Python 高级编程之多线程、多进程和线程池编程
多线程、多进程和线程池编程
- 1. GIL
- 2. 多线程编程
- 2.1 通过Thread类实例化
- 2.2 通过继承Thread来实现多线程
- 3. 线程间通信
- 3.1 通过共享变量方式
- 3.2 通过 queue 的方式进行线程间同步
- 4. 进程间同步
- 4.1 Lock 和 RLock
- 4.2 condition
- 4.3 Semaphore
- 5 线程池
- 5.1 done, cancel, 和 result 三个方法
- 5.2 获取成功执行的线程返回值
- 5.2.1 使用 as_completed 方法
- 5.2.2 使用 map 方法完成
- 5.3 等待特定的线程执行完,再向下执行
- 5.4 分析线程池源码 (重点)
- 6. 多进程编程
- 6.1 对于耗费 cpu 的操作,多进程优于多线程
- 6.2 对于 io 操作来说,多线程优于多进程
- 6.3 fork 与多进程的区别
- 6.4 multiprocessing
- 6.5 进程池
- 6.6 imap 和 imap_unordered
- 6.7 进程间通信
- 6.7.1 使用 multiprocessing 中的 Queue
- 6.7.2 使用 Pipe
- 6.7.3 使用 Manager() 中的数据结构
- 7. Summary
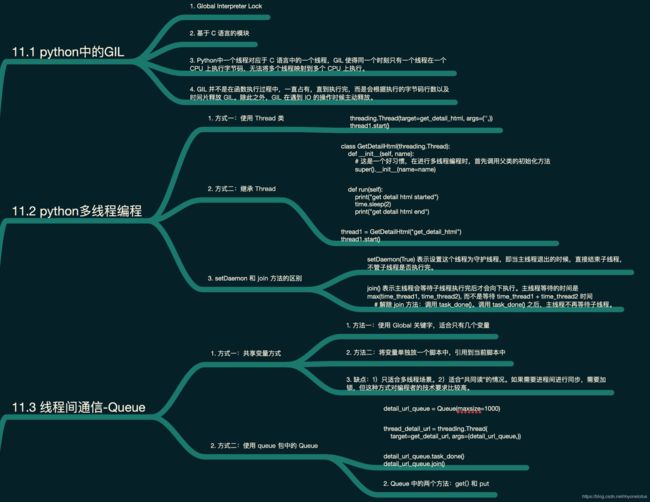
1. GIL
GIL 全称:global interpreter lock 这是一个基于 C 语言的模块。python中一个线程对应于c语言中的一个线程。GIL 使得同一个时刻只有一个线程在一个cpu上执行字节码, 无法将多个线程映射到多个cpu上执行
# 使用 dis 模块打印函数的字节码
# import dis
# def add(a):
# a = a+1
# return a
#
# print(dis.dis(add))
GIL 并不是在函数执行过程中,一直占有,直到执行完,而是会根据执行的字节码行数以及时间片释放gil。除此之外,gil在遇到io的操作时候主动释放。下面的代码演示了 total 每次运行后的结果都不一样,这说明了 GIL 并不是一直占有的,而是根据时间片和字节码释放 GIL。
import threading
total = 0
def add():
# 1. dosomething1
# 2. io操作
# 1. dosomething3
global total
for i in range(1000000):
total += 1
def desc():
global total
for i in range(1000000):
total -= 1
thread1 = threading.Thread(target=add)
thread2 = threading.Thread(target=desc)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(total)
2. 多线程编程
对于io操作来说,多线程和多进程性能差别不大。
2.1 通过Thread类实例化
比较简单的任务或者动态创建线程或者线程池时,可能会使用这种方式。
import time
import threading
def get_detail_html(url):
print("get detail html started")
time.sleep(2)
print("get detail html end")
def get_detail_url(url):
print("get detail url started")
time.sleep(4)
print("get detail url end")
if __name__ == "__main__":
# 方式一:通过Thread类实例化
# 注意这里面传入的是函数名,而不是函数的调用
thread1 = threading.Thread(target=get_detail_html, args=('',))
thread2 = threading.Thread(target=get_detail_url, args=('',))
# setDaemon(True) 表示设置这个线程为守护线程,即当主线程退出的时候,直接结束子线程,不管子线程是否执行完。
# thread1.setDaemon(True)
# thread2.setDaemon(True)
start_time = time.time()
thread1.start()
thread2.start()
# join() 表示主线程会等待子线程执行完后才会向下执行。
# 下面两行设置后,主线程会等待 thread1 和 thread2都执行完,才执行后面的 print 语句。
# 并且,主线程等待的时间是 max(time_thread1, time_thread2), 而不是等待 time_thread1 + time_thread2 时间
# 解除 join 方法:调用 task_done()。调用 task_done() 之后,主线程不再等待子线程。
thread1.join()
thread2.join()
# 当主线程退出的时候, 子线程kill掉
print("last time: {}".format(time.time()-start_time))
2.2 通过继承Thread来实现多线程
大部分情况,都是使用这种方式。
import time
import threading
class GetDetailHtml(threading.Thread):
def __init__(self, name):
# 这是一个好习惯,在进行多线程编程时,首先调用父类的初始化方法
super().__init__(name=name)
def run(self):
print("get detail html started")
time.sleep(2)
print("get detail html end")
class GetDetailUrl(threading.Thread):
def __init__(self, name):
super().__init__(name=name)
def run(self):
