arangoDB基本操作
CRUD
Create documents
在使用AQL插入文档之前,我们需要一个放置文档的地方—集合。集合可以通过web接口、arangosh或驱动程序来管理。然而,使用AQL是不可能做到这一点的。
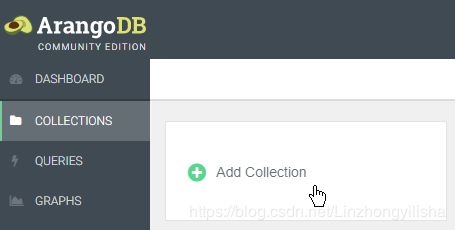

单击web界面中的collection,然后添加collection并键入字符作为名称。确认保存。新collection应该出现在列表中。
接下来,单击queries。要创建使用AQL收集的第一个文档,请使用下面的AQL查询,您可以将其粘贴到查询文本框中,然后单击Execute运行:
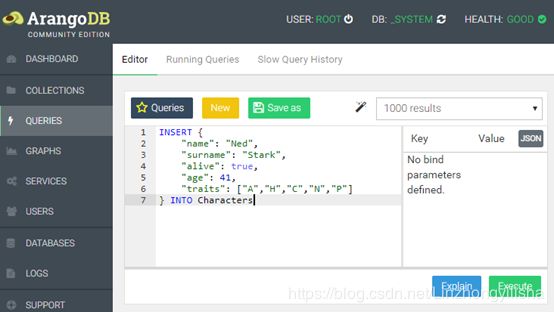
INSERT {
"name": "Ned",
"surname": "Stark",
"alive": true,
"age": 41,
"traits": ["A","H","C","N","P"]
} INTO Characters
语法是 INSERT document INTO collectionName。document是一个对象,就像您可能从JavaScript或JSON中了解到的那样,它由属性键和值对组成。属性键周围的引号在AQL中是可选的。键总是字符序列(字符串),而属性值可以有不同的类型:
零
布尔(真、假)
数(整数和浮点数)
字符串
数组
对象
我们插入的字符文档的名称和姓氏都是字符串值。活动状态使用布尔值。年龄是一个数值。特征是字符串数组。整个文档是一个对象。
让我们在一个查询中添加一些其他字符:
LET data = [
{ "name": "Robert", "surname": "Baratheon", "alive": false, "traits": ["A","H","C"] },
{ "name": "Jaime", "surname": "Lannister", "alive": true, "age": 36, "traits": ["A","F","B"] },
{ "name": "Catelyn", "surname": "Stark", "alive": false, "age": 40, "traits": ["D","H","C"] },
{ "name": "Cersei", "surname": "Lannister", "alive": true, "age": 36, "traits": ["H","E","F"] },
{ "name": "Daenerys", "surname": "Targaryen", "alive": true, "age": 16, "traits": ["D","H","C"] },
{ "name": "Jorah", "surname": "Mormont", "alive": false, "traits": ["A","B","C","F"] },
{ "name": "Petyr", "surname": "Baelish", "alive": false, "traits": ["E","G","F"] },
{ "name": "Viserys", "surname": "Targaryen", "alive": false, "traits": ["O","L","N"] },
{ "name": "Jon", "surname": "Snow", "alive": true, "age": 16, "traits": ["A","B","C","F"] },
{ "name": "Sansa", "surname": "Stark", "alive": true, "age": 13, "traits": ["D","I","J"] },
{ "name": "Arya", "surname": "Stark", "alive": true, "age": 11, "traits": ["C","K","L"] },
{ "name": "Robb", "surname": "Stark", "alive": false, "traits": ["A","B","C","K"] },
{ "name": "Theon", "surname": "Greyjoy", "alive": true, "age": 16, "traits": ["E","R","K"] },
{ "name": "Bran", "surname": "Stark", "alive": true, "age": 10, "traits": ["L","J"] },
{ "name": "Joffrey", "surname": "Baratheon", "alive": false, "age": 19, "traits": ["I","L","O"] },
{ "name": "Sandor", "surname": "Clegane", "alive": true, "traits": ["A","P","K","F"] },
{ "name": "Tyrion", "surname": "Lannister", "alive": true, "age": 32, "traits": ["F","K","M","N"] },
{ "name": "Khal", "surname": "Drogo", "alive": false, "traits": ["A","C","O","P"] },
{ "name": "Tywin", "surname": "Lannister", "alive": false, "traits": ["O","M","H","F"] },
{ "name": "Davos", "surname": "Seaworth", "alive": true, "age": 49, "traits": ["C","K","P","F"] },
{ "name": "Samwell", "surname": "Tarly", "alive": true, "age": 17, "traits": ["C","L","I"] },
{ "name": "Stannis", "surname": "Baratheon", "alive": false, "traits": ["H","O","P","M"] },
{ "name": "Melisandre", "alive": true, "traits": ["G","E","H"] },
{ "name": "Margaery", "surname": "Tyrell", "alive": false, "traits": ["M","D","B"] },
{ "name": "Jeor", "surname": "Mormont", "alive": false, "traits": ["C","H","M","P"] },
{ "name": "Bronn", "alive": true, "traits": ["K","E","C"] },
{ "name": "Varys", "alive": true, "traits": ["M","F","N","E"] },
{ "name": "Shae", "alive": false, "traits": ["M","D","G"] },
