使用PaddlePaddle进行微博谣言检测
近期,在新冠肺炎疫情防控的关键期,网上各种有关疫情防控的谣言接连不断,这些谣言操纵了舆论感情,误导了公众判断,更影响了社会稳定。本项目基于基于循环神经网络(RNN)的课言检测模型实现了微博谣言检测
本实践使用 Paddle Fluid API 编程并搭建一个循环神经网络(Recurrent Neural Network,RNN),进行谣言检测。主要分为五个步骤:
1.数据准备
2.模型配置
3.模型训练
(1)定义网络
(2)定义损失函数
(3)定义优化方法
4.模型评估
5.模型预测
数据集介绍:
本次实践所使用的数据是从新浪微博不实信息举报平台抓取的中文谣言数据,数据集中共包含1538条谣言和1849条非谣言。如下图所示,每条数据均为json格式,其中text字段代表微博原文的文字内容。

数据处理及模型:
# Step1、数据准备
# (1)解压数据,读取并解析数据,生成all_data.txt
# (2)生成数据字典,即dict.txt
# (3)生成数据列表,并进行训练集与验证集的划分,train_list.txt 、eval_list.txt
# (4)定义训练数据集提供器train_reader和验证数据集提供器eval_reader
#解压原始数据集,将Rumor_Dataset.zip解压至data目录下
import zipfile
import os
import random
from PIL import Image
from PIL import ImageEnhance
import json
src_path="D:\PycharmProjects2020\\tensor1\yaoyanjianche\data\Chinese_Rumor_Dataset-master.zip"
target_path="D:\PycharmProjects2020\\tensor1\yaoyanjianche\data\Chinese_Rumor_Dataset-master"
if(not os.path.isdir(target_path)): #如果不存在target_path路径的话,进行解压
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
# 分别为谣言数据、非谣言数据、全部数据的文件路径
rumor_class_dirs = os.listdir(target_path + "/Chinese_Rumor_Dataset-master/CED_Dataset/rumor-repost/")
non_rumor_class_dirs = os.listdir(target_path + "/Chinese_Rumor_Dataset-master/CED_Dataset/non-rumor-repost/")
original_microblog = target_path + "/Chinese_Rumor_Dataset-master/CED_Dataset/original-microblog/"
# 谣言标签为0,非谣言标签为1
rumor_label = "0"
non_rumor_label = "1"
# 分别统计谣言数据与非谣言数据的总数
rumor_num = 0
non_rumor_num = 0
all_rumor_list = []
all_non_rumor_list = []
# 解析谣言数据
for rumor_class_dir in rumor_class_dirs:
if (rumor_class_dir != '.DS_Store' and rumor_class_dir !='._.DS_Store' ):
# 遍历谣言数据,并解析 老提示编码错误的原因 :UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb0
# 因为文件夹里面除了.DS_Store 还有._.DS_Store文件 ._.DS_Store文件没有判断
with open(original_microblog + rumor_class_dir, 'r',encoding='UTF-8') as f:
rumor_content = f.read()
rumor_dict = json.loads(rumor_content)
all_rumor_list.append(rumor_label + "\t" + rumor_dict["text"] + "\n")#取text的值并加上标签
rumor_num += 1
# 解析非谣言数据
for non_rumor_class_dir in non_rumor_class_dirs:
if (non_rumor_class_dir != '.DS_Store' and non_rumor_class_dir != '._.DS_Store'):
with open(original_microblog + non_rumor_class_dir, 'r',encoding='UTF-8') as f2:
non_rumor_content = f2.read()
non_rumor_dict = json.loads(non_rumor_content)
all_non_rumor_list.append(non_rumor_label + "\t" + non_rumor_dict["text"] + "\n")
non_rumor_num += 1
print("谣言数据总量为:" + str(rumor_num))
print("非谣言数据总量为:" + str(non_rumor_num))
# print(all_rumor_list)
# 全部数据进行乱序后写入all_data.txt
data_list_path = "D:\PycharmProjects2020\\tensor1\yaoyanjianche\data"
all_data_path = data_list_path + "\\all_data.txt"
all_data_list = all_rumor_list + all_non_rumor_list
random.shuffle(all_data_list)
# 在生成all_data.txt之前,首先将其清空
with open(all_data_path, 'w',encoding='UTF-8') as f:
f.seek(0)
f.truncate()
with open(all_data_path, 'a',encoding='UTF-8') as f:
for data in all_data_list:
f.write(data)
# 导入必要的包
import os
from multiprocessing import cpu_count
import numpy as np
import shutil
import paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
# 生成数据字典
def create_dict(data_path, dict_path):
dict_set = set()
# 读取全部数据
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.readlines()#读取文件的所有的行,保存在列表中
# 把数据生成一个集合
for line in lines:
content = line.split('\t')[-1].replace('\n', '')#[]括号 里面,表示取值 0是从左到右第一个。-1,从右到左第一个。 既,取标签右边的文字把标签去掉,replace是把'\n'替换成''
for s in content:
dict_set.add(s)
# 把列表转换成字典,一个字对应一个数字
dict_list = []
i = 0
for s in dict_set:
dict_list.append([s, i])
i += 1
# 添加未知字符
dict_txt = dict(dict_list)
end_dict = {"" : i}
dict_txt.update(end_dict)
# 把这些字典保存到本地中
with open(dict_path, 'w', encoding='utf-8') as f:
f.write(str(dict_txt))
print("数据字典生成完成!")
