Gradient Boosted Decision Trees(GBDT)详解
感受
GBDT集成方法的一种,就是根据每次剩余的残差,即损失函数的值。在残差减少的方向上建立一个新的模型的方法,直到达到一定拟合精度后停止。我找了一个相关的例子来帮助理解。本文结合了多篇博客和书,试图完整介绍GBDT的内容,欢迎大家来指正。
介绍
GBDT是一个应用很广泛的算法,可以用来做分类、回归。GBDT这个算法还有其它名字,如MART(Multiple AdditiveRegression Tree),GBRT(Gradient Boost Regression Tree),TreeNet等等。Gradient Boost其实是一个框架,里面可以套入很多不同的算法。
原始的Boost算法是在算法开始的时候,为每一个样本赋上一个权重值,初始的时候,大家都是一样重要的。在每一步训练中得到的模型,会使得数据点的估计有对有错,我们就在每一步结束后,增加分错的点的权重,减少分对点的权重,这样使得某些点如果老师被分错,那么就会被“严重关注”,也就被赋上一个很高的权重。然后等进行了N次迭代(由用户指定),将得到N个简单的分类器(basic learner),然后我们将它们组合起来(比如说可以对它们进行加权、或者让它们进行投票等),得到一个最终的模型。
Gradient Boost与传统的Boost的区别是,每一次的计算是为了减少上一次的残差(residual),而为了消除残差,我们可以在残差减少的梯度方向上建立一个新的模型。所以说,在Gradient Boost中,每个新模型的建立是为了使得之前模型的残差梯度方向减少,对传统Boost对正确,错误的样本进行加权有很大的区别。
在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是ft-1(x),损失函数是L(yi,ft-1(x)),我们本轮迭代的目标是找到一个CART回归树模型的弱学习器ht(x),让本轮的损失L(yi,ft(x)=L(yi,ft-1(x))+ht(x)最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
GBDT的思想用一个通俗的例子解释,加入有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有1岁了。如果我们的迭代轮数还没有完,可以继续往下迭代,每一轮迭代,拟合的岁数误差都会减小。

上图为一个GBDT的例子,表示预测一个人是否喜欢电脑游戏。
GBDT梯度提升决策树算法是在决策树的基础上引入GB(逐步提升)和shrinkage(小幅缩进)两种思想,从而提升普通决策树的泛化能力。核心点在于GBDT的结果是多颗决策树预测值的累加,而残差则是每棵决策树的学习目标。GBDT是回归树而不是分类树,调整后可用于分类。
从上面的例子看这个思想还是蛮简单的,但是有个问题是这个损失的拟合不好度量,损失函数各种各样,怎么找到一种通用的拟合方法呢?
概念
GBDT的负梯度拟合
针对损失函数拟合方法的问题,大牛Friedman提出了用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树。第t轮的第i个样本的损失函数的负梯度表示为:

利用(xi,rti)(i=1,2,…,m),我们可以拟合一个CART回归树,得到了第t个回归树,其对应的叶结点区域Rtj,j=1,2,…,J.其中J为叶子结点的个数。
针对每一个叶子结点里的样本,我们求出使损失函数最小,也就是拟合叶子结点最好的输出值cij如下:

这样我们就得到了本轮的决策树拟合函数如下:
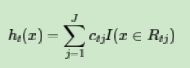
从而本轮最终得到的强学习器的表达式如下:

通过损失函数的负梯度来拟合,我们找到了一种通用的拟合损失误差的办法,这样无论是分裂问题还是回归问题,我们通过其损失函数的负梯度的拟合,就可以用GBDT来解决我们的分类回归问题,区别仅仅在于损失函数不同导致的负梯度不同而已。
决策树
决策树时一个类似于流程图的结构,每个内部结点代表一个属性的测试,每个分支代表测试的结果,每个叶子结点代表分类的结果。从根结点到叶子结点代表分类的规则。
详细了解的话可以参考我的博客http://blog.csdn.net/w5688414/article/details/77920930
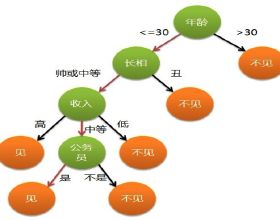
上图是一个决策树的例子。
信息熵:

样本集为D,Pk(k=1,2,…,Y)代表样本集D中第k个样本的比例。决策树就是每次选择一个属性划分使得Ent(D)最小。
决策树有很多算法,ID3,CART的区别是所选择的划分标准不一样,ID3选择的是信息增益,当CART是分类树时,采用GINI值作为节点分裂的依据;当CART是回归树时,采用样本的最小方差作为节点分裂的依据;。



分裂特征为a’,值为v’.DL是样本val(x,a’)<=v’ 的集合.DR是样本val(x,a’)>v’的集合.D=DL∪DR。
选择分裂点的依据:

