合格式。
2.核心代码,主模块
while self.urls.has_new_url():
try:
#从URL管理器取出URL
new_url = self.urls.get_new_url()
#输出当前爬取进度
print 'craw %d : %s ;success :%d '%(sumcount,new_url,count)
#网页下载器获取HTML页面
html_cont = self.downloader.download(new_url)
#网页解析器获取数据和URL
new_urls,new_data = self.parser.parse(new_url,html_cont.text,word_click_back[0])
#将URL添加进URL管理器
self.urls.add_new_urls(new_urls)
#将数据存放在output中
if new_data is not None:
count = self.outputer.collect_data(new_data,count,basescore,basewordcount,basewordclick)
if count > sum:
break
sumcount+=1
except:
print 'craw failed' 3.网页解析器模块
(1)2种解析器
①beautifulsoup4可以把HTML文件解析成DOM树,可以像访问树一样,通过find方法一层层访问,如
title_node = soup.find('div',class_="book-info").find("h1").find("em")...
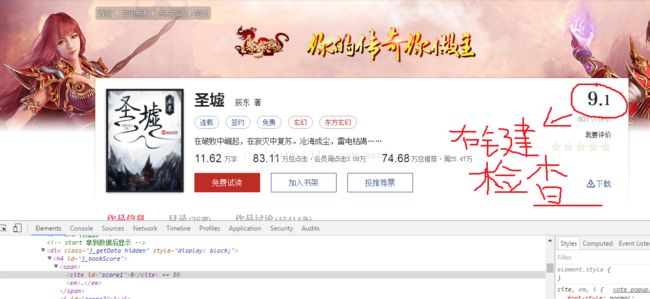
②Xpath定位神器,可以直接定位所需信息,结合chrome浏览器的copy Xpath简直不要太简单,下面写Xpath用法
如下图,匹配一个分数:
(2).检查
(3).找到所需标签,右键复制xpath,得到一串匹配字符串
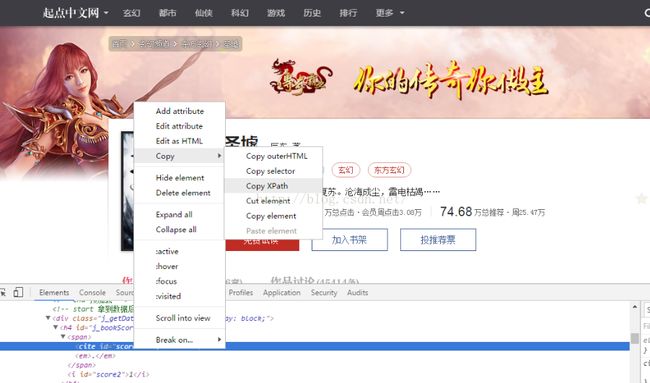
(4).得到字符串(//*[@id="score1"]),写代码
html_cont = requests.get(page_url,timeout=0.5)
selector = etree.HTML(html_cont.text)
word_count = selector.xpath('//*[@id="score1"]/text()')
res_data['word_count']=word_count[0](5).贴出解析器核心方法代码(前面使用bs4,后面使用Xpath)
def _get_new_data(self, page_url, soup,word_click_back):
res_data = {}
score = 0
res_data['url'] = page_url
# 小说名
title_node = soup.find('div',class_="book-info").find("h1").find("em")
res_data['title'] = title_node.get_text()
#小说简介
summary_node = soup.find('p',class_="intro")
res_data['summary'] = summary_node.get_text()
#获取getURL,获取预加载数据
score_url=self._get_score_url(page_url)
res_data['score']=0
if score_url is not None:
score_cont = requests.get(score_url,timeout=0.5)
try:
score=re.search('rate":(.*?),', score_cont.text, re.S).group(1)
except:
score=0
#以下使用Xpath
res_data['score']=score
#获取字数信息
html_cont = requests.get(page_url,timeout=0.5)
selector = etree.HTML(html_cont.text)
word_count = selector.xpath('/html/body/div[2]/div[6]/div[1]/div[2]/p[3]/em[1]/text()')
res_data['word_count']=word_count[0]
#获取"万总点击",将值赋给res_data['word_click_num']
word_click_back1= selector.xpath('/html/body/div[2]/div[6]/div[1]/div[2]/p[3]/cite[2]/text()')
word_click_num1= selector.xpath('/html/body/div[2]/div[6]/div[1]/div[2]/p[3]/em[2]/text()')
if word_click_back1[0]==word_click_back:
res_data['word_click_num']=word_click_num1[0]
else:
res_data['word_click_num']=None
#获取小说类别
book_category = selector.xpath('/html/body/div[2]/div[6]/div[1]/div[2]/p[1]/a[1]/text()')
res_data['book_category']=book_category[0]
return res_data 4.成果展示,爬取10个符合条件的小说,条件可以自己设置,主要从字数,点击,评分来判定,
这里设置字数10W以上,分数9以上,总点击50W以上
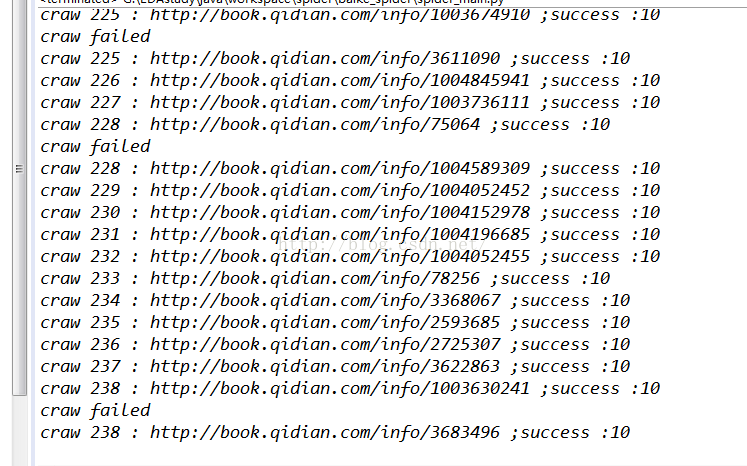
控制台可以看到,这里爬取了超过238个页面才找到10本符合条件的小说
继续看成果

