目标分割(一)FCN讲解
目标分割FCN
- ABSTRACT
- 1. INTRODUCTION
- 2. 稠密预测调整分类器
- 3. 去卷积--上采样
- 4. 跳跃结构
- Reference

原文:Fully Convolutional Networks for Semantic Segmentation
收录:CVPR 2015 (The IEEE Conference on Computer Vision and Pattern Recognition)
代码:FCN code
| 年份 | 模型 | 重要贡献 |
|---|---|---|
| 2014 | FCN | 在语义分割中推广使用端对端卷积神经网络,使用反卷积来进行上采样 |
| 2015 | U-Net | 构建了一套完整 的编码解码器 |
| 2015 | SegNet | 将最大池化转换为解码器来提高分辨率 |
| 2015 | Dilated Convolutions | 更广范围内提高了内容的聚合并不降低分辨率 |
| 2016 | DeepLab v1&v2 | |
| 2016 | RefineNet | 使用残差连接,降低了内存使用量,提高了模块间的特征融合 |
| 2016 | PSPNet | |
| 2017 | DeepLab V3 |
※中心思想:全卷积神经网络FCN主要使用以下三种技术:
- 卷积化(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
ABSTRACT
论文核心思想:构建全卷积网络,该网络接收任意大小的输入,并通过有效的处理和学习产生与原图像大小相同的输出。
论文所采用经典分类网络:
1. AlexNet
2. VGG net
3. GoogLeNet
我们将这三个分类网络调整为完全卷积网络,并通过微调(fine-tuning)来将它们学习的特征表示转换到分割任务上来。(其中达到最高分类精度的是VGG-16)
图像的语义分割: 简言之就是对一张image上的所有像素点进行分类,分配类别ID。
1. INTRODUCTION
现在卷积网络Conv在 目标识别 方面领域发展迅速。而且卷积网络不仅在全图式的分类上有所提高,也在结构化输出的局部任务上取得了进步。包括在目标检测边界框、部分和关键点预测 和 局部通信 方面。
在从粗糙到精细推理的进展中下一步自然是对每一个像素进行预测。早前的方法已经将卷积网络用于语义分割 ,其中每个像素被标记为其封闭对象或区域的类别,但是这项工作也有不足之处。
