《HBase原理与实践》阅读笔记
学习笔记(1-3章)
- 全书概述
- 1.HBase概述
- 1.1.Hbase发展历史
- 1.2.Hbase数据模型
- 1.3.Hbase体系结构
- 1.4.Hbase系统特性
- 2.Hbase基础数据结构与算法
- 2.1.LSM树
- 2.1.1.KeyValue存储格式
- 2.2.跳跃表
- 2.3.布隆过滤器
- 3.Hbase依赖服务
- 3.1.Zookeeper相关
- 3.2.HDFS相关
本博客内容基本整理自《Hbase原理与实践》一书。仅用于个人学习和积累。
全书概述
《HBase原理与实践》共有16章,根据文章内容可以分为如下6个部分。
-
1.HBase基础部分: 包含第1、2章。其中,第1章主要介绍HBase系统的发展历史、数据模型以及体系结构,第2章主要介绍HBase系统中常用的数据结构以及基础算法。
-
2.HBase系统相关组件: 包含第3、4、5章。其中,第3章重点介绍HBase所依赖的核心组件,包括ZooKeeper、HDFS等,第4章介绍HBase客户端组件实现,第5章介绍RegionServer内部组件的实现。
-
3.HBase核心工作原理: 包含第6、7、8、9、10、11章。其中,第6章详细分析HBase读写流程,第7章介绍HBase Compaction的实现原理,第8章介绍HBase中Region的迁移、合并以及分裂等操作是如何实现的,第9章介绍RegionServer宕机后如何通过HLog进行数据恢复,第10章介绍HBase不同集群之间的复制是如何实现的,第11章介绍HBase如何通过Snapshot机制完成数据的备份和恢复。
-
4.HBase运维调优实践: 包含第12、13、14章。其中,第12章介绍HBase集群常用的运维管理操作,包括集群如何有效监控,基准性能如何测试等,第13章集中介绍HBase集群的常用调优技巧,第14章重点分析几个HBase实际运维案例,通过案例分析介绍HBase集群定位和处理问题的技巧。
-
5.HBase 2.x核心特性(第15章): 介绍HBase最新2.x版本的核心功能与特性。
-
6.HBase高级话题(第16章): 介绍社区中比较热门的二级索引话题,以及HBase内核的开发与测试。
1.HBase概述
1.1.Hbase发展历史
Hbase作为大数据中至关重要的一个组件,和其他很多组件一样,起源于Google当年风靡一时的“三篇论文”—GFS、MapReduce、BigTable。一家叫做Powerset的公司,为了高效处理自然语言搜索产生的海量数据实现了BigTable的开源版本—HBase,并在发展了2年之后被Apache收录为顶级项目,正式入驻Hadoop生态系统。
Hbase版本变迁:
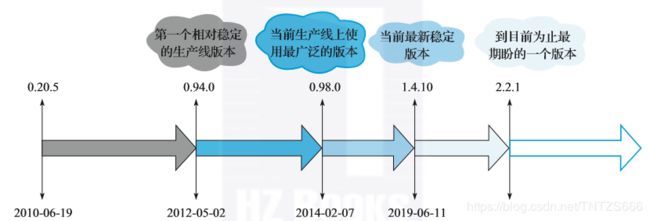
注:2.x版本是接下来最受期待的一个版本(升级要慎重,请参考社区中的实践),因为最近一两年社区开发的新功能都将集中在2.x版本发布,2.x包含的核心功能特别多,包括:大幅度减小GC影响的offheap read path/write path工作,极大提升系统稳定性的Procedure V2框架,支持多租户隔离的RegionServer Group功能,支持大对象存储的MOB功能等。
1.2.Hbase数据模型
- 从使用角度来看,HBase包含了大量关系型数据库的基本概念—表、行、列。
- 从逻辑视图来看,HBase中的数据是以表形式进行组织的,而且和关系型数据库中的表一样,HBase中的表也由行和列构成,因此HBase非常容易理解。
- 从物理视图来看,HBase是一个Map,由键值(KeyValue,KV)构成,不过与普通的Map不同,HBase是一个稀疏的、分布式的、多维排序的Map——“sparse, distributed, persistent multidimensional sorted map”。HBase中Map的key是一个复合键,由rowkey、column family、qualifier、type以及timestamp组成,value即为cell的值。
1.3.Hbase体系结构
HBase体系结构是典型的Master-Slave模型。

RegionServer主要用来响应用户的IO请求,是HBase中最核心的模块,由WAL(HLog)、BlockCache以及多个Region构成。