{ "name": "Talisa", "surname": "Maegyr", "alive": false, "traits": ["D","C","B"] },
{ "name": "Gendry", "alive": false, "traits": ["K","C","A"] },
{ "name": "Ygritte", "alive": false, "traits": ["A","P","K"] },
{ "name": "Tormund", "surname": "Giantsbane", "alive": true, "traits": ["C","P","A","I"] },
{ "name": "Gilly", "alive": true, "traits": ["L","J"] },
{ "name": "Brienne", "surname": "Tarth", "alive": true, "age": 32, "traits": ["P","C","A","K"] },
{ "name": "Ramsay", "surname": "Bolton", "alive": true, "traits": ["E","O","G","A"] },
{ "name": "Ellaria", "surname": "Sand", "alive": true, "traits": ["P","O","A","E"] },
{ "name": "Daario", "surname": "Naharis", "alive": true, "traits": ["K","P","A"] },
{ "name": "Missandei", "alive": true, "traits": ["D","L","C","M"] },
{ "name": "Tommen", "surname": "Baratheon", "alive": true, "traits": ["I","L","B"] },
{ "name": "Jaqen", "surname": "H'ghar", "alive": true, "traits": ["H","F","K"] },
{ "name": "Roose", "surname": "Bolton", "alive": true, "traits": ["H","E","F","A"] },
{ "name": "The High Sparrow", "alive": true, "traits": ["H","M","F","O"] }
]
FOR d IN data
INSERT d INTO Characters
LET关键字定义了一个变量,其中名称数据和一个对象数组作为值,所以让variableName = valueExpression和表达式作为一个字面数组定义,如[{…},{…},……].
FOR variableName IN expression用于遍历数据数组的每个元素。在每个循环中,一个元素被分配给变量d。然后,这个变量将在INSERT语句中使用,而不是在文本对象定义中使用。所做的基本上是:
INSERT {
"name": "Robert",
"surname": "Baratheon",
"alive": false,
"traits": ["A","H","C"]
} INTO Characters
INSERT {
"name": "Jaime",
"surname": "Lannister",
"alive": true,
"age": 36,
"traits": ["A","F","B"]
} INTO Characters注意:AQL不允许在一个查询中针对同一个集合执行多个插入操作。但是,它可以作为FOR循环的主体,插入多个文档,就像我们在上面的查询中所做的那样。
Read documents
There are a couple of documents in the Characters collection by now. We can retrieve them all using a FOR loop again. This time however, we use it to go through all documents in the collection instead of an array
到目前为止,在Characters集合中有几个文档。我们可以再次使用FOR循环来检索它们。但是,这一次,我们使用它来遍历集合中的所有文档,而不是数组。
FOR c IN Characters
RETURN cThe syntax of the loop is FOR variableName IN collectionName. For each document in the collection, c is assigned a document, which is then returned as per the loop body. The query returns all characters we previously stored.
Among them should be Ned Stark, similar to this example:
循环的语法 FOR variableName IN collectionName。对于集合中的每个文档,c都被分配了一个文档,然后根据循环体返回该文档。查询返回我们之前存储的所有字符。
其中应该包括 Ned Stark,如下例所示:
{
"_key": "2861650",
"_id": "Characters/2861650",
"_rev": "_V1bzsXa---",
"name": "Ned",
"surname": "Stark",
"alive": true,
"age": 41,
"traits": ["A","H","C","N","P"]
},
该文档具有我们存储的四个属性,以及数据库系统添加的另外三个属性。每个文档都需要一个惟一的_key,它在集合中标识它。_id是一个计算属性,是集合名称、正斜杠/和文档键的连接。它惟一地标识数据库中的文档。_rev是由系统管理的修订ID。
用户可以在创建文档时提供文档密钥,或者自动分配一个惟一的值。以后不能再改了。以下划线_开头的所有三个系统属性都是只读的。
我们可以使用文档键或文档ID在AQL函数document()的帮助下检索特定的文档:
RETURN DOCUMENT("Characters", "2861650")
// --- or ---
RETURN DOCUMENT("Characters/2861650")
[
{
"_key": "2861650",
"_id": "Characters/2861650",
"_rev": "_V1bzsXa---",
"name": "Ned",
"surname": "Stark",
"alive": true,
"age": 41,
"traits": ["A","H","C","N","P"]
}
]Note: Document keys will be different for you. Change the queries accordingly. Here, "2861650" is the key for the Ned Stark document, and "2861653" for Catelyn Stark.
