【论文解读 WWW 2019 | MVAE】Multimodal Variational Autoencoder for Fake News Detection

论文题目:MVAE: Multimodal Variational Autoencoder for Fake News Detection
论文来源:WWW 2019
论文链接:https://doi.org/10.1145/3308558.3313552
代码链接:https://github.com/dhruvkhattar/MVAE
关键词:多模态融合;图片;文本;变分自编码器;假新闻检测;microblogs
文章目录
- 1 摘要
- 2 引言
- 3 模型
- 3.1 模型概览
- 3.2 编码器
- 3.3 解码器
- 3.4 假新闻检测器
- 3.5 将损失合并
- 4 实验
- 5 总结
- 参考文献
1 摘要
本文利用文本和视觉信息,进行假新闻的检测。
本文提出了端到端的多模态变分自编码器(MVAE),使用双峰的变分自编码器(bimodal variational autoencoder)和二元分类器进行假新闻的检测任务。
模型由3个主要组件组成:1)编码器;2)解码器;3)假新闻检测模块。
变分自编码器能够通过优化观测数据的边际似然值的边界,来学习概率潜在变量模型。
The variational autoencoder is capable of learning probabilistic latent variable models by optimizing a bound on the marginal likelihood of the observed data.
假新闻检测模块使用从双峰变分自编码器得到的多模态表示,对帖子进行真假的分类。
在Weibo和Twitter两个数据集上进行了实验,在F1值和准确率上超越了SOTA方法。
2 引言
(1)动机
现有的两个多模态假新闻检测的模型[1, 2],没有明确的目标来发现跨模态之间的关联。
(2)本文提出
为了克服现有的多模态假新闻检测方法的局限性,本文提出多模态变分自编码器(MVAE),学习到文本和图像两个模态的共享表示。
通过对多模变分自编码器的训练,可以从学习到的共享表示中重构出两种模态,进而发现跨模态之间的关联。
作者联合训练多模变分自编码器和一个分类器来进行假新闻检测。
本文模型仅使用新闻的内容信息,包括文本和图像内容,不使用社交信息或事件相关的信息。
3 模型
3.1 模型概览
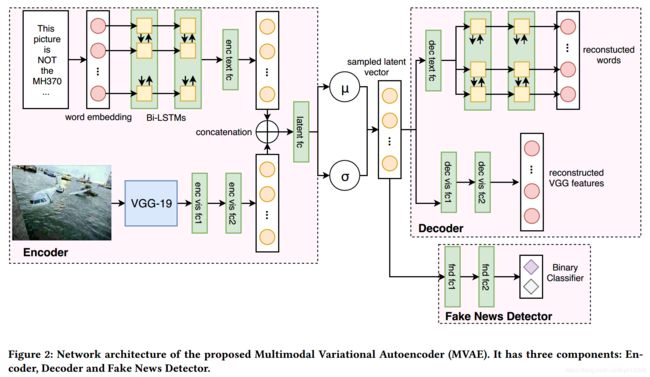
MVAE的基本思想是学习到文本和图片两种模态的统一表示。MVAE的整体架构如图 2所示,由3部分组成:
(1)编码器:将文本和图像的信息编码成隐层向量;
(2)解码器:从隐层向量重构出原始的图像和文本;
(3)假新闻检测器:使用学习到的共享表示(隐层向量)来预测新闻是否为假。
3.2 编码器
输入为帖子的文本和图片,输出为从两个模态学习到的特征的共享表示。编码器可分为两部分:1)文本编码器;2)视觉编码器。
(1)文本编码器
文本编码器的输入是帖子中的单词序列 T = [ T 1 , T 2 , . . . , T n ] T=[T_1, T_2, ...,T_n ] T=[T1,T2,...,Tn], n n n为单词数量。每个单词 T i ∈ T T_i\in T Ti∈T都用一个词嵌入向量表示。词嵌入向量是在给定的数据集上进行无监督的预训练得到的。
使用LSTM,令 [ h 1 , h 2 , . . . , h n ] [h_1, h_2, ..., h_n] [h1,h2,...,hn]表示LSTM的状态,状态更新满足如下的等式:

