ubuntu18.04利用docker安装NVIDIA驱动、cuda、cudnn、tensorflow、torch等深度学习环境
目录
前言
一、Docker安装
备份sources.list并新建
阿里源镜像填入(最近清华源好像有问题)
更新源使之生效
二、NVIDIA GPU 驱动安装
驱动安装
检查安装结果
三、Docker安装
docker安装
检查安装结果
为避免docker操作必须要sudo,将当前用户加入docker用户组(${YOUR_NAME_HERE}处填当前用户名)
四、Nvidia-docker安装
安装
检查安装结果
五、Docker基本使用
Docker启动
Dokcer关闭
Docker仓库国内源修改,以加速镜像获取
拉取镜像
查看镜像
运行镜像,即生成新容器
查看容器
六、Docker守护进程修改
七、深度学习框架生成
Dockerfile编写
镜像起名
运行生成容器
八、镜像修改
九、pycharm配置
十、命令行执行
十一、额外福利
首先去官网下载cuDNN
进入cuDNN目录后进行解压
进入解压后的文件夹下的include目录
进入lib64目录下,对动态文件进行复制和软链接
前言
docker一词的原意为“码头的装卸工”,其开发的目的是为解决广大程序员在开发、测试、部署维护等不同场景不可避免的场景不同问题,即提供抽象的“镜像、容器“等概念,为windows、linux、macos等不同操作系统运行环境提供一站式解决方案。
镜像image是静态文件,容器container是动态运行,同一个镜像的不同运行可以产生多个不同容器。
一个简介但精炼的docker学习教程。
但docker比正常环境更吃配置,建议不同时使用的深度学习框架尽量分成不同的镜像制作、安装部署、使用,否则内存爆炸。
一、Docker安装
参考博客
备份sources.list并新建
sudo mv /etc/apt/sources.list /etc/apt/sources.list.old
sudo vim /etc/apt/sources.list阿里源镜像填入(最近清华源好像有问题)
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse更新源使之生效
sudo apt-get update二、NVIDIA GPU 驱动安装
驱动安装
sudo ubuntu-drivers autoinstall检查安装结果
watch nvidia-smi三、Docker安装
docker安装
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install docker-ce检查安装结果
docker -v为避免docker操作必须要sudo,将当前用户加入docker用户组(${YOUR_NAME_HERE}处填当前用户名)
sudo usermod -aG docker ${YOUR_NAME_HERE}四、Nvidia-docker安装
安装
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd上述最后一步会重启docker,并载入nvidia-docker的配置
检查安装结果
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi五、Docker基本使用
Docker启动
sudo service docker start或
sudo systemctl start dockerDokcer关闭
sudo service docker stop或
sudo systemctl stop dockerDocker仓库国内源修改,以加速镜像获取
打开/etc/default/docker文件(需要sudo权限),在文件的底部加上一行。
DOCKER_OPTS="--registry-mirror=https://registry.docker-cn.com"然后,重启 Docker 服务。
sudo service docker restart拉取镜像
docker image pull [仓库名]/[镜像名][:版本号](版本号可选,默认为最新)
docker image pull library/hello-world查看镜像
docker image ls运行镜像,即生成新容器
docker container run --runtime=nvidia -it --rm -p 8000:3000 dockername /bin/bash其中
--runtime=nvidia 表示选择NVIDIA驱动作为运行时环境
-it 交互式运行 与之对应的是-d代表后台运行
–rm 代表退出容器后就删除容器
-p 8000:3000 容器端口与本地端口映射,前为本地端口,后为容器端口。这里的例子是将容器的3000端口映射到 8000端口
tf-gpu 为之前创立的镜像名称
/bin/bash 代表进入容器后选择bash的方式
另外
-d 后台运行容器,并返回容器ID
--name 给容器命名,没有这个参数会随机生成一个名字
查看容器
docker container ls六、Docker守护进程修改
参考博客
问题:Cannot connect to the Docker daemon at tcp://localhost:4243. Is the docker daemon running?
