Spark DataFrame算子使用与窗口函数
Spark DataFrame常用算子介绍
1. where
where(conditionExpr: String):SQL语言中where关键字后的条件,传入筛选条件表达式,可以用and和or。得到DataFrame类型的返回结果, 示例:
data.where("score >99 or lesson != 'Math'").show
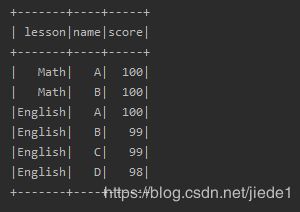
2.filter
用法与where一样
data.filter("score >99 or lesson != 'Math'").show
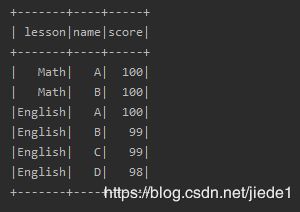
3.select
(一) select:获取指定字段值
根据传入的String类型字段名,获取指定字段的值,以DataFrame类型返回。示例:
data.select("name").show

还可以这样,传入一个Column类型参数,实现score+1这种效果
data.select(data("name"),data("score") + 1).show

**(二) selectExpr:可以直接对指定字段调用UDF函数,或者指定别名等。传入String类型参数,得到DataFrame对象。 **
spark.udf.register("plusOne",(i:Int) => i+1)
spark.udf.register("addfrr",(s:String) => s + "_frr")
data.selectExpr("addfrr(name)","lesson as les","plusOne(score)").show
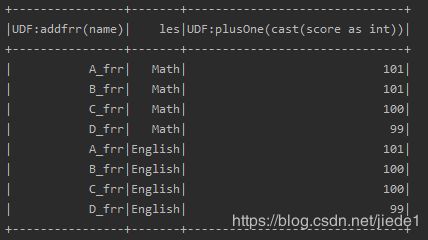
4.col
获取指定字段 ,且只能获取一个字段,返回对象为Column类型。
5.apply
获取指定字段 ,且只能获取一个字段,返回对象为Column类型
6.drop
去除指定字段,保留其他字段 ,返回一个新的DataFrame对象,其中不包含去除的字段,一次只能去除一个字段。
7.limit
limit方法获取指定DataFrame的前n行记录,得到一个新的DataFrame对象。和take与head不同的是,limit方法不是Action操作。
8.order by
类似的还有sort,按指定字段排序,默认为升序
data.sort("score").show()
data.sort(data("score").desc).show
data.orderBy("score").show
data.orderBy(data("score").desc).show


sortWithinPartitions
和上面的sort方法功能类似,区别在于sortWithinPartitions方法返回的是按Partition排好序的DataFrame对象。
9 .group by
(一) groupBy:根据字段进行group by操作
groupBy方法有两种调用方式,可以传入String类型的字段名,也可传入Column类型的对象。 使用方法如下,
data.groupBy("name").count.show
data.groupBy(data("name")).count.show
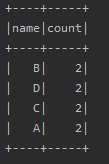
#####(二) cube 与rollup
cude也是聚合,但是是全维度的聚合
cube(a,b,c)则首先会对(a,b,c)进行group by,
然后依次是(a,b),(a,c),(a),(b,c),(b),©,最后在对全表进行group by,他会统计所选列中值的所有组合的聚合
用cube函数就可以完成所有维度的聚合工作
data.cube("name","lesson").sum("score").show
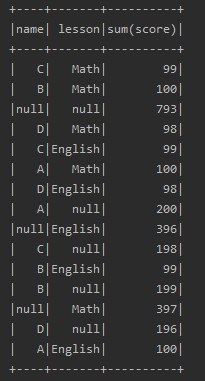
rollup函数是cube的子集,以最左侧维度为主,按照顺序依次进行聚合. 例如聚合的维度为 col1,col2,col3
使用rollup聚合的字段分别为 col1,(col1,col2),(col1,col3),(col1,col2,col3)
data.rollup("name","lesson").sum("score").show
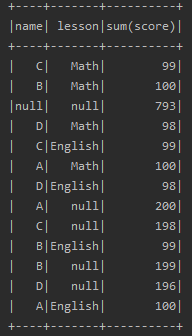
(三)GroupedData对象
该方法得到的是GroupedData类型对象,在GroupedData的API中提供了group by之后的操作,比如,