其中, f t , i t , o t f_t, i_t, o_t ft,it,ot分别表示遗忘门、输入门和输出门; x t x_t xt表示输入; h t h_t ht表示时间 t t t时的隐状态。三个门控制了整个序列的信息流。
作者使用堆叠的Bi-LSTM抽取文本特征。通过拼接前向和后向的状态,得到LSTM最后的隐状态。然后将LSTM的输出传递给一个全连接层,以得到文本特征。
(2)视觉编码器
使用再ImageNet数据集上进行了预训练的VGG-19网络,并使用全连接层(FC7)的输出。在联合训练过程中,将VGG网络的参数固定以避免参数爆照。最后,将VGG的输出通过多个全连接层(enc vis fc*)以得到和文本表示维度一致的图像表示。
(3)文本特征和视觉特征的融合
将文本特征表示 R T R_T RT和视觉特征表示 R V R_V RV拼接,输入到全连接层以形成共享的表示。然后从共享的表示中得到 μ \mu μ和 σ \sigma σ两个向量,可分别视为共享表示分布的均值和方差。同时从之前的分布中采样出一个随机变量 ϵ \epsilon ϵ。最终参数化的多模表示为 R m R_m Rm,计算如下:
我们将编码器定义为 G e n c ( M , θ e n c ) G_{enc}(M, \theta_{enc}) Genc(M,θenc),其中 θ e n c \theta_{enc} θenc表示编码器中所有需要学习的参数, M M M表示多媒体帖子的集合。因此,对于多媒体帖子 m m m,编码器输出的多模态表示为:
3.3 解码器
和编码器结构相似但是是反过来的。解码器的目的是从采样的多模态表示中重构出数据。和编码器一样,解码器分为两部分:1)文本解码器;2)视觉解码器。
(1)文本解码器
将多模态表示作为输入,重构出文本中的单词。将多模态表示传递给一个全连接层(dec text fc),以生成Bi-LSTM的输入。然后使用和编码器相似的Bi-LSTM。最后将LSTM的输出传递给有softmax激活函数的全连接层,以得到该时间步每个单词的概率。
(2)视觉解码器
视觉解码器的目标是从多模态表示中重构出VGG-19的特征。将多模表示传递给多个全连接层(dec vis fc*)来重构出VGG-19的特征。
我们将解码器定义为 G d e c ( R m , θ d e c ) G_{dec}(R_m, \theta_{dec}) Gdec(Rm,θdec),其中 θ d e c \theta_{dec} θdec表示解码器中的所有参数。因此,对于多媒体帖子 m m m,解码器的输出由两部分组成:1)概率矩阵,表示每个单词在文本每个位置的概率;2)重构的VGG-19特征, r ^ v g g m \hat{r}_{vgg_{m}} r^vggm。
VAE模型的训练损失是重构损失以及KL散度损失。对于文本的重构,使用交叉熵损失;对于图像特征的重构,使用均方误差(mean squared error)。两个概率分布间的KL散度,衡量了他们互相之间的偏离程度。最小化KL散度意味着优化概率分布的参数 μ \mu μ, σ \sigma σ,使其接近目标分布(正态分布)。上述损失计算如下:

其中, M M M表示一组多媒体帖子; n v n_v nv是VGG-19特征的维度; n t n_t nt是文本中单词的数量; n m n_m nm是多模态特征的维度; C C C是词表大小。
通过寻找最优的参数 θ ^ e n c \hat{\theta}_{enc} θ^enc和 θ ^ d e c \hat{\theta}_{dec} θ^dec,来最小化VAE损失:
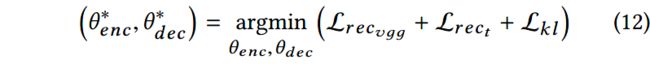
3.4 假新闻检测器
将多模态表示作为输入,目的是对帖子进行真假分类。假新闻检测器由多个全连接层和相应额激活函数构成。我们将假新闻检测器定义为 G f n d ( R m , θ f n d ) G_{fnd}(R_m, \theta_{fnd}) Gfnd(Rm,θfnd),其中 θ f n d \theta_{fnd} θfnd表示所有的参数。假新闻检测器的输出是,多媒体帖子 m m m是假新闻的概率:
分类损失为交叉熵:

其中, M M M表示一组多媒体帖子, Y Y Y表示ground truth labels。寻找最合适的参数 θ ^ f n d \hat{\theta}_{fnd} θ^fnd和 θ ^ e n c \hat{\theta}_{enc} θ^enc,以最小化分类损失。
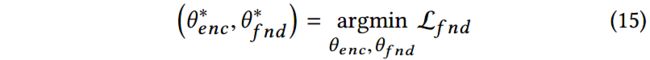
3.5 将损失合并
联合训练VAE和假新闻检测器,因此最终的损失如下:
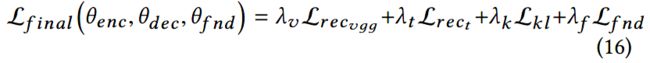
4 实验
(1)数据集
1)Twitter Dataset
数据集由tweet组成,每个tweet有文本内容,图像/视频,以及相关的社交上下文信息。作者过滤掉了有视频信息的帖子。
C. Boididou, S. Papadopoulos, D.-T. Dang-Nguyen, G. Boato, M. Riegler, S. E. Middleton, A. Petlund, Y. Kompatsiaris et al., “Verifying multimedia use at mediaeval 2016.” in MediaEval, 2016.
2)Weibo Dataset
从2012年5月到2016年1月的微博谣言数据,并且被微博官方谣言检测系统所证实。
Z. Jin, J. Cao, H. Guo, Y. Zhang, and J. Luo, “Multimodal fusion with recurrent neural networks for rumor detection on microblogs,” in Proceedings of the 2017 ACM on Multimedia Conference. ACM, 2017, pp. 795–816.
(2)实验结果

5 总结
本文解决的是多模态假新闻检测任务。为了克服已有模型的局限性,作者提出了多模态变分自编码器,学习到了共享(visual + textual)的表示,从而学习到了不同模态间的关联。
本文提出的MVAE模型由3部分组成:编码器;解码器;假新闻检测器。
实验结果显示超越了SOTA方法。
未来工作:利用tweet传播数据和用户特征。
参考文献
[1] Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multimodal fusion with recurrent neural networks for rumor detection on microblogs. In Proceedings of the 2017 ACM on Multimedia Conference. ACM, 795–816.
[2] Yaqing Wang, Fenglong Ma, Zhiwei Jin, Ye Yuan, Guangxu Xun, Kishlay Jha, Lu Su, and Jing Gao. 2018. EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 849–857.