修改配置文件/etc/systemd/system/multi-user.target.wants/docker.service为:
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:4243 -H unix:///var/run/docker.sock
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always即修改ExecStart改成上述值,即为docker指定启动的本地端口。
然后,systemctl daemon-reload/ systemctl restart docker.service /
分别运行上述命令进行docker重启,重启成功!
七、深度学习框架生成
参考博客
Dockerfile编写
FROM nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04
MAINTAINER zjhao666
# install basic dependencies
RUN apt-get update
RUN apt-get install -y wget \
vim \
cmake
# install Anaconda3
RUN wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.2.0-Linux-x86_64.sh -O ~/anaconda3.sh
RUN bash ~/anaconda3.sh -b -p /home/anaconda3 \
&& rm ~/anaconda3.sh
ENV PATH /home/anaconda3/bin:$PATH
# change mirror
RUN mkdir ~/.pip \
&& cd ~/.pip
RUN echo -e "[global]\nindex-url = https://pypi.mirrors.ustc.edu.cn/simple/" >> ~/pip.conf
RUN /home/anaconda3/bin/pip install --upgrade pip
RUN /home/anaconda3/bin/pip install numpy==1.16.0
RUN /home/anaconda3/bin/pip install matplotlib
RUN /home/anaconda3/bin/pip install scipy
RUN /home/anaconda3/bin/pip install sklearn
RUN /home/anaconda3/bin/pip install echarts
RUN /home/anaconda3/bin/pip install tensorflow-gpu==1.9.0
RUN /home/anaconda3/bin/pip install torch===1.2.0 torchvision===0.4.0 -f https://download.pytorch.org/whl/torch_stable.html
末尾即为众框架。
根据之前的建议,torch\tensorflow这种大框架,一个镜像最好只有一个。
镜像起名
docker build -t my_image .
-t 后面跟镜像的名字
运行生成容器
docker run --runtime=nvidia -it --rm my_image /bin/bash八、镜像修改
1、先使用下载的镜像启动容器。
| 1 2 |
|
注意:记住容器的 ID,稍后还会用到。
2、在容器中添加 json 和 gem 两个应用。
| 1 |
|
当结束后,我们使用 exit 来退出,现在我们的容器已经被我们改变了,使用 docker commit 命令来提交更新后的副本。
| 1 2 |
|
其中,-m 来指定提交的说明信息,跟我们使用的版本控制工具一样;-a 可以指定更新的用户信息;之后是用来创建镜像的容器的 ID;最后指定目标镜像的仓库名和 tag 信息。创建成功后会返回这个镜像的 ID 信息。
使用 docker images 来查看新创建的镜像。
| 1 2 3 4 5 |
|
之后,可以使用新的镜像来启动容器
| 1 2 |
|
九、pycharm配置
file,settings,build-execution-deployment,docker,如图,配置URL为tcp://localhost:4243即可。
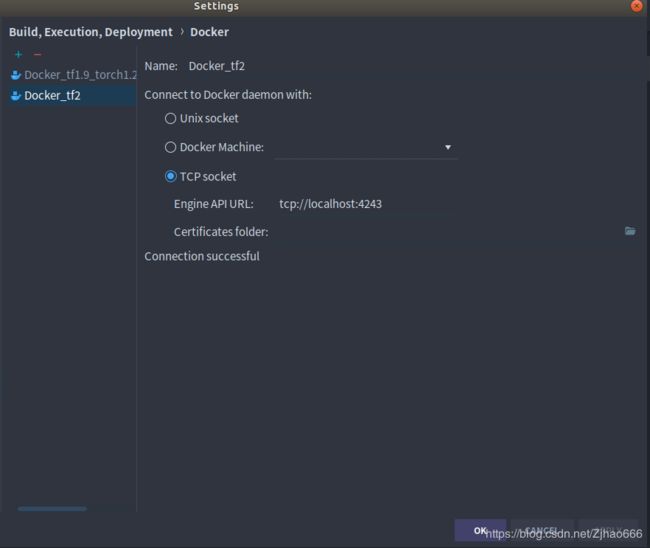
随后,在file,settings,project,interprter,选择reset下的三个点,选add,docker,如下

image name对应正确的docker镜像名+版本号,点击ok,可见已加载tensorflow2gpu版的docker镜像成功。

找一段测试tensorflow2gpu的代码,放进test.py里。代码如下:
import tensorflow as tf
import timeit
print(tf.test.is_gpu_available())
with tf.device('/cpu:0'):
cpu_a = tf.random.normal([10000, 1000])
cpu_b = tf.random.normal([1000, 2000])
print(cpu_a.device, cpu_b.device)
with tf.device('/gpu:0'):
gpu_a = tf.random.normal([10000, 1000])
gpu_b = tf.random.normal([1000, 2000])
print(gpu_a.device, gpu_b.device)
def cpu_run():
with tf.device('/cpu:0'):
c = tf.matmul(cpu_a, cpu_b)
return c
def gpu_run():
with tf.device('/gpu:0'):
c = tf.matmul(gpu_a, gpu_b)
return c
# warm up
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('warmup:', cpu_time, gpu_time)
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('run time:', cpu_time, gpu_time)
特别的,ubuntu机器上的pycharm设置运行无法输出,要右键python文件,点run 'test'才行。
后面要改,也可以继续照常修改设置。
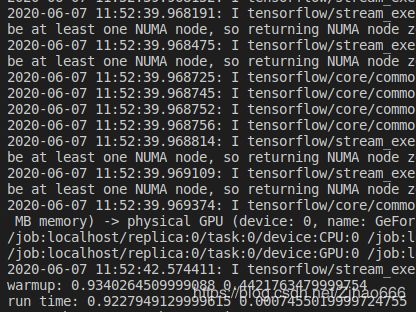
运行结果如图:

可见,无论是bool判断,还是运行时间,均证明tensorflow2gpu的docker版环境已经成功部署。
十、命令行执行
在不使用pycharm的情况下,可以将文件目录挂载到docker环境中执行。例如,
docker run -v /home/zjhao/Desktop/pycharm_test:/home -it --rm tensorflow/tensorflow:2.0.0-gpu-py3 /bin/bash这样,就把本机的/home/zjhao/Desktop/pycharm_test目录故在到了冒号之后的/home目录下。原始目录下有上文提到的测试tensorflow是否安装成功的代码。正常命令行执行即可。
root@95b391468605:/# cd /home/
root@95b391468605:/home# ls
test.py
root@95b391468605:/home# python test.py结果依然符合要求。
然后ctrl d退出即可。
此外,特别提醒,-v可重复使用,即可以一次运行时挂载多个本地文件目录到docker容器中——从而有效解决非父子目录的不同路径下,本地执行文件对数据文件、及本地执行文件之间的文件依赖报错,即依赖文件不存在的问题。
十一、额外福利
使用正常框架安装tensorflow gpu版时,可能会出现ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory这类错误,可在每次开机后,第一次运行前使用如下命令解决:
sudo ldconfig /usr/local/cuda-9.0/lib64当然,这是cudnn正常安装的解决方案。cudnn的正常安装步骤如下:
首先去官网下载cuDNN
cuDNN官网 https://developer.nvidia.com/rdp/cudnn-download,需要注册一个账号才能下载(免费的)。下载cuDNN时也一定要注意与CUDA版本的适配性。
cuDNN在持续更新中,只要对应(我们这里是CUDA9.0)就好了,因此不一定要最新的。如cudnn-9.0-linux-x64-v7.4.2.24.solitairetheme8,即7.4.2版本,不是最新的,但可用即可。
进入cuDNN目录后进行解压
sudo tar -xzvf cudnn-9.0-linux-x64-v7.4.2.24.solitairetheme8得到cuda文件夹
进入解压后的文件夹下的include目录
cd cuda/include
sudo cp cudnn.h /usr/local/cuda/include进入lib64目录下,对动态文件进行复制和软链接
cd ..
cd lib64
sudo cp lib* /usr/local/cuda/lib64/
cd /usr/local/cuda/lib64/
sudo rm -rf libcudnn.so libcudnn.so.7
sudo ln -s libcudnn.so.7.4.2 libcudnn.so.7
sudo ln -s libcudnn.so.7 libcudnn.so