# 获取字典的长度
def get_dict_len(dict_path):
with open(dict_path, 'r', encoding='utf-8') as f:
line = eval(f.readlines()[0])
return len(line.keys())
# 创建序列化表示的数据,并按照一定比例划分训练数据与验证数据
def create_data_list(data_list_path):
# 在生成数据之前,首先将eval_list.txt和train_list.txt清空
with open(os.path.join(data_list_path, 'eval_list.txt'), 'w', encoding='utf-8') as f_eval:
f_eval.seek(0)
f_eval.truncate()
with open(os.path.join(data_list_path, 'train_list.txt'), 'w', encoding='utf-8') as f_train:
f_train.seek(0)
f_train.truncate()
with open(os.path.join(data_list_path, 'dict.txt'), 'r', encoding='utf-8') as f_data:
dict_txt = eval(f_data.readlines()[0])
with open(os.path.join(data_list_path, 'all_data.txt'), 'r', encoding='utf-8') as f_data:
lines = f_data.readlines()
i = 0
with open(os.path.join(data_list_path, 'eval_list.txt'), 'a', encoding='utf-8') as f_eval, open(
os.path.join(data_list_path, 'train_list.txt'), 'a', encoding='utf-8') as f_train:
for line in lines:
words = line.split('\t')[-1].replace('\n', '')
label = line.split('\t')[0]
labs = ""
if i % 8 == 0:
for s in words:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + label + '\n'
f_eval.write(labs)
else:
for s in words:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + label + '\n'
f_train.write(labs)
i += 1
print("数据列表生成完成!")
#dict_path为数据字典存放路径
dict_path = data_list_path + "\dict.txt"
#创建数据字典,存放位置:dict.txt。在生成之前先清空dict.txt
with open(dict_path, 'w') as f:
f.seek(0)
f.truncate()
create_dict(all_data_path, dict_path)
#创建数据列表,存放位置:train_list.txt eval_list.txt
create_data_list(data_list_path)
def data_mapper(sample):
data, label = sample
data = [int(data) for data in data.split(',')]
return data, int(label)
#定义数据读取器
def data_reader(data_path):
def reader():
with open(data_path, 'r') as f:
lines = f.readlines()
for line in lines:
data, label = line.split('\t')
yield data, label
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 1024)
# 获取训练数据读取器和测试数据读取器
BATCH_SIZE = 128
train_list_path = data_list_path+'/train_list.txt'
eval_list_path = data_list_path+'/eval_list.txt'
train_reader = paddle.batch(
reader=data_reader(train_list_path),
batch_size=BATCH_SIZE)
eval_reader = paddle.batch(
reader=data_reader(eval_list_path),
batch_size=BATCH_SIZE)
# Step2、配置网络
#(1)搭建网络
# 定义长短期记忆网络
def lstm_net(ipt, input_dim):
# 以数据的IDs作为输入
emb = fluid.layers.embedding(input=ipt, size=[input_dim, 128], is_sparse=True)
# 第一个全连接层
fc1 = fluid.layers.fc(input=emb, size=128)
# 进行一个长短期记忆操作
lstm1, _ = fluid.layers.dynamic_lstm(input=fc1, #返回:隐藏状态(hidden state),LSTM的神经元状态
size=128) #size=4*hidden_size
# 第一个最大序列池操作
fc2 = fluid.layers.sequence_pool(input=fc1, pool_type='max')
# 第二个最大序列池操作
lstm2 = fluid.layers.sequence_pool(input=lstm1, pool_type='max')
# 以softmax作为全连接的输出层,大小为2,也就是正负面
out = fluid.layers.fc(input=[fc2, lstm2], size=2, act='softmax')
return out
#(2)定义数据层
# 定义输入数据, lod_level不为0指定输入数据为序列数据
words = fluid.data(name='words', shape=[None,1], dtype='int64', lod_level=1)
