机器学习(七)——规则化和模型选择
http://antkillerfarm.github.io/
H 为无限集的情况
某些预测函数的参数是实数,它实际上包含了无穷多个数。针对这样的情况,我们可以参照IEEE浮点数的规则,进行离散采样。
IEEE浮点数由64bit的二进制数构成,因此d个实数参数组成的 H ,可组成 k=264d 个不同的预测函数,因此:
这里的下标 γ,δ 表示一些依赖于它们的常量。从上式可以看出需要的训练样本的数量和预测模型的参数个数成线性关系。
以上就是和ERM相关的算法的理论知识,至于其他非ERM算法理论仍在研究之中。
下面是 H 参数化的问题。一个线性分类器可以写为:
这种形式有 n+1 个参数。
但它也可以写为:
这种形式有 2n+2 个参数。
显然这两种形式在数学上是等价的,但参数的个数却不同。为此我们引入Vapnik-Chervonenkis维度(简称VC维度),用以刻画参数的个数。

如上图所示,3个样本点有以上几种分布方式。毫无疑问,它们都能被 hθ(x)=1{θ0+θ1x1+θ2x2≥0} 所分割,且它们的训练误差为0。但如果是4个点的话,就不能无训练误差的分割了。我们将这种最大分割的个数称作VC维度,这里 VC(H)=3 。
需要注意的是,VC维度表征的是模型的最大切割能力,而不是针对所有的情况都成立。比如下图所示的三个点,就不可以被 hθ(x)=1{θ0+θ1x1+θ2x2≥0} 所分割,但这并不影响 hθ(x) 的VC维度值。
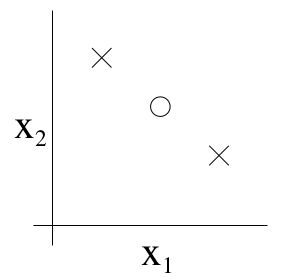
如果模型能切割任意大小的样本集,则 VC(H)=∞ 。
我们将VC维度值替换 H 为有限集时的 ∣H∣ ,可得以下相关结论:
令 VC(H)=d ,则:
以上公式的其他条件,与 H 为有限集时相同,这里不再赘述。
规则化和模型选择
对于多项回归模型
或者,我们是选择局部权重回归(locally weighted regression),还是SVM呢?
我们定义算法模型的集合为 M={M1,…,Md} 。其中的 Mi 为不同的算法模型,比如SVM、神经网络等等。
交叉验证
回想之前讨论的过拟合和ERM算法,如果我们针对多项回归模型使用ERM算法,几乎必然会选择高方差的高维多项回归模型,因为它的训练误差最小。但这显然不是个好选择。
因此,我们改进算法如下:
1.从全部的训练数据S中随机选择70%的样例作为训练集 Strain ,剩余的30%作为测试集 SCV 。
2.在 Strain 上训练每一个 Mi ,得到预测函数 hi 。
3.在 SCV 上测试每一个 hi ,得到相应的经验误差 ε^SCV(hi) 。
4.选择具有最小 ε^SCV(hi) 的 hi ,作为最佳模型。
这种方法被称为hold-out交叉验证(cross validation),或者称为简单(simple)交叉验证。
由于 Strain 和 SCV 是随机选取的,因此我们可以认为这里的经验误差 ε^SCV(hi) 是 hi 的泛化误差的一个很好的估计值。测试集一般占所有样本数的1/4~1/3,这里的30%是一个典型值。
还可以对模型作改进,当选出最佳的模型 Mi 后,再在全部数据S上做一次训练,显然训练数据越多,模型参数越准确。
简单交叉验证方法的缺点在于得到的最佳模型是在70%的训练数据上选出来的,不代表在全部训练数据上是最佳的。还有当训练数据本来就很少时,再分出测试集后,训练数据就太少了。
我们对简单交叉验证方法再做一次改进,如下:
1.将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作 {S1,…,Sk} 。
2.每次从模型集合 M 中拿出来一个 Mi ,然后在S中选择出k-1个子集 S1∪⋯∪Sj−1∪Sj+1∪⋯∪Sk ,在这个集合上训练 Mi 得到预测函数 hij 。在 Sj 上测试 hij ,得到相应的经验误差 ε^Sj(hij) 。
3.使用 1k∑kj=1ε^Sj(hij) 作为 Mi 泛化误差的估计值。
4.选出泛化误差估计值最小的 Mi ,在S上重新训练,得到最终的预测函数 hi 。
这个方法被称为k-折叠(k-fold)交叉验证。一般来说k取值为10,这样训练数据稀疏时,基本上也能进行训练,缺点是训练和测试次数过多。
更极端的,如果 k=m ,则该方法又被称为leave-one-out交叉验证。
