【论文解读 EMNLP 2018】Cross-Lingual Cross-Platform Rumor Verification Pivoting on Multimedia Content

论文题目:Cross-Lingual Cross-Platform Rumor Verification Pivoting on Multimedia Content
论文来源:EMNLP 2018
论文链接:https://www.aclweb.org/anthology/D18-1385/
代码链接:https://github.com/WeimingWen/CCRV
关键词:跨语言;跨平台;特征;多媒体内容;谣言验证
文章目录
- 摘要
- 1 引言
- 2 相关工作
- 3 CCMR 数据集
- 4 框架概览
- 5 跨语言跨平台特征
- 5.1 Distance Fearures
- 5.2 Agreement Features
- 6 利用跨平台信息的谣言验证
- 7 利用跨语言信息的谣言验证
- 8 通过迁移学习实现低资源的谣言验证
- 9 总结
- 参考文献
摘要
本文研究的是利用多媒体内容进行谣言验证(rumor verification)。
之前的谣言验证研究仅利用多媒体作为输入特征。本文提出不使用多媒体内容,而是在其他以其为中心的新闻平台上寻找外部信息。
作者引入了一个新的特征集,即利用谣言和外部信息之间的语义相似性的跨语言跨平台的特征。
1 引言
(1)跨平台进行谣言验证的意义
读者通常没有时间去浏览不同平台上的类似时间,从而对谣言的真假进行明智的判断。因此,即使一个可信度高的平台已经辟谣,该谣言仍可在其他社交平台上继续传播。
(2)已有工作的局限性
有学者使用forensics features用于检测多媒体是否篡改,以对谣言进行验证。但这些特征并没有为模型的性能带来显著的提高。这是因为没有被篡改(un-tampered)的多媒体内容仍可能承载错误的信息,即图文无关。
(3)如何获取跨平台和跨语言的数据
作者提出以多媒体内容为中心,进行谣言的验证。与关键词相比,以视觉内容为中心的信息搜索更加有效和准确。
为了从多个平台更方便地获得信息,作者通过扩展一个Twitter谣言数据集,使用搜索引擎从不同的社交媒体平台获得网页,以构建一个新的谣言验证数据集。
已有的谣言验证数据集主要是单语言的,例如英语或中文。然而当在世界范围进行谣言验证时,谣言发生时的所使用的语言更有帮助。
因此,作者在Google上使用图片进行搜索时,关注到英文的网页;并且通过Baidu搜索,关注到中文的网页。
(4)作者提出
作者提出,通过寻找来自不同社交媒体平台但是有相似视觉内容的帖子间的一致性和不一致性,实现对多媒体信息的利用。
作者引入跨语言跨平台的特征,这些特征可以捕获来自于不同社交媒体的谣言帖子间的相似性和一致性。
作者使用这些特征构建了自动的谣言验证模型,并且在MediaEval 2015’s Verifying Multimedia Use (VMU 2015) [1]数据集上得到了SOTA的效果。
收集并标注外语描述的谣言是困难且耗时的,尤其是对于谣言验证标签资源较少的语言。本文提出的跨语言跨平台特征适用于不同语言的谣言,作者证明了这些特征可以将训练时在某一语言下学得的知识迁移到测试的另一种语言中。这种跨语言的适应能力有助于预测标注数据较少的语言的谣言。
2 相关工作
(1)利用特征的方法
对于检测篡改的图像有效,但不适用于误导性的图像(即图文不符)。
作者提出,通过寻找来自不同社交媒体平台但是有相似视觉内容的帖子间的一致性和不一致性,实现对多媒体信息的利用。
(2)wisdom of crowds