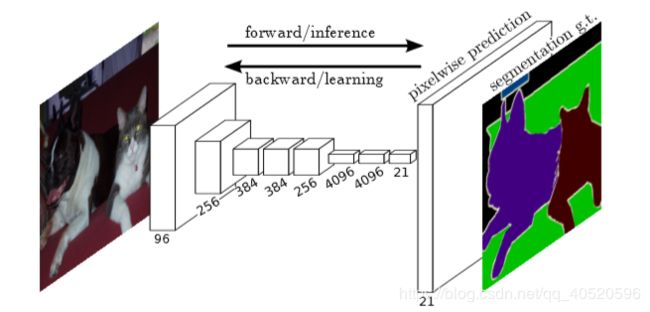
图1 全卷积网络FCN能对每个像素做出密集预测(dense prediction),例如语义分割
我们证明了一个完全卷积网络(FCN),经过端到端训练,像素到像素的语义分割在没有进一步机制的情况下超过了目前的水平。全卷积FCN在现有的网络基础上能对任意尺寸的输入预测密集输出,通过密集前馈计算和反向传播,实现了对图像的学习和推理。网络内的上采样层能在像素级别进行预测并且通过下采样池化来学习。
语义分割面临在语义和位置的内在张力问题:全局信息解决的“是什么”,而局部信息解决的是“在哪里”。在第4.2节中,我们定义了一种新的“跳跃”结构,它结合了深度、粗糙的语义信息和浅层、精细的表征信息。
2. 稠密预测调整分类器
典型的识别网络,包括LeNet、AlexNet及其更深层的后继网络,表面上采用固定大小的输入产生了非空间的输出。这些网络的全连通层FC具有固定的尺寸并丢弃空间坐标。然而,这些FC也可以看作是内核覆盖整个输入区域的卷积。
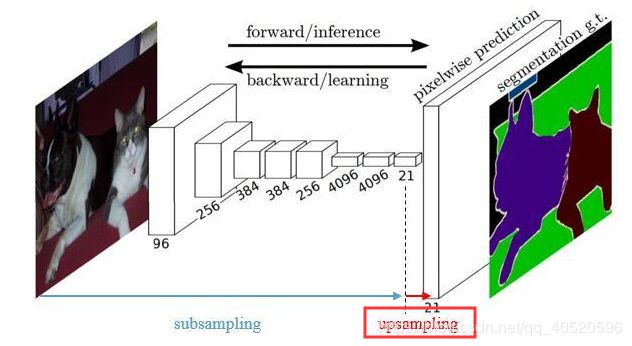
FCN与CNN区别: 一般的分类CNN网络( 例如VGG、Resnet ),在网络的最后会有一些全连接层FC,经过softmax后就可以获得label类别概率信息。但这个概率信息是一维,即只能标识整个图片的类别,不能标识每个像素点的类别,所以FC不适用于图像分割;而FCN把后面几个FC都换成Conv,这样就可以获得一张二维的特征图feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题。
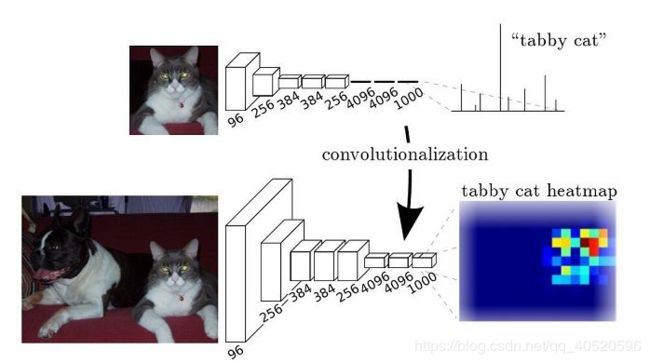
图2 将FC转换成Conv能使分类网络输出热图。添加层和空间损失(如图1所示)将生成端到端密集学习机制
如果输出按f的因数向下采样,则输入(通过左填充和上填充)向右移动x像素,向下移动y像素
3. 去卷积–上采样
实际上,对于 上采样(upsampling) 一般包括两种方式:
1. Resize,如双线性插值直接缩放,类似于图像缩放
2. Deconvolution(去卷积),也叫Transposed Convolution
去卷积具体是怎么实现,这里解释一下Deconvolution!
①对于一般卷积,下图则是卷积变换后,由蓝色变换成绿色,输入蓝色4x4矩阵,卷积核大小3x3。当设置卷积参数pad=0,stride=1时,输出绿色2x2矩阵;