The DOCUMENT() function also allows to fetch multiple documents at once:
注意:文档键对您来说是不同的。相应地更改查询。这里,“2861650”是Ned Stark文件的关键字,“2861653”是Catelyn Stark的关键字。
DOCUMENT()函数还允许同时获取多个文档:
RETURN DOCUMENT("Characters", ["2861650", "2861653"])
// --- or ---
RETURN DOCUMENT(["Characters/2861650", "Characters/2861653"])
[
[
{
"_key": "2861650",
"_id": "Characters/2861650",
"_rev": "_V1bzsXa---",
"name": "Ned",
"surname": "Stark",
"alive": true,
"age": 41,
"traits": ["A","H","C","N","P"]
},
{
"_key": "2861653",
"_id": "Characters/2861653",
"_rev": "_V1bzsXa--B",
"name": "Catelyn",
"surname": "Stark",
"alive": false,
"age": 40,
"traits": ["D","H","C"]
}
]
]See the DOCUMENT() function documentation for more details.
Update documents
According to our Ned Stark document, he is alive. When we get to know that he died, we need to change the alive attribute. Let us modify the existing document:
根据Ned Stark文件,他还活着。当我们知道他死了,我们需要改变活着的属性。让我们修改现有的文件:
UPDATE "2861650" WITH { alive: false } IN Characters
The syntax is UPDATE documentKey WITH object IN collectionName. It updates the specified document with the attributes listed (or adds them if they don’t exist), but leaves the rest untouched. To replace the entire document content, you may use REPLACE instead of UPDATE:
语法UPDATE documentKey WITH object IN collectionName。它使用列出的属性更新指定的文档(如果不存在属性,则添加它们),但不修改其余的属性。要替换整个文档内容,可以使用replace代替UPDATE:
REPLACE "2861650" WITH {
name: "Ned",
surname: "Stark",
alive: false,
age: 41,
traits: ["A","H","C","N","P"]
} IN Characters
这也在一个循环中使用,添加一个新的属性到所有documens,例如:
FOR c IN Characters
UPDATE c WITH { season: 1 } IN Characters
A variable is used instead of a literal document key, to update each document. The query adds an attribute season to the documents’ top-level. You can inspect the result by re-running the query that returns all documents in collection:
使用变量而不是文本文档键来更新每个文档。查询将属性season添加到文档的顶级。您可以通过重新运行返回集合中所有文档的查询来检查结果:
FOR c IN Characters
RETURN cDelete documents
to fully remove documents from a collection, there is the REMOVE operation. It works similar to the other modification operations, yet without a WITH clause:
要从集合中完全删除文档,可以执行remove操作。它的工作原理与其他修改操作类似,但没有WITH子句:
REMOVE "2861650" IN Characters
它也可以用在循环体中,有效地截断一个集合:
FOR c IN Characters
REMOVE c IN CharactersMatching documents
到目前为止,我们要么查找单个文档,要么返回整个字符集合。对于查找,我们使用DOCUMENT()函数,这意味着我们只能通过文档的键或ID来查找文档。
为了找到满足某些比键相等更复杂的标准的文档,AQL中有一个过滤器操作,它使我们能够制定任意的条件来匹配文档。
Equality condition
FOR c IN Characters
FILTER c.name == "Ned"
RETURN c
过滤器条件读起来像:“字符文档的属性名必须等于内嵌的字符串”。如果条件适用,则返回字符文档。这同样适用于任何属性:
FOR c IN Characters
FILTER c.surname == "Stark"
RETURN cRange conditions
严格的等式是我们可以表述的一个可能条件。然而,我们还可以制定许多其他条件。例如,我们可以问所有年轻的角色:
FOR c IN Characters
FILTER c.age >= 13
RETURN c.name
[
"Joffrey",
"Tyrion",
"Samwell",
"Ned",
"Catelyn",
"Cersei",
"Jon",
"Sansa",
"Brienne",
"Theon",
"Davos",
"Jaime",
"Daenerys"
]运算符>=表示更大或更大,因此返回年龄为13岁或更大的每个字符(在示例中仅返回其名称)。我们可以通过将操作符更改为小于13并使用对象语法定义要返回的属性子集来返回所有小于13岁的字符的名称和年龄
FOR c IN Characters
FILTER c.age < 13
RETURN { name: c.name, age: c.age }
[
{ "name": "Tommen", "age": null },
{ "name": "Arya", "age": 11 },
{ "name": "Roose", "age": null },
...