print("get detail url started")
time.sleep(4)
print("get detail url end")
if __name__ == "__main__":
# 方式二:通过集成Thread来实现多线程
thread1 = GetDetailHtml("get_detail_html")
thread2 = GetDetailUrl("get_detail_url")
# setDaemon(True) 表示设置这个线程为守护线程,即当主线程退出的时候,直接结束子线程,不管子线程是否执行完。
# thread1.setDaemon(True)
# thread2.setDaemon(True)
start_time = time.time()
thread1.start()
thread2.start()
# join() 表示主线程会等待子线程执行完后才会向下执行。
# 下面两行设置后,主线程会等待 thread1 和 thread2都执行完,才执行后面的 print 语句。
# 并且,主线程等待的时间是 max(time_thread1, time_thread2), 而不是等待 time_thread1 + time_thread2 时间
# 解除 join 方法:调用 task_done()。调用 task_done() 之后,主线程不再等待子线程。
thread1.join()
thread2.join()
# 当主线程退出的时候, 子线程kill掉
print("last time: {}".format(time.time()-start_time))
3. 线程间通信
本篇中,本小节之后的所有部分都需要扎实的操作系统知识。Prerequisite:https://blog.csdn.net/kisslotus/article/details/84503886
3.1 通过共享变量方式
通过 global 关键字,多个线程对一个变量共同读的方式。这种方式是适合“共同读”的情况。如果需要进程间进行同步,需要加锁,但这种方式对编程者的技术要求比较高。
如果共享变量很多时,可以把变量单独放到一个文件中,便于管理。
这里有一个坑需要注意,在从其他文件中引用变量时,使用 from chapter11 import variables
# 线程间通信
import time
import threading
# 下面这一行代码,不要这样使用:from chapter11.variables import detail_url_list
# 这种做法的坏处就是:当另一个线程修改了 detail_url_list 这个变量,我们看不到了。
# 但是,下面这一行的这种使用方法,在 detail_url_list = variables.detail_url_list 这一行中,
# 如果其他线程修改了 detail_url_list,我们就能通过 detail_url_list 看得到。
from chapter11 import variables
from threading import Condition
# 1. 生产者当生产10个url以后就就等待,保证detail_url_list中最多只有十个url
# 2. 当url_list为空的时候,消费者就暂停
def get_detail_html(lock):
# 爬取文章详情页
# 互斥变量
detail_url_list = variables.detail_url_list
while True:
if len(variables.detail_url_list):
lock.acquire()
if len(detail_url_list):
# 每次弹出从 list 中弹出一个元素
url = detail_url_list.pop()
lock.release()
# for url in detail_url_list:
print("get detail html started")
time.sleep(2)
print("get detail html end")
else:
lock.release()
time.sleep(1)
def get_detail_url(lock):
# 爬取文章列表页
# 互斥变量
detail_url_list = variables.detail_url_list
while True:
print("get detail url started")
time.sleep(4)
for i in range(20):
lock.acquire()
if len(detail_url_list) >= 10:
lock.release()
time.sleep(1)
else:
detail_url_list.append(
"http://projectsedu.com/{id}".format(id=i))
lock.release()
print("get detail url end")
# 1. 线程通信方式- 共享变量
# 一般不建议使用共享变量的方式进行线程通信,除非对锁有比较扎实的了解
if __name__ == "__main__":
lock = RLock()
thread_detail_url = threading.Thread(target=get_detail_url, args=(lock,))
for i in range(10):
html_thread = threading.Thread(target=get_detail_html, args=(lock,))
html_thread.start()
# # thread2 = GetDetailUrl("get_detail_url")
start_time = time.time()
# thread_detail_url.start()
# thread_detail_url1.start()
#
# thread1.join()
# thread2.join()
# 当主线程退出的时候, 子线程kill掉
print("last time: {}".format(time.time()-start_time))
3.2 通过 queue 的方式进行线程间同步
# 2. 通过queue的方式进行线程间同步
from queue import Queue