5.遇到的问题
(1)python中爬取的数据返回值类型是_ElementStringResult,和int String难匹配,只能强制转换
如:float() str()
(2)异步加载和简单反爬虫
有些网页是ajax异步加载,你要post一些数据之后,他才能返回你想要的一些数据,具体可以通过chrome的
Network来查看提交了什么数据
然后构造一个字典,通过requests.post提交上去,就可以得到想要的返回资源。
同理有些反爬虫要提交HTTP报头也是如此
(3)预加载
这个问题从一开始就存在,困扰了我好几天,爬虫也被迫中断,主要的表现是
爬取分数score 浏览器可以返回正常数据,但是我爬取到的数据一直是0!?
之后我在问题(2)中得到启发,发现它每次刷新都会发出一个根据uuid发出的
GET请求,然后数据才从那个response返回

http://book.qidian.com/ajax/comment/index?_csrfToken=hRMAi3nDUU6l7ZJo3hOcTeqXlFOcgJI8ZzGepfcq&bookId=1004608738&pageSize=15
然后response里面包含我想要的分数数据,如下:

之后我就每个URL都构造一个这样的请求来获取分数数据,如下
url="http://book.qidian.com/ajax/comment/index?_csrfToken=hRMAi3nDUU6l7ZJo3hOcTeqXlFOcgJI8ZzGepfcq&bookId="
id=re.search('info/(\d+)', page_url, re.S).group(1)
url=url+id好,问题解决
四.爬虫进阶展望
(1)速度,这次爬取10本小说,总共爬取238+页面,耗时2分钟,实在难以想象爬取大量页面的耗时,
可以用多线程Pool加以改进,虽然python的多线程不是真正的多线程,但是也会大大提高速度。
(2)反爬虫
主要是代理,IP什么的,不过我想一般的网站也不会考虑这么多吧,程序员本身够辛苦了,再考虑这些,真是累死猿了,想想自己也朝着这方面走。。。。
(3)账号密码提交,验证码
这个是以后主要方向,验证码最好爬取出来人工处理
本人小菜,欢迎指正交流,账号名即qq,有错别字下次再改,先将就着看
github源码:
https://github.com/bo07997/algorithm-