谣言和评论间的一致性经常被用于谣言的验证模型中。但是the crowd is not always wise。本文没有使用wisdom of crowds,而是使用来自不同新闻平台的知识来进行谣言的验证。
(3)关于知识
Ciampaglia等人[2]利用事实知识库,例如Wikipedia,来得到简单陈述的可信度。Shao等人[3]设计了一个系统,用于在不同平台上追踪谣言,和本文的工作最相近。但是它们没有利用到跨平台的信息以用于谣言验证。
本文提出的方法可以利用任意平台的信息来验证谣言,只要它有文本和多媒体信息。
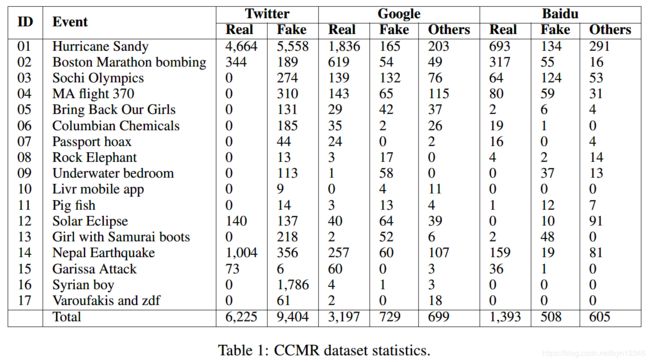
3 CCMR 数据集
本文构建了一个跨语言跨平台的多媒体谣言验证数据集CCMR,来研究如何利用不同媒体平台和不同语言的信息,以进行谣言的自动验证。
CCMR由3个子数据集构成:CCMR Twitter, CCMR Google, CCMR Baidu。
4 框架概览
图 2描述了本文框架的概览。

在收集完CCMR数据集后,首先利用Google进行Twitter谣言验证,如图 2底部所示。我们利用CCMR Google中的网页,为CCMR Twitter中的tweets抽取跨语言跨平台的特征(TFG)。然后使用这些特征进行谣言验证。
然后利用Baidu进行Twitter谣言验证,来测试本文的方法是否可以通过借用来自不同语言和平台的信息,进行谣言的验证。我们利用CCMR Baidu中的网页,为tweets抽取出跨语言跨平台的特征(TFB),并使用这些特征验证tweets。
接着通过迁移学习进行Baidu谣言验证,来测试跨语言跨平台特征的跨语言适应能力。我们将CCMR Baidu中的中文网页视为谣言,并通过迁移学习对谣言进行了验证。我们利用Google,为Baidu网页抽取跨语言跨平台的特征(BFG)。
由于BFG和TFG都是利用Google的跨语言跨平台特征,我们在CCMR Twitter上使用TFG特征对分类器进行预训练,然后使用该分类器验证使用BFG特征的CCMR Baidu数据集中的网页。假设前提是:tweets和网页有相似的分布。
5 跨语言跨平台特征
作者提出一组跨语言跨平台特征来利用不同社交媒体平台的信息。
首先使用预训练的多语言句子嵌入,将谣言和检索网页的标题嵌入成300维的向量。
接着进一步计算这些嵌入间的distance特征和agreement特征,以得到一组跨语言跨平台的特征。一共有10个特征,2个是distance特征,8个是agreement特征。
5.1 Distance Fearures
计算目标谣言和检索到的网页标题嵌入间的余弦距离。这个距离表明了,谣言是否和检索到的有着相似多媒体内容的网页也具有相似的含义。我们计算此距离的均值和方差。
(1)均值
距离的均值表示,一个谣言和与其相关的来自其他平台的网页间的平均相似度。均值越高则说明谣言和来自其他平台的检索到的信息越不同,则该谣言越有可能是假的。
(2)方差
方差表示这些检索到的网页彼此之间不一致的程度。高方差意味着多媒体信息被不同的事件使用,或者在不同的陈述中被描述。因此,谣言覆盖到的事件或陈述可能是假的。
5.2 Agreement Features
首先在Fake News Challenge提供的立场检测数据集上预训练一个agreement分类器。这一数据集为英语句子对提供了agreement标注,标签有agree, disagree, discuss, unrelated。
我们使用谣言和所有检索网页间预测概率的均值和方差,计算出agreement特征。因为一共有4个标签,所以总共有8个agreement特征。
agreement特征表示了谣言的陈述是否和其他平台相应的信息一致。
除了能够像distance特征一样获得类似的好处之外,agreement特征还捕获了信息立场被不同资源的谣言描绘成不同的情况。争论信息也可以视为假新闻的指示器。