import time
import threading
def get_detail_html(queue):
# 爬取文章详情页
while True:
url = queue.get()
# for url in detail_url_list:
print("get detail html started")
time.sleep(2)
print("get detail html end")
def get_detail_url(queue):
# 爬取文章列表页
while True:
print("get detail url started")
time.sleep(4)
for i in range(20):
queue.put("http://projectsedu.com/{id}".format(id=i))
print("get detail url end")
if __name__ == "__main__":
detail_url_queue = Queue(maxsize=1000)
thread_detail_url = threading.Thread(
target=get_detail_url, args=(detail_url_queue,))
for i in range(10):
html_thread = threading.Thread(
target=get_detail_html, args=(detail_url_queue,))
html_thread.start()
# # thread2 = GetDetailUrl("get_detail_url")
start_time = time.time()
# thread_detail_url.start()
# thread_detail_url1.start()
#
# thread1.join()
# thread2.join()
detail_url_queue.task_done()
detail_url_queue.join()
# 当主线程退出的时候, 子线程kill掉
print("last time: {}".format(time.time()-start_time))
4. 进程间同步
RLock 是基于 Lock 实现的。Condition 是基于 Lock 和 RLock 实现的。Semaphore 是基于 Condition 实现的。
4.1 Lock 和 RLock
使用 Lock 或者 RLock 完成进程的同步,对互斥资源使用 acquire 加锁,使用 release 释放锁。acquire 不可以连续多次调用。
RLock 表示可重入的锁,可以连续多次调用 acquire,但是一定要注意acquire的次数要和release的次数相等。RLock 更常用。
import threading
from threading import Lock, RLock, Condition
# RLock 表示可重入的锁
# 在同一个线程里面,可以连续调用多次acquire, 一定要注意acquire的次数要和release的次数相等。
# 注意,这里是同一个线程,并不是多个线程之间可以调用多次
total = 0
lock = RLock()
def add():
# 1. dosomething1
# 2. io操作
# 1. dosomething3
global lock
global total
for i in range(1000000):
lock.acquire()
total += 1
lock.release()
def desc():
global total
global lock
for i in range(1000000):
lock.acquire()
total -= 1
lock.release()
thread1 = threading.Thread(target=add)
thread2 = threading.Thread(target=desc)
thread1.start()
thread2.start()
#
thread1.join()
thread2.join()
print(total)
# 1. 用锁会影响性能
# 2. 锁会引起死锁
# 死锁的情况 A(a,b)
"""
下面的代码会出现循环等待情况,导致死锁
A(a、b)
acquire (a)
acquire (b)
B(a、b)
acquire (a)
acquire (b)
"""
4.2 condition
用于进程间的复杂通信
import threading
# 条件变量, 用于复杂的线程间同步
# class XiaoAi(threading.Thread):
# def __init__(self, lock):
# super().__init__(name="小爱")
# self.lock = lock
#
# def run(self):
# self.lock.acquire()
# print("{} : 在 ".format(self.name))
# self.lock.release()
#
# self.lock.acquire()
# print("{} : 好啊 ".format(self.name))
# self.lock.release()
#
# class TianMao(threading.Thread):
# def __init__(self, lock):
# super().__init__(name="天猫精灵")
# self.lock = lock
#
# def run(self):
#
# self.lock.acquire()
# print("{} : 小爱同学 ".format(self.name))
# self.lock.release()
#
# self.lock.acquire()
# print("{} : 我们来对古诗吧 ".format(self.name))
# self.lock.release()
# 通过condition完成协同读诗
class XiaoAi(threading.Thread):
def __init__(self, cond):
super().__init__(name="小爱")