]您可能会注意到,它返回的名称和年龄为30个字符,大多数为null。原因是,如果查询请求一个属性,但是文档中不存在这样的属性,并且null与较低的数字进行比较(请参见类型和值顺序),那么null是回退值。因此,它意外地满足了年龄标准c。年龄< 13 (null < 13)。
Multiple conditions
FOR c IN Characters
FILTER c.age < 13
FILTER c.age != null
RETURN { name: c.name, age: c.age }
[
{ "name": "Arya", "age": 11 },
{ "name": "Bran", "age": 10 }
]
这同样可以用布尔和运算符写成:
FOR c IN Characters
FILTER c.age < 13 AND c.age != null
RETURN { name: c.name, age: c.age }
And the second condition could as well be c.age > null.Alternative conditions
如果您希望文档满足一个或另一个条件,可能还需要满足不同的属性,请使用or:
FOR c IN Characters
FILTER c.name == "Jon" OR c.name == "Joffrey"
RETURN { name: c.name, surname: c.surname }Sorting and limiting
Cap the result count
可能并不总是需要返回所有文档,而FOR循环通常会返回所有文档。在这种情况下,我们可以使用limit()操作来限制文档的数量:
FOR c IN Characters
LIMIT 5
RETURN c.name
[
"Joffrey",
"Tommen",
"Tyrion",
"Roose",
"Tywin"
]
LIMIT后面跟着一个数字,用于最大文档计数。然而,还有第二种语法,它允许您跳过一定数量的记录并返回后面的n个文档:
FOR c IN Characters
LIMIT 2, 5
RETURN c.name
[
"Tyrion",
"Roose",
"Tywin",
"Samwell",
"Melisandre"
]
Sort by name
这里显示的查询返回匹配记录的顺序基本上是随机的。要按定义的顺序返回它们,可以添加SORT()操作。如果与LIMIT()结合使用,则会对结果产生很大的影响,因为如果先排序,结果就会变得可预测。
FOR c IN Characters
SORT c.name
LIMIT 10
RETURN c.name
[
"Arya",
"Bran",
"Brienne",
"Bronn",
"Catelyn",
"Cersei",
"Daario",
"Daenerys",
"Davos",
"Ellaria"
]看看它是如何按名称排序的,然后返回按字母顺序排在前面的10个名称。我们可以颠倒排序顺序,DESC降序:
FOR c IN Characters
SORT c.name DESC
LIMIT 10
RETURN c.name
[
"Ygritte",
"Viserys",
"Varys",
"Tywin",
"Tyrion",
"Tormund",
"Tommen",
"Theon",
"The High Sparrow",
"Talisa"
]The first sort was ascending, which is the default order. Because it is the default, it is not required to explicitly ask for ASC order.
Sort by multiple attributes
假设我们要按surname排序。许多角色都有一个surname。相同surname的字符之间的结果顺序没有定义。我们可以先按surname排序,然后按name确定顺序:
FOR c IN Characters
FILTER c.surname
SORT c.surname, c.name
LIMIT 10
RETURN {
surname: c.surname,
name: c.name
}
[
{ "surname": "Baelish", "name": "Petyr" },
{ "surname": "Baratheon", "name": "Joffrey" },
{ "surname": "Baratheon", "name": "Robert" },
{ "surname": "Baratheon", "name": "Stannis" },
{ "surname": "Baratheon", "name": "Tommen" },
{ "surname": "Bolton", "name": "Ramsay" },
{ "surname": "Bolton", "name": "Roose" },
{ "surname": "Clegane", "name": "Sandor" },
{ "surname": "Drogo", "name": "Khal" },
{ "surname": "Giantsbane", "name": "Tormund" }
]总的来说,文档是按last name排序的。如果两个字符的surname相同,则比较name并对结果排序。
注意,在排序之前应用了一个filter,只允许文档通过,它实际上具有一个surname(许多没有surname,并且会导致结果中出现null值)。
Sort by age
The order can also be determined by a numeric value, such as the age:
FOR c IN Characters
FILTER c.age
SORT c.age
LIMIT 10
RETURN {
name: c.name,
age: c.age
}
[
{ "name": "Bran", "age": 10 },
{ "name": "Arya", "age": 11 },
{ "name": "Sansa", "age": 13 },
{ "name": "Jon", "age": 16 },
{ "name": "Theon", "age": 16 },
{ "name": "Daenerys", "age": 16 },
{ "name": "Samwell", "age": 17 },
{ "name": "Joffrey", "age": 19 },
{ "name": "Tyrion", "age": 32 },
{ "name": "Brienne", "age": 32 }
]
使用filter来避免没有age属性的文档。其余的文档按age按升序排序,返回最年轻的十个字符的名称和年龄。
See the SORT operation and LIMIT operation documentation for more details.