max(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的最大值,只能作用于数字型字段
min(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的最小值,只能作用于数字型字段
mean(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的平均值,只能作用于数字型字段
sum(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的和值,只能作用于数字型字段
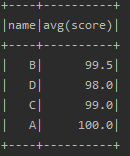
data.groupBy("name").avg("score").show
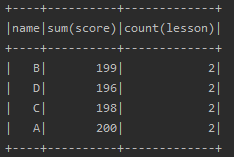
10. agg
聚合操作调用的是agg方法,该方法有多种调用方式。一般与groupBy方法配合使用。
data.groupBy("name").agg("score" -> "sum", "lesson" -> "count").show()
data.groupBy("name").agg(Map("score" -> "sum", "lesson" -> "count")).show()
11. distinct
(一)distinct:返回一个不包含重复记录的DataFrame
返回当前DataFrame中不重复的Row记录。该方法和接下来的dropDuplicates()方法不传入指定字段时的结果相同。
(二)dropDuplicates:根据指定字段去重
根据指定字段去重。类似于select distinct a, b操作
data.dropDuplicates("name").show

12. join
重点来了。在SQL语言中用得很多的就是join操作,DataFrame中同样也提供了join的功能。
接下来隆重介绍join方法。在DataFrame中提供了六个重载的join方法。
(1)、笛卡尔积
data.join(records).show
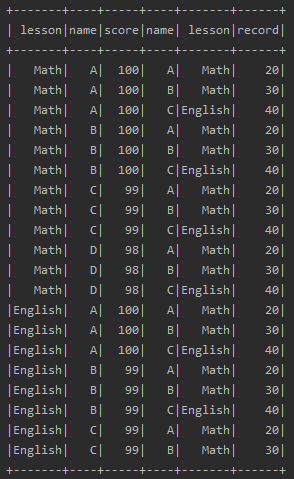
(2)、using一个字段形式
下面这种join类似于a join b using column1的形式,需要两个DataFrame中有相同的一个列名,
data.join(records,"name").show
data.join(records,Seq("name")).show()
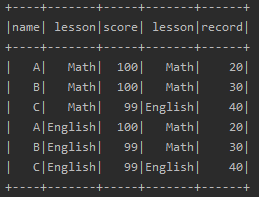
(3)、using多个字段形式
除了上面这种using一个字段的情况外,还可以using多个字段,如下
data.join(records, Seq("name","lesson")).show

(4)、指定join类型
在上面的using多个字段的join情况下,可以写第三个String类型参数,指定join的类型,如下所示
inner:内连
outer,full,full_outer:全连
left, left_outer:左连
right,right_outer:右连
left_semi:过滤出joinDF1中和joinDF2共有的部分
left_anti:过滤出joinDF1中joinDF2没有的部分
val joinDF = data.join(records,Seq("name"),"inner")
joinDF.select("name","score").show
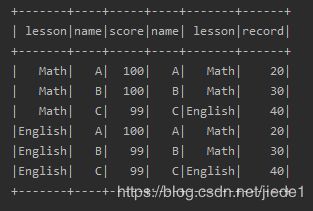
(5)、使用Column类型来join
如果不用using模式,灵活指定join字段的话,可以使用如下形式
(6)、在指定join字段同时指定join类型
data.join(records, data("name") === records("name"), "inner").show()
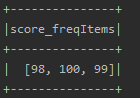
13.获取指定字段统计信息
stat方法可以用于计算指定字段或指定字段之间的统计信息,比如方差,协方差等。这个方法返回一个DataFramesStatFunctions类型对象。 下面代码统计score该字段值出现频率在30%以上的内容。
data.stat.freqItems(Seq("score"), 0.3).show
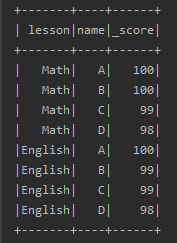