self.cond = cond
def run(self):
# 这里使用了 with 语句,如果不实用 with 语句,应该使用 self.cond.acquire(),并在结束时使用 self.cond.release()
# with 语句实际调用了 Condition 的 acquire 方法。
# Condition 其实是有两层锁的,一把是 Condition 对象的锁,这种是底层锁,
# 另一把是 wait 方法被调用时产生的锁,这个锁被放在一个 deque 中,并在 notify 时从 deque 中释放一个锁。
# 主线程先调用 Xiaoai 线程,当 Xiaoai 线程执行 with self.cond 时,Tianmao 是无法进入 with self.cond 的。
# 当 Xiaoai 线程执行 wait() 方法时,自己被阻塞,Tianmao 线程开始执行。
print('A')
with self.cond:
print('B')
self.cond.wait()
print("{} : 在 ".format(self.name))
self.cond.notify()
print('F')
self.cond.wait()
print("{} : 好啊 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 君住长江尾 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 共饮长江水 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 此恨何时已 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 定不负相思意 ".format(self.name))
self.cond.notify()
class TianMao(threading.Thread):
def __init__(self, cond):
super().__init__(name="天猫精灵")
self.cond = cond
def run(self):
# 这里使用了 with 语句,如果不实用 with 语句,应该使用 self.cond.acquire(),并在结束时使用 self.cond.release()
print('C')
with self.cond:
print('D')
print("{} : 小爱同学 ".format(self.name))
self.cond.notify()
print('E')
self.cond.wait()
print('G')
print("{} : 我们来对古诗吧 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 我住长江头 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 日日思君不见君 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 此水几时休 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 只愿君心似我心 ".format(self.name))
self.cond.notify()
self.cond.wait()
if __name__ == "__main__":
from concurrent import futures
cond = threading.Condition()
xiaoai = XiaoAi(cond)
tianmao = TianMao(cond)
# 启动顺序很重要
# 在调用with cond之后才能调用wait或者notify方法
# condition有两层锁, 一把底层锁会在线程调用了 wait 方法的时候释放, 上面的锁会在每次调用 wait 的时候分配一把并放入到 cond 的等待队列中,等到 notify 方法的唤醒
xiaoai.start()
tianmao.start()
4.3 Semaphore
通过 Semaphore 控制线程并发数量
#Semaphore 是用于控制进入数量的锁
#文件, 读、写, 写一般只是用于一个线程写,读可以允许有多个
#做爬虫
import threading
import time
class HtmlSpider(threading.Thread):
def __init__(self, url, sem):
super().__init__()
self.url = url
self.sem = sem
def run(self):
time.sleep(2)
print("got html text success")
# 每调用 release 时,semaphore 都会加一
self.sem.release()
class UrlProducer(threading.Thread):
def __init__(self, sem):
super().__init__()
self.sem = sem
def run(self):
for i in range(20):
# 每调用 acquire 时,semaphore 都会减一
self.sem.acquire()
html_thread = HtmlSpider("https://baidu.com/{}".format(i), self.sem)
html_thread.start()
if __name__ == "__main__":
# 最多允许三个线程并发
sem = threading.Semaphore(3)
url_producer = UrlProducer(sem)
url_producer.start()
5 线程池
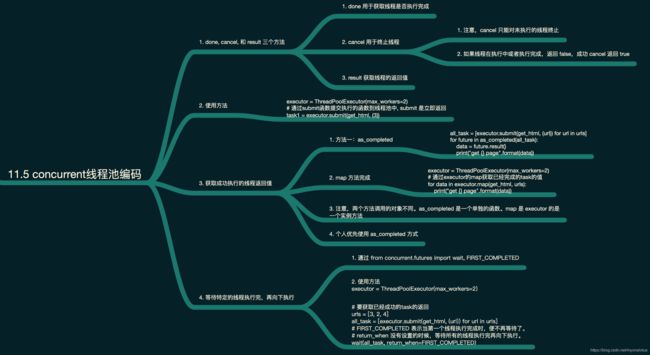
5.1 done, cancel, 和 result 三个方法
done 用于获取线程是否执行完成
cancel 用于终止线程。注意,cancel 只能对未执行的线程终止。如果线程在执行中或者执行完成,返回 false。成功 cancel 返回 true。
result 获取线程的返回值。