label = fluid.data(name='label', shape=[None,1], dtype='int64')
#(3)获取分类器
# 获取数据字典长度
dict_dim = get_dict_len(dict_path)
# 获取分类器
model = lstm_net(words, dict_dim)
#(4)定义损失函数和准确率
# 获取损失函数和准确率
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=model, label=label)
# 获取预测程序
test_program = fluid.default_main_program().clone(for_test=True)
#(5)定义优化方法
# 定义优化方法
optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.001)
opt = optimizer.minimize(avg_cost)
#step3、训练网络&step4、评估网络
#(1)创建Executor
# use_cuda为False,表示运算场所为CPU;use_cuda为True,表示运算场所为GPU
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
#(2)定义数据映射器
# DataFeeder负责将数据提供器(train_reader,test_reader)返回的数据转成一种特殊的数据结构,使其可以输入到Executor中。
# feed_list设置向模型输入的向变量表或者变量表名
# 定义数据映射器
feeder = fluid.DataFeeder(place=place, feed_list=[words, label])
#(3)展示模型训练曲线
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
all_eval_iter=0
all_eval_iters=[]
all_eval_costs=[]
all_eval_accs=[]
def draw_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
# (4)训练并保存模型
# Executor接收传入的program,并根据feed map(输入映射表)和fetch_list(结果获取表) 向program中添加feed operators(数据输入算子)和fetch operators(结果获取算子)。
# feed map为该program提供输入数据。fetch_list提供program训练结束后用户预期的变量。
# 每一轮训练结束之后,再使用验证集进行验证,并求出相应的损失值Cost和准确率acc
EPOCH_NUM = 100 # 训练轮数
model_save_dir = "D:\PycharmProjects2020\\tensor1\yaoyanjianche\data\model" # 模型保存路径
# 开始训练
for pass_id in range(EPOCH_NUM):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
all_train_iter = all_train_iter + BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
if batch_id % 100 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Acc:%0.5f' % (pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行验证
eval_costs = []
eval_accs = []
for batch_id, data in enumerate(eval_reader()):
eval_cost, eval_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
eval_costs.append(eval_cost[0])
eval_accs.append(eval_acc[0])
all_eval_iter = all_eval_iter + BATCH_SIZE
all_eval_iters.append(all_eval_iter)
all_eval_costs.append(eval_cost[0])
all_eval_accs.append(eval_acc[0])
# 计算平均预测损失在和准确率
eval_cost = (sum(eval_costs) / len(eval_costs))
eval_acc = (sum(eval_accs) / len(eval_accs))
print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, eval_cost, eval_acc))
# 保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir,
feeded_var_names=[words.name],
target_vars=[model],
executor=exe)
print('训练模型保存完成!')
draw_process("train", all_train_iters, all_train_costs, all_train_accs, "trainning cost", "trainning acc")
draw_process("eval", all_eval_iters, all_eval_costs, all_eval_accs, "evaling cost", "evaling acc")
结果:

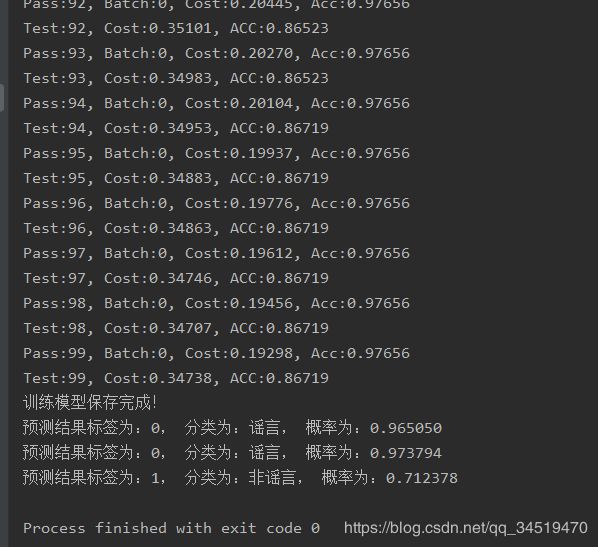
预测以及文件分类:
# 导入必要的包
import zipfile
import os
import random
from PIL import Image
from PIL import ImageEnhance
import json
import os
from multiprocessing import cpu_count
import numpy as np
import shutil
import paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