14.行转列 pivot
也叫透视,具体含义可以看下图
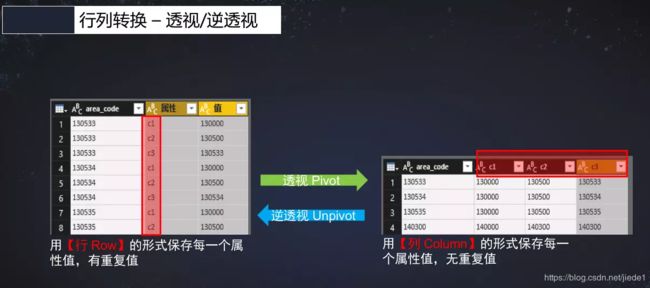
data.show
val pivotDF = data.groupBy("name").pivot("lesson").agg(sum("score"))
pivotDF.show
原本的data
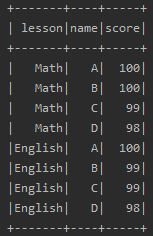
透视后的
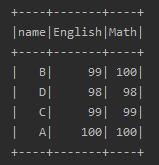
透视操作简单直接,逻辑如下
按照不需要转换的字段分组,本例中是name;
使用pivot函数进行透视,透视过程中可以提供第二个参数来明确指定使用哪些数据项;
汇总数字字段,本例中是score;
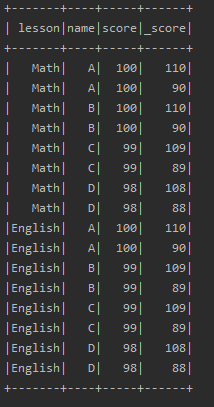
除了pivot,还有一个操作需要知道的:explode。有时候需要根据某个字段内容进行分割,然后生成多行,这时可以使用explode方法
val explodeDF = data.explode("score","_score"){a:Long => Array(a + 10, a-10)}
explodeDF.show
15.withColumnRenamed
重命名DataFrame中的指定字段名。如果指定的字段名不存在,不进行任何操作。
val renameDF = data.withColumnRenamed("score","_score")
renameDF.show
15.withColumn
增加一列
val addDF = data.withColumn("addScore",data("score").divide(2))
addDF.show

Spark DataFrame 窗口函数
上面介绍了spark dataframe常用的一些操作。除此之外,spark还有一类操作比较特别的操作,窗口函数。窗口函数常多用于sql,spark sql也集成了,同样,spark dataframe也有这种函数,spark sql的窗口函数与spark dataframe的写法不太一样。
spark sql 写法
select pcode,event_date,sum(duration) over (partition by pcode order by event_date asc) as sum_duration
from userlogs_date
spark dataframe
import org.apache.spark.sql.expressions._
val first_2_now_window = Window.partitionBy("pcode").orderBy("event_date")
df_userlogs_date.select(
$"pcode",
$"event_date",
sum($"duration").over(first_2_now_window).as("sum_duration")
).show
窗口函数形式为 over(partition by A order by B),意为对A分组,对B排序,然后进行某项计算,比如求count,max等。
count(...) over(partition by ... order by ...)--求分组后的总数。
sum(...) over(partition by ... order by ...)--求分组后的和。
max(...) over(partition by ... order by ...)--求分组后的最大值。
min(...) over(partition by ... order by ...)--求分组后的最小值。
avg(...) over(partition by ... order by ...)--求分组后的平均值。
rank() over(partition by ... order by ...)--rank值可能是不连续的。
dense_rank() over(partition by ... order by ...)--rank值是连续的。
first_value(...) over(partition by ... order by ...)--求分组内的第一个值。
last_value(...) over(partition by ... order by ...)--求分组内的最后一个值。
lag() over(partition by ... order by ...)--取出前n行数据。