Joining together
References to other documents
我们导入的字符数据为每个字符都有一个属性traits,这是一个字符串数组。它不存储字符特性
然而直接:
{
"name": "Ned",
"surname": "Stark",
"alive": false,
"age": 41,
"traits": ["A","H","C","N","P"]
}它是一串没有明显意义的字母。这里的想法是traits应该存储另一个的文档键集合,我们可以使用它将字母解析为“strong”之类的标签。使用另一个集合来获取实际特征的好处是,我们可以很容易地查询所有现有的特性,并以多种语言存储标签,例如在一个中心位置。如果我们将直接嵌入特征. .
{
"name": "Ned",
"surname": "Stark",
"alive": false,
"age": 41,
"traits": [
{
"de": "stark",
"en": "strong"
},
{
"de": "einflussreich",
"en": "powerful"
},
{
"de": "loyal",
"en": "loyal"
},
{
"de": "rational",
"en": "rational"
},
{
"de": "mutig",
"en": "brave"
}
]
}如果要重命名或翻译其中一个字符,则需要找到具有相同特征的所有其他字符文档,并在其中执行更改。如果我们只引用另一个集合中的一个trait,那么它就像更新单个文档一样简单。
Importing traits
Below you find the traits data. Follow the pattern shown in Create documents to import it:
Create a document collection Traits
Assign the data to a variable in AQL, LET data = [ ... ]
Use a FOR loop to iterate over each array element of the data
INSERT the element INTO Traits
[
{ "_key": "A", "en": "strong", "de": "stark" },
{ "_key": "B", "en": "polite", "de": "freundlich" },
{ "_key": "C", "en": "loyal", "de": "loyal" },
{ "_key": "D", "en": "beautiful", "de": "schön" },
{ "_key": "E", "en": "sneaky", "de": "hinterlistig" },
{ "_key": "F", "en": "experienced", "de": "erfahren" },
{ "_key": "G", "en": "corrupt", "de": "korrupt" },
{ "_key": "H", "en": "powerful", "de": "einflussreich" },
{ "_key": "I", "en": "naive", "de": "naiv" },
{ "_key": "J", "en": "unmarried", "de": "unverheiratet" },
{ "_key": "K", "en": "skillful", "de": "geschickt" },
{ "_key": "L", "en": "young", "de": "jung" },
{ "_key": "M", "en": "smart", "de": "klug" },
{ "_key": "N", "en": "rational", "de": "rational" },
{ "_key": "O", "en": "ruthless", "de": "skrupellos" },
{ "_key": "P", "en": "brave", "de": "mutig" },
{ "_key": "Q", "en": "mighty", "de": "mächtig" },
{ "_key": "R", "en": "weak", "de": "schwach" }
]
Resolving traits
让我们从简单的开始,只返回每个字符的traits属性:
FOR c IN Characters
RETURN c.traits
[
{ "traits": ["A","H","C","N","P"] },
{ "traits": ["D","H","C"] },
...
]Also see the Fundamentals of Objects / Documents about attribute access.
我们可以使用traits数组和DOCUMENT()函数来使用元素作为文档键,并在traits集合中查找它们:
FOR c IN Characters
RETURN DOCUMENT("Traits", c.traits)
函数的作用是:通过文档标识符查找单个或多个文档。在我们的示例中,我们将要从中获取文档的集合名作为第一个参数(“Traits”)传递,将文档键数组(_key属性)作为第二个参数传递。作为回报,我们将得到每个字符的完整特征文档数组。
这是一个有点太多的信息,所以让我们只返回英语标签使用数组扩展符号:
FOR c IN Characters
RETURN DOCUMENT("Traits", c.traits)[*].en
[
[
"strong",
"powerful",
"loyal",
"rational",
"brave"
],
[
"beautiful",
"powerful",
"loyal"
],
...