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
from concurrent.futures import Future
from multiprocessing import Pool
# 线程池, 为什么要线程池
# 主线程中可以获取某一个线程的状态或者某一个任务的状态,以及返回值
# 当一个线程完成的时候我们主线程能立即知道
# futures可以让多线程和多进程编码接口一致
import time
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 通过submit函数提交执行的函数到线程池中, submit 是立即返回
# 注意,这里传递的是函数名,不是函数的调用
task1 = executor.submit(get_html, (3))
task2 = executor.submit(get_html, (2))
#done方法用于判定某个任务是否完成
print(task1.done())
print(task2.cancel())
time.sleep(3)
print(task1.done())
#result方法可以获取task的执行结果
print(task1.result())
5.2 获取成功执行的线程返回值
使用 as_completed 或者 map 方法完成。注意,两个方法调用的对象不同。as_completed 是一个单独的函数。map 是 executor 的是一个实例方法。个人优先使用 as_completed 方式。
5.2.1 使用 as_completed 方法
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
from concurrent.futures import Future
from multiprocessing import Pool
import time
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 要获取已经成功的task的返回
urls = [3, 2, 4]
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task):
data = future.result()
print("get {} page".format(data))
5.2.2 使用 map 方法完成
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
from concurrent.futures import Future
from multiprocessing import Pool
import time
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 通过executor的map获取已经完成的task的值
for data in executor.map(get_html, urls):
print("get {} page".format(data))
5.3 等待特定的线程执行完,再向下执行
这个需求有点像 join 方法实现的功能。
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
from concurrent.futures import Future
from multiprocessing import Pool
import time
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 要获取已经成功的task的返回
urls = [3, 2, 4]
all_task = [executor.submit(get_html, (url)) for url in urls]
# FIRST_COMPLETED 表示当第一个线程执行完成时,便不再等待了。
# return_when 没有设置的时候,等待所有的线程执行完再向下执行。
wait(all_task, return_when=FIRST_COMPLETED)
print("main")
5.4 分析线程池源码 (重点)
线程池有一个非常重要的类,Future。Future 放置在 from concurrent.futures import Future 中。每个线程执行后返回的对象是 Future,即 task 的返回容器。Future 贯穿于多线程编程的始终,可以理解为一个统一的封装接口,就好像所有的对象的顶层父类都是 Object一样。
理解了上一点,那么,Future 对象是怎么贯穿线程生命周期的始终呢?
在调用 ThreadPoolExecutor 的 submit 函数时,以下面的代码为例,首先会生成 Future 对象,最后返回这个对象。在执行的过程中,生成 _WorkItem,并将 Future 对象,线程函数体,参数一起传入 _WorkItem中,再将其放入 queue 中,这个 queue 是线程安全的。放入 queue 之后,使用 _adjust_thread_count 调成线程数量。在 _adjust_thread_count 函数体中,如果当前等待的线程数小于线程池的容量,会启动线程,直到等于线程池数量。
def submit(self, fn, *args, **kwargs):
with self._shutdown_lock:
if self._shutdown:
raise RuntimeError('cannot schedule new futures after shutdown')
f = _base.Future()
w = _WorkItem(f, fn, args, kwargs)
self._work_queue.put(w)
self._adjust_thread_count()
return f
下面,我们来详细了解 _adjust_thread_count 的执行过程。启动一个新的线程时,执行体是 _worker,_worker 从 queue 中取出一个值,这是值是封装了我们自己写的线程函数体的 work_item,进而调用 work_item 中的 run 方法。
def _adjust_thread_count(self):