lead() over(partition by ... order by ...)--取出后n行数据。
ratio_to_report() over(partition by ... order by ...)--Ratio_to_report() 括号中就是分子,over() 括号中就是分母。
percent_rank() over(partition by ... order by ...)-- 计算当前行所在前百分位
窗口函数可以实现如下逻辑:
1.求取聚合后个体占组的百分比
2.求解历史数据累加
- 1.求取聚合后个体占组的百分比
val data = spark.read.json(spark.createDataset(
Seq(
"""{"name":"A","lesson":"Math","score":100}""",
"""{"name":"B","lesson":"Math","score":100}""",
"""{"name":"C","lesson":"Math","score":99}""",
"""{"name":"D","lesson":"Math","score":98}""",
"""{"name":"A","lesson":"English","score":100}""",
"""{"name":"B","lesson":"English","score":99}""",
"""{"name":"C","lesson":"English","score":99}""",
"""{"name":"D","lesson":"English","score":98}"""
)))
data.show
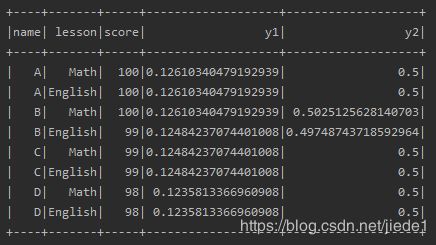
//求取每个人的单科成绩占自己总成绩的百分比
spark.sql(
s"""
|select name, lesson, score, (score/sum(score) over()) as y1, (score/sum(score) over(partition by name)) as y2
|from score
|""".stripMargin).show
- 2.求解历史数据累加
比如,有个需求,求取从2018年到2020年各年累加的物品总数。
val data1 = spark.read.json(spark.createDataset(
Seq(
"""{"date":"2020-01-01","build":1}""",
"""{"date":"2020-01-01","build":1}""",
"""{"date":"2020-04-01","build":1}""",
"""{"date":"2020-04-01","build":1}""",
"""{"date":"2020-05-01","build":1}""",
"""{"date":"2020-09-01","build":1}""",
"""{"date":"2019-01-01","build":1}""",
"""{"date":"2019-01-01","build":1}""",
"""{"date":"2018-01-01","build":1}"""
)))
data1.createOrReplaceTempView("data1")
/**
* 历史累加
*/
//统计build字段的历史累加数据
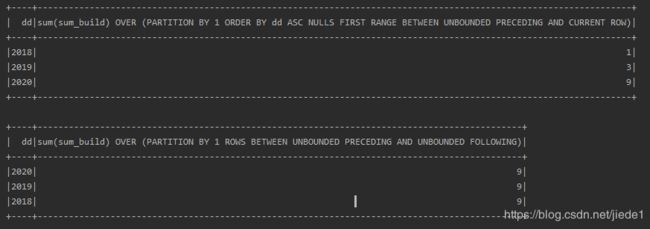
spark.sql(
s"""
|select c.dd,sum(c.sum_build) over(partition by 1 order by dd asc) from
|(select substring(date,0,4) as dd, sum(build) as sum_build from data1 group by dd) c
|""".stripMargin).show
spark.sql(
s"""
|select c.dd,sum(c.sum_build) over (partition by 1) from
|(select substring(date,0,4) as dd, sum(build) as sum_build from data1 group by dd) c
|""".stripMargin).show
参考文献
Spark常用算子
聚合cude和rollup
Spark-sql 计算某行值占累加总数的百分比
Spark窗口函数实现历史累加
Spark API 全集(2):Spark SQL 函数全集
hive开窗函数over(partition by …)与group by 的区别