]
Merging characters and traits
太好了,我们把字母分解成有意义的特征!但我们也需要知道它们属于哪个角色。因此,我们需要合并字符文档和来自特征文档的数据:
FOR c IN Characters
RETURN MERGE(c, { traits: DOCUMENT("Traits", c.traits)[*].en } )
[
{
"_id": "Characters/2861650",
"_key": "2861650",
"_rev": "_V1bzsXa---",
"age": 41,
"alive": false,
"name": "Ned",
"surname": "Stark",
"traits": [
"strong",
"powerful",
"loyal",
"rational",
"brave"
]
},
{
"_id": "Characters/2861653",
"_key": "2861653",
"_rev": "_V1bzsXa--B",
"age": 40,
"alive": false,
"name": "Catelyn",
"surname": "Stark",
"traits": [
"beautiful",
"powerful",
"loyal"
]
},
...
]
Merge()函数的作用是:合并对象。因为我们使用了一个对象{traits:…}具有与原始字符属性相同的属性名特征,合并操作覆盖了原始字符属性。
Join another way
函数的作用是:利用主索引快速查找文档。但是,只能通过标识符查找文档。对于我们示例中的用例,完成一个简单的连接就足够了。
还有另一种更灵活的连接语法:在多个集合上嵌套for循环,并使用筛选条件来匹配属性。在traits键数组的情况下,需要第三个循环来迭代键:
FOR c IN Characters
RETURN MERGE(c, {
traits: (
FOR key IN c.traits
FOR t IN Traits
FILTER t._key == key
RETURN t.en
)
})对于每个字符,它循环遍历它的traits属性(例如["D","H","C"]),对于这个数组中的每个文档引用,它循环遍历traits集合。有一个条件可以将文档键与键引用匹配。在本例中,内部FOR循环和过滤器被转换为主索引查找,而不是构建笛卡尔积来过滤除单个匹配外的所有内容:集合中的文档键是惟一的,因此只能有一个匹配。
每次写出来,返回English trait,然后将所有trait与字符文档合并。结果与使用DOCUMENT()的查询相同。但是,这种嵌套FOR循环和过滤器的方法并不局限于主键。您也可以对任何其他属性执行此操作。要实现高效查找,请确保为该属性添加了一个散列索引。如果它的值是惟一的,那么还将index选项设置为惟一。
Graph traversal
Traversal
在ArangoDB中,两个文档(父文档和子字符文档)可以通过edge文档链接。Edge文档存储在Edge集合中,并具有两个附加属性:_from和_to。它们通过文档id (_id)引用任何两个文档。
ChildOf relations
我们的角色有以下父母和孩子之间的关系(只是为了更好的概述而直呼其名):
Robb -> Ned
Sansa -> Ned
Arya -> Ned
Bran -> Ned
Jon -> Ned
Robb -> Catelyn
Sansa -> Catelyn
Arya -> Catelyn
Bran -> Catelyn
Jaime -> Tywin
Cersei -> Tywin
Tyrion -> Tywin
Joffrey -> Jaime
Joffrey -> Cersei
Visualized as graph:
Creating the edges
要创建将这些关系存储在数据库中所需的edge文档,我们可以运行一个查询,该查询结合了连接和筛选,以匹配正确的字符文档,然后使用它们的_id属性将一个edge插入edge collection ChildOf。
首先,创建一个名为ChildOf的新集合,并确保将集合类型更改为Edge。
Then run the following query:
LET data = [
{
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Robb", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Sansa", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Arya", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Bran", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Robb", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Sansa", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Arya", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Bran", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Jon", "surname": "Snow" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Jaime", "surname": "Lannister" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Cersei", "surname": "Lannister" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Tyrion", "surname": "Lannister" }