# 最后的infer有问题,需要修改的地方:
# 1. infer_exe = fluid.Executor(place) 下面的infer_exe.run(fluid.default_startup_program())去掉。这是一个空程序,抛出警告
# 2.get_data函数,s = ''下面类型是int64,不能直接用int转,可使用np.array(dict_txt[s]).astype("int64")
# 3.# 执行预测 下面的exe.run,应该是 infer_exe.run 所有的问题,汇总就是第二个是重点,因为文字处理类案例一直一直没改 get_data 的数据类型是 int64
#文件分类的路径
f1 = open('D:\PycharmProjects2020\\tensor1\yaoyanjianche\data/rumor.csv', 'a+',encoding='utf-8') # 存放正面 名字也可自定义哦
f2 = open('D:\PycharmProjects2020\\tensor1\yaoyanjianche\data/unrumor.csv', 'a+',encoding='utf-8') # 存放负面
# 要检测的文件的路径
fileee="D:\PycharmProjects2020\qingganfenlei\data\weibo1.csv"
source = open(fileee,"r")
line = source.readlines()#读取后保存到line 方便后面循环
#(1)创建Executor
# use_cuda为False,表示运算场所为CPU;use_cuda为True,表示运算场所为GPU
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
# 用训练好的模型进行预测并输出预测结果
# 创建执行器
place = fluid.CPUPlace()
infer_exe = fluid.Executor(place)
infer_exe.run(fluid.default_startup_program())
model_save_dir = "D:\PycharmProjects2020\\tensor1\yaoyanjianche\data\model"
save_path = model_save_dir
# 从模型中获取预测程序、输入数据名称列表、分类器
[infer_program, feeded_var_names, target_var] = fluid.io.load_inference_model(dirname=save_path, executor=infer_exe)
# 获取数据
def get_data(sentence):
# 读取数据字典
with open('D:\PycharmProjects2020\\tensor1\yaoyanjianche\data/dict.txt', 'r', encoding='utf-8') as f_data:
dict_txt = eval(f_data.readlines()[0])
# print(dict_txt)
dict_txt = dict(dict_txt)
# print(dict_txt)
# 把字符串数据转换成列表数据
keys = dict_txt.keys()
data = []
for s in sentence:
# 判断是否存在未知字符
if not s in keys:
s = ''
# data.append(int(dict_txt[s]))
data.append(np.array(dict_txt[s]).astype("int64"))
# print(data)
return data
data = []
# 获取数据
#循环一下line 读取数据 并对它getdata 进行处理 放进data中
for i in line :
data.append(get_data(i))
# data1 = get_data('兴仁县今天抢小孩没抢走,把孩子母亲捅了一刀,看见这车的注意了,真事,车牌号辽HFM055!!!!!赶紧散播! 都别带孩子出去瞎转悠了 尤其别让老人自己带孩子出去 太危险了 注意了!!!!辽HFM055北京现代朗动,在各学校门口抢小孩!!!110已经 证实!!全市通缉!!')
# data2 = get_data('重庆真实新闻:2016年6月1日在重庆梁平县袁驿镇发生一起抢儿童事件,做案人三个中年男人,在三中学校到镇街上的一条小路上,把小孩直接弄晕(儿童是袁驿新幼儿园中班的一名学生),正准备带走时被家长及时发现用棒子赶走了做案人,故此获救!请各位同胞们以此引起非常重视,希望大家有爱心的人传递下')
# data3 = get_data('@尾熊C 要提前预习育儿知识的话,建议看一些小巫写的书,嘻嘻')
# data.append(data1)
# data.append(data2)
# data.append(data3)
# print(data)
# 获取每句话的单词数量
base_shape = [[len(c) for c in data]]
# 生成预测数据
tensor_words = fluid.create_lod_tensor(data, base_shape, place)
# 执行预测
result = infer_exe.run(program=infer_program,
feed={feeded_var_names[0]: tensor_words},
fetch_list=target_var)
# 分类名称
names = [ '谣言', '非谣言']
# print(range(len(data)))
# print(len(data))
# 获取结果概率最大的label
for i in range(len(data)):
lab = np.argsort(result)[0][i][-1]
print('预测结果标签为:%d, 分类为:%s, 概率为:%f' % (lab, names[lab], result[0][i][lab]))
#进行判断凡是 概率大于0.6的 lab1 放进f2
if result[0][i][lab] > 0.6 and lab==1: # 可以自定义范围
# print(i+'这是一个负面评价')
# print(SnowNLP(i).sentiments)
# 这段文本写入neg文件中
f2.write(line[i])
# f2.write('\n')
elif result[0][i][lab] > 0.6 and lab==0:
f1.write(line[i])