Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述
Spark SQL模块,主要就是处理跟SQL解析相关的一些内容,说得更通俗点就是怎么把一个SQL语句解析成Dataframe或者说RDD的任务。以Spark 2.4.3为例,Spark SQL这个大模块分为三个子模块,如下图所示

其中Catalyst可以说是Spark内部专门用来解析SQL的一个框架,在Hive中类似的框架是Calcite(将SQL解析成MapReduce任务)。Catalyst将SQL解析任务分成好几个阶段,这个在对应的论文中讲述得比较清楚,本系列很多内容也会参考论文,有兴趣阅读原论文的可以到这里看:Spark SQL: Relational Data Processing in Spark。
而Core模块其实就是Spark SQL主要解析的流程,当然这个过程中会去调用Catalyst的一些内容。这模块里面比较常用的类包括SparkSession,DataSet等。
至于hive模块,这个不用说,肯定跟hive有关的。这个模块在本系列基本不会涉及到,就不多介绍了。
值得一提的是,论文发表的时候还是在Spark1.x阶段,那个时候SQL解析成词法树用的是scala写的一个解析工具,到2.x阶段改为使用antlr4来做这部分工作(这应该算是最大的改变)。至于为什么要改,我猜是出于可读性和易用性方面的考虑,当然这个仅是个人猜测。
另外,这一系列会简单介绍一条SQL语句的处理流程,基于spark 2.4.3(sql这个模块在spark2.1后变化不大)。这一篇先从整体介绍Spark SQL出现的背景及解决问题,Dataframe API以及Catalyst的流程大概是怎么样,后面分阶段细说Catalyst的流程。
Spark SQL出现的背景及解决的问题
在最早的时候,大规模处理数据的技术是MapReduce,但这种框架执行效率太慢,进行一些关系型处理(如join)需要编写大量代码。后来hive这种框架可以让用户输入sql语句,自动进行优化并执行。
但在大型系统中,任然有两个主要问题,一个是ETL操作需要对接多个数据源。另一个是用户需要执行复杂分析,比如机器学习和图计算等。但传统的关系型处理系统中较难实现。
Spark SQL提供了两个子模块来解决这个问题,DataFrame API和Catalyst。
相比于RDD,Dataframe api提供了更加丰富的关系型api,并且能和RDD相互转换,后面Spark机器学习方面的工作重心,也从以RDD为基础的mllib转移到以Dataframe为基础的Spark ML(虽然Dataframe底层也是RDD)。
另一个就是Catalyst,通过它可以轻松为诸如机器学习之类的域添加数据源(比如json或通过case class自定义的类型),优化规则和数据类型。
通过这两个模块,Spark SQL主要实现以下目标:
- 提供方便易用好的API,包括读取外部数据源,以及关系数据处理(用过的都知道)
- 使用已建立的DBMS技术提供高性能。
- 轻松支持新数据源,包括半结构化数据和外部数据库(比如MYSQL)。
- 图计算和机器学习方面的拓展
那下面就介绍Dataframe和Catalyst的流程,当然主要讨论的还是Catalyst。
统一API Dataframe
先来看看论文里面提供的一张图:
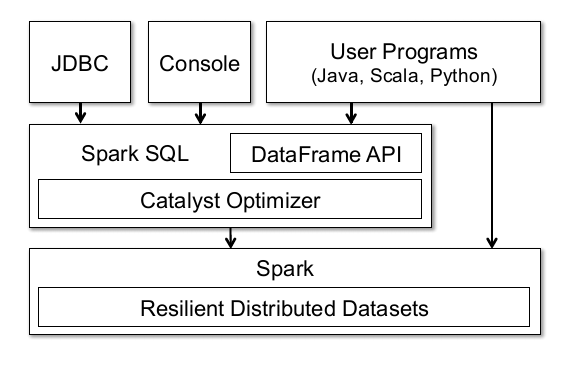
这张图可以说明很多,首先Spark的Dataframe API底层也是基于Spark的RDD。但与RDD不同的在于,Dataframe会持有schema(这个实在不好翻译,可以理解为数据的结构吧),以及可以执行各种各样的关系型操作,比如Select,Filter,Join,Groupby等。从操作上来说,和pandas的Dataframe有点像(连名字都是一样的)。
同时因为是基于RDD的,所以很多RDD的特性Dataframe都能够享受到,比如说分布式计算中一致性,可靠性方面的保证,以及可以通过cache缓存数据,提高计算性能啊等等。
同时图中页展示了Dataframe可以通过JDBC链接外部数据库,通过控制台操作(spark-shell),或者用户程序。说白了,就是Dataframe可以通过RDD转换而来,也可以通过外部数据表生成。
对了,这里顺便说一句,很多初次接触Spark SQL的童鞋可能会对Dataset和Dataframe这两个东西感到疑惑,在1.x时代它们确实有些差别,不过在spark2.x的时候,这两个API已经统一了。所以基本上Dataset和Dataframe可以看成是等价的东西。
最后还是结合代码做一下实际的展示吧,如下展示生成一个RDD,并且根据这个RDD生成对应的Dataframe,从中可以看出RDD和Dataframe的区别:
//生成RDD
scala> val data = sc.parallelize(Array((1,2),(3,4)))
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at :24
scala> data.foreach(println)
(1,2)
(3,4)
scala> val df = data.toDF("fir","sec")
df: org.apache.spark.sql.DataFrame = [fir: int, sec: int]
scala> df.show()
+---+---+
|fir|sec|
+---+---+
| 1| 2|
| 3| 4|
+---+---+
//跟RDD相比,多了schema
scala> df.printSchema()
root
|-- fir: integer (nullable = false)
|-- sec: integer (nullable = false)
Catalyst流程解析
Catalyst在论文中被叫做优化器(Optimizer),这部分是论文里面较为核心的内容,不过其实流程还是蛮好理解的,依旧贴下论文里面的图。
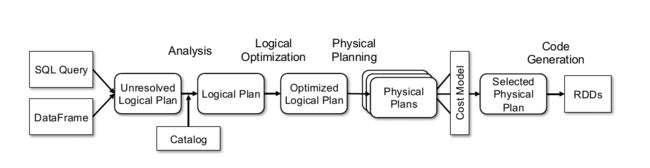
主要流程大概可以分为以下几步:
- Sql语句经过Antlr4解析,生成Unresolved Logical Plan(有使用过Antlr4的童鞋肯定对这一过程不陌生)
- analyzer与catalog进行绑定(catlog存储元数据),生成Logical Plan;
- optimizer对Logical Plan优化,生成Optimized LogicalPlan;
- SparkPlan将Optimized LogicalPlan转换成 Physical Plan;
- prepareForExecution()将 Physical Plan 转换成 executed Physical Plan;
- execute()执行可执行物理计划,得到RDD;
提前说一下吧,上述流程多数是在org.apache.spark.sql.execution.QueryExecution这个类里面,这个贴一下简单的代码,看看就好,先不多做深究。后面的文章会详细介绍这里的内容。
class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan) {
......其他代码
//analyzer阶段
lazy val analyzed: LogicalPlan = {
SparkSession.setActiveSession(sparkSession)
sparkSession.sessionState.analyzer.executeAndCheck(logical)
}
//optimizer阶段
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
//SparkPlan阶段
lazy val sparkPlan: SparkPlan = {
SparkSession.setActiveSession(sparkSession)
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now,
// but we will implement to choose the best plan.
planner.plan(ReturnAnswer(optimizedPlan)).next()
}
//prepareForExecution阶段
// executedPlan should not be used to initialize any SparkPlan. It should be
// only used for execution.
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
//execute阶段
/** Internal version of the RDD. Avoids copies and has no schema */
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
......其他代码
}
值得一提的是每个阶段都使用了lazy懒加载,对这块感兴趣可以看看我之前的文章Scala函数式编程(六) 懒加载与Stream。
上述主要介绍Spark SQL模块内容,其出现的背景以及主要解决问题。而后简单介绍下Dataframe API的内容,以及Spark SQL解析SQL的内部框架Catalyst。后续主要会介绍Catalyst中各个步骤的流程,结合源码来做一些分析。
以上~