对于决策树模型,分类和回归的损失函数可以用户自定义,通常,扫描所有分裂点的代价很大,所以有一些近似算法(这个自行百度了),为了避免过拟合,常用的方法是后剪枝。
集成学习
集成方法就是使用多种学习算法去获得更好的预测性能的方法,典型的集成方法有很多,如AdaBoost,随机森林(Random Forest),GBDT。前面的两种算法不是本文讲的内容,本文主要解析一下GBDT算法。
损失函数

算法
回归算法
当GBDT用于回归时,常用的损失函数包括平方损失函数、绝对值损失函数、Huber损失函数。每次朝着损失函数的负梯度方向移动即可取得损失函数的最小值。
输入:训练样本T={(x1,y1),(x2,y2),…,(xm,ym) },最大迭代次数是T,损失函树为L.
输出:强学习器f(x)
1) 初始化弱分类器

2) 对迭代轮数t=1,2,…,T有:
a) 对样本i=1,2,…,m,计算负梯度:

b) 利用(xi,rti)(i=1,2,…,m),拟合一个CART回归树,得到第t颗回归树,其对应的叶子结点区域为Rtj,j=1,2,…,J. 其中J为回归树t的叶子结点的个数。
c) 对叶子区域j=1,2,…,J.计算最佳拟合值

d) 更新强学习器

3)得到强学习器f(x)的表达式

分类算法
当GBDT用于分类时,常用的损失函数有对数损失函数、指数损失函数等。这种损失函数的目的是求预测值为真实值的概率。
二元分类
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,其损失函数为:
![]()
其中y∈{-1,+1},则此时的负梯度误差为

对于生成的决策树,我们各个叶子结点的最佳残差拟合值为

由于上式比较难优化,我们一般使用近似值代替:

除了负梯度计算和叶子结点的最佳残差拟合的线性搜索,二元GBDT回归算法和GBDT回归算法过程相同。
多元分类
多元GBDT比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归。假设类别为K,则此时我们的对数似然损失函数为:

其中如果样本输出类别为K,则yk=1。第k类的概率pk(x)的表达式为:

集合两式,我们可以计算出第i个样本对应类别l的负梯度误差为

(分母多了个括号)
观察上式可以看出,其实这里的误差就是样本i对应的类别l的真实概率和t-1轮预测概率的差值。
对于生成的决策树,我们各个叶子结点的最佳残差拟合值为

由于上式比较难优化,我们一般使用近似值代替

除了负梯度计算和叶子结点的最佳残差拟合的线性搜索,多元GBDT分类和二元GBDT分类以及回归算法过程相似。
GBDT优缺点
优点
1) 可以灵活处理各种类型的数据,包括连续值和离散值。
2) 在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数(huber详细见本文的损失函数模块)和Quantile损失函数。
缺点
1) 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT(Stochastic Gradient Boosting Tree)来达到部分并行。
例子
这个例子不是一个典型的GBDT的例子,没有用到负梯度求解,但是过程和GBDT一样,并且有明确的计算过程,可以帮助理解GBDT的过程,值得借鉴。实际问题比这个简单的例子复杂得多。
已知如表8.2所示的训练数据,x的取值范围为区间[0.5,10.5],y的取值范围为区间[5.0,10.0],学习这个回归问题的boosted tree模型,考虑只用树桩作为基本函数。损失函数是误差的平方和。

按照算法,第1步求f1(x)即回归树T1(x)。
首先通过以下优化问题:

求解训练数据的切分点s:
![]()
容易求得在R1,R2内部使平方损失误差达到最小值的c1,c2为

这里N1,N2是R1,R2的样本点数。

现将s及m(x)的计算结果列表如下:


用f1(x)拟合训练数据的残差见表8.4,表中r2i=yi-f1(xi),i=1,2,…,10

用f1(x)拟合训练数据的平方损失误差:
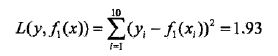
第2步求T2(x)。方法与求T1(x)一样,只是拟合的数据表8.4的残差。可以得到:

用f2(x)拟合训练数据的平方损失误差是

继续求得


用f6(x)拟合训练数据的平方损失误差是
![]()
假设此时已满足误差要求,那么f(x)=f6(x)即为所求提升树。读者可以手算一下,计算量还是有点大,毕竟有那么多求和和求均值,还有平方和。
参考文献
[1]. Gradient boosting. https://en.wikipedia.org/wiki/Gradient_boosting
[2]. 梯度提升树(GBDT)原理小结
[3]. 决策树系列(五)——CART
[4] GBDT(Gradient Boosting Decision Tree) 没有实现只有原理
[5].李航.《统计机器学习》