特征选择
特征选择(Feature Selection)严格来说也是模型选择中的一种。
假设我们想对维度为n的样本点进行回归,如果,n远远大于训练样例数m,且你认为其中只有很少的特征起关键作用的话,就可以对整个特征集进行特征选择,以减少特征的数量。
对于n个特征的 M 来说,根据特征是否包含在最终结果中,可以写出 2n 个不同的 Mi 。直接使用上面的交叉验证方法,计算量过大。这时可以采用如下启发式算法:
1.初始化特征集 F=∅ 。
2.Repeat {
(a)for 特征i=1 to n, {
如果 i∉F ,则 Fi=F∪{i} 。
在 Fi 上使用交叉验证方法评估它的泛化误差。
}
(b)将第(a)步中最优的 Fi 设为新的 F 。
}
3.选择并输出搜索过程中得到的最优子集。
这个算法被称为前向搜索(forward search)。其外部循环的终止条件为 ∣F∣ 达到n或者事先设定的门限值。
前向搜索属于wrapper model特征选择方法的一种。 Wrapper这里指不断地使用不同的特征子集来测试学习的算法。
除了前向搜索之外,还有后向搜索(backward search)算法。它和前者的区别在于,它的初始集合为全集,然后每次删除一个特征,并评价,直到 ∣F∣ 达到阈值或者为空,然后选择最佳的 F 即可。
可以看出无论前向搜索,还是后向搜索,其算法复杂度都是 O(n2) 。
KL散度
KL散度(Kullback–Leibler divergence)是两个随机分布间距离的度量。其定义如下:
其中,P和Q是离散概率分布, P(i) 和 Q(i) 是相应分布的概率密度函数。如果P和Q是连续随机变量的话,将上式中的累加符号换成积分符号即可。
但KL散度并不是真正的度量(metric)。它既不满足三角不等式(两边之和 ≥ 第三边),也不满足对称性(即 DKL(P∥Q)≠DKL(Q∥P) )。
注:Solomon Kullback,1907~1994,美国数学家和密码学家。乔治·华盛顿大学博士。NSA首任首席科学家。二战期间,参与破解德国的Enigma机器。
Richard Leibler,1914~2003,美国数学家和密码学家。伊利诺伊大学博士。NSA高级主管,入选NSA名人堂。
过滤特征选择方法
过滤特征选择(Filter feature selection)方法,是另一种启发式的特征选择算法,计算量比较小。它的思路是计算特征 xi 和类别标签y之间的相关度的评分 S(i) 。
可以使用 xi 和y之间的互信息量(mutual information),作为评分依据。
其中, p(xi,y) 是 xi 和y的联合概率密度, p(xi) 和 p(y) 是相应的边缘概率密度。
和KL散度类似,如果x和y是连续随机变量的话,将上式中的累加符号换成积分符号即可。
MI也可以用KL散度来表示:
过滤特征选择方法的算法复杂度为 O(n) 。
最后一个问题,选择多少个特征合适呢?按照 S(i) 从高到低的顺序,依次选择1到n个特征进行交叉验证,直到效果达到预期为止。
贝叶斯统计和规则化
前面提到最大似然(maximum likelihood)估计方法的公式如下:
从频率统计(frequentist statistic)学派的观点来看,这里的 θ 是一个未知的常数,我们的任务就是求出这个常数。然而从贝叶斯学派的观点来看, θ 是一个未知的随机变量。
也就是说似然函数,对于前者来说,是这样的: ∏mi=1p(y(i)|x(i);θ) ;但对于后者来说,却是这样的: ∏mi=1p(y(i)|x(i),θ)
我们首先假定 θ 的分布为 p(θ) ,这种假定由于没有事实根据,通常被称作先验分布(prior distribution)。
我们针对训练集 S={(x(i),y(i))}mi=1 ,训练得到预测函数。并按照如下公式计算后验分布(posterior distribution):
由全概率公式可得:
上式的 θi 表示 θ 的各个取值区间,然而由于 θ 是连续随机变量,根据微积分原理可得:
将公式2代入公式1可得:
当我们针对新的样本x进行预测时,和上面的推导类似,可得:
因为预测样本集和训练样本集的分布是独立的,因此上式又可写为:
这个公式又被称作后验预测分布(Posterior predictive distribution)。