}, {
"parent": { "name": "Cersei", "surname": "Lannister" },
"child": { "name": "Joffrey", "surname": "Baratheon" }
}, {
"parent": { "name": "Jaime", "surname": "Lannister" },
"child": { "name": "Joffrey", "surname": "Baratheon" }
}
]
FOR rel in data
LET parentId = FIRST(
FOR c IN Characters
FILTER c.name == rel.parent.name
FILTER c.surname == rel.parent.surname
LIMIT 1
RETURN c._id
)
LET childId = FIRST(
FOR c IN Characters
FILTER c.name == rel.child.name
FILTER c.surname == rel.child.surname
LIMIT 1
RETURN c._id
)
FILTER parentId != null AND childId != null
INSERT { _from: childId, _to: parentId } INTO ChildOf
RETURN NEW
字符文档没有用户定义的键。如果有的话,我们可以更容易地创建边,比如:
INSERT { _from: "Characters/robb", _to: "Characters/ned" } INTO ChildOf
然而,基于字符名以编程方式创建边缘是一个很好的练习。查询的分类:
以对象数组的形式将关系分配给一个变量数据,每个对象都有一个父属性和一个子属性,每个对象都有子属性name和name
对于这个数组中的每个元素,将一个关系分配给一个变量rel并执行后续的指令
将表达式的结果赋给变量parentId
以子查询结果的第一个元素为例(子查询用圆括号括起来,但在这里它们也是一个函数调用)
对于Characters集合中的每个文档,将该文档分配给一个变量c
应用两个筛选条件:字符文档中的名称必须等于rel中的父名称,姓氏也必须等于关系数据中的姓氏give
第一场比赛结束后停止比赛,以提高效率
返回字符文档的ID(子查询的结果是一个带有一个元素的数组,FIRST()接受这个元素并将其分配给parentId变量)
将表达式的结果分配给变量childId
子查询用于查找子字符文档,并以与父文档ID相同的方式返回ID(参见上面)
如果两个子查询中有一个或两个都无法找到匹配项,请跳过当前关系,因为创建一个匹配项需要边缘两端的两个id(这只是一种预防措施)
向ChildOf集合插入一个新的edge文档,该文档的edge从childId到parentId,没有其他属性
返回新的edge文档(可选)
Traverse to the parents
现在边链接字符文档(顶点),我们有一个图,我们可以查询谁是另一个字符的父节点——或者用图的术语来说,我们想要从一个顶点开始,然后沿着边遍历AQL图中的其他顶点:
FOR v IN 1..1 OUTBOUND "Characters/2901776" ChildOf
RETURN v.name这个FOR循环不遍历一个集合或数组,它走图和遍历连接顶点它发现,与顶点文档分配给一个变量(:v)。它还可以发出边缘走以及完整路径从开始到结束到另一个两个变量。
在上面的查询中,遍历被限制为最小和最大遍历深度为1(从起始顶点开始需要多少步),并且只沿着出站方向的边进行遍历。我们的边从子结点指向父结点,父结点离子结点只有一步之遥,因此它给出了起始点的父结点。“字符/2901776”是起始点。请注意,您的文档ID会有所不同,所以请将其调整为您的文档ID,例如Bran Stark文档:
FOR c IN Characters
FILTER c.name == "Bran"
RETURN c._id
[ "Characters/" ]
你也可以直接把这个查询和遍历结合起来,通过调整过滤条件来改变起始点:
FOR c IN Characters
FILTER c.name == "Bran"
FOR v IN 1..1 OUTBOUND c ChildOf
RETURN v.name
起始点后面跟着ChildOf,这是我们的边集合。示例查询只返回每个父类的名称,以保持结果简短:
[
"Ned",
"Catelyn"
]
以同样的结果作为起点的还有 Robb, Arya and Sansa. 对Jon Snow来说, 只有 Ned.
