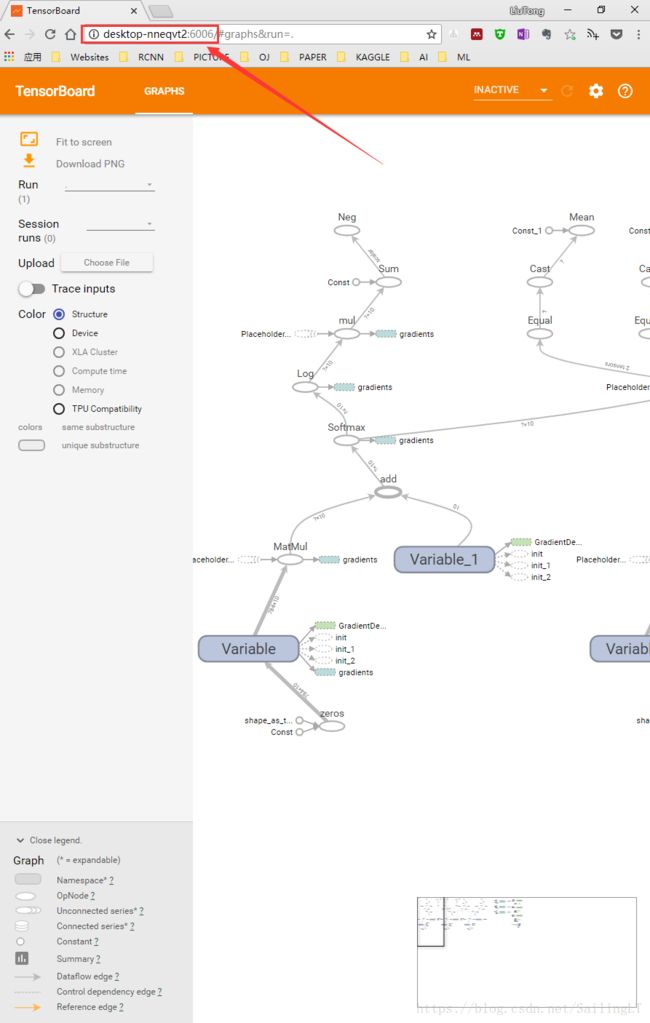
win10下使用Tensorboard
1、下载minist数据集到本地
下载地址:http://yann.lecun.com/exdb/mnist/

下载后保存,我的保存地址是 C:\Users\LT\testdata
2、建立input_data.py文件
# -*- coding: utf-8 -*-
"""Functions for downloading and reading MNIST data."""
#2017-10-08将文件下载改写为本地读取
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tensorflow.python.platform
import numpy
import urllib
#from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
#本地minst数据地址
localpath =r'C:\Users\LT\testdata'
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
#该方法在此案例不使用,保留
def maybe_download(filename, work_directory):
"""Download the data from Yann's website, unless it's already here."""
if not os.path.exists(work_directory):
os.mkdir(work_directory)
filepath = os.path.join(work_directory, filename)
if not os.path.exists(filepath):
filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath)
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
return filepath
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)[0]
def extract_images(filename):
"""Extract the images into a 4D uint8 numpy array [index, y, x, depth]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2051:
raise ValueError(
'Invalid magic number %d in MNIST image file: %s' %
(magic, filename))
num_images = _read32(bytestream)
rows = _read32(bytestream)
cols = _read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8)
data = data.reshape(num_images, rows, cols, 1)
return data
def dense_to_one_hot(labels_dense, num_classes=10):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
def extract_labels(filename, one_hot=False):
"""Extract the labels into a 1D uint8 numpy array [index]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2049:
raise ValueError(
'Invalid magic number %d in MNIST label file: %s' %
(magic, filename))
num_items = _read32(bytestream)
buf = bytestream.read(num_items)
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
return dense_to_one_hot(labels)
return labels
class DataSet(object):
def __init__(self, images, labels, fake_data=False, one_hot=False,
dtype=tf.float32):
"""Construct a DataSet.
one_hot arg is used only if fake_data is true. `dtype` can be either
`uint8` to leave the input as `[0, 255]`, or `float32` to rescale into
`[0, 1]`.
