KMeans聚类算法示例
三个例子:1.二位点聚类 2.手写字符聚类 3.图像压缩
Clustering: K-Means In-Depth
Here we’ll explore K Means Clustering, which is an unsupervised clustering technique.
We’ll start with our standard set of initial imports
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy import statsIntroducing K-Means
K Means is an algorithm for unsupervised clustering: that is, finding clusters in data based on the data attributes alone (not the labels).
K Means is a relatively easy-to-understand algorithm. It searches for cluster centers which are the mean of the points within them, such that every point is closest to the cluster center it is assigned to.
Let’s look at how KMeans operates on the simple clusters we looked at previously. To emphasize that this is unsupervised, we’ll not plot the colors of the clusters:
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=300, centers=4,
random_state=0, cluster_std=0.60)
plt.scatter(X[:, 0], X[:, 1], s=50);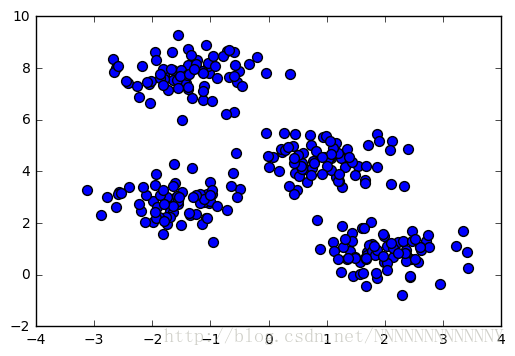
By eye, it is relatively easy to pick out the four clusters. If you were to perform an exhaustive search for the different segmentations of the data, however, the search space would be exponential in the number of points. Fortunately, there is a well-known Expectation Maximization (EM) procedure which scikit-learn implements, so that KMeans can be solved relatively quickly.
from sklearn.cluster import KMeans
est = KMeans(4) # 4 clusters
est.fit(X)
y_kmeans = est.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='rainbow');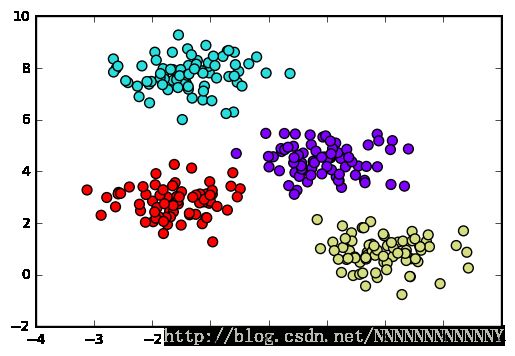
The algorithm identifies the four clusters of points in a manner very similar to what we would do by eye!
The K-Means Algorithm: Expectation Maximization
K-Means is an example of an algorithm which uses an Expectation-Maximization approach to arrive at the solution.
Expectation-Maximization is a two-step approach which works as follows:
- Guess some cluster centers
- Repeat until converged
A. Assign points to the nearest cluster center
B. Set the cluster centers to the mean
Let’s quickly visualize this process:
from fig_code import plot_kmeans_interactive
plot_kmeans_interactive();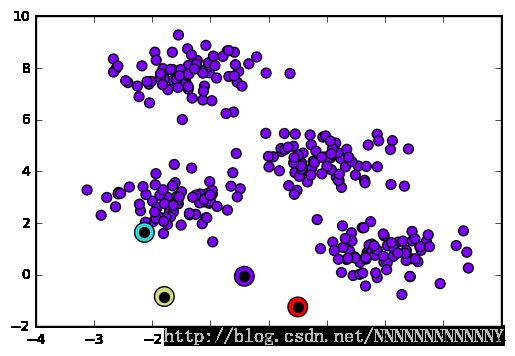
This algorithm will (often) converge to the optimal cluster centers.
KMeans Caveats
The convergence of this algorithm is not guaranteed; for that reason, scikit-learn by default uses a large number of random initializations and finds the best results.
Also, the number of clusters must be set beforehand… there are other clustering algorithms for which this requirement may be lifted.
Application of KMeans to Digits
For a closer-to-real-world example, let’s again take a look at the digits data. Here we’ll use KMeans to automatically cluster the data in 64 dimensions, and then look at the cluster centers to see what the algorithm has found.
from sklearn.datasets import load_digits
digits = load_digits()est = KMeans(n_clusters=10)
clusters = est.fit_predict(digits.data)
est.cluster_centers_.shape(10, 64)
We see ten clusters in 64 dimensions. Let’s visualize each of these cluster centers to see what they represent:
fig = plt.figure(figsize=(8, 3))
for i in range(10):
ax = fig.add_subplot(2, 5, 1 + i, xticks=[], yticks=[])
ax.imshow(est.cluster_centers_[i].reshape((8, 8)), cmap=plt.cm.binary)
We see that even without the labels, KMeans is able to find clusters whose means are recognizable digits (with apologies to the number 8)!
Example: KMeans for Color Compression
One interesting application of clustering is in color image compression. For example, imagine you have an image with millions of colors. In most images, a large number of the colors will be unused, and conversely a large number of pixels will have similar or identical colors.
Scikit-learn has a number of images that you can play with, accessed through the datasets module. For example:
from sklearn.datasets import load_sample_image
china = load_sample_image("china.jpg")
plt.imshow(china)
plt.grid(False);
The image itself is stored in a 3-dimensional array, of size (height, width, RGB):
china.shape(427, 640, 3)
We can envision this image as a cloud of points in a 3-dimensional color space. We’ll rescale the colors so they lie between 0 and 1, then reshape the array to be a typical scikit-learn input:
X = (china / 255.0).reshape(-1, 3)
print(X.shape)(273280, 3)
We now have 273,280 points in 3 dimensions.
Our task is to use KMeans to compress the 2563 colors into a smaller number (say, 64 colors). Basically, we want to find Ncolor clusters in the data, and create a new image where the true input color is replaced by the color of the closest cluster.
# reduce the size of the image for speed
image = china[::3, ::3]
print(image.shape)
n_colors = 64
X = (image / 255.0).reshape(-1, 3)
model = KMeans(n_colors)
labels = model.fit_predict(X)
colors = model.cluster_centers_
new_image = colors[labels].reshape(image.shape)
new_image = (255 * new_image).astype(np.uint8)
plt.figure()
plt.imshow(image)
plt.title('input')
plt.figure()
plt.imshow(new_image)
plt.title('{0} colors'.format(n_colors))(143, 214, 3)


Compare the input and output image: we’ve reduced the 2563 colors to just 64.