6 利用跨平台信息的谣言验证
我们利用Google搜索引擎,为CCMR Twitter中的tweets抽取到了跨语言跨平台的特征(TFG),并且在谣言验证任务上使用MLP分类器,评估了TFG的有效性。


详见论文
7 利用跨语言信息的谣言验证
用Baidu的网页替换Google的网页,为tweets抽取出特征(TFB)。因为我们有一个预训练的多语言句子嵌入,该嵌入可以将中文和英文映射到共享的嵌入空间。
也是用MLP分类器,评估TFB和TFG、baseline的性能。
详见论文
8 通过迁移学习实现低资源的谣言验证
我们利用Google的信息,抽取出了CCMR Baidu数据集中网页的跨语言跨平台特征(BFG)。
然后使用第6节中在CCMR Twitter数据集上使用TFG进行训练的MLP分类器,来验证这些网页。
由于CCMR Baidu中网页的特征和tweets的特征不共享,例如tweets的特征有the number of likes and retweets。因此我们采用一个随机的选择模型作为baseline,它会以同等的概率预测谣言为真或假。我们在每个事件上比较迁移模型的性能和这一baseline的性能,并使用F1值作为评估度量。
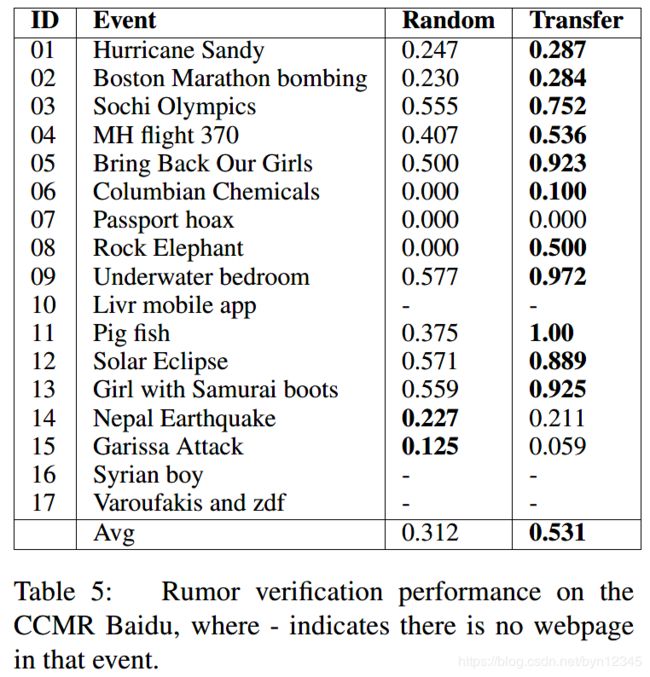
结果详见论文
9 总结
本文通过使用共享相似图像内容的通过Google、Baidu搜索引擎检索到的网页,对一个多媒体Twitter数据集进行扩展,构建了一个多媒体谣言验证数据集。
本文还设计了一组跨语言跨平台的特征,以利用不同平台和语言间的similarity和agreement,从而进行谣言的验证。
本文还涉及了基于神经网络的模型,以利用跨语言跨平台的特征,并在自动谣言验证这一任务上取得了SOTA的效果。
思考:
文章中提到百度检索到的网页往往会有更夸张的和有误导性的标题,以提高点击率。生成检索网页的嵌入时,只考虑到标题的信息,标题党的文章是否会产生影响。
参考文献
[1] Christina Boididou, Katerina Andreadou, Symeon Papadopoulos, Duc-Tien Dang-Nguyen, Giulia Boato, Michael Riegler, and Yiannis Kompatsiaris. 2015. Verifying multimedia use at mediaeval 2015. In MediaEval.
[2] Giovanni Luca Ciampaglia, Prashant Shiralkar, Luis M Rocha, Johan Bollen, Filippo Menczer, and Alessandro Flammini. 2015. Computational fact checking from knowledge networks. PloS one, 10(6):e0128193.
[3] Chengcheng Shao, Giovanni Luca Ciampaglia, Alessandro Flammini, and Filippo Menczer. 2016. Hoaxy: A platform for tracking online misinformation. In Proceedings of the 25th International Conference Companion on World Wide Web, pages 745–750. International World Wide Web Conferences Steering Committee.