"""
dtype = tf.as_dtype(dtype).base_dtype
if dtype not in (tf.uint8, tf.float32):
raise TypeError('Invalid image dtype %r, expected uint8 or float32' %
dtype)
if fake_data:
self._num_examples = 10000
self.one_hot = one_hot
else:
assert images.shape[0] == labels.shape[0], (
'images.shape: %s labels.shape: %s' % (images.shape,
labels.shape))
self._num_examples = images.shape[0]
# Convert shape from [num examples, rows, columns, depth]
# to [num examples, rows*columns] (assuming depth == 1)
assert images.shape[3] == 1
images = images.reshape(images.shape[0],
images.shape[1] * images.shape[2])
if dtype == tf.float32:
# Convert from [0, 255] -> [0.0, 1.0].
images = images.astype(numpy.float32)
images = numpy.multiply(images, 1.0 / 255.0)
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def next_batch(self, batch_size, fake_data=False):
"""Return the next `batch_size` examples from this data set."""
if fake_data:
fake_image = [1] * 784
if self.one_hot:
fake_label = [1] + [0] * 9
else:
fake_label = 0
return [fake_image for _ in range(batch_size)], [
fake_label for _ in range(batch_size)]
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Shuffle the data
perm = numpy.arange(self._num_examples)
numpy.random.shuffle(perm)
self._images = self._images[perm]
self._labels = self._labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def read_data_sets(train_dir, fake_data=False, one_hot=False, dtype=tf.float32):
class DataSets(object):
pass
data_sets = DataSets()
if fake_data:
def fake():
return DataSet([], [], fake_data=True, one_hot=one_hot, dtype=dtype)
data_sets.train = fake()
data_sets.validation = fake()
data_sets.test = fake()
return data_sets
TRAIN_IMAGES = '\\train-images-idx3-ubyte.gz'
TRAIN_LABELS = '\\train-labels-idx1-ubyte.gz'
TEST_IMAGES = '\\t10k-images-idx3-ubyte.gz'
TEST_LABELS = '\\t10k-labels-idx1-ubyte.gz'
VALIDATION_SIZE = 5000
#改为读取本地文件,不再调用Maybe_download文件
#local_file = maybe_download(TRAIN_IMAGES, train_dir)
local_file = localpath+TRAIN_IMAGES
train_images = extract_images(local_file)
#local_file = maybe_download(TRAIN_LABELS, train_dir)
local_file = localpath+TRAIN_LABELS
train_labels = extract_labels(local_file, one_hot=one_hot)
#local_file = maybe_download(TEST_IMAGES, train_dir)
local_file = localpath+TEST_IMAGES
test_images = extract_images(local_file)
#local_file = maybe_download(TEST_LABELS, train_dir)
local_file = localpath+TEST_LABELS
test_labels = extract_labels(local_file, one_hot=one_hot)
validation_images = train_images[:VALIDATION_SIZE]
validation_labels = train_labels[:VALIDATION_SIZE]
train_images = train_images[VALIDATION_SIZE:]
train_labels = train_labels[VALIDATION_SIZE:]
data_sets.train = DataSet(train_images, train_labels, dtype=dtype)
data_sets.validation = DataSet(validation_images, validation_labels,dtype=dtype)
data_sets.test = DataSet(test_images, test_labels, dtype=dtype)
return data_sets3、建立test_mnist.py文件
# -*- coding: utf-8 -*-
import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# soft回归模型
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x,W) + b)
# 训练模型
y_ = tf.placeholder("float", [None,10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# 评估模型
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
# 生成日志文件log_1,用tensorboard查看
writer = tf.summary.FileWriter("log_1",tf.get_default_graph())
writer.close()4、运行程序文件test_mnist.py
运行程序之后,在该文件所在目录下会生成一个日志文件夹log_1
5、找到tensorboard.exe所在文件夹
6、打开Windows PowerShell,切换路径到tensorboard.exe的所在文件夹(Scripts),将logdir后面的路径换成上述步骤4中日志文件所在的路径

7、在浏览器中复制输入上述步骤6中的地址