Traverse to the children
我们也可以从父节点沿反向边缘方向(入站)走到子节点:
FOR c IN Characters
FILTER c.name == "Ned"
FOR v IN 1..1 INBOUND c ChildOf
RETURN v.name
[
"Robb",
"Sansa",
"Jon",
"Arya",
"Bran"
]
Traverse to the grandchildren
对于兰尼斯特家来说,我们的关系从父母一直延续到孙辈。让我们更改遍历深度以返回子元素,这意味着只执行两个步骤
FOR c IN Characters
FILTER c.name == "Tywin"
FOR v IN 2..2 INBOUND c ChildOf
RETURN v.name
[
"Joffrey",
"Joffrey"
]Joffrey 回来了两次,这可能有点出乎意料。然而,如果你看一下图形可视化,你会发现从Joffrey (右下角)到Tywin有多条路径:
Tywin <- Jaime <- Joffrey
Tywin <- Cersei <- Joffrey
作为一个快速修复,将查询的最后一行更改为返回不同的v.name,只返回每个值一次。但是请记住,有一些遍历选项可以在早期抑制重复的顶点。
Traverse with variable depth
为了返回Joffrey的父母和祖父母,我们可以沿出站方向走边,调整遍历深度至少走1步,最多走2步:
FOR c IN Characters
FILTER c.name == "Joffrey"
FOR v IN 1..2 OUTBOUND c ChildOf
RETURN DISTINCT v.name
[
"Cersei",
"Tywin",
"Jaime"
]
如果我们有更深的族谱,那么只需要改变查询曾孙和类似关系的深度值。
Geospatial queries
由经纬度值组成的地理空间坐标可以存储为两个单独的属性,也可以存储为具有两个数值的数组形式的单个属性。ArangoDB可以为快速地理空间查询索引这样的坐标。
Locations data
让我们插入一些拍摄地点到一个新的集合地点,你需要先创建,然后运行以下AQL查询:
LET places =
[
{
"name":
"Dragonstone",
"coordinate":
[
55.167801,
-6.815096
]
},
{
"name":
"King's Landing",
"coordinate":
[
42.639752,
18.110189
]
},
{
"name":
"The Red Keep",
"coordinate":
[
35.896447,
14.446442
]
},
{
"name":
"Yunkai",
"coordinate":
[
31.046642,
-7.129532
]
},
{
"name":
"Astapor",
"coordinate":
[
31.50974,
-9.774249
]
},
{
"name":
"Winterfell",
"coordinate":
[
54.368321,
-5.581312
]
},
{
"name":
"Vaes Dothrak",
"coordinate":
[
54.16776,
-6.096125
]
},
{
"name":
"Beyond the wall",
"coordinate":
[
64.265473,
-21.094093
]
}
]
FOR place IN places
INSERT place INTO Locations
地图上坐标的可视化及其标签:
Geospatial index
要基于坐标进行查询,需要一个地理索引。它确定哪些字段包含纬度和经度值。
- 去集合
- 单击Locations集合
- 切换到顶部的Indexes选项卡
- 单击右边带有加号的绿色按钮
- 将类型更改为Geo Index
- 在Fields字段中输入coordinate
- 单击Create确认
Find nearby locations
再次使用FOR循环,但这一次是遍历对NEAR()函数调用的结果,以找到与参考点最近的n个坐标,并返回具有附近位置的文档。n的缺省值是100,这意味着最多返回100个文档,最接近的匹配先返回。
在下面的例子中,限制被设置为3。原点(参考点)是爱尔兰都柏林市中心某处的坐标:
FOR loc IN WITHIN(Locations,53.35, -6.26, 200*1000)
RETURN
{ name: loc.name,
latitude:loc.coordinate[0],
longitude: loc.coordinate[1]
}
[
{
"name": "Vaes Dothrak",
"latitude": 54.16776,
"longitude": -6.096125
},
{
"name": "Winterfell",
"latitude": 54.368321,
"longitude": -5.581312
}
]查询返回位置名称和坐标。坐标作为两个单独的属性返回。如果需要,可以使用更简单的返回loc。
Find locations within radius
NEAR()可以替换为WITHIN(),以便从参考点搜索给定半径内的位置。语法是一样的
至于NEAR(),除了第四个参数,它指定半径而不是限制。半径的单位是米。的
示例使用半径为200,000米(200公里):
FOR loc IN WITHIN(Locations,53.35,-6.26,200*1000)
RETURN{name:loc.name,latitude:loc.coordinate[0],longitude:loc.coordinate[1]}
[
{
"name": "Vaes Dothrak",
"latitude": 54.16776,
"longitude": -6.096125
},
{
"name": "Winterfell",
"latitude": 54.368321,
"longitude": -5.581312
}
]Return the distance
NEAR()和WITHIN()都可以通过添加第五个可选参数返回到参考点的距离。它必须是一个字符串,该字符串将用作一个附加属性的属性名,该属性的距离以米为单位
FOR loc IN NEAR(Locations,53.35,-6.26,3,"distance")
RETURN{
name:loc.name,
latitude:loc.coordinate[0],
longitude:loc.coordinate[1],
distance:loc.distance/1000
}
[
{
"name": "Vaes Dothrak",
"latitude": 54.16776,
"longitude": -6.096125,
"distance": 91.56658640314431
},
{
"name": "Winterfell",
"latitude": 54.368321,
"longitude": -5.581312,
"distance": 121.66399816395028
},
{
"name": "Dragonstone",
"latitude": 55.167801,
"longitude": -6.815096,
"distance": 205.31879386198324
}
]
这里称为distance的额外属性作为loc变量的一部分返回,就像它是location文档的一部分一样。这个值是
在示例查询中除以1000,将单位转换为公里,只是为了更好地可读性。