# When the executor gets lost, the weakref callback will wake up
# the worker threads.
def weakref_cb(_, q=self._work_queue):
q.put(None)
# TODO(bquinlan): Should avoid creating new threads if there are more
# idle threads than items in the work queue.
num_threads = len(self._threads)
if num_threads < self._max_workers:
thread_name = '%s_%d' % (self._thread_name_prefix or self,
num_threads)
t = threading.Thread(name=thread_name, target=_worker,
args=(weakref.ref(self, weakref_cb),
self._work_queue))
t.daemon = True
t.start()
self._threads.add(t)
_threads_queues[t] = self._work_queue
def _worker(executor_reference, work_queue):
try:
while True:
work_item = work_queue.get(block=True)
if work_item is not None:
work_item.run()
# Delete references to object. See issue16284
del work_item
continue
executor = executor_reference()
# Exit if:
# - The interpreter is shutting down OR
# - The executor that owns the worker has been collected OR
# - The executor that owns the worker has been shutdown.
if _shutdown or executor is None or executor._shutdown:
# Notice other workers
work_queue.put(None)
return
del executor
except BaseException:
_base.LOGGER.critical('Exception in worker', exc_info=True)
下面,我们再来看一下 work_item 中的 run 方法。首先,run 方法会执行我们自己写的线程函数体,得到函数的返回值,并将值设置到 Future 对象中。由此,变完成了使用 Future 统一线程的执行。
def run(self):
if not self.future.set_running_or_notify_cancel():
return
try:
result = self.fn(*self.args, **self.kwargs)
except BaseException as exc:
self.future.set_exception(exc)
# Break a reference cycle with the exception 'exc'
self = None
else:
self.future.set_result(result)
6. 多进程编程
耗 cpu 的操作,用多进程编程。对于 io 操作来说, 使用多线程编程。
由于 Python 中有 GIL 锁,Python 中的多线程编程是无法充分利用多核的优势。但是,多进程编程就能够利用多核的优势。
6.1 对于耗费 cpu 的操作,多进程优于多线程
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from concurrent.futures import ProcessPoolExecutor
def fib(n):
if n<=2:
return 1
return fib(n-1)+fib(n-2)
if __name__ == "__main__":
# 多线程
with ThreadPoolExecutor(3) as executor:
all_task = [executor.submit(fib, (num)) for num in range(25,40)]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
# 多进程
# Windows 下面执行 ProcessPoolExecutor 需要放到 main 函数下执行,不然会报错
with ProcessPoolExecutor(3) as executor:
all_task = [executor.submit(fib, (num)) for num in range(25,40)]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
6.2 对于 io 操作来说,多线程优于多进程
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from concurrent.futures import ProcessPoolExecutor
def random_sleep(n):
time.sleep(n)
return n
if __name__ == "__main__":
# 多线程
with ThreadPoolExecutor(3) as executor:
all_task = [executor.submit(random_sleep, (num)) for num in [2]*30]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
# 多进程
with ProcessPoolExecutor(3) as executor:
all_task = [executor.submit(random_sleep, (num)) for num in [2]*30]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
6.3 fork 与多进程的区别
fork 会新建一个子进程
import os
# fork只能用于linux/unix中
# 调用 fork 函数之后,会完全拷贝一份父进程的数据给子进程,子进程执行 fork 之后的代码
pid = os.fork()
print("bobby")
if pid == 0:
print('子进程 {} ,父进程是: {}.' .format(os.getpid(), os.getppid()))
else:
print('我是父进程:{}.'.format(pid))
# 如果没有 sleep 代码,会出现子进程无法退出的情况。这是因为,父进程执行完了之后,由于没有 sleep 函数,父进程会直接退出,但是,此时子进程依然在执行,当子进程执行完了之后,发现父进程已经消失了,子进程就无法退出。
time.sleep(2)
6.4 multiprocessing
import multiprocessing
import time
# 多进程编程
def get_html(n):
time.sleep(n)
print("sub_progress success")