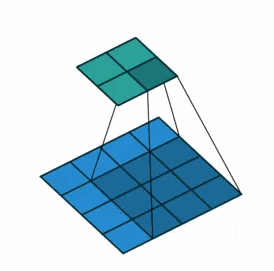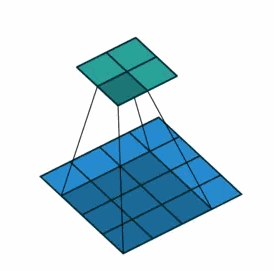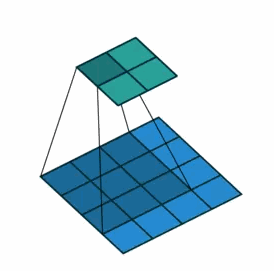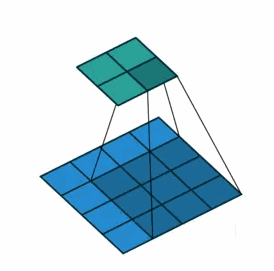
②对于去卷积,则是相当于把卷积倒过来,去卷积变换后,由蓝色变换成绿色,输入蓝色2x2矩阵,卷积核大小还是3x3。当设置反卷积参数pad=0,stride=1时输出绿色4x4矩阵。
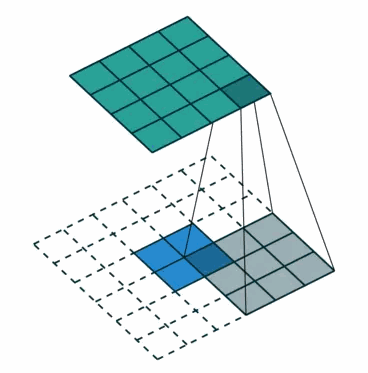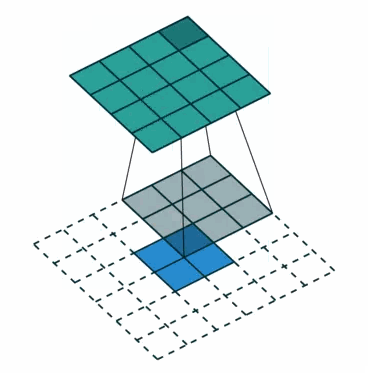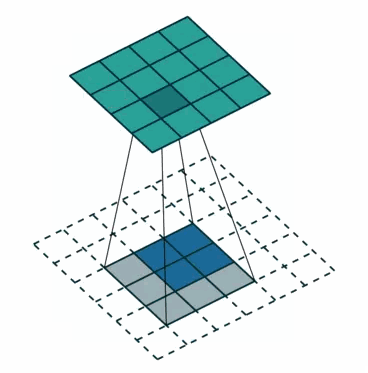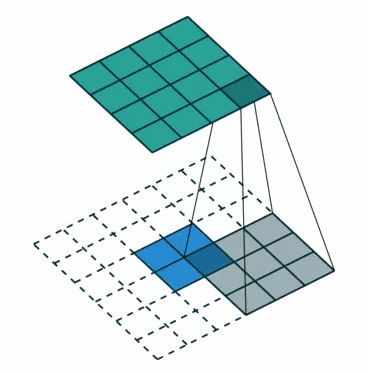
※Q:为什么需要上采样?
经过多次卷积、池化以后,得到的图像越来越小,分辨率越来越低(得到粗糙的图像),只有从这个分辨率低的粗略图像恢复到原图的分辨率,FCN是才能得到image中每一个像素的类别label,因此FCN使用上采样操作。例如经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。
综上所述: 模型前期是通过卷积、池化、非线性激活函数等作用输出特征图像,之后经过反卷积等操作恢复图像,但是输出的图像仍然是很粗糙,毕竟丢了很多细节。因此我们需要找到一种方式填补丢失的细节数据,所以就有了跳跃结构。
4. 跳跃结构
作用:将来自深层(粗糙)的语义信息和来自浅层(精细)的表征信息结合起来,得到更加精确和鲁棒的分割结果。
下图则是对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,一些细节无法恢复。于是Jonathan将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。下图是这个卷积和反卷积上采样的过程:
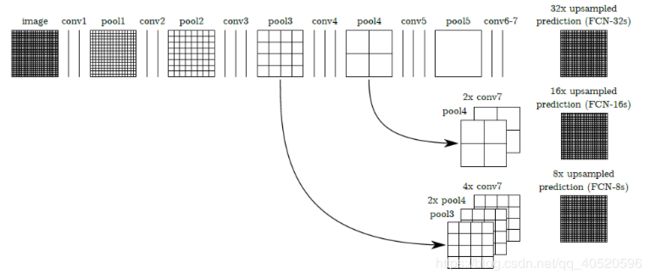
下图是32倍,16倍和8倍上采样得到的结果的对比,可以看到它们得到的结果越来越精确:

Reference
- 10分钟看懂全卷积神经网络( FCN ):语义分割深度模型先驱
- 图像语义分割入门+FCN/U-Net网络解析
- 【论文笔记】FCN
- FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)