- WAL(HLog):HLog在HBase中有两个核心作用—其一,用于实现数据的高可靠性,HBase数据随机写入时,并非直接写入HFile数据文件,而是先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,数据写入缓存之前需要首先顺序写入HLog,这样,即使缓存数据丢失,仍然可以通过HLog日志恢复;其二,用于实现HBase集群间主从复制,通过回放主集群推送过来的HLog日志实现主从复制。
- BlockCache:HBase系统中的读缓存。客户端从磁盘读取数据之后通常会将数据缓存到系统内存中,后续访问同一行数据可以直接从内存中获取而不需要访问磁盘。对于带有大量热点读的业务请求来说,缓存机制会带来极大的性能提升。
- BlockCache缓存对象是一系列Block块,一个Block默认为64K,由物理上相邻的多个KV数据组成。BlockCache同时利用了空间局部性和时间局部性原理,前者表示最近将读取的KV数据很可能与当前读取到的KV数据在地址上是邻近的,缓存单位是Block(块)而不是单个KV就可以实现空间局部性;后者表示一个KV数据正在被访问,那么近期它还可能再次被访问。当前BlockCache主要有两种实现—LRUBlockCache和BucketCache,前者实现相对简单,而后者在GC优化方面有明显的提升。
- Region:数据表的一个分片,当数据表大小超过一定阈值就会“水平切分”,分裂为两个Region。Region是集群负载均衡的基本单位。通常一张表的Region会分布在整个集群的多台RegionServer上,一个RegionServer上会管理多个Region,当然,这些Region一般来自不同的数据表。
1.4.Hbase系统特性
与其他数据库相比,HBase在系统设计以及实际实践中有很多独特的优点如:容量巨大,良好的可扩展性,稀疏性,高性能,多版本,支持过期,Hadoop原生支持等。
HBase的缺点
- HBase本身不支持很复杂的聚合运算(如Join、GroupBy等)。如果业务中需要使用聚合运算,可以在HBase之上架设Phoenix组件或者Spark组件,前者主要应用于小规模聚合的OLTP场景,后者应用于大规模聚合的OLAP场景。
- HBase本身并没有实现二级索引功能,所以不支持二级索引查找。好在针对HBase实现的第三方二级索引方案非常丰富,比如目前比较普遍的使用Phoenix提供的二级索引功能。
- HBase原生不支持全局跨行事务,只支持单行事务模型。同样,可以使用Phoenix提供的全局事务模型组件来弥补HBase的这个缺陷。
2.Hbase基础数据结构与算法
Hbase的一个列簇(Column Family)本质上是一颗LSM树(Log-Structured Merge-Tree)。LSM树的索引一般分为两部分,为内存部分和磁盘部分。内存部分Hbase选择了跳跃表来维护一个有序的KeyValue集合,而磁盘部分采用了布隆过滤器。
2.1.LSM树
2.1.1.KeyValue存储格式
一般来说,LSM中存储的是多个KeyValue组成的集合,每个KeyValue一般都用一个字节数组来表示。Hbase中该字节数组主要分为以下几个字段,其中Rowkey、Family、Qualifier、Timestamp、Type这5个字段组成KeyValue中的key部分。其中type字段表示这个KeyValue操作的类型,HBase内有Put、Delete、Delete Column、Delete Family等等。注意,这是一个非常关键的字段,表明了LSM树内存储的不只是数据,而是每一次操作记录。 Value直接存储的是值的二进制内容。
2.2.跳跃表
跳跃表(SkipList)是一种能高效实现插入,删除,查找内容的数据结构,这些操作的期望复杂度都是O(logN)。
定义:
- 跳跃表由多条分层的链表组成。
- 每条链表中的元素都是有序的。
- 每条链表都有两个元素:+∞(正无穷大)和- ∞(负无穷大),分别表示链表的头部和尾部。
- 从上到下,上层链表元素集合是下层链表元素集合的子集,即S1是S0的子集,S2是S1的子集。
- 跳跃表的高度定义为水平链表的层数。
2.3.布隆过滤器
布隆过滤器由一个长度为N的01数组组成。布隆过滤器串对任意给定元素w,经过哈希运算后可以给出的存在性结果为两种:
- w可能存在于集合A中。
- w肯定不在集合A中。
详细解释见原文或者点击此处。
3.Hbase依赖服务
3.1.Zookeeper相关