return n
if __name__ == "__main__":
# 下面这行代码也可以使用继承 multiprocessing.Process 方式实现,就像继承 Thread 方式实现多线程一样
progress = multiprocessing.Process(target=get_html, args=(2,))
# 打印 pid
print(progress.pid)
progress.start()
print(progress.pid)
progress.join()
print("main progress end")
6.5 进程池
使用进程池时,建议使用ProcessPoolExecutor,而不是multiprocessing模块。
import multiprocessing
#多进程编程
import time
def get_html(n):
time.sleep(n)
print("sub_progress success")
return n
if __name__ == "__main__":
# 使用进程池
pool = multiprocessing.Pool(multiprocessing.cpu_count())
# 提交任务到池子中
result = pool.apply_async(get_html, args=(3,))
# 等待所有任务完成
# 在调用 join 之前,需要调用 close 方法,关闭池子
pool.close()
pool.join()
print(result.get())
6.6 imap 和 imap_unordered
import multiprocessing
#多进程编程
import time
def get_html(n):
time.sleep(n)
print("sub_progress success")
return n
if __name__ == "__main__":
# 使用进程池
pool = multiprocessing.Pool(multiprocessing.cpu_count())
# imap 按顺序执行
for result in pool.imap(get_html, [1,5,3]):
print("{} sleep success".format(result))
# imap_unordered
for result in pool.imap_unordered(get_html, [1, 5, 3]):
print("{} sleep success".format(result))
6.7 进程间通信
6.7.1 使用 multiprocessing 中的 Queue
多线程编程时通过 queue 进行通信,但是在多进程编程时,需要使用 from multiprocessing import Queue 中的 queue。
多进程编程时不能通过共享全局变量方式通信,因为多个进程之前的变量是完全隔离的。
import time
from multiprocessing import Process, Queue, Pool, Manager, Pipe
def producer(queue):
queue.put("a")
time.sleep(2)
def consumer(queue):
time.sleep(2)
data = queue.get()
print(data)
if __name__ == "__main__":
queue = Queue(10)
my_producer = Process(target=producer, args=(queue,))
my_consumer = Process(target=consumer, args=(queue,))
my_producer.start()
my_consumer.start()
my_producer.join()
my_consumer.join()
multiprocessing中的queue不能用于pool进程池。pool中的进程间通信需要使用manager中的queue。
import time
from multiprocessing import Process, Queue, Pool, Manager, Pipe
def producer(queue):
queue.put("a")
time.sleep(2)
def consumer(queue):
time.sleep(2)
data = queue.get()
print(data)
if __name__ == "__main__":
queue = Manager().Queue(10)
pool = Pool(2)
pool.apply_async(producer, args=(queue,))
pool.apply_async(consumer, args=(queue,))
pool.close()
pool.join()
Python 中有三个 Queue,需要注意不同点。
from queue import Queue
from multiprocessing import Queue
from multiprocessing import Manager
Manager().Queue()
6.7.2 使用 Pipe
pipe的性能高于queue。但是 pipe只能适用于两个进程。
import time
from multiprocessing import Process, Queue, Pool, Manager, Pipe
def producer(pipe):
pipe.send("bobby")
def consumer(pipe):
print(pipe.recv())
if __name__ == "__main__":
recevie_pipe, send_pipe = Pipe()
#pipe只能适用于两个进程
my_producer= Process(target=producer, args=(send_pipe, ))
my_consumer = Process(target=consumer, args=(recevie_pipe,))
my_producer.start()
my_consumer.start()
my_producer.join()
my_consumer.join()
6.7.3 使用 Manager() 中的数据结构
Manager 类中有 dict, array, list 等数据结构。可以通过共享这些数据结构对象,进而实现通信。但是,使用这种方式需要注意同步的问题,即需要加锁,保持数据一致性。
import time
from multiprocessing import Process, Queue, Pool, Manager, Pipe
def add_data(p_dict, key, value):
p_dict[key] = value
if __name__ == "__main__":
progress_dict = Manager().dict()
first_progress = Process(target=add_data, args=(progress_dict, "bobby1", 22))
second_progress = Process(target=add_data, args=(progress_dict, "bobby2", 23))
first_progress.start()
second_progress.start()
first_progress.join()
second_progress.join()
print(progress_dict)
7. Summary