在安装HBase集群时需要在配置文件conf/hbase-site.xml中配置与ZooKeeper相关的几个重要配置项,如下所示:
hbase.zookeeper.quorum
localhost
hbase.zookeeper.property.clientPort
2181
zookeeper.znode.parent
/hbase
其中,hbase.zookeeper.quorum为ZooKeeper集群的地址,必须进行配置,该项默认为localhost。hbase.zookeeper.property.clientPort默认为2181,可以不进行配置。zookeeper. znode.parent默认为/hbase,可以不配置。HBase集群启动之后,使用客户端进行读写操作时也需要配置上述ZooKeeper相关参数。
HBase在ZooKeeper根节点下创建的主要子节点:
[zk: localhost:2181(CONNECTED) 2] ls /hbase
[meta-region-server, backup-masters, table, region-in-transition, table-lock,master, balancer, namespace, hbaseid, online-snapshot, replication, splitWAL,recovering-regions, rs]
其中:replication用来实现HBase复制功能。 splitWAL/recovering-regions:用来实现HBase分布式故障恢复。
3.2.HDFS相关
一般情况下,一个线上的高可用HDFS集群主要由4个重要的服务组成:NameNode、DataNode、JournalNode、ZkFailoverController。
其中NameNode采用写EditLog和FsImage的方式来保证元数据的高效持久化,JournalNode其实是用来维护EditLog一致性的Paxos组。
HBase使用HDFS存储所有数据文件,从HDFS的视角看,HBase就是它的客户端。
Hbase在HDFS上的文件布局
通过HDFS的客户端列出HBase集群的文件如下:
hadoop@hbase37:~/hadoop-current/bin$ ./hdfs dfs -ls /hbase
Found 10 items
drwxr-xr-x - hadoop hadoop 2018-05-07 10:42 /hbase-nptest/.hbase-snapshot
drwxr-xr-x - hadoop hadoop 2018-04-27 14:04 /hbase-nptest/.tmp
drwxr-xr-x - hadoop hadoop 2018-07-06 21:07 /hbase-nptest/MasterProcWALs
drwxr-xr-x - hadoop hadoop 2018-06-25 17:14 /hbase-nptest/WALs
drwxr-xr-x - hadoop hadoop 2018-05-07 10:43 /hbase-nptest/archive
drwxr-xr-x - hadoop hadoop 2017-10-10 20:24 /hbase-nptest/corrupt
drwxr-xr-x - hadoop hadoop 2018-05-31 12:02 /hbase-nptest/data
-rw-r--r-- 3 hadoop hadoop 2017-09-29 17:30 /hbase-nptest/hbase.id
-rw-r--r-- 3 hadoop hadoop 2017-09-29 17:30 /hbase-nptest/hbase.version
drwxr-xr-x - hadoop hadoop 2018-07-06 21:22 /hbase-nptest/oldWALs
其中:.tmp:临时文件目录,主要用于Hbase表创建删除操作。.WALs:存储集群中所有RegionServer的HLog日志文件。.archive:文件归档目录。这个目录主要会在以下几个场景下使用。
- 所有对HFile文件的删除操作都会将待删除文件临时放在该目录。
- 进行Snapshot或者升级时使用到的归档目录。
- Compaction删除HFile的时候,也会把旧的HFile移动到这里。
注:不同版本的Hbase在HDFS上文